Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Stockage dans les systèmes Pair à Pair
Olivier Soyez Directeurs de Thèse : Cyril Randriamaro – Vincent Villain L'action concertée incitative

2
Un pair? Internet Pas de consensus sur la définition

3
Emule Pas de consensus sur la définition

4
Emule 14 Millions d’utilisateurs
1,4 Milliards de fichiers = Plusieurs Po Pas de consensus sur la définition

5
Qui possède les ressources qui alimentent le système ?
Pair à Pair (P2P) ? Qui possède les ressources qui alimentent le système ? l’ensemble des pairs Pas de consensus sur la définition À la base définition fonctionnelle , puis par glissement sémantique définition structurelle et duynamique PAS SIMPLISTE
 Qui possède les ressources qui alimentent le système l’ensemble des pairs. Pas de consensus sur la définition. À la base définition fonctionnelle , puis par glissement sémantique définition structurelle et duynamique. PAS SIMPLISTE.")
6
Plan Les systèmes de stockage Pair à Pair Le projet Us
Politiques de distribution Conclusion / Perspectives

7
Applications du P2P Partage des fichiers Partage de CPU
Diffusion de MP3, DIVX Pionnier : Napster (Shawn Fanning) Emule (Open Source) Partage de CPU Applications scientifiques (Berkeley) Décrypthon (Téléthon) XtremWeb (Paris XI - LRI) Partage des disques Système génèrique calcul pair à pair : détecter une vie extraterrestre, de grandes paraboles écoute à la porte du ciel, et grâce au nombre conséquent de participant, il est possible de traiter l’immense masse de données reçues. Le décrypthon pour décrypter le génome humain et analyser des molécules à des fins thérapeutiques. A titre d’exemple, le décrypthon a permis de trouver 45 traitements antivariolique en l’espace de 6 mois, alors qu’il aurait fallu des années de calcul avec des moyens traditionnels.
 Emule (Open Source) Partage de CPU. Applications scientifiques. (Berkeley) Décrypthon (Téléthon) XtremWeb (Paris XI - LRI) Partage des disques. Système génèrique calcul pair à pair. : détecter une vie extraterrestre, de grandes paraboles écoute à la porte du ciel, et grâce au nombre conséquent de participant, il est possible de traiter l’immense masse de données reçues. Le décrypthon pour décrypter le génome humain et analyser des molécules à des fins thérapeutiques. A titre d’exemple, le décrypthon a permis de trouver 45 traitements antivariolique en l’espace de 6 mois, alors qu’il aurait fallu des années de calcul avec des moyens traditionnels.")
8
Projets stockage P2P Projet IRIS (12 M$) Projet DELIS
Mnemosyne (sprintlab) Clique (HP) Mammoth (BC U) Ficus (UCLA) Tornado (Tsing Hua U.) ... OceanStore (Berkeley) CFS (MIT) PAST (Rice) PASTA (Microsoft) Farsite (Microsoft) InterMemory (NEC) Ivy (MIT) PlanetP (Rutger U.) Projet IRIS (12 M$) MIT, Berkeley, Rice, ... ( Projet DELIS (
 Clique (HP) Mammoth (BC U) Ficus (UCLA) Tornado (Tsing Hua U.) ... OceanStore (Berkeley) CFS (MIT) PAST (Rice) PASTA (Microsoft) Farsite (Microsoft) InterMemory (NEC) Ivy (MIT) PlanetP (Rutger U.) Projet IRIS (12 M$) MIT, Berkeley, Rice, ... ( Projet DELIS. (")
9
Deux grandes classes Indexation centralisée Indexation distribuée DHT
IBP (LoCI) Intermemory (NEC) Indexation distribuée PAST (Rice) PASTIS (Paris VI - LIP 6) Ivy (MIT) OceanStore (Berkeley) DHT Indexation , qui à quoi? OceanStore partage collaboratif et système multi écrivain
 Intermemory (NEC) Indexation distribuée. PAST (Rice) PASTIS (Paris VI - LIP 6) Ivy (MIT) OceanStore (Berkeley) DHT. Indexation , qui à quoi OceanStore partage collaboratif et système multi écrivain.")
10
Table de Hachage Distribuée (DHT)
1 3 2 5 Ensemble des identifiants codés sur m bits 4

11
Table de Hachage Distribuée (DHT)
Modéle en couches (CFS : Chord File System) Primitives simples (put, get) Application distribuée (Application) put(clé, donnée) get (clé) donnée Table de hachage distribuée (Pérennité) (DHT) lookup(clé) Adresse IP (Routage) (Overlay) Service de localisation (Pairs)
 Primitives simples (put, get) Application distribuée. (Application) put(clé, donnée) get (clé) donnée. Table de hachage distribuée. (Pérennité) (DHT) lookup(clé) Adresse IP. (Routage) (Overlay) Service de localisation. (Pairs)")
12
Routage dynamique (Overlay)
1 9 Chaque pair mémorise k pairs de distance 2i, 1 i k 64 32 16 8 4 2 128 137 REDONDANCE DES CHEMINS + maintenir à jour les chemins Du au caractère dynamique des nœuds, chaque nœud mémorise k successeurs. Et un algorithme autostabilisant s’exécute de manière périodique pour mettre à jour les k successeurs de chaque nœud. Chord

13
Écriture d’un fichier (DHT)
1 4 56 8 41 12 14 30 19 12
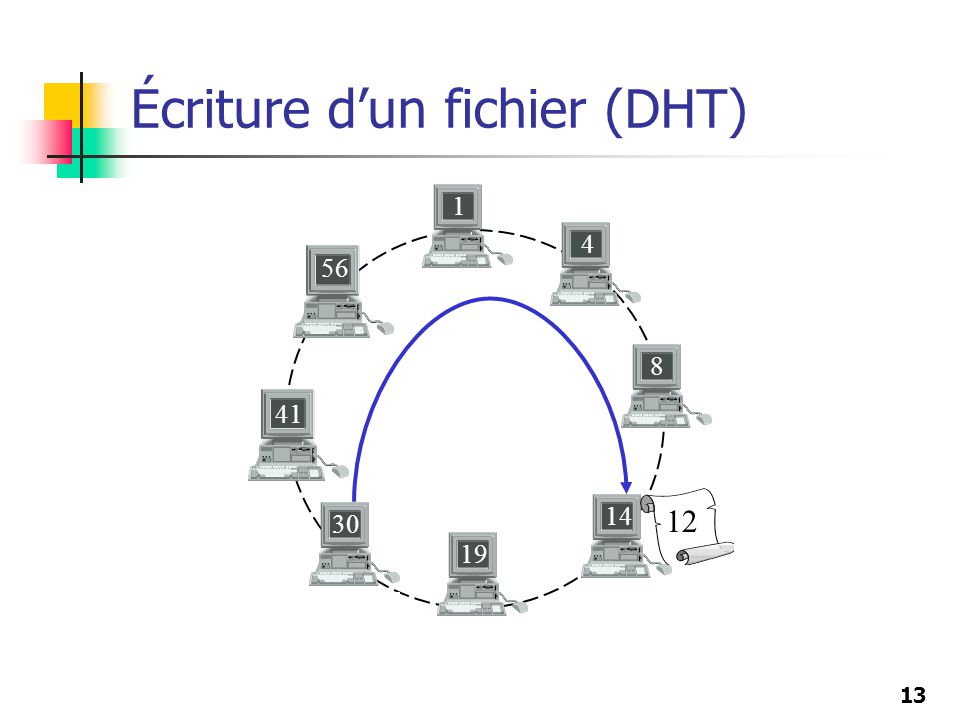
14
Lecture d’un fichier (DHT)
1 4 56 8 41 12 14 30 fichier 12? 19

15
Écriture d’un fichier (DHT)
1 4 56 8 41 12 14 30 19 12
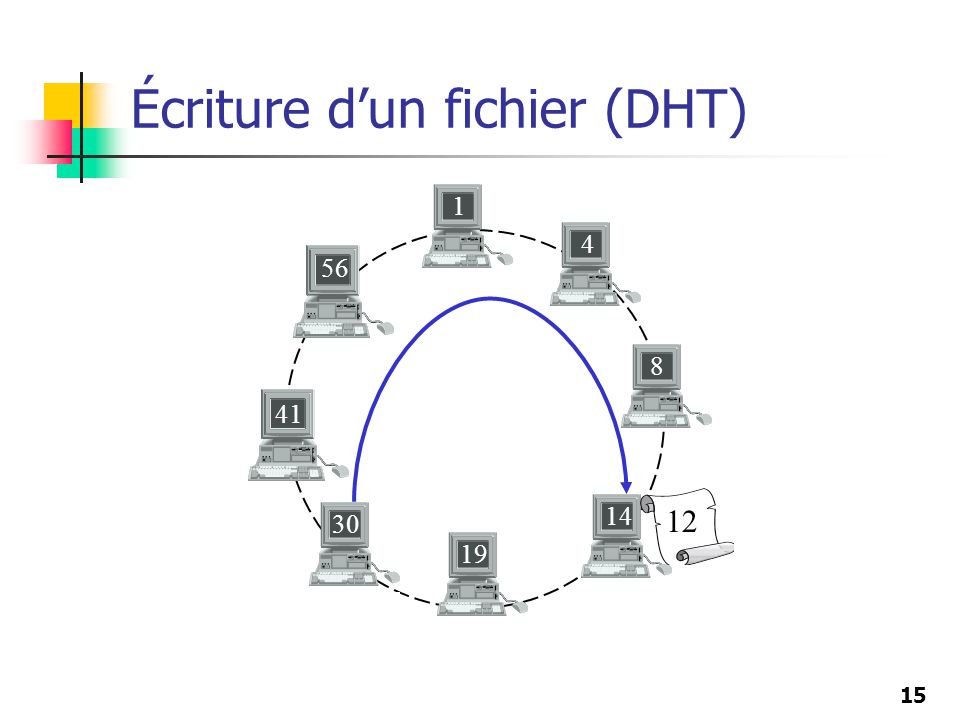
16
Pérennité? (DHT) 1 4 56 8 12 41 12 14 30 19 12
")
17
Le projet Us

18
Sauvegarde

19
Incident

20
Restauration

21
Reconstruction = s quelconques parmi s+r
Redondances k = 2 vs (s,r)=(4, 4) A)Réplication (DHT) - Données dupliquées : k fois - Espace utile : 1/k - Tolérance : k-1 pannes B)Codes Correcteurs (Us…) - Données fragmentées : s - Redondance : r - Espace utile : s / (s+r) - Tolérance : r pannes Exemple avec 10 Mo et 20 Mo, 50% N’impçorte quelle combinaison de s fragments parmi les s+r permet de reconstruire le bloc Reconstruction = s quelconques parmi s+r
=(4, 4) A)Réplication (DHT) - Données dupliquées : k fois. - Espace utile : 1/k. - Tolérance : k-1 pannes. B)Codes Correcteurs (Us…) - Données fragmentées : s. - Redondance : r. - Espace utile : s / (s+r) - Tolérance : r pannes. Exemple avec 10 Mo et 20 Mo, 50% N’impçorte quelle combinaison de s fragments parmi les s+r permet de reconstruire le bloc. Reconstruction = s quelconques parmi s+r.")
22
Redondance : vie des données ?
Fragments d’1 bloc avec s=3, r=5 s+r Seuil critique Fragments disponibles s 1 seul bloc inéluctablement le bloc est perdu Temps

23
Fragments disponibles
Redondance + Maintien Fragments d’1 bloc avec s=3, r=5 s+r Fragments disponibles s Comme pour le processus de maintenance de la redondance des chemins dans chord, …. Pour remédier à cela, on utilise un processus dynamique de reconstruction des fragments Temps

24
Us = Disque Dur Virtuel P2P Pérenne

25
Architecture Us Us Utilisateur Us Client Us Blocs Fournisseur
Système de fichier UsFS Utilisateur Us Client Us Blocs Fournisseur 3 entités : les clients en rouge, les fournisseurs en jaune, les stockeurs en … Fournisseur Fragments Us

26
Stockage d’un fichier UsFs Us fichier blocs s fragments
découpage blocs fragmentation Us s fragments On note f le nombre de fragments Le stockage d’un fichier s’effectue en 3 phases découpage Cette phase est assurée par le système de fichier UsFS. Fragmentation + redondance Ces phases sont gérées par le système de stockage Us. redondance f=s+r fragments

27
Distribution des données

28
Contexte Us Environnement Pair à Pair Couche communication Pannes
Déconnections fréquentes Couche communication Internet (ADSL) : Réception >> Envoi Bande passante limitée des Pairs Asymétriques
 : Réception >> Envoi. Bande passante limitée des Pairs. Asymétriques.")
29
A la mort d’un seul pair Exemple 100*30=3000 fragments 3 Go
Chaque pair stocke 100 fragments de taille 1 Mo Un bloc est composé de f=31 fragments Régénérer un fragment perdu Envoi des f-1 fragments A la mort d’un seul pair 100*30=3000 fragments 3 Go Annuaire ils ont choisi d’être centralisé … Mettre origine Labo projet

30
Exemple 128 Kb 10 Mb 2 minutes ! 4 heures !

31
Problématique Coût de reconstruction élevé X Y
Nombreuses reconstructions X Y Coût de reconstruction = Nombre maximum de fragments envoyés dans le pire des cas

32
Théorème du repliement
Le coût de reconstruction est linéaire et facteur du nombre de blocs stockés X X’ Y Y’ Coût=2 Trouver une distribution optimale de coût de reconstruction = 1

33
Formulation du problème
X Y Maximiser le nombre de blocs Coût de reconstruction = 1 Intersection entre 2 blocs 1 Notre problème est : J’ai prouvé que ce problème équivaut à obtenir une intersection entre 2 blocs distincts 1

34
Et ça, pour tous les pairs !
Cas idéal Bi Bj Et ça, pour tous les pairs ! Cas idéal : chaque pair est centre d’une fleur

35
Formulation mathématique
Trouver un ensemble maximal de listes de f éléments parmi N Intersection entre 2 listes distinctes 1 1 liste de f éléments = 1 bloc f=5 X : {1,2,3,4,5} et Y : {5,6,7,8,9} N = nombre total de pair SOLUTION ?

36
Plan affine fini d’ordre n
Nombre de points = n² Nombre de lignes = n²+n Intersection entre 2 lignes 1 1 2 3 5 6 4 7 pairs N= n² blocs NB= n²+n blocs Restrictions sont fortes : Le nombre de fragments doit être un nombre premier Le nombre total de pairs est fixé

37
Pas toujours de solution
Contraintes f fixé : puissance d’un nombre premier Paramètre modulable du système N fixé : dépendant de f Hypothèse non acceptable Pas toujours de solution Bilan Chercher la limite théorique du problème Proposer une heuristique de distribution dans un système pair à pair impossible d’imposer le nombre d’utilisateur Restrictions sont fortes : Le nombre de fragments doit être un nombre premier Le nombre total de pairs est fixé

38
Limite théorique du problème
Schonheim (1966) Trouver une distribution qui approche le plus possible le nombre de blocs stockés NBmax : la distribution pseudo-affine * Annuaire ils ont choisi d’être centralisé … Mettre origine Labo projet C. Randriamaro, O. Soyez, G. Utard and F. Wlazinski Data distribution in a peer to peer storage system Actes de GP2PC05, mai 2005 *
 Trouver une distribution qui approche le plus possible le nombre de blocs stockés NBmax : la distribution pseudo-affine * Annuaire. ils ont choisi d’être centralisé … Mettre origine Labo projet. C. Randriamaro, O. Soyez, G. Utard and F. Wlazinski. Data distribution in a peer to peer storage system. Actes de GP2PC05, mai *")
39
Distribution pseudo-affine
Détermine le + grand nombre premier p1 f p1 N/f nombre d’ = 0 p1 matrices d’ = 1 + matrices d’ = 0 1 p p … (f-1)p1+1 1 p p … (f-1)p1+2 1 p p … (f-1)p1+2 … … … … 1 p1+ p1 2p1+ p1 … (f-1)p1+ p1 p1 lignes 1 centre de la fleur !!!! f colonnes
p p1+2 2p1+2 … (f-1)p p1+3 2p1+3 … (f-1)p … … … … 1 p1+ p1 2p1+ p1 … (f-1)p1+ p1. p1 lignes. 1 centre de la fleur !!!! f colonnes.")
40
Distribution pseudo-affine
f=5 (fragments) et N=40 (pairs) p1=7 +1 +2 +3 rotations
 et N=40 (pairs) p1= rotations.")
41
Distribution pseudo-affine
f=5 (fragments) et N=40 (pairs) p1=7
 et N=40 (pairs) p1=")
42
Distribution pseudo-affine
f=5 (fragments) et N=40 (pairs) p1=7 On peut encore construire des matrices plus petites … NBp1=p1²
 et N=40 (pairs) p1= On peut encore construire des matrices plus petites … NBp1=p1².")
43
Distribution pseudo-affine *
Arithmétique modulaire Théorie des nombres premiers Solution f nombre premier Pour tout N Asymptotiquement optimale Optimale N multiple de f² Ensemble quotient C. Randriamaro, O. Soyez, G. Utard and F. Wlazinski Data distribution in a peer to peer storage system Actes de GP2PC05, mai 2005 *

44
Analyse Limite théorique Distribution pseudo-affine Nombre de blocs
(NB) En plus d’être asymptotiquement optimale, pour des nombres possibles de pairs, notre distribution est toujours très proche de l’optimale. + ZOOM pour : croissance en escalier = éloignement de N par rapport aux multiples de f² La courbe de notre distribution évolue en escalier due à l’éloignement de N par rapport aux multiples de f² Nombre de pairs (N)
 En plus d’être asymptotiquement optimale, pour des nombres possibles de pairs, notre distribution est toujours très proche de l’optimale. + ZOOM pour : croissance en escalier = éloignement de N par rapport aux multiples de f². La courbe de notre distribution évolue en escalier due à l’éloignement de N par rapport aux multiples de f². Nombre de pairs (N)")
45
Distribution DHT = Aléatoire
1 4 56 8 41 12 14 30 19 12
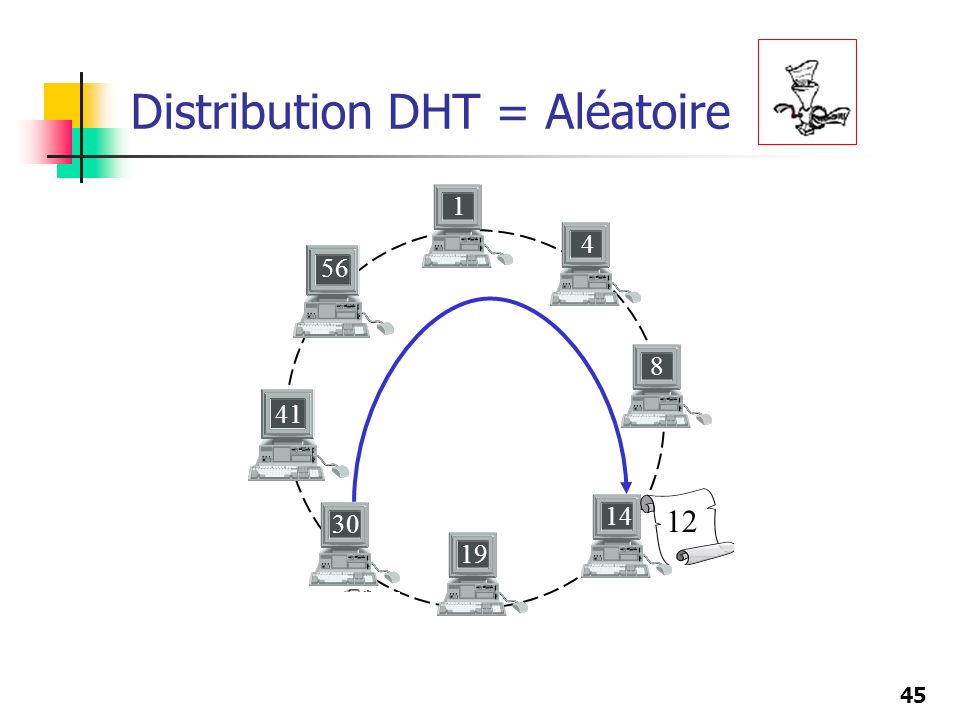
46
Coût de reconstruction
Comparaison Distribution aléatoire Limite théorique Distribution pseudo-affine Coût de reconstruction Nombre de pairs (N)
")
47
Corrélation des pannes

48
Corrélation des pannes
Y X ECHEC PERENNITE

49
* Métapairs Regroupement de Pairs Architecture à 2 niveaux
Corrélation des pannes * Rapprochement topologique Métapair = + proche géographiquement Architecture à 2 niveaux Métapairs Pairs C. Randriamaro, O. Soyez, G. Utard and F. Wlazinski Data distribution for failure correlation management in a peer to peer storage system Actes de GP2PC05, mai 2005 *

50
Métapairs 1 2 3 4 5 6 7 8 9 Association de la distribution pseudo-affine et d’une distribution aléatoire 1 2 3 4 5 6 7 8 9 On réutilise la distribution statique, chaque pair devient un métapair (un ensemble de pair) Chaque pair devient un métapair, un métapair est un ensemble de pairs géographiquement proche. Each peer become a MetaPeer, one MetaPeer is a set of peers geographically close. And we have the following storage rules: The f fragments of a block are stored inside f differents MetaPeers. In this condition, the failure correlation is managed. And one fragment of a block is stored by a peer selected randomly inside a MetaPeer.
 Chaque pair devient un métapair, un métapair est un ensemble de pairs géographiquement proche. Each peer become a MetaPeer, one MetaPeer is a set of peers geographically close. And we have the following storage rules: The f fragments of a block are stored inside f differents MetaPeers. In this condition, the failure correlation is managed. And one fragment of a block is stored by a peer selected randomly inside a MetaPeer.")
51
Pseudo-affine sur Métapairs
Blocs 1 2 3 4 5 6 7 8 9 Métapairs Pairs

52
Exemple avec f=3 9 pairs répartis dans 3 Métapairs
Taille des Métapairs = 3 MP 1 MP 2 MP 3 MP 1 MP 2 MP 3 1 1 1 Mieux que aléatoire, on peut faire du pseudo affine à l’intérieur des Métapairs. 2 3 2 3 2 3

53
Exemple avec f=3 Répartition cyclique MP 1 MP 2 MP 3 MP 1 MP 2 MP 3 1

54
Exemple avec f=3 Algorithme de la distribution pseudo-affine
MP 1 MP 2 MP 3 MP 1 MP 2 MP 3 1 1 1 1 1 2 2 3 2 2 3 2 3 3 3

55
Coût de reconstruction
Analyse (1) Coût de reconstruction Nombre de pairs (N)
 Coût de reconstruction. Nombre de pairs (N)")
56
Coût de reconstruction
Analyse (2) Distribution aléatoire RSUW05 avec 7 Métapairs RSUW05 avec 294 Métapairs Coût de reconstruction Temps
 Distribution aléatoire. RSUW05 avec 7 Métapairs. RSUW05 avec 294 Métapairs. Coût de reconstruction. Temps.")
57
Développements Us (Java) UsFS (C) Prototype fonctionnel
Système de fichier Module noyau Journalisation Espace Utilisateur Noyau ls –l /home/oli/UsFS glibc libfuse UsFS /home/oli/UsFS VFS NFS Fuse Ext3 JE Quantification de l’impact de la corrélation des pannes sur

58
Conclusion / Perspectives
Distribution pseudo-affine Coût de reconstruction Corrélation des pannes Etude quantitative de la pérennité de la distribution Métapairs Expérimentation à grande échelle Grid5000 Etude comportementale des pairs Profil utilisateur JE Quantification de l’impact de la corrélation des pannes sur

Présentations similaires





![[number 1-100].](/1/172887/big_thumb.jpg "[number 1-100].>")













