Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Cours 5 Partie 1 Les statistiques avec R

2
Lois de probabilité, distributions On peut évaluer les quantités suivantes: Fonctions de répartition Densité Quantiles Echantillons Simulés Les fonctions ont le même nom avec des préfixes différents r: donne des échantillons d: donne les valeurs P(X=j) p: donne les valeurs P(X<=x) q: donne la valeur y telle que P(X=x)=y Exemples: dnorm(),pnorm(),qnorm(),rnorm():loi normale dbinom(),pbinom(),qbinom(),rbinom():loi binomiale dt(),pt(),qt(),rt():loi de student dpois(), ppois(), qpois(), tpois():loi de Poisson …
 p: donne les valeurs P(X<=x) q: donne la valeur y telle que P(X=x)=y Exemples: dnorm(),pnorm(),qnorm(),rnorm():loi normale dbinom(),pbinom(),qbinom(),rbinom():loi binomiale dt(),pt(),qt(),rt():loi de student dpois(), ppois(), qpois(), tpois():loi de Poisson …")
3
exemples dbinom(k, n, p) donne la valeur P(X=k) sachant que X suit une loi B(n,p),c’est-à-dire Exemple: dbinom(3,10,0.2) 0.2013266
 donne la valeur P(X=k) sachant que X suit une loi B(n,p),c’est-à-dire Exemple: dbinom(3,10,0.2)")
4
rbinom(10,n,p) donne un échantillon de taille 10 extrait d’une population suivant une loi B(n,p): Exemple: rbinom(10,10,0.2) [1] 5 2 3 2 4 0 4 2 0 2 pbinom(k,n,p) donne P(X<=k) sachant que X suit une loi B(n,p),c’est-à-dire la valeur de la fonction de répartition F(k) Exemples: pbinom(3,10,0.2); 0.8791261 pbinom(1:10,10,0,2) ; [1] 0.1073742 0.3758096 0.6777995 0.8791261 0.9672065 0.9936306 0.9991356 0.9999221 0.9999958 1.0000000
![rbinom(10,n,p) donne un échantillon de taille 10 extrait d’une population suivant une loi B(n,p): Exemple: rbinom(10,10,0.2) [1] pbinom(k,n,p) donne P(X<=k) sachant que X suit une loi B(n,p),c’est-à-dire la valeur de la fonction de répartition F(k) Exemples: pbinom(3,10,0.2); pbinom(1:10,10,0,2) ; [1]](http://images.slideplayer.fr/41/11186240/slides/slide_4.jpg "rbinom(10,n,p) donne un échantillon de taille 10 extrait d’une population suivant une loi B(n,p): Exemple: rbinom(10,10,0.2) [1] pbinom(k,n,p) donne P(X<=k) sachant que X suit une loi B(n,p),c’est-à-dire la valeur de la fonction de répartition F(k) Exemples: pbinom(3,10,0.2); pbinom(1:10,10,0,2) ; [1]")
5
Fonction de répartition de la loi binomiale de paramètres 10 et 0,2 ●

7
qbinom(q,n,p) est le quantile, c’est-à-dire la plus petite valeur x telle que F(x)=P(X =q. Exemple: qbinom(0.5,10,0.2) ; [1] 2 qchisq(.1,df=8) est le premier décile de X^2(8) (loi du chi-deux a 8 degrés de liberté)
 ; [1] 2 qchisq(.1,df=8) est le premier décile de X^2(8) (loi du chi-deux a 8 degrés de liberté).")
8
Exemple d'une loi continue: la loi normale qnorm(0.2) [1] -0.8416212 ●
![Exemple d une loi continue: la loi normale qnorm(0.2) [1] ●](http://images.slideplayer.fr/41/11186240/slides/slide_8.jpg "Exemple d une loi continue: la loi normale qnorm(0.2) [1] ●")
9
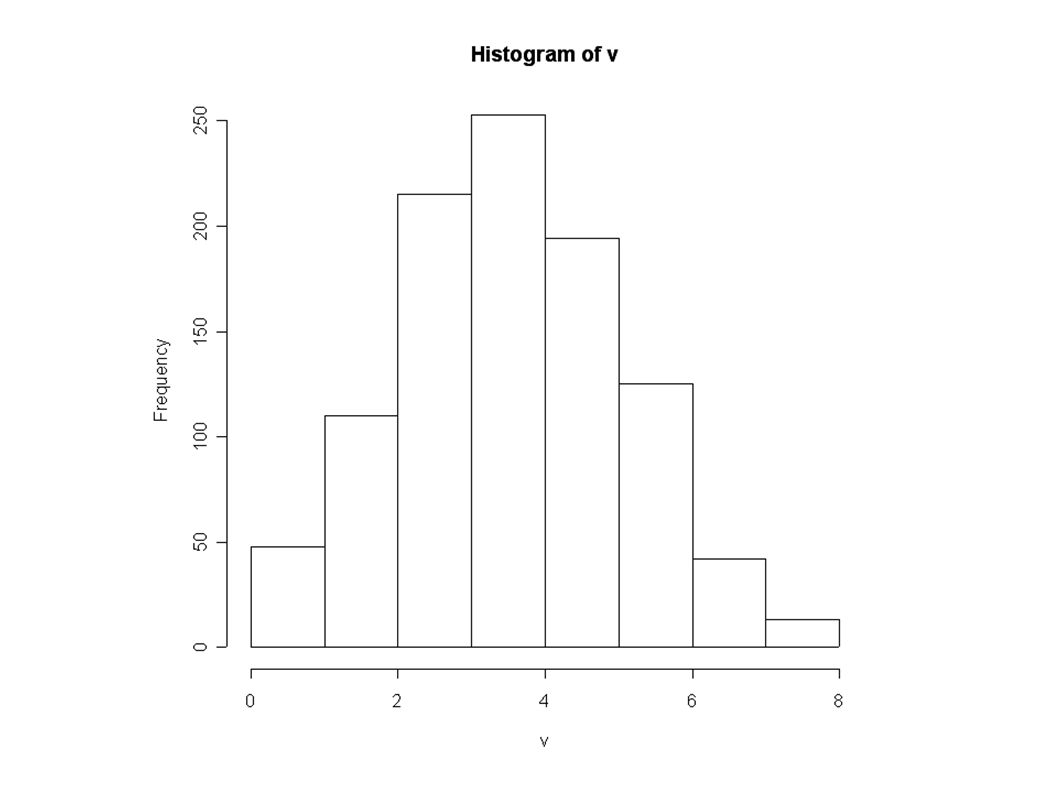
Représentation de données discrètes: tracés d'histogrammes La fonction hist() Exemple: v=rbinom(1000,10,0.4) table(v); v 0 1 2 3 4 5 6 7 8 4 44 110 215 253 194 125 42 13 hist(v);
 Exemple: v=rbinom(1000,10,0.4) table(v); v hist(v);")
11
Distribution d’un ensemble d’observations Quelques fonctions: si v est un ensemble d’observations table(v): compte les fréquences des éléments de v hist(v): trace l’histogramme summary(v): renvoie un résumé statistique du contenu de v,avec le min 1er quartile, moyenne, médiane,3iemme quartile et max quantile(v): renvoie les quantiles correspondant au vecteur de probabilité donné. Par défaut renvoie les quartiles Moins utilisées stem():arbre qqplot(x,y):trace les quantiles de x /quantiles de y
:arbre qqplot(x,y):trace les quantiles de x /quantiles de y.")
12
exemples essai=sample(1:20,200,replace=TRUE) ● stem(essai) ● ● 1 | 0000000000000000 ● 1 | ● 2 | 0000000000000000000000000 ● 2 | ● 3 | 00000000000000000000000 ● 3 | ● 4 | 0000000000000000 ● 4 | ● 5 | 00000000000000000000 ● 5 | ● 6 | 000000000000000000000 ● 6 | ● 7 | 00000000000000000 ● 7 | ● 8 | 00000000000000000000000000 ● 8 | ● 9 | 00000000000000000 ● 9 | ● 10 | 0000000000000000000
 ● stem(essai) ● ● 1 | ● 1 | ● 2 | ● 2 | ● 3 | ● 3 | ● 4 | ● 4 | ● 5 | ● 5 | ● 6 | ● 6 | ● 7 | ● 7 | ● 8 | ● 8 | ● 9 | ● 9 | ● 10 |")
13
● hist(essai)
")
14
Cours 5 Partie 2 Approfondissements divers

15
hist(x,breaks= « Sturges »,prob=FALSE) ● X un vecteur de valeurs pour lequel on souhaite un histogramme ● breaks:soit -un vecteur chaine de caractère donnant un algorithme pour calculer le nombre d'intervalles -un nombre donnant le nombre d'intervalles ● prob=FALSE:fréquences ● prob=TRUE: fréquences relatives ou probabilités
 ● X un vecteur de valeurs pour lequel on souhaite un histogramme ● breaks:soit -un vecteur chaine de caractère donnant un algorithme pour calculer le nombre d intervalles -un nombre donnant le nombre d intervalles ● prob=FALSE:fréquences ● prob=TRUE: fréquences relatives ou probabilités")
16
Eviter d ’écrire des boucles: 1 avec les fonctions apply() lapply()sapply() apply(X, MARGIN, FUN,...) retourne un vecteur de la taille appropriée, où X: tableau Margin =1 pour les lignes, 2 pour les colonnes Fun: fonction '+', '%*%‘, mean, sum,... lapply sapply() même fonction pour les listes et les vecteurs
 même fonction pour les listes et les vecteurs.")
17
Eviter d ’écrire des boucles (2) Exemple 1 n=10 p=0.2 x=0:n y=choose(n,x)*p^x*(1-p)^(n- x) #ou bien y=dbinom(x,n,p) plot(x,y,type="h",lwd=10) Exemple 2 prod(1:8); 40320 identique à factorial(8)
 Exemple 1 n=10 p=0.2 x=0:n y=choose(n,x)*p^x*(1-p)^(n- x) #ou bien y=dbinom(x,n,p) plot(x,y,type= h ,lwd=10) Exemple 2 prod(1:8); identique à factorial(8)")
18
Un exemple d'utilisation du type factor

19
Le type factor:Un exemple Un facteur est un objet vecteur qui peut être utilisé pour spécifier une classification discrète des composants d’un autre vecteur de même longueur Facteurs non ordonné:variable qualitative ou Facteurs ordonnés:variable qualitative ordonnée

20
prov=c("PA","PA","AG","RG","ME","CT","CT","SR","TP","EN", "CL","ME","PA","AG","RG","ME","CT","CT","SR","TP","EN") length(prov) [1] 21 fprov=factor(prov) ;fprov [1] PA PA AG RG ME CT CT SR TP EN CL ME PA AG RG ME CT CT SR TP EN Levels: AG CL CT EN ME PA RG SR TP levels(fprov) [1] "AG" "CL" "CT" "EN" "ME" "PA" "RG" "SR" "TP"
![prov=c( PA , PA , AG , RG , ME , CT , CT , SR , TP , EN , CL , ME , PA , AG , RG , ME , CT , CT , SR , TP , EN ) length(prov) [1] 21 fprov=factor(prov) ;fprov [1] PA PA AG RG ME CT CT SR TP EN CL ME PA AG RG ME CT CT SR TP EN Levels: AG CL CT EN ME PA RG SR TP levels(fprov) [1] AG CL CT EN ME PA RG SR TP](http://images.slideplayer.fr/41/11186240/slides/slide_20.jpg "prov=c( PA , PA , AG , RG , ME , CT , CT , SR , TP , EN , CL , ME , PA , AG , RG , ME , CT , CT , SR , TP , EN ) length(prov) [1] 21 fprov=factor(prov) ;fprov [1] PA PA AG RG ME CT CT SR TP EN CL ME PA AG RG ME CT CT SR TP EN Levels: AG CL CT EN ME PA RG SR TP levels(fprov) [1] AG CL CT EN ME PA RG SR TP")
21
revenus=c(13000,14900,14000,16100,14500,16600,159 00,15400,17000,19000,14600,17000,18500,15800,14500,16600,15900,15400,17000,19000,20000) revenu.par.province=tapply(revenus,fprov,mean); revenu.par.province; AG CL CT EN ME PA 14900.00 14600.00 15950.00 19500.00 16033.33 15466.6 RG SR TP 15300.00 16200.00 18000.00
 revenu.par.province=tapply(revenus,fprov,mean); revenu.par.province; AG CL CT EN ME PA RG SR TP")
22
La fonction which() which(x, arr.ind = FALSE) x: un vecteur ou tableau logique arr.ind: logique est-ce que les indices du tableau doivent être retournés lorsque x est un tableau? Exemple: m = matrix(12:24,3,4) ;m [,1] [,2] [,3] [,4] [1,] 12 15 18 21 [2,] 13 16 19 22 [3,] 14 17 20 23
 ;m [,1] [,2] [,3] [,4] [1,] [2,] [3,]")
23
which(m % 3 == 0); [1] 1 4 7 10 which(m % 3 == 0, arr.ind=TRUE); row col [1,] 1 1 [2,] 1 2 [3,] 1 3 [4,] 1 4
![which(m % 3 == 0); [1] which(m % 3 == 0, arr.ind=TRUE); row col [1,] 1 1 [2,] 1 2 [3,] 1 3 [4,] 1 4](http://images.slideplayer.fr/41/11186240/slides/slide_23.jpg "which(m % 3 == 0); [1] which(m % 3 == 0, arr.ind=TRUE); row col [1,] 1 1 [2,] 1 2 [3,] 1 3 [4,] 1 4")
24
Etude empirique des fluctuations d'échantillonnage ● Quelquefois, on est dans l'impossibilité de calculer la distribution d'échantillonnage de certaines caractéristiques utiles: soit parce que n est trop petit,soit parce que la distribution parente est inconnue ● On utilise alors des techniques de simulation, qui substituent la puissance de calcul d'un ordinateur à celle d'un développement analytique:

25
Population de distribution connue: ● Si on connait la loi F de la variable parente X, il suffit de simuler un très grand nombre N d'échantillons de n valeurs de X. Pour chaque échantillon, on calcule la statistique cherchée, d'ou une distribution T1,...Ti ● Si N est grand, la répartition empirique des Ti est proche de la loi de la variable T

26
Population de distribution inconnue:la méthode de rééchantillonnage bootstrap L'idée (B.EFRON) est la suivante: ● Si n est grand Fn* est proche de F, on aura donc une bonne approximation de la loi de T en utilisant Fn*à la place de F. ● On tire donc des échantillons de n valeursdans la loi Fn*, ce qui revient à rééchantillonner dans l'échantillon x1,...xn. ● Autrement dit à effectuer des tirages avec remise des n valeurs parmi les n observées

27
● Les valeurs observées sont donc répétées. ● Lorsque n n'est pas très grand, on peut énumérer tous les échantillons possible équiprobables,(n^n),sinon on se contente d'en tirer un nombre suffisamment grand à l'aide d'une technique de tirage dans une population finie
,sinon on se contente d en tirer un nombre suffisamment grand à l aide d une technique de tirage dans une population finie.")
28
Cours 5 Partie 3 Exemples de statistiques descriptives

29
Exercice 1 : Dans une enquête sur les conditions de vie des ménages de banlieue, on dispose de la série statistique du nombre d’enfants de 10 ménages:

30
D=data.frame(men=1:11,nbenf=c(3,2,5,3,6,3,5,5,1,5,2));D; men nbenf 1 1 3 2 2 2 3 3 5 4 4 3 5 5 6 6 6 3 7 7 5 8 8 5 9 9 1 10 10 5...
);D; men nbenf")
31
Calculer la moyenne du nombre d’enfants par ménage de deux façons différentes mean(D$nbenf); [1] 3.636364 sum(D$nbenf)/length(D$nbenf) [1] 3.636364
![Calculer la moyenne du nombre d’enfants par ménage de deux façons différentes mean(D$nbenf); [1] sum(D$nbenf)/length(D$nbenf) [1]](http://images.slideplayer.fr/41/11186240/slides/slide_31.jpg "Calculer la moyenne du nombre d’enfants par ménage de deux façons différentes mean(D$nbenf); [1] sum(D$nbenf)/length(D$nbenf) [1]")
32
Construire le tableau de la distribution des fréquences de cette série ● df=D$nbenf/sum(D$nbenf) ● > df ● [1] 0.075 0.050 0.125 0.075 0.150 0.075 0.125 0.125 0.025 0.125 0.050
![Construire le tableau de la distribution des fréquences de cette série ● df=D$nbenf/sum(D$nbenf) ● > df ● [1]](http://images.slideplayer.fr/41/11186240/slides/slide_32.jpg "Construire le tableau de la distribution des fréquences de cette série ● df=D$nbenf/sum(D$nbenf) ● > df ● [1]")
33
Représenter graphiquement cette distribution. plot(table(D$nbenf),main="diagramme en batons des effectifs") plot(table(D$nbenf),main="polygone des effectifs ", type="b", col=2)
,main= diagramme en batons des effectifs ) plot(table(D$nbenf),main= polygone des effectifs , type= b , col=2).")
34
plot(table(D$nbenf)/length(D$nbenf),xlab= "nombre d'enfants", ylab="frequence")
/length(D$nbenf),xlab= nombre d enfants , ylab= frequence )")
36
Exercice 2 : Au poste de péage, on compte le nombre de voitures se présentant sur une période de 5mn. Sur 100 observations de 5mn, on obtient les résultats suivants:...

37
Construire le diagramme en bâtons et le polygone des fréquences cumulées de la série du nombre de voitures. ● D1=data.frame(nv=1:12,no=c(2,8,14,20,19,15,9,6,2,3,1,1)) ● plot(D1$nv,D1$no,type="h", main="diagramme en batons",xlab="nombre de voitures", ylab="nombre d'observations")
) ● plot(D1$nv,D1$no,type= h , main= diagramme en batons ,xlab= nombre de voitures , ylab= nombre d observations ).")
39
Polygone des fréquences cumuléees ● fc=cumsum(no) ● plot(D1$nv,fc,type="l", main="polygone des frequences cumulées",xlab="nombre de voitures", ylab="frequences cumulees")
 ● plot(D1$nv,fc,type= l , main= polygone des frequences cumulées ,xlab= nombre de voitures , ylab= frequences cumulees )")
41
Calculer la moyenne et l’écart-type de cette série. ● (attention il s'agit de moyennes et d'ecart type pondérés) moy=sum(D1$nv*D1$no)/100 [1] 5.07 et=sqrt(sum(0.01*D1$no*(D1$nv- moy)^2)) > et [1] 2.182911
 moy=sum(D1$nv*D1$no)/100 [1] 5.07 et=sqrt(sum(0.01*D1$no*(D1$nv- moy)^2)) > et [1]")
42
Déterminer la médiane, les quartiles et tracer le box-plot. ● s=rep(D1$nv,D1$no);s summary(s) Min. 1st Qu. Median Mean 3rd Qu. Max. 1.00 4.00 5.00 5.07 6.00 12.00 boxplot(s)
;s summary(s) Min. 1st Qu. Median Mean 3rd Qu. Max boxplot(s).")
44
Etudier la symétrie de la série calcul du moment d'ordre r r=2 mr=(sum(0.01*D1$no*(D1$nv-moy)^r))^(1/r): 2.18 r=3 mr=(sum(0.01*D1$no*(D1$nv-moy)^r))^(1/r) mr [1] 1.944207 r=4 [1] 2.982554
![Etudier la symétrie de la série calcul du moment d ordre r r=2 mr=(sum(0.01*D1$no*(D1$nv-moy)^r))^(1/r): 2.18 r=3 mr=(sum(0.01*D1$no*(D1$nv-moy)^r))^(1/r) mr [1] r=4 [1]](http://images.slideplayer.fr/41/11186240/slides/slide_44.jpg "Etudier la symétrie de la série calcul du moment d ordre r r=2 mr=(sum(0.01*D1$no*(D1$nv-moy)^r))^(1/r): 2.18 r=3 mr=(sum(0.01*D1$no*(D1$nv-moy)^r))^(1/r) mr [1] r=4 [1]")
Présentations similaires










 Situation: On souhaite.>")
 Ce sont des vecteurs qui possèdent un argument supplémentaire, qui est lui-même un vecteur de longueur 2, sa dimension,>")
 Pour prendre possession des données o des chiffres dans un tableau, c’est bien o.>")



>")







