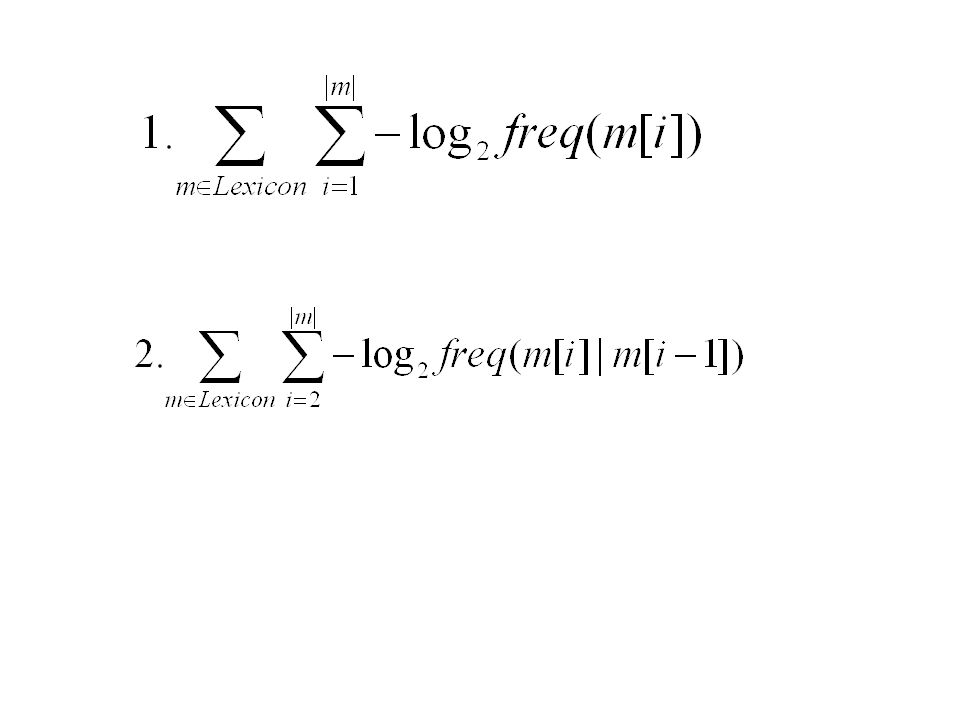Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Vers un nouvel empirisme: lapprentissage automatique John Goldsmith Université de Chicago Projet MoDyCo / CNRS

2
1.Remarques générales sur une perspective empiriste, et sur ses implications vis-à-vis la linguistique. –Remarques un peu trop formelles et mathématiques sur les structures probabilistes. 2.Lapprentissage automatique de la structure morphologique, implémenté dans un logiciel: Linguistica, qui illustre cette perspective.

3
Le message central de Chomsky Lapprentissage est difficile à expliquer. La présentation des données namène pas automatiquement à une généralisation. Le problème de linduction en philosophie et sa pertinence en linguistique : Comment établir une généralisation dans la portée est non-bornée, étant donné un échantillon fini dobservations.

4
Une conclusion possible? Rechercher ce qui nest pas appris dans le langage. Ce qui nest pas appris sera universel. Valoriser la recherche du non-appris.

5
Non-appris Appris

6
Non-appris Appris Non-appris

7
Comment déterminer devant quel scénario nous nous trouvons? Considérons une question dont la réponse doit être apprise: –Le vocabulaire dune langue, ou –La structure morphologique de ce vocabulaire.

8
Quels méthodes faut-il pour apprendre lappris?

9
Deux facteurs de lapprentissage dans un domaine 1.La simplicité du système g appris 2.La mesure dans laquelle g explique les données D. Ces deux facteurs jouaient un role important dans la grammaire générative de LSLT (Chomsky 1975 [1955])
.")
10
La métrique de simplicité I think the right approach to the fundamental theoretical issues is the one attempted [in LSLT]: to make precise a certain format and schematism for grammars, and to provide an evaluation procedure (or simplicity measure) that leads to the choice of a particular system, a particular grammar that is of the required form, namely, the optimal, most highly valued system of the required form that is compatible with the presented data. Then what the language learner comes to know is that most highly valued system; it is that system that underlies the actual use of language by the person who has gained his knowledge.
![La métrique de simplicité I think the right approach to the fundamental theoretical issues is the one attempted [in LSLT]: to make precise a certain format and schematism for grammars, and to provide an evaluation procedure (or simplicity measure) that leads to the choice of a particular system, a particular grammar that is of the required form, namely, the optimal, most highly valued system of the required form that is compatible with the presented data.](http://images.slideplayer.fr/3/1325024/slides/slide_10.jpg "Then what the language learner comes to know is that most highly valued system; it is that system that underlies the actual use of language by the person who has gained his knowledge..")
11
Chomsky Language and Mind A third task is that of determining just what it means for a hypothesis about the generative grammar of a language to be consistent with the data of sense. Notice that it is a great oversimplification to suppose that a child must discover a generative grammar that accounts for all the linguistic data that has been presented to him and that projects such data to an infinite range of potential sound-meaning relations….

12
Chomsky Language and Mind The task, then, is to study what we might think of as the problem of confirmation in this context, the problem of what relation must hold between a potential grammar and a set of data for this grammar to be confirmed as the actual theory of the language in question.

13
Equivalence Trouver la grammaire g dont sa complexité et sa confirmation par les données D sont maximales. Sous 2 conditions: 1.g assigne à chaque représentation engendrée une valeur p( g ) et 2.nous assignons une valeur a chaque grammaire g alors: g est la grammaire la plus probable, étant donné D.
 et 2.nous assignons une valeur a chaque grammaire g alors: g est la grammaire la plus probable, étant donné D..")
14
Une citation de Syntactic Structures, Noam Chomsky 1957 The strongest requirement that could be placed on the relation between a theory of linguistic structure and particular grammars is that the theory must provide a practical and mechanical method for actually constructing the grammar, given a corpus of utterances. Let us say that such a theory provides us with a discovery procedure.

15
corpus grammar

16
A weaker requirement would be that the theory must provide a practical and mechanical method for determining whether or not a grammar proposed for a given corpus is, in fact, the best grammar of the language from which the corpus is drawn (a decision procedure).
.")
17
corpus yes/no grammar

18
An even weaker requirement would be that given a corpus and given two proposed grammars G 1 and G 2, the theory must tell us which is the better grammar....an evaluation procedure.

19
"G 1 " or "G 2 " G1G1 G2G2 corpus

20
The point of view adopted here is that it is unreasonable to demand of linguistic theory that it provide anything more than a practical evaluation procedure for grammars. That is, we adopt the weakest of the three positions described above...

21
I think that it is very questionable that this goal is attainable in any interesting way, and I suspect that any attempt to meet it will lead into a maze of more and more elaborate and complex analytic procedures that will fail to provide answers for many important questions about the nature of linguistic structure. I believe that by lowering our sights….

22
lowering oursights to the more modest goal of developing an evaluation procedure for grammars we can focus attention more clearly on truly crucial problems...The correctness of this judgment can only be determined by the actual development and comparison of theories of these various sorts.

23
Notice, however, that the weakest of these three requirements is still strong enough to guarantee significance for a theory that meets it. There are few areas of science in which one would seriously consider the possibility of developing a general, practical, mechanical method for choosing among several theories, each compatible with the available data. Noam Chomsky, Syntactic Structures 1957

24
2. Lapprentissage automatique de la grammaire Plan général –Un corpus C –Une famille de grammaires possibles G –Une façon de mesurer la relation entre un corpus C et une grammaire particulière g: Complexité de g (indépendamment du corpus) La complexité du corpus selon grammaire g. Notre but est de minimiser la somme de ces deux éléments. ( MDL = Longueur de déscription minimale). Nous y revenons!
 La complexité du corpus selon grammaire g. Notre but est de minimiser la somme de ces deux éléments. ( MDL = Longueur de déscription minimale). Nous y revenons!.")
25
Plus contrètement: Une heuristique initiale (amorce) qui prend un corpus comme input et en crée une grammaire préliminaire (sans doute trop simple). Une série de heuristiques de modifie la grammaire. Une facon dappeler la mesure du slide précédent: est-ce que la modification est pour le meilleur? (MDL)
.")
26
Corpus Nous choississons un corpus naturel dune langue naturelle (5,000- 1,000,000 mots)
")
27
Corpus Heuristique amorce Nous introduisons le corpus à la heuristique bootstrap

28
Corpus Cela nous donne une morphologie, qui nest pas forcément très bonne. morphologie Heuristique amorce

29
Corpus Heuristiques incrémentieles Nous lenvoyons aux heuristiques incrémentielles. Heuristique amorce morphologie

30
Corpus Sortie: une morphologie modifiée Heuristique amorce morphologie Heuristiques incrémentieles morphologie modifiée

31
Corpus morphologie modifiée Est-ce que la modification est un amélioration? Notre expression MDL donne la réponse. Heuristique amorce morphologie Heuristiques incrémentieles

32
Corpus morphologie Sil sagit dune amélioration,elle remplace la vieille morphologie. Poubelle Heuristique amorce morphologie modifiée

33
Corpus Send it back to the incremental heuristics again... Heuristique amorce Heuristiques incrémentieles morphologie modifiée

34
morphologie Continuez jusquau moment où il nexiste plus daméliorations à tester. Heuristiques incrémentieles morphologie modifiée

35
Reprise Nous avons vu la méthode algorithmique. Pour chaque domaine linguistique, il nous faut préciser: 1.La heuristique amorce; 2.Les heuristiques incrémentielles; 3.Le modéle MDL (Longueur de déscription minimale).
..")
36
1. Lheuristique amorce Elle se fait en deux temps: A.Elle trouve des coupures potentielles en utilisant une suggestion de Zellig Harris. B.Elle acceptent une coupure potentielle si et seulement si elle fait partie dune signature propre.

37
Zellig Harris: successor frequency Successor frequency of jum : 2 jum p ( jump, jumping, jumps, jumped, jumpy ) b (jumble) Successor frequency of jump : 5 e (jumped) i (jumping) jumps (jumps) y (jumpy) # (jump)
 b (jumble) Successor frequency of jump : 5 e (jumped) i (jumping) jumps (jumps) y (jumpy) # (jump)")
38
Zellig Harris:Successor Frequency a c c e p t i n g 19 9 6 3 1 3 1 1 able ing lerate (accelerate) nted (accented) ident (accident) laim (acclaim) omodate (accomodate) reditated (accredited) used (accused) coupure prévue
 nted (accented) ident (accident) laim (acclaim) omodate (accomodate) reditated (accredited) used (accused) coupure prévue")
39
5 Zellig Harris: Successor frequency d a e i o 9 a b debate, debuting c decade, december, decide d dedicate, deduce, deduct e deep f edefeat, defend, defer ideficit, deficiency rdefraud ddead fdeaf ldeal ndean tdeath 18 3 prédictions fausses bonnes prédictions

40
Zellig Harris:Successor frequencies c o n s e r v a t i v e s 9 18 11 6 4 1 2 1 1 2 1 1 incorrecte correcteincorrecte

41
Problèmes Si 2+ suffixes commencent par le même phoneme/lettre: donn ais ait a donna is it NULL Analyse basée sur successor frequency

42
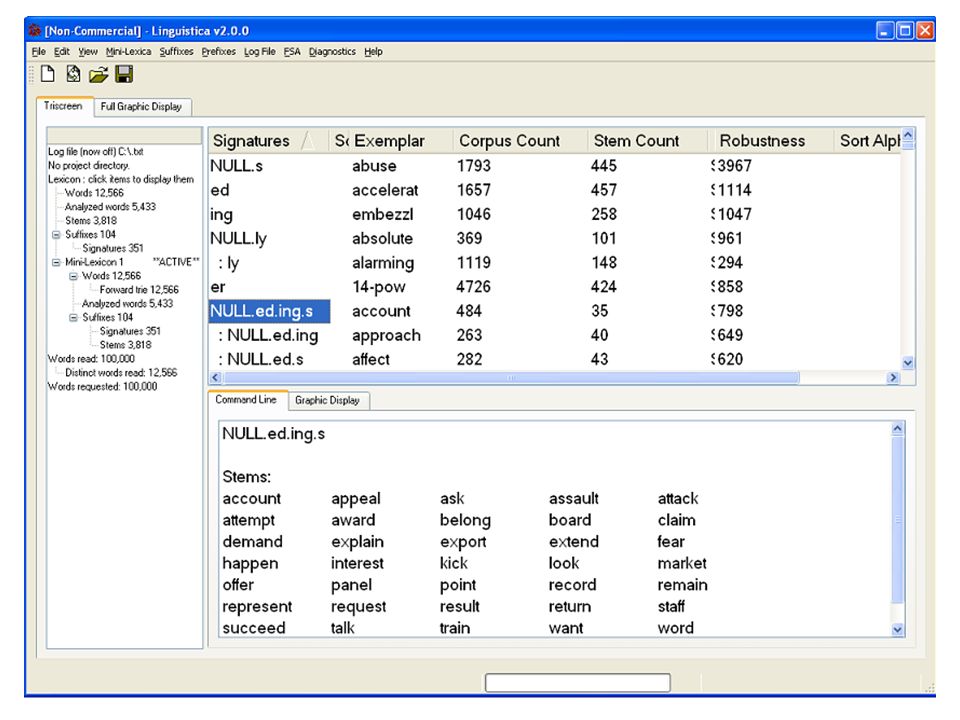
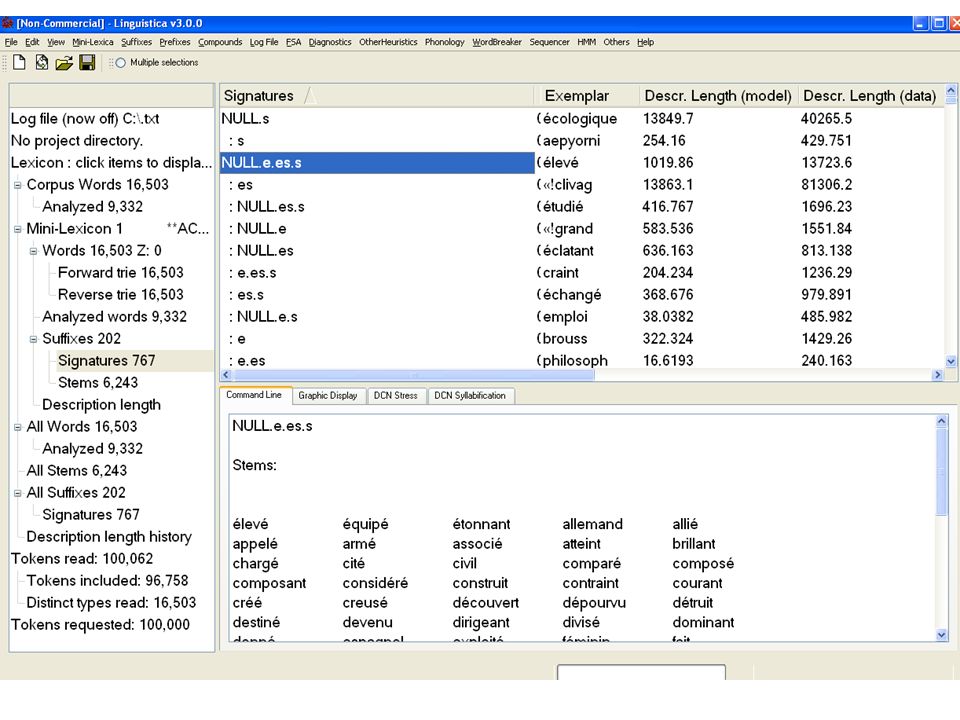
Amorce B: Signatures Nous acceptons la dernière coupure dans chaque mot: –Racine (potentiel) + suffixe (potentiel) Avec chaque racine (potentiel) nous associons lensemble de ses suffixes (potentiels):
 + suffixe (potentiel) Avec chaque racine (potentiel) nous associons lensemble de ses suffixes (potentiels):")
43
Signatures Toutes les racines qui possèdent le même ensemble de suffixes forment lensemble de racines dans une signature:

44
Finite state automaton (FSA) jump walk NULL ed ing
 jump walk NULL ed ing")
45
Signature propre Une signature propre contient au moins deux racines et au moins deux suffixes. Nous gardons (maintenant) seulement les signatures propres, et jetent les autres. (Certaines dentres elles vont revenir plus tard.)
 seulement les signatures propres, et jetent les autres. (Certaines dentres elles vont revenir plus tard.).")
46
Reprise Pour chaque domaine linguistique, il nous faut préciser: 1.La heuristique amorce; 2.Les heuristiques incrémentielles; 3.Le modéle MDL (Longueur de déscription minimale).
.")
47
Exemples Bientôt --

48
Reprise Pour chaque domaine linguistique, il nous faut préciser: 1.La heuristique amorce; 2.Les heuristiques incrémentielles; 3.Le modéle MDL (Longueur de déscription minimale).
.")
49
Modèle MDL La longueur de déscription se compose de deux termes: [La longueur de la grammaire, en bits ] + [La quantité dinformation dans le corpus qui nest pas expliquée totalement par la grammaire, en bits ] Ici, grammaire = morphologie
![Modèle MDL La longueur de déscription se compose de deux termes: [La longueur de la grammaire, en bits ] + [La quantité dinformation dans le corpus qui nest pas expliquée totalement par la grammaire, en bits ] Ici, grammaire = morphologie](http://images.slideplayer.fr/3/1325024/slides/slide_49.jpg "Modèle MDL La longueur de déscription se compose de deux termes: [La longueur de la grammaire, en bits ] + [La quantité dinformation dans le corpus qui nest pas expliquée totalement par la grammaire, en bits ] Ici, grammaire = morphologie")
50
[La longueur de la grammaire, en bits ] + [La quantité dinformation dans le corpus qui nest pas expliquée totalement par la grammaire, en bits ] Lidée centrale: une analyse extrait toujours des redondances. Par exemple…
![[La longueur de la grammaire, en bits ] + [La quantité dinformation dans le corpus qui nest pas expliquée totalement par la grammaire, en bits ] Lidée centrale: une analyse extrait toujours des redondances.](http://images.slideplayer.fr/3/1325024/slides/slide_50.jpg "Par exemple….")
51
Longueur de description (version naïve!) Corpus: jump, jumps, jumping laugh, laughed, laughing sing, sang, singing the, dog, dogs totale: 62 lettres Analyse: Racines : jump laugh sing sang dog (20 lettres) Suffixes : s ing ed (6 lettres) Non analysés : the (3 lettres) totale: 29 lettres.
 Corpus: jump, jumps, jumping laugh, laughed, laughing sing, sang, singing the, dog, dogs totale: 62 lettres Analyse: Racines : jump laugh sing sang dog (20 lettres) Suffixes : s ing ed (6 lettres) Non analysés : the (3 lettres) totale: 29 lettres.")
52
Pour decrire le corpus, il vaut mieux extraire un lexicon structuré, et décrire le corpus à travers la structure du lexicon.

53
Pourquoi minimiser ? Si la longueur de la grammaire est trop longue, on risque overfitting: la grammaire décrit le message, non pas le système qui a crée le message. Si la description des données est trop longue, on risque de ne pas avoir capté des généralisations inhérentes dans les données.

54
Essence of MDL…

55
Mesurer la longueur de la morphologie La morphologie est composée de trois composantes: 1.Une liste de racines 2.Une liste daffixes 3.Une list de signatures. Nous calculons dabord (1) et (2).
 et (2)..")
56
La longueur dune liste de morphèmes La longueur dune list (de longueur N) de morphèmes = –log N + longueur de chaque morphème ] La longueur dun morphème m: 1.log|m| + [-1 * log 2 freq de chaque lettre] 2.log |m| + [-1 * log 2 freq de chaque lettre, donné la lettre précédente] autrement dit:
![La longueur dune liste de morphèmes La longueur dune list (de longueur N) de morphèmes = –log N + longueur de chaque morphème ] La longueur dun morphème m: 1.log|m| + [-1 * log 2 freq de chaque lettre] 2.log |m| + [-1 * log 2 freq de chaque lettre, donné la lettre précédente] autrement dit:](http://images.slideplayer.fr/3/1325024/slides/slide_56.jpg "La longueur dune liste de morphèmes La longueur dune list (de longueur N) de morphèmes = –log N + longueur de chaque morphème ] La longueur dun morphème m: 1.log|m| + [-1 * log 2 freq de chaque lettre] 2.log |m| + [-1 * log 2 freq de chaque lettre, donné la lettre précédente] autrement dit:")
58
Mesurer la longueur de la morphologie La morphologie est composée de trois composantes: 1.Une liste de racines 2.Une liste daffixes 3.Une list de signatures. Nous calculons (3).
..")
59
Nous remplaçons chaque morphème par un pointeur au morphème, qui coûte moins cher (en bits). La longueur optimale dun pointeur est basé sa fréquence: -log 2 fréquence(m). Une signature consiste de deux listes de pointers, et nous sommes en mesure de tout mesurer:
. Une signature consiste de deux listes de pointers, et nous sommes en mesure de tout mesurer:.")
60
LInformation contenue dans toutes les signatures

61
Source plus profonde de MDL Le but de tout sysème rationel est de trouver le meilleur explication des observations. On interprète ceci dans un contexte probabiliste: Trouver lanalyse la plus probable, étant données les faits.

62
La règle de Bayes h = hypothèse; D = données. Trouver lhypothèse la plus probable = trouver celle dans le produit de sa probabilité et de la probabilité quelle donne aux données est maximale.

64
Probabilité dun mot m =pr(sig(m)) x pr(racine(m)|sig(m)) x pr(suffixe(m)|sig(m))
) x pr(racine(m)|sig(m)) x pr(suffixe(m)|sig(m))")
65
Nous pouvons maintenant regarder le fonctionnement de cet algorithme.

66
http://Linguistica.uchicago.edu
71
Conclusion Comment définir ce type danalyse linguistique? Aucun linguiste générative à lheure actuelle ne lidentifierait comme une analyse générative. Et pourtant… Cest une interprétation empiriste du programme original générativiste.

Présentations similaires