Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Additionneurs

2
Rappel sur l'écriture des entiers en base 2
Entiers positifs Entiers relatifs (complément à 2)
")
3
Additionneur "Full Adder" (FA)
Ai Bi Ci+1 Si = Ai Å Bi Å Ci Ci+1 = AiBi + AiCi + BiCi= majorité(Ai,Bi,Ci) Ci Ci+1 = AiBi + Ci ( Ai Å Bi) Si AiBiCi Ci+1 Si La somme pondérée de ce qui entre est égale à la somme pondérée de ce qui sort : Ai + Bi + Ci = Si + 2 * Ci+1
 Ci. Ci+1 = AiBi + Ci ( Ai Å Bi) Si. AiBiCi. Ci+1 Si La somme pondérée de ce qui entre est égale. à la somme pondérée de ce qui sort : Ai + Bi + Ci = Si + 2 * Ci+1.")
4
I- Additionneur à propagation de retenue
S = A + B A=A3 A2 A1A0 B=B3 B2 B1 B0 S=R S3 S2 S1S0 A0B0 A1B1 A2B2 A3B3 C0 C1 C2 C3 C4 S0 S1 S2 S3 Ci+1 = 1 si retenue Co=0 La retenue se propage à travers tous les étages Délai = O(n) Si = Ai Å Bi Å Ci Ci+1 = AiBi + AiCi + BiCi Ci+1 = AiBi + Ci ( Ai Å Bi)
 Si = Ai Å Bi Å Ci. Ci+1 = AiBi + AiCi + BiCi. Ci+1 = AiBi + Ci ( Ai Å Bi)")
5
II- Additionneur à sélection de retenue (carry select adder CSA)
Idée : on sélectionne la retenue sortante à l'aide de la retenue entrante La retenue entrante ne se propage pas à travers les FA on dispose de temps pour la calculer à mettre en poids fort (là où la retenue est en retard)
")
6
Cellule de CSA Si = Ai Å Bi Å Ci Ci+1 = AiBi + Ci ( Ai Å Bi)
")
7
Carry select adder CSA : Délai n1/2
1 t2 t3 t4 t5 t6 t1

8
Première cellule d'un bloc CSA
x 1 Ci+1 = AiBi + Ci ( Ai Å Bi) Retenue1 = AiBi + 0 ( Ai Å Bi) = AiBi Retenue2 = AiBi + 1 ( Ai Å Bi) = Ai+Bi
 Retenue1 = AiBi + 0 ( Ai Å Bi) = AiBi. Retenue2 = AiBi + 1 ( Ai Å Bi) = Ai+Bi.")
9
III Additionneur à retenue bondissante
Idée : Si Ai=Bi=0, Ci+1=0 : pas de retenue quelque soit Ci Si Ai=Bi=1, Ci+1=1 : il y a forcément une retenue, quelque soit Ci Si Ai≠Bi, , la retenue sortante de l’étage i est égale à la retenue entrante Par blocs de p bits : De même, la retenue sortante de l’étage i est égale à la retenue entrante si et seulement si les Apbits sont les inverses des Bpbits 01101 Cin Cin Somme Dans les autres cas, la retenue sortante peut être calculée indépendamment de la retenue entrante

10
calcule : (A0 B0).(A1 B1)…. (A7 B7)
Carry Skip ADDER Un bloc est constitué d’un additionneur à propagation de retenue et d’un « circuit » détectant si pour chaque bit i du bloc on a Ai≠Bi, Ai,Bi, i=23,…,16 Ai,Bi, i=15,…,8 Ai,Bi, i=7,…,0 & & & + + + Cn C0 P23 P15 P7 calcule : (A0 B0).(A1 B1)…. (A7 B7) & Temps de calcul : plus long temps de propagation d’une retenue : une retenue se propage depuis le rang i où elle est générée (et pour lequel Gi=1) jusqu’au rang où la retenue suivante est générée
.(A1 B1)…. (A7 B7) & Temps de calcul : plus long temps de propagation d’une retenue : une retenue se propage depuis le rang i où elle est générée (et pour lequel Gi=1) jusqu’au rang où la retenue suivante est générée.")
11
Carry Skip ADDER & & & + + + Cn C0 Remarques
les signaux ne servent pas pour calculer la retenue (que la somme) Les signaux peuvent être calculés en parallèle & & & + + + Cn C0 P23 P15 P7
 Les signaux peuvent être calculés en parallèle. & & & Cn. C0. P23. P15. P7.")
12
Carry Skip ADDER & & & + & + + + Temps de calcul Groupe 3 Groupe 2
pire cas : le retenue est générée au premier bloc, « saute » les blocs suivants et est générée au dernier bloc & & & + & + + + Groupe 3 Groupe 2 Groupe 1

13
Taille des blocs Hypothèse: Groupes de même taille k , m=n/k groupes , k et n/k entiers k sélectionné pour minimiser le temps de la plus longue chaîne de propagation temps de traversée d’un bloc de k additionneurs : t1*k temps de propagation à l'aide des comparateurs: t2 (comparaison + "et" + "ou") Temps total (pire cas) : 2*t1*k + (m-2)*t2 = 2* t1 * n/m + (m-2) * t2 Il suffit de déterminer où cette fonction est minimale.
 Temps total (pire cas) : 2*t1*k + (m-2)*t2 = 2* t1 * n/m + (m-2) * t2. Il suffit de déterminer où cette fonction est minimale.")
14
Carry Skip ADDER : taille des blocs
Sous hypothèse 1 : le temps de propagation à travers les comparateurs est constant soit f(x) : 2*t1*n/x + (x-2) * t2 minimum pour x0 = (2*n*t1/t2)1/2 f convexe sur R+ => m optimal : 2 valeurs entières qui encadrent x0 Temps total = O(n1/2) exemple : additionneur de 60 bits, t1=t2 => x0=1201/2=10,95 m = 10 ou m =12 10 blocs de 6 bits ou 12 blocs de 5 bits
 : 2*t1*n/x + (x-2) * t2. minimum pour x0 = (2*n*t1/t2)1/2. f convexe sur R+ => m optimal : 2 valeurs entières qui encadrent x0. Temps total = O(n1/2) exemple : additionneur de 60 bits, t1=t2 => x0=1201/2=10,95. m = 10 ou m = blocs de 6 bits ou 12 blocs de 5 bits.")
15
Carry Skip ADDER : taille des blocs
Hypothèse: Groupes de même taille k , m=n/k groupes , k et n/k entiers k sélectionné pour minimiser le temps de la plus longue chaîne de propagation Notations: tr - temps de propagation de la retenue sur un seul bit ts(k) – Temps pour sauter un groupe taille k (la plupart du temps - indépendant de k) tb – délai du "OU" entre 2 groupes Ttotal – temps total de propagation de la retenue – lorsque la retenue est générée à l'étage 0 et se propage jusqu'à l'étage n-1 La retenue se propage dans les étages 1,2, … ,k-1 du groupe 1, saute les groupes 2,3, … , (n/k-1), et se propage dans le groupe n/k
 – Temps pour sauter un groupe taille k (la plupart du temps - indépendant de k) tb – délai du OU entre 2 groupes. Ttotal – temps total de propagation de la retenue – lorsque la retenue est générée à l étage 0 et se propage jusqu à l étage n-1. La retenue se propage dans les étages 1,2, … ,k-1 du groupe 1, saute les groupes 2,3, … , (n/k-1), et se propage dans le groupe n/k.")
16
Carry Skip ADDER : taille des blocs
Ttotal=(k-1)tr+tb+(n/k-2)(ts+tb)+(k-1)tr Exemple - implémentation 2 niveaux tr = ts+tb = 2G (G = délai d'une porte) Ttotal=(4k+2n/k-7) G En dérivant Ttotal par rapport à k et en égalisant à 0 - kopt = n/2 Taille des groupes et temps de propagation de la retenue proportionnel à n - idem carry-select adder Exemple : n=32, 8 groupes de taille kopt = 4 est la meilleure solution Topt=25G au lieu 62G pour un additionneur à propagation de retenue
tr+tb+(n/k-2)(ts+tb)+(k-1)tr. Exemple - implémentation 2 niveaux. tr = ts+tb = 2G (G = délai d une porte) Ttotal=(4k+2n/k-7) G. En dérivant Ttotal par rapport à k et en égalisant à 0 - kopt = n/2. Taille des groupes et temps de propagation de la retenue proportionnel à n - idem carry-select adder. Exemple : n=32, 8 groupes de taille kopt = 4 est la meilleure solution. Topt=25G au lieu 62G pour un additionneur à propagation de retenue.")
17
Accélération Taille du premier et dernier groupe plus petite que la taille fixée k – le temps de propagation de la retenue dans ces groupes réduit Taille des groupes centraux augmentée – puisque le temps de "saut" est à peu près indépendant de la taille du groupe Autre approche : ajouter un second niveau pour permettre le saut de deux ou plusieurs groupes en une étape (plus de 2 niveaux possible) Algorithmes existant pour déterminer les taille de groupes optimales pour différentes technologies et implantations (càd différentes valeurs du ratio (ts+tb)/tr)
 Algorithmes existant pour déterminer les taille de groupes optimales pour différentes technologies et implantations (càd différentes valeurs du ratio (ts+tb)/tr)")
18
Groupes de taille variable
A l'inverse du cas des groupes constants – on ne peut se restreindre à l'analyse du pire cas de la propagation de la retenue Peut mener à la conclusion triviale : le premier et le dernier groupe composé d'un seul étage (1 bit) – les n-2 étages restants constituant un seul groupe central La retenue générée au début du groupe central peut se propager à travers les autre n-3 étages – et par là devenant le pire cas On doit donc considérer toutes les chaînes de retenue démarrant à n'importe quelle position arbitraire de bit a (avec xa=ya) et s'arrêtant à b (xb=yb), position à laquelle une nouvelle chaîne de retenue (indépendante de la précédente) commence. (X et Y opérandes)
 – les n-2 étages restants constituant un seul groupe central. La retenue générée au début du groupe central peut se propager à travers les autre n-3 étages – et par là devenant le pire cas. On doit donc considérer toutes les chaînes de retenue démarrant à n importe quelle position arbitraire de bit a (avec xa=ya) et s arrêtant à b (xb=yb), position à laquelle une nouvelle chaîne de retenue (indépendante de la précédente) commence. (X et Y opérandes)")
19
Optimiser les taille de groupe
k1, k2, … , kL – tailles des L groupes – avec Cas général : Chaîne commençant dans le groupe u, finissant dans le groupe v, sautant les groupes u+1, u+2, … ,v-1 Pire cas - retenue générée à la première position dans u et finissant dans la dernière position dans v Le temps de propagation de la retenue est : Nombre de groupes L et tailles k1, k2, …, kL sélectionnées de telle façon que la plus longue chaîne de propagation de la retenue soit minimale Solutions algorithmiques développées - programmation dynamique

20
Optimisation - Exemple
additionneur 32-bit avec un seul niveau de saut ts+tb=tr Organisation optimale - L=10 groupes de taille k1,k2,…,k10 = 1,2,3,4,5,6,5,3,2,1 Résultat Tcarry 9 tr Si tr=2 G - Tcarry 18 G au lieu 25 G pour des groupes de taille égale Exercice: Montrer que toute paire de position de bits dans deux groupes quelconques u et v ( 1 u v 10 ) satisfait Tcarry(u,v) 9 tr
 satisfait. Tcarry(u,v) 9 tr.")
21
IV- Additionneur à retenue anticipée (Carry Look-Ahead : CLA)
L'inconvénient des structures précédentes est le temps nécessaire à la réalisation de l'addition. Ce temps est en effet conditionné par la propagation de la retenue à travers tous les additionneurs élémentaires. Dans un additionneur à retenue anticipée on évalue en même temps la retenue de chaque étage. Pour cela on détermine pour chaque étage les quantités Pi et Gi suivantes: pi = ai Å bi (propagation d'une retenue) gi = ai.bi (génération d'une retenue)
 gi = ai.bi (génération d une retenue)")
22
Additionneur à retenue anticipée : CLA
pi= ai Å bi (propagation d'une retenue) gi = ai.bi (génération d'une retenue) La retenue entrante à l'ordre i vaut 1 si : - soit l'étage i-1 a généré la retenue (gi-1 = 1) - soit l'étage i-1 a propagé la retenue générée à l'étage i-2 (pi-1=1 et gi-2=1) - soit les étages i-1 et i-2 ont propagé la retenue générée à l'étage i (pi-1=pi-2=1 et gi-3=1) soit tous les étages inférieurs ont propagé la retenue entrante dans l'additionneur (pi-1=pi-2=...=p0=c0=1). ci = gi-1 + pi-1.gi-2 + pi-1.pi-2.gi pi-1.pi-2.pi-3....p0.c0 c1 = g0 + p0.c0 c2 = g1 + p1.g0 + p1.p0.c0 c3 = g2 + p2.g1 + p2.p1.g0 + p2.p1.p0.c0 c4 = g3 + p3.g2 + p3.p2.g1 + p3.p2.p1.g0 + p3.p2.p1.p0.c0
 gi = ai.bi (génération d une retenue) La retenue entrante à l ordre i vaut 1 si : - soit l étage i-1 a généré la retenue (gi-1 = 1) - soit l étage i-1 a propagé la retenue générée à l étage i-2 (pi-1=1 et gi-2=1) - soit les étages i-1 et i-2 ont propagé la retenue générée à l étage i-3 (pi-1=pi-2=1 et gi-3=1) soit tous les étages inférieurs ont propagé la retenue entrante dans l additionneur (pi-1=pi-2=...=p0=c0=1). ci = gi-1 + pi-1.gi-2 + pi-1.pi-2.gi pi-1.pi-2.pi-3....p0.c0. c1 = g0 + p0.c0 c2 = g1 + p1.g0 + p1.p0.c0 c3 = g2 + p2.g1 + p2.p1.g0 + p2.p1.p0.c0 c4 = g3 + p3.g2 + p3.p2.g1 + p3.p2.p1.g0 + p3.p2.p1.p0.c0.")
23
Additionneur à retenue anticipée
pi= ai Å bi (propagation d'une retenue) gi = ai.bi (génération d'une retenue) Si = ai Å bi Å ci = pi Å ci ci = gi-1 + pi-1.gi-2 + pi-1.pi-2.gi pi-1.pi-2.pi-3....p0.c0
 gi = ai.bi (génération d une retenue) Si = ai Å bi Å ci = pi Å ci. ci = gi-1 + pi-1.gi-2 + pi-1.pi-2.gi pi-1.pi-2.pi-3....p0.c0.")
24
Additionneur à retenue anticipée
b3 a3 b2 a2 b1 a1 b0 a0 g.p. g.p. g.p. g.p. p3 g3 p2 g2 p1 g1 p0 g0 c4 C.L.U. c0 p3 c3 p2 c2 p1 c1 p0 s3 s2 s1 s0 Si = pi Å ci CLU : Carry Look-ahead Unit

25
Bloc g.p. pi= ai Å bi (propagation d'une retenue)
gi = ai.bi (génération d'une retenue) ai bi pi gi
 ai. bi. pi. gi.")
26
Bloc CLU ci = gi-1 + pi-1.gi-2 + pi-1.pi-2.gi pi-1.pi-2.pi-3....p0.c0 p3 g3 p2 g2 p1 g1 p0 g0 c0 c4 c3 c2 c1 Délai : 2 portes

27
C.L. Adder (n>4) En pratique : n = 4 Pour n >4 :
Arbre de C.L.A multi-niveau (au détriment de la vitesse) a11 b11 a10 b10 a9 b9 a8 b8 a7 b7 a6 b6 a5 b5 a4 b4 a3 b3 a2 b2 a1 b1 a0 b0 c0 c12 c8 c4
 a11. b11. a10. b10. a9. b9. a8. b8. a7. b7. a6. b6. a5. b5. a4. b4. a3. b3. a2. b2. a1. b1. a0. b0. c0. c12. c8. c4.")
28
V- Génération et propagation de groupe
Soient gi , pi , Pi,j , Gi,j définis de la façon suivante : Gi,i = gi = ai . bi : génération au rang i Pi,i = pi = ai Å bi : propagation au rang i Gi,k = Gi,j + Pi,j .Gj-1,k : génération du rang k au rang i (n>i≥j≥k≥0) Pi,k = Pi,j .Pj-1,k : propagation du rang k au rang i ci+1 = Gi,0 + Pi,0 . c0 : retenue au rang i+1 que l'on cherche à obtenir Si = ai Å bi Å ci = pi Å ci = pi Å Gi-1,0 et S0 =p0 Å c0
 Pi,k = Pi,j .Pj-1,k : propagation du rang k au rang i. ci+1 = Gi,0 + Pi,0 . c0 : retenue au rang i+1 que l on cherche à obtenir. Si = ai Å bi Å ci = pi Å ci = pi Å Gi-1,0 et S0 =p0 Å c0.")
29
Cellule de Brent et Krung
n ≥ i ≥ j ≥ k ≥ 1 Pi,k Pi,j Pj-1,k Gi,k Gi,j Pi,j Gj-1,k Pi,j Gi,j Pj-1,k Gj-1,k Pi,k Gi,k Gi,k = Gi,j + Pi,j .Gj-1,k Pi,k = Pi,j .Pj-1,k Gi,i = gi Pi,i = pi Propriétés : La cellule est associative => nombreux assemblages possibles Règle d’assemblage : toute sortie de rang i dépend des entrées des rangs 0 à i La cellule est non commutative

30
Calcul arborescent de la retenue de sortie
3,2 5,4 7,6 9,8 11,10 13,12 15,14 7,4 11,8 15,12 15,8 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 Le calcul des autres retenues peut-être fait : - 1 à coût minimum, - 2 rapide à fanout variable, - 3 rapide à fanout fixe ci+1 = Gi,0 + Pi,0 . c0 Si = pi Å Gi-1,0

31
Additionneur Brent & Kung en temps log2(n)+2
calcul pi et gi Gi C16 si = pi Gi-1,0

32
Additionneur de Brent & Kung
temps

33
Règles de construction
Il y a une seule règle de construction des arbres imbriqués de cellules "BK" : Toute retenue ci de rang i est reliée à toutes les entrées de rang j < i par un arbre binaire planaire de cellules "BK". Cela permet d'entrelacer les arbres des n sorties de très nombreuses façons en fonction du nombre de bits et du délai de l'additionneur. Ce délai va de (n-1) à log2(n), bornes comprises.
 à log2(n), bornes comprises.")
34
Additionneur de Brent & Kung modifié
G14,0 = G14,14 + P14,14 .G13,0 Modification de Fishburn (1990) : une cellule de plus mais réduction de 6 à 5 G14,0= G14,12+ P14,12 .G11,0 G14,12= G14,14+ P14,14 .G13,12
 : une cellule de plus mais réduction de 6 à 5. G14,0= G14,12+ P14,12 .G11,0. G14,12= G14,14+ P14,14 .G13,12.")
35
Additionneur de Sklansky en temps log2(n)
Délai : log2(n) contre log2(n)+2 Nombre de celules : 32 contre 27
 contre log2(n)+2. Nombre de celules : 32 contre 27.")
36
Additionneur en temps (n1/2)
")
37
Additionneur en temps (n1/3)
")
38
Exercice

39
Additionneur de Ling (1981)
ki = le retenue a été tuée au rang i = ai' . bi' Remarque : gi = k'i gi Calcul de la 6ième retenue S6 = p6 Å G5,0 G5,0 = G5,3 + P5,3 G2,0 G5,3 = g5 + k'5 g4 + k'5k'4 g3 G2,0 = g2 + k'2 g1 + k'2k'1 g0 P5,3 = k'5k'4 k'3 Le délai de S6 est déterminé par G5,0 dont tous les termes contiennent k'5 sauf le premier . Or g5 = k'5 g5. On met k'5 en facteur : S6 = p6 Å k'5 H5,0 (Hi,0 pseudo-retenue au rang i) H5,0 = H5,3 + Q5,3 H2,0 H5,3 = g5 + g4 + k'4 g3 H2,0 = g2 + g1 + k'1 g0 Q5,3 = k'4 k'3 k'2
 H5,0 = H5,3 + Q5,3 H2,0. H5,3 = g5 + g4 + k 4 g3. H2,0 = g2 + g1 + k 1 g0. Q5,3 = k 4 k 3 k 2.")
40
Additionneur de Ling Pour S6 on précalcule p6 et p6 Å k'5
G5,3 = g5 + k'5 g4 + k'5k'4 g3 = a5b5 + (a5+b5)a4b4 + (a5+b5) (a4+b4)a3b3 H5,3 = g5 + g4 + k'4 g3 = a5b5 + a4b4 + (a4+b4)a3b3 H5,3 est plus rapide à calculer que G5,3
a4b4 + (a5+b5) (a4+b4)a3b3. H5,3 = g5 + g4 + k 4 g3 = a5b5 + a4b4 + (a4+b4)a3b3. H5,3 est plus rapide à calculer que G5,3.")
41
Additionneurs Parallèles
But : éviter la propagation de la retenue Astuce : coder les chiffres sur 2 bits Le résultat est la somme de l'addition et de la retenue de l'étage précédent codage : 0 : 00, 1 : 01 ou 10, 2 : 11 Exemple : (13)10= 1*23+1*22+0*21+1*20 = >1101 en binaire naturel => en CS = 1*23+0*22+2*21+1*20 = > en CS
10= 1*23+1*22+0*21+1*20 = >1101 en binaire naturel. => en CS. = 1*23+0*22+2*21+1*20. = > en CS.")
42
Cellule CS (Carry-Save)
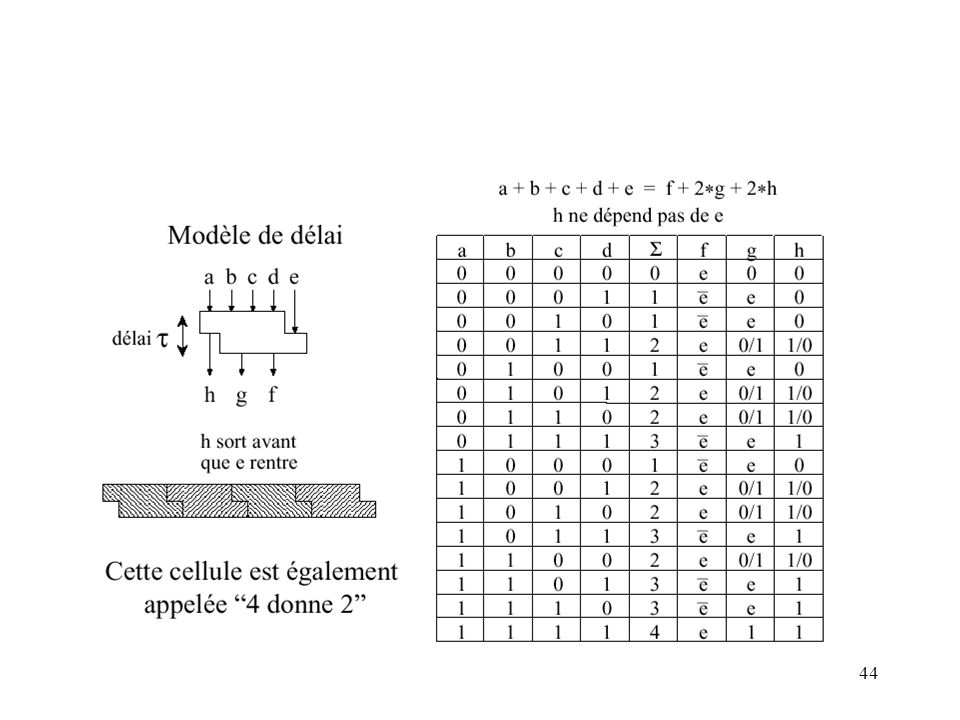
somme pondérée des sorties = somme pondérée des entrées a + b + c + d + e = 2*h + 2*g + f CS a b c d e h g f La sortie "h" ne dépend pas de l'entrée "e". h : retenue pour le bit suivant g : partie du résultat pour le bit suivant Chaque chiffre est maintenant représenté sur 2 bits la valeur du chiffre est la somme de ces deux bits. Les valeurs possibles des chiffres "CS" sont donc '0', '1' et '2' .

43
Additionneur parallèle CS
b2 a1 b1 a0 b0 CS CS CS g f g f g f s0 s2 s1

45
Table de vérité a + b + c + d + e = 2*h + 2*g + f h = majorité (a,b,c)
g = majorité (somme(a,b,c),d,e) f = (somme (a,b,c,d,) e ) = somme (a,b,c,d,e)
,d,e) f = (somme (a,b,c,d,) e ) = somme (a,b,c,d,e)")
46
Implantation : additionneur parallèle CS
h = majorité (a,b,c) g = majorité (somme(a,b,c),d,e) FA a b c d h g f e f = somme (a,b,c,d,e)
 g = majorité (somme(a,b,c),d,e) FA. a. b. c. d. h. g. f. e. f = somme (a,b,c,d,e)")
47
Additionneur parallèle
ai {0,1,2} Codage : ai:{ai1,ai2} / ai1+a12 = ai 0 : 00 1 : 01 ou 10 2 : 11 CS

48
Implantation Cellule CS (Carry-Save)
")
49
Variantes

50
Additionneurs de réels

51
Nombre réels Codage des réels : virgule flottante
flottant stocké sous la forme M * BE M : Mantisse ; B : Base ; E : Exposant exemple : = Représentation IEEE 754, base 2 (signe 1 bit, exposant et mantisse sur 32 ou 64 bits pour simple et double précision) SM : signe de la mantisse : 1 bit Eb : exposant biaisé : 8 ou 11 bits M : Mantisse : 23 ou 52 bits SM Eb M
 SM : signe de la mantisse : 1 bit. Eb : exposant biaisé : 8 ou 11 bits. M : Mantisse : 23 ou 52 bits. SM. Eb. M.")
52
Mantisse et exposant Signe : bit de poids fort (0 = + ; 1 = -)
placé avant la mantisse pour simplifier les comparaisons (pour ceci il ne doit pas être représenté en complément à deux : 2-1 > 2) sur 8 bits : sans signe mais biaisé de 127 (on enlève 127) : Eb = 0 ⇒ E = 0 – 127 = -127 Eb = 255 ⇒ E = 255 – 127 = 128 Remarque : E>0 si et seulement si le bit de poids fort de Eb =1 Mantisse normalisée : bit de poids fort n’est pas 0 et un seul chiffre avant la virgule ex : 3,2510 =11,01 = 1,101 * 21
 sur 8 bits : sans signe mais biaisé de 127 (on enlève 127) : Eb = 0 ⇒ E = 0 – 127 = Eb = 255 ⇒ E = 255 – 127 = 128. Remarque : E>0 si et seulement si le bit de poids fort de Eb =1. Mantisse. normalisée : bit de poids fort n’est pas 0 et un seul chiffre avant la virgule. ex : 3,2510 =11,01 = 1,101 * 21.")
53
Virgule Flottante Mantisse : Comme le bit de poids fort de la mantisse est nécessairement 1, on ne l’indique pas (gaspillage de place). Il est implicite partie fractionnaire = f1f2 …fn ⇒ m = 1,f1f2…fn nombre x = (-1)SM * 1,M * 2Eb-127 Exemple x = (-2,5)10 = (-1,01*21)2 SM = 1 ; E= 1 => Eb= 128 = ; m=1,01 => M = 010…….0 1 010……0
. Il est implicite. partie fractionnaire = f1f2 …fn ⇒ m = 1,f1f2…fn. nombre x = (-1)SM * 1,M * 2Eb-127. Exemple. x = (-2,5)10 = (-1,01*21)2. SM = 1 ; E= 1 => Eb= 128 = ; m=1,01 => M = 010…… ……0.")
54
Exemple : 452, ,5 452,5= A= *28 117,5= B= *26 452,5= A= *28 B= *28 117,5= A+B = *28 = *29

55
Addition virgule flottante
Les réels étant codés en "signe/valeur absolue", un seul opérateur pour addition et soustraction (Cmpà1 +1 si signes dif.) Exposant du résultat : exposant du + grand (voir la suite) Déroulement de l'addition alignement des mantisses si les exposants sont dif. addition ou soustraction des mantisses alignées renormalisation de la mantisse de la somme S (si elle n'est pas normalisée) => modif de l'exposant arrondi de la mantisse
 Exposant du résultat : exposant du + grand (voir la suite) Déroulement de l addition. alignement des mantisses si les exposants sont dif. addition ou soustraction des mantisses alignées. renormalisation de la mantisse de la somme S (si elle n est pas normalisée) => modif de l exposant. arrondi de la mantisse.")
56
Exemple : 452,5+117,5 452,5= A= *28 B= *26 117,5= Alignement des mantisses B= |00*28 Addition des mantisses alignées A= *28 +B= *28 S= *28 Normalisation de la mantisse S'= *29 Arrondi de la mantisse S'= *29

57
Alignement des mantisses
Par décalage de p bits La valeur p du décalage est donnée par la différence des exposants. Dans l'exemple 8-6 =2 . Décalage de 2 bits. La valeur max de décalage est 23 , la différence est codée sur 5 bits

58
Architecture : huit blocs
Bloc 1: entrent les deux exposants, sort plus grand exposant (8 bits), sort la valeur absolue de la différence des exposants (5 bits), sort le bit implicite du plus petit opérande et le bit implicite du plus grand opérande. Bloc 2: entrent les deux mantisses, sort à gauche la mantisse du plus petit opérande (23 bits), sort à droite la mantisse du plus grand opérande (23 bits). Commande le mux du signe résultat (signe du plus grand). Décaleur 1: décale vers la droite la mantisse du plus petit, conserve un "bit de garde" et un "bit d'arrondi" et ajoute un "bit collant"; total 27 bits. Complémenteur: fait sur commande le complément logique en vue d'une soustraction. Additionneur 1: additionne les deux mantisses alignées et la retenue, sort un résultat arrondi et une retenue, en tout 28 bits (dont 2 avant la virgule et 5 servant à l'arrondi dont 2 perdus). Compteur de zéros en tête: la sortie ZLC compte le nombre de '0' en poids forts ou vaut 1 si le comptage est inhibé. Décaleur 2: décale vers la gauche de ( ZLC – 2 ) positions (de 2 positions à droite jusqu'à 23 positions à gauche). Sort la mantisse du résultat, le bit sortant poids fort est perdu (bit '1' implicite si normalisé). Additionneur 2: soustrait ( ZLC – 1 ) du plus grand exposant. Sort l'exposant du résultat.
, sort la valeur absolue de la différence des exposants (5 bits), sort le bit implicite du plus petit opérande et le bit implicite du plus grand opérande. Bloc 2: entrent les deux mantisses, sort à gauche la mantisse du plus petit opérande (23 bits), sort à droite la mantisse du plus grand opérande (23 bits). Commande le mux du signe résultat (signe du plus grand). Décaleur 1: décale vers la droite la mantisse du plus petit, conserve un bit de garde et un bit d arrondi et ajoute un bit collant ; total 27 bits. Complémenteur: fait sur commande le complément logique en vue d une soustraction. Additionneur 1: additionne les deux mantisses alignées et la retenue, sort un résultat arrondi et une retenue, en tout 28 bits (dont 2 avant la virgule et 5 servant à l arrondi dont 2 perdus). Compteur de zéros en tête: la sortie ZLC compte le nombre de 0 en poids forts ou vaut 1 si le comptage est inhibé. Décaleur 2: décale vers la gauche de ( ZLC – 2 ) positions (de 2 positions à droite jusqu à 23 positions à gauche). Sort la mantisse du résultat, le bit sortant poids fort est perdu (bit 1 implicite si normalisé). Additionneur 2: soustrait ( ZLC – 1 ) du plus grand exposant. Sort l exposant du résultat.")
59
Architecture 452,5+117,5 Bloc1 Bloc2 Décal.1 Compl. Addit. 1
Compt. zéros Décal.2 Addit. 2 voir :

60
Multiplieurs

61
Multiplication binaire
1 2 * 1 3 3 6 1 5 6 Multiplicande Multiplieur Produit partiel Produit partiel Produit partiel Produit partiel

62
Multiplieur A3 A2 A1 A0 * B3 B2 B1 B0 A3 B0 A2B0 A1B0 A0B0 PP1 PP2
P = A * B A=A3 A2 A1A0 B=B3 B2 B1 B0 P=P7P6P5P4P3 P2 P1P0 A A A A0 * B B B B0 A3 B0 A2B0 A1B0 A0B0 PP1 PP2 PP3 PP4 A3 B1 A2B1 A1B1 A0B1 A3 B2 A2B2 A1B2 A0B2 + Ri Ai-1 Bj Ri+1 A3 B3 A2B3 A1B3 A0B3 P P P P P P P P0 PP1 + PP2 = R1 => R1 + PP3 = R2 => R2 + PP4 = P

63
Multiplieur B0 B1 + B2 B3 P7 P6 P5 P4 P3 P2 P1 P0 A3 B0 A2B0 A1B0 A0B0
A3 B2 A2B2 A1B2 A0B2 A3 B3 A2B3 A1B3 A0B3

64
25 adders, chemin critique 13 adders
Multiplieur naïf (5 x 6) 25 adders, chemin critique 13 adders
 25 adders, chemin critique 13 adders.")
65
24 adders, chemin critique 9 adders
Multiplieur amélioré Tous les chiffres d'un même colonne ont même poids. En jouant sur : - l'associativité et la commutativité de l'addition - sur le fait que l'on ajoute des 0 sur la première couche diagonale on peut réduire le chemin critique 24 adders, chemin critique 9 adders

66
Avec P0= A0B0, P1=A1B0+A0B1, P2 = A2B0+A1B1+A0B2, etc…
Multiplieur de Braun A A A A A0 * B B4 B B B B0 A4B0 A3 B0 A2B0 A1B0 A0B0 A4B1 A3B1 A2B1 A1B1 A0B1 A4B2 A3B2 A2B2 A1B2 A0B2 A4B3 A3B3 A2B3 A1B3 A0B3 A4B4 A3B4 A2B4 A1B4 A0B4 A4B5 A3B5 A2B5 A1B5 A0B5 P P P P P P P P P P0 Avec P0= A0B0, P1=A1B0+A0B1, P2 = A2B0+A1B1+A0B2, etc…

67
24 adders, chemin critique 9 adders
Multiplieur de Braun 24 adders, chemin critique 9 adders

68
Multiplication Signée (complément à 2)
")
69
Multiplieur séquentiel 1
Avec addition de A sur le ième bit (A) (B) R2R Initialisation de R1 et R2 +A* b0=1 => on ajoute A* R2R Décalage de B => B=(0101) +A* b0=1 => on ajoute A* R2R Décalage de B => B=(0010) +0* b0=0 => on ajoute 0* R2R Décalage de B => B=(0001) +A* b0=1 => on ajoute A* R2R Fin
 1110 (B) R2R Initialisation de R1 et R2 +A* b0=1 => on ajoute A* R2R Décalage de B => B=(0101) +A* b0=1 => on ajoute A* R2R Décalage de B => B=(0010) +0*22 b0=0 => on ajoute 0* R2R Décalage de B => B=(0001) +A* b0=1 => on ajoute A* R2R Fin.")
70
Multiplieur séquentiel 2
Avec addition de A sur les poids forts et décalage (A) (B) R3R2R Initialisation de R3 R2 R1 +A b0=1 => (R2 + A -> R3R2) R3R2R Décalage de R3R2R1 R3R2R Décalage de B => B=(0101) +A b0=1 => (R2 + A -> R3R2) R3R2R Décalage de R3R2R1 R3R2R Décalage de B => B=(0010) b0=0 => (R > R3R2) R3R2R Décalage de R3R2R1 R3R2R Décalage de B => B=(0001) +A b0=1 => (R2 + A -> R3R2) R3R2R Décalage de R3R2R1 R3R2R Fin A la ième itération : n-i bits à 0 et n-i bits utiles dans B
 1110 (B) R3R2R Initialisation de R3 R2 R1 +A 1110 b0=1 => (R2 + A -> R3R2) R3R2R Décalage de R3R2R1 R3R2R Décalage de B => B=(0101) +A 1110 b0=1 => (R2 + A -> R3R2) R3R2R Décalage de R3R2R1 R3R2R Décalage de B => B=(0010) b0=0 => (R > R3R2) R3R2R Décalage de R3R2R1 R3R2R Décalage de B => B=(0001) +A 1110 b0=1 => (R2 + A -> R3R2) R3R2R Décalage de R3R2R1 R3R2R Fin. A la ième itération : n-i bits à 0 et n-i bits utiles dans B.")
71
Multiplieur séquentiel 3
(A) R3 R2 R Initialisation de R3R2R1 (B->R1) +A b0(R1)=1 => (R2 + A -> R3R2) R3 R2 R Décalage de R3R2R1 R3 R2 R b0(R1)=1 => (R2 + A -> R3R2) A R3 R2 R Décalage de R3R2R1 R3 R2 R b0(R1)=0 => (R > R3R2) R3 R2 R Décalage de R3R2R1 R3 R2 R b0(R1)=1 => (R2 + A -> R3R2) A R3 R2 R Décalage de R3R2R1 R3 R2 R Fin
 R3 R2 R Initialisation de R3R2R1 (B->R1) +A 1110 b0(R1)=1 => (R2 + A -> R3R2) R3 R2 R Décalage de R3R2R1 R3 R2 R b0(R1)=1 => (R2 + A -> R3R2) +A R3 R2 R Décalage de R3R2R1 R3 R2 R b0(R1)=0 => (R > R3R2) R3 R2 R Décalage de R3R2R1 R3 R2 R b0(R1)=1 => (R2 + A -> R3R2) +A R3 R2 R Décalage de R3R2R1 R3 R2 R Fin.")
72
Multiplieur séquentiel 4
architecture SHIFT_MULT of MULT is A_PORT B_PORT begin process variable A,B,M : BIT_VECTOR; START variable COUNT : INTEGER; begin wait until (START=1); CLK B:=B_PORT; COUNT:=0; A:=A_PORT; DONE<='0'; M:=b"00000"; M_OUT DONE while (COUNT<4) loop if (B(0) = ‘1’) M:=M+A; entity MULT is endif; PORT( B:=SHR(B,M(0)); A_PORT,B_PORT : in bit_vector(3 downto 0); M:=SHR(M,'0'); Product : out bit_vector(7 downto 0); COUNT:=COUNT+1; CLK : in CLOCK. endloop; START : in BIT; Product<=M&B; DONE : out BIT; DONE<='1' ); endprocess; end MULT; end SHIFT_MULT;
; CLK. B:=B_PORT; COUNT:=0; A:=A_PORT; DONE<= 0 ; M:=b ; M_OUT. DONE. while (COUNT<4) loop. if (B(0) = ‘1’) M:=M+A; entity MULT is. endif; PORT( B:=SHR(B,M(0)); A_PORT,B_PORT : in bit_vector(3 downto 0); M:=SHR(M, 0 ); Product : out bit_vector(7 downto 0); COUNT:=COUNT+1; CLK : in CLOCK. endloop; START : in BIT; Product<=M&B; DONE : out BIT; DONE<= 1 ); endprocess; end MULT; end SHIFT_MULT;")
73
Description structurelle
B_PORT A_PORT S1&COUNT<4 S2&~(B(0)=1) Mux1 Mux2 Control Unit S0&START=1 S0&~(START=1) S1&~(COUNT<4) S2&B(0)=1 S3 Count_Reg Mux1 1 M_Reg Mux2 1 Mux3 1 A_reg Mux4 B_Reg Load A_Reg 1 1 Load B_Reg 1 0001 Clear Count_Reg 1 Load Count_Reg 1 Clear Mult 1 M(0) Load Mult 1 1 Adder 1 1 Schift 1 1 Shift1 Shift2 Mux3 Mux4 Schift 2 1 DONE 1 Next State 1 2 3 3 1 Concat Adder 0100 State Reg Comp B_reg(0) CLK DONE Compar.LT Product
=1) Mux1. Mux2. Control Unit. S0&START=1. S0&~(START=1) S1&~(COUNT<4) S2&B(0)=1. S3. Count_Reg. Mux1. 1. M_Reg. Mux2. 1. Mux3. 1. A_reg. Mux4. B_Reg. Load A_Reg Load B_Reg Clear Count_Reg. 1. Load Count_Reg. 1. Clear Mult. 1. M(0) Load Mult Adder Schift Shift1. Shift2. Mux3. Mux4. Schift DONE. 1. Next State Concat. Adder State Reg. Comp. B_reg(0) CLK. DONE. Compar.LT. Product.")
74
Synthèse contrôle S0 S1 S2 S3 Start = 0 Start = 1 / Count = 4 /
A:=A_PORT; B:=B_PORT; Start = 1 / COUNT:=0; DONE:='0'; M:="00000"; Count = 4 / S1 DONE:='1'; Count < 4 S2 B(0) = 1 / M:=M+A B:=SHR(B,M(0)); B(0) 1 M:=SHR(M,'0'); COUNT:=COUNT+1; S3
 = 1 / M:=M+A. B:=SHR(B,M(0)); B(0) 1. M:=SHR(M, 0 ); COUNT:=COUNT+1; S3.")
75
Synthèse contrôle Etat Présent CONDITION VALEUR ACTIONS Etat Futur
A:=A_PORT; T B:=B_PORT; COUNT:=0; S1 S0 START=1 DONE:='0'; M:="00000"; F S0 T S2 S1 COUNT<4 F S0 DONE:='1'; T M:=M+A S3 S2 B(0)=1 F S3 B:=SHR(B,M(0)); S3 M:=SHR(M,'0'); S1 COUNT:=COUNT+1;
=1. F. S3. B:=SHR(B,M(0)); S3. M:=SHR(M, 0 ); S1. COUNT:=COUNT+1;")
76
Synthèse contrôleur Chemin de données Start State Reg Compar.LT
S1&~(COUNT<4) S0&START=1 S1&COUNT<4 S2&~(B(0)=1) S2&B(0)=1 S3 Mux1 1 Mux2 1 Mux3 1 Mux4 Load A_Reg 1 1 Chemin de données Load B_Reg 1 Clear Count_Reg 1 Load Count_Reg 1 Clear Mult 1 Load Mult 1 1 Adder 1 1 Schift 1 1 Schift 2 1 DONE 1 Next State 1 2 3 3 1 State Reg Start Compar.LT B_reg(0) DONE
 S0&START=1. S1&COUNT<4. S2&~(B(0)=1) S2&B(0)=1. S3. Mux1. 1. Mux2. 1. Mux3. 1. Mux4. Load A_Reg Chemin de. données. Load B_Reg. 1. Clear Count_Reg. 1. Load Count_Reg. 1. Clear Mult. 1. Load Mult Adder Schift Schift DONE. 1. Next State State Reg. Start. Compar.LT. B_reg(0) DONE.")
77
Multiplieur de Booth : Principe
L'algorithme de Booth est basé sur 2 principes : une suite de 0's dans B ne demande ni addition ni soustraction (juste un décalage) une suite de 1's dans B est associée avec une combinaison de soustractions (là où la suite commence) et une addition (là où la suite finit). Justification : … ….. = .… Donc : au passage 01 on rajoute A au passage 10 on enlève A
 une suite de 1 s dans B est associée avec une combinaison de soustractions (là où la suite commence) et une addition (là où la suite finit). Justification : … ….. = .… Donc : au passage 01 on rajoute A. au passage 10 on enlève A.")
78
Multiplieur de Booth : Implantation
Multiplication de 2 nombres A et B sur N bits signés en C2 Cpt est un compteur de séquence (N) BC est un registre de 2 bits (fenêtre) B et A sont des registres de N et N+1 bits. Initialement B est chargé dans le registre B A est chargé dans A et son signe est recopié dans le bit de poids fort (AN et AN-1 ont même valeur) Les registres B et BC concaténés sont notés B:BC, donc B:BC a N+2 bits. P a 2N bits de long et contiendra le produit final. Les N+1 bits de poids fort sont appelés PH et les N-1 de poids faibles PL.
 BC est un registre de 2 bits (fenêtre) B et A sont des registres de N et N+1 bits. Initialement B est chargé dans le registre B. A est chargé dans A et son signe est recopié dans le bit de poids fort (AN et AN-1 ont même valeur) Les registres B et BC concaténés sont notés B:BC, donc B:BC a N+2 bits. P a 2N bits de long et contiendra le produit final. Les N+1 bits de poids fort sont appelés PH et les N-1 de poids faibles PL.")
79
Algorithme de Booth 1. Initialisation:
Le multiplicande est chargé dans A (et étendu à N+1 bits), le multiplieur dans B. La valeur N est chargée dans Cpt. P et BC sont initialisés à zéro 2. Décalage arithmétique à droite: ashift (recopie du bit de poids fort) préserve le signe d'un nombre en complément à 2 (c'est une division par 2). Faire un ashift sur P Faire ashift sur B:BC 3. Addition, Soustraction, ou Nop: si BC = 01b alors Additionner A à PH, sinon si BC = 10b alors Soustraire A à PH. (pour soustraire, faire le complément à 2 et additionner) sinon (BC = 00 ou 11) ne rien faire Nop 4. Décrémenter Cpt, si Cpt ≠ 0, retourner en 2 sinon fin
, le multiplieur dans B. La valeur N est chargée dans Cpt. P et BC sont initialisés à zéro. 2. Décalage arithmétique à droite: ashift (recopie du bit de poids fort) préserve le signe d un nombre en complément à 2 (c est une division par 2). Faire un ashift sur P. Faire ashift sur B:BC. 3. Addition, Soustraction, ou Nop: si BC = 01b alors Additionner A à PH, sinon. si BC = 10b alors Soustraire A à PH. (pour soustraire, faire le complément à 2 et additionner) sinon (BC = 00 ou 11) ne rien faire Nop. 4. Décrémenter Cpt, si Cpt ≠ 0, retourner en 2 sinon fin.")
80
B= -5 (11011b) A= +2 (00010b). Le complément à 2 de A est 111110b
Exemple : N=5, P= (-5) * (+2) B= -5 (11011b) A= +2 (00010b). Le complément à 2 de A est b Etapes B BC PH PL Cpt soustraction ------ 3, 2,3, nop addition 3, soustraction 3, nop 2,3, Résultat : b est le complément à 2 de = 10d càd -10
 * (+2) B= -5 (11011b) A= +2 (00010b). Le complément à 2 de A est b. Etapes B BC PH PL Cpt soustraction , ,3, nop addition , soustraction. 3, nop. 2,3, Résultat : b est le complément à 2 de = 10d càd -10.")
81
Améliorations Alors qu'avec cette version , on utilise un additionneur N+1 bits, on peut n'utiliser qu'un additionneur N bits (mais il faut gérer le dépassement de capacité en complément à 2) Chaque itération comporte une opération de décalage, donc les étapes 2 et 3 peuvent être combinées pour gagner du temps. Finalement, on peut éliminer le registre B, en se servant de PH pour mémoriser le multiplicande.
 Chaque itération comporte une opération de décalage, donc les étapes 2 et 3 peuvent être combinées pour gagner du temps. Finalement, on peut éliminer le registre B, en se servant de PH pour mémoriser le multiplicande.")
82
Multiplieur virgule flottante
Exemple : P= A*B= 452,5*117,5 Signe du produit : "et" des bits de signe Exposant du produit : Somme des exposants Eb(P)= E(P)+127 = Eb(A)-127+Eb(B) = Eb(A)+Eb(B)-127 Mantisse du produit : Produit des mantisses et recadrage => modification de l'exposant
= E(P)+127. = Eb(A)-127+Eb(B) = Eb(A)+Eb(B)-127. Mantisse du produit : Produit des mantisses et recadrage. => modification de l exposant.")
83
Division

84
Division Binaire Exemple : 11 / 9 Soustraction 5 bits 1 0 1 1 1 0 0 1
1 ,0 0 1 , 1 2 0 2 1 Soustraction 5 bits

85
Diviseur S = A / D A=A3 A2 A1A0 D=D3 D2 D1 D0 S=S7S6S5S4,S3 S2 S1S0 1 0 1 0 1 Q R R R R 1 , Si R>D alors Q=1 et R-D sinon Q=0 et R 1 1

86
, Diviseur R D Ci+1 + Ci Si alors R R D Ci+1 Ci Si R Do + - D1 D2 D3
A3 A2 A1 A0 Q3 Q2 Q1 Q0 Q-1 Q-2 Q-3 , + - Ci+1 + Ci Si alors 1 R R D + - Ci+1 Ci - Si Si R

87
Diviseur Do + - D1 D2 D3 A3 A2 A1 A0 Q3 Q2 Q1 Q0 Q-1 Q-2 Q-3 ,

88
Divisions multiplication de polynômes dans GF(2n)
")
89
Espace des polynômes Suite de bits de p bits élément de [GF(2)]p coefficients du polynôme ap-1x(p-1)+ap-2x(p-2)+…+a0 Ex : 1.x5+0.x4+1.x3+0.x2+0.x+1 = x5+x3+1 Pp-1 (ensemble des polys de degré < p) isomorphe à [GF(2)]p Attention : degré du poly = p-1 Structure d'espace vectoriel sur GF[2] Division polynomiale P1(x) = P2(x).Q(x)+R(x) avec R(x)=0 ou deg(R)<deg(P2) exemple x3+x2+x=(x+1)(x2+1) + 1 Structure d'anneau
![Espace des polynômes Suite de bits de p bits élément de [GF(2)]p coefficients du polynôme ap-1x(p-1)+ap-2x(p-2)+…+a0.](http://slideplayer.fr/slide/1326513/3/images/89/Espace+des+polyn%C3%B4mes+Suite+de+bits+de+p+bits+%EF%83%B3+%C3%A9l%C3%A9ment+de+%5BGF%282%29%5Dp+%EF%83%B3+coefficients+du+polyn%C3%B4me+ap-1x%28p-1%29%2Bap-2x%28p-2%29%2B%E2%80%A6%2Ba0..jpg "Ex : 1.x5+0.x4+1.x3+0.x2+0.x+1 = x5+x3+1. Pp-1 (ensemble des polys de degré < p) isomorphe à [GF(2)]p. Attention : degré du poly = p-1. Structure d espace vectoriel sur GF[2] Division polynomiale. P1(x) = P2(x).Q(x)+R(x) avec R(x)=0 ou deg(R)<deg(P2) exemple x3+x2+x=(x+1)(x2+1) + 1. Structure d anneau.")
90
Division de Polynômes Division dans [GF(2)]p
P1(x) = P2(x).Q(x)+R(x) avec R(x)=0 ou deg(R)<deg(P2) Calcul du reste Si degré(P1(x)) = degré (P2(x)) alors Q(x) = 1 et R(x) = P1(x) – P2(x).1 = P1(x) – P2(x) = P1(x) + P2(x) exemple : divisé par x4+x3+x+1 divisé par x4+x3+x2 Q(x)=1 et R(x) = (11011) + (11100) = (00111) = x2+x+1 Si degré(P1(x)) < degré(P2(x)) alors Q(x) =0 et R(x) = P1(x)
![Division de Polynômes Division dans [GF(2)]p](http://slideplayer.fr/slide/1326513/3/images/90/Division+de+Polyn%C3%B4mes+Division+dans+%5BGF%282%29%5Dp.jpg "P1(x) = P2(x).Q(x)+R(x) avec R(x)=0 ou deg(R)<deg(P2) Calcul du reste. Si degré(P1(x)) = degré (P2(x)) alors Q(x) = 1. et R(x) = P1(x) – P2(x).1 = P1(x) – P2(x) = P1(x) + P2(x) exemple : divisé par x4+x3+x+1 divisé par x4+x3+x2. Q(x)=1 et R(x) = (11011) + (11100) = (00111) = x2+x+1. Si degré(P1(x)) < degré(P2(x)) alors Q(x) =0. et R(x) = P1(x)")
91
Implantation du reste de la division de polynômes dans (GF[2])n
reste de la division de x14+x12+x8+x7+x5 par x5+x4 +x2+1 x14+x12+x8+x7+x5 = (x5+x4+x2+1) (x9+x8+x6+x4+x2+x) + (x3+x2+x) Quotient Reste = Syndrome
![Implantation du reste de la division de polynômes dans (GF[2])n](http://slideplayer.fr/slide/1326513/3/images/91/Implantation+du+reste+de+la+division+de+polyn%C3%B4mes+dans+%28GF%5B2%5D%29n.jpg "reste de la division de x14+x12+x8+x7+x5 par x5+x4 +x2+1. x14+x12+x8+x7+x5 = (x5+x4+x2+1) (x9+x8+x6+x4+x2+x) + (x3+x2+x) Quotient. Reste. = Syndrome.")
92
Implantation du reste de la division de polys
division de x14+x12+x8+x7 +x5 par x5+x4 +x2+1 Remarques : on n'a besoin que 5 bits de résultats intermédiaire, le dividende peut être rentré en série si le bit de poids fort du reste intermédiaire est 0 : on décale le reste intermédiaire en incluant un bit de plus du dividende 1 : on décale de reste intermédiaire en incluant un bit de plus du dividende et enlève (i.e. ajoute) le diviseur
 le diviseur.")
93
Implantation du reste de la division de polys
Entrée du dividende, puissance forte en tête division par x5+x4 +x2+1 x5 x0 x1 x2 x3 x4 i0.... ik Quotient 1 1 1 0 1 1 1 0 1 0 0 = Remarques : si le bit de poids fort = 0, décalage si le bit de poids fort =1, décalage et addition du diviseur (càd soustraction)
")
94
Forme générale d'un diviseur
Division par a0 + a1x + ……+ an-1xn-1 + xn xn x0 a0 x1 a1 xn-2 an-2 xn-1 an-1 i0.... ik la connexion existe si ai = 1 la connexion n'existe pas si ai = 0 ai

95
Implantation de la multiplication de polynômes
Multiplication de polynômes par un polynôme g(x) = x3+x+1 Exemple : soit à calculer i(x).g(x) avec g(x) = x3+x+1, i(x) = x3+x2+1 1101 A B C i0.... i3 t E ABC Sortie 000 1 i3 =1 100 2 i2=1 110 3 i1=0 011 4 i0=1 101 5 010 6 001 7 1011 x3 x x0 x6 Initialement les bascules A,B,C sont à 0 x5 x4 x3 x2 x1 x0
 = x3+x+1. Exemple : soit à calculer i(x).g(x) avec g(x) = x3+x+1, i(x) = x3+x2+1 A. B. C. i0.... i3. t. E. ABC. Sortie i3 = i2= i1= i0= x3. x. x0. x6. Initialement les bascules A,B,C sont à 0. x5. x4. x3. x2. x1. x0.")
96
Implantations multiplication
Exemple : g(x) = x3+x+1 A B C i0.... i3 x3 x1 x0 Autre implantation A B C i0.... i3 x0 x1 x3
 = x3+x+1. A. B. C. i0.... i3. x3. x1. x0. Autre implantation. A. B. C. i0.... i3. x0. x1. x3.")
97
Implantation : multiplication / division
Multiplication par x+x3, le résultat est divisé par 1+x2+x5 2 3 1 4 i0.... ik

98
Applications Codes correcteurs
L'information à coder est considérer comme un polynôme i(x) par exemple : est considéré comme le poly x4+x3 +1 Codes polynomiaux : Codes linéaires Tous les mots de code sont des multiples de l'un d'eux (au sens produit de polynômes) Le polynôme g(x) servant à construire le codage est appelé polynôme générateur (C'est le poly. qui code i(x) = 00….1)
 par exemple : est considéré comme le poly x4+x3 +1. Codes polynomiaux : Codes linéaires. Tous les mots de code sont des multiples de l un d eux (au sens produit de polynômes) Le polynôme g(x) servant à construire le codage est appelé polynôme générateur (C est le poly. qui code i(x) = 00….1)")
99
Codage Soit à coder les mots de Pk-1 (blocs de k bits)
Si le degré s de g(x) est fixé, il détermine la longueur du code Si la longueur n du code est fixée, tout polynôme de degré s=n-k engendre un code Cn,k Codage par multiplication de polynômes la fonction de codage f(i(x)) = i(x) .g(x) permet de construire un code polynomial tel que Cn,k = {c(x) = i(x) .g(x) avec i(x)Pk-1 et deg(g)=n-k}
 est fixé, il détermine la longueur du code. Si la longueur n du code est fixée, tout polynôme de degré s=n-k engendre un code Cn,k. Codage par multiplication de polynômes. la fonction de codage f(i(x)) = i(x) .g(x) permet de construire un code polynomial tel que. Cn,k = {c(x) = i(x) .g(x) avec i(x)Pk-1 et deg(g)=n-k}")
100
Exemple Pour un code polynomial de longueur 5, de dimension 3 le polynôme générateur doit être de degré 5-3=2, ce peut être x2, x2+1, x2+x+1 ou x2+x Soit par exemple g(x) = x2+x, en appliquant c(x)=i(x).g(x), on obtient i i(x) c(x) = i(x).g(x) c 0 0 0 0 0 1 1 x2+x 0 1 0 x x3+x2 0 1 1 x+1 x3+x 1 0 0 x2 x4+x3 1 0 1 x2+1 x4+x3+x2+x 1 1 0 x4+x2 1 1 1 x2+x+1 x4+x
 = x2+x, en appliquant c(x)=i(x).g(x), on obtient. i. i(x) c(x) = i(x).g(x) c x2+x x. x3+x x+1. x3+x x2. x4+x x2+1. x4+x3+x2+x x4+x x2+x+1. x4+x")
101
Matrice génératrice caractéristique
Code linéaire, matrice génératrice. En codant la base canonique de Pk-1 par la fonction de codage, on obtient une base de Pn-1 => matrice génératrice caractéristique (très facile à obtenir) Base = {e1,e2,…..,ek} e1(x) = xk-1 e1 = (1 0 0 … 0) …. ek-1(x) = x ek-1 = (0 0 0…1 0) ek(x) =1 ek = (0 0 0 …..1) Ce qui donne : xk-1 codé en xk-1.g(x), x codé en x.g(x) 1 codé en g(x)
 Base = {e1,e2,…..,ek} e1(x) = xk-1 e1 = (1 0 0 … 0) …. ek-1(x) = x ek-1 = (0 0 0…1 0) ek(x) =1 ek = (0 0 0 …..1) Ce qui donne : xk-1 codé en xk-1.g(x), x codé en x.g(x) 1 codé en g(x)")
102
Matrice génératrice caractéristique
Les polynômes de code obtenu forment un base du code, sous-espace vectoriel de dimension k de Pn-1, chacun représente une des k colonnes d'une matrice génératrice G(g) que l'on peut écrire avec g(x) = xn-k+gk+1.xn-(k+1)+gn-1.x2+gn Les colonnes sont les vecteurs formés par les coef. des polys Si g(x)= xn-k+gk+1.xn-(k+1)+gn-1.x2+gn, il vient (0 …. 0 1 gk+1 ……………gn) correspond à g(x) (0 …. 1 gk+1 ……………gn 0) correspond à x.g(x) …… (1 gk+1 ……………gn 0 …….0) correspond à xk-1.g(x)
 que l on peut écrire. avec g(x) = xn-k+gk+1.xn-(k+1)+gn-1.x2+gn. Les colonnes sont les vecteurs formés par les coef. des polys. Si g(x)= xn-k+gk+1.xn-(k+1)+gn-1.x2+gn, il vient. (0 …. 0 1 gk+1 ……………gn) correspond à g(x) (0 …. 1 gk+1 ……………gn 0) correspond à x.g(x) …… (1 gk+1 ……………gn 0 …….0) correspond à xk-1.g(x)")
103
Matrice génératrice caractéristique
La matrice G(g) est donc de la forme Exemple : sur l'exemple précédent g(x) = x2+x qui correspond au vecteur ( ) de [GF(2)]5 , càd gn = 0 gn+1 = 1 gn+2 = 1 gn+3 = 0 gn+4 = 0 ……………….....0 gk …………………0 gk+2 gk …………..0 …………………………… gn ………………… gk+1 1 0 ……………………….gk+1 ……………………………… 0……………………….0 gn 1 0 0 1 1 0 0 1 1 0 0 1 0 0 0
 est donc de la forme. Exemple : sur l exemple précédent g(x) = x2+x qui correspond au vecteur. ( ) de [GF(2)]5 , càd. gn = 0. gn+1 = 1. gn+2 = 1. gn+3 = 0. gn+4 = ……………… gk …………………0. gk+2 gk …………..0. …………………………… gn ………………… gk ……………………….gk+1. ……………………………… 0……………………….0 gn")
104
Codage systématique (par multiplication et division)
Rappel : code systématique = info + bits Soit g(x) de degré s avec s=n-k, le codage se fait en 3 étapes (multipli. puis division de poly) Tout poly de code est de la forme c(x) = (i1.xn-1+….+ikxn-k) + a1.xn-k-1+…..+an-k+1.x+an-k = xn-k (i1.xk-1+….+ik) + a1.xn-k-1+…..+an-k+1.x+an-k soit c(x) = xn-k . i(x) + a(x) avec a(x) =0 ou deg(a(x)) (n-k)-1 avec a(x) poly associé à la clef de contrôle.
 de degré s avec s=n-k, le codage se fait en 3 étapes (multipli. puis division de poly) Tout poly de code est de la forme. c(x) = (i1.xn-1+….+ikxn-k) + a1.xn-k-1+…..+an-k+1.x+an-k. = xn-k (i1.xk-1+….+ik) + a1.xn-k-1+…..+an-k+1.x+an-k. soit c(x) = xn-k . i(x) + a(x) avec a(x) =0 ou deg(a(x)) (n-k)-1 avec a(x) poly associé à la clef de contrôle.")
105
Codage systématique (par multiplication et division)
1/ calculer le produit xn-k.i(x) (cela revient à décaler les coef. de i(x) vers la gauche de n-k positions) 2/ calcul de la clef de contrôle il faut que xn-k.i(x) + a(x) soit un mot du code i.e. de la forme i*(x).g(x) avec i*(x) Pk-1 ce qui implique xn-k.i(x) = i*(x).g(x) + a(x) on a deg(a(x)) = 0 ou deg(a(x)) (n-k)+1 donc a(x) est le reste de la division de xn-k.i(x) par g(x) 3/ concaténer xn-k i(x) et a(x) En résumé : c(x) = xn-k.i(x) + (xn-k.i(x) mod g(x))
 (cela revient à décaler les coef. de i(x) vers la gauche de n-k positions) 2/ calcul de la clef de contrôle. il faut que xn-k.i(x) + a(x) soit un mot du code i.e. de la forme i*(x).g(x) avec i*(x) Pk-1. ce qui implique xn-k.i(x) = i*(x).g(x) + a(x) on a deg(a(x)) = 0 ou deg(a(x)) (n-k)+1. donc a(x) est le reste de la division de xn-k.i(x) par g(x) 3/ concaténer xn-k i(x) et a(x) En résumé : c(x) = xn-k.i(x) + (xn-k.i(x) mod g(x))")
106
Règle du code systématique
Pour construire Cn,r de générateur g(x) par un codage systématique, il faut pour chaque i(x) : 1/ calculer le produit xn-k.i(x) => coefs de plus haut degré 2/ diviser xn-k i(x) par g(x), le reste de la division est la clef a(x) associée à i(x) => coefs de plus petit degré 3/ ajouter (ce qui revient à concaténer) xn-k.i(x) et a(x)
 par un codage systématique, il faut pour chaque i(x) : 1/ calculer le produit xn-k.i(x) => coefs de plus haut degré. 2/ diviser xn-k i(x) par g(x), le reste de la division est la clef a(x) associée à i(x) => coefs de plus petit degré. 3/ ajouter (ce qui revient à concaténer) xn-k.i(x) et a(x)")
107
Codage systématique : exemple
Soit le code précédent C5,3 de poly g(x) = x2+x 1/ Calcul de xn-k.i(x) = x5-3.i(x) = x2.i(x) 2/Tableau des clefs a(x) par : x2.i(x) = (x2+x).Q(x) +a(x) i i(x) x2.i(x) =(x2+x) Q(x) a(x) a(x) 0 0 0 =(x2+x) 0 0 0 1 1 x2 =(x2+x) x x 0 1 0 x3 =(x2+x) (x+1) x 0 1 1 x+1 x3+x2 =(x2+x) x 1 0 0 x4 =(x2+x) (x2+x+1) +x 1 0 1 x2+1 x4+x2 =(x2+x) (x2+x) 1 1 0 x2+x x4+x3 =(x2+x) x2 1 1 1 x2+x+1 x4+x3+x2 =(x2+x) (x2+1) x
 = x2+x. 1/ Calcul de xn-k.i(x) = x5-3.i(x) = x2.i(x) 2/Tableau des clefs a(x) par : x2.i(x) = (x2+x).Q(x) +a(x) i. i(x) x2.i(x) =(x2+x) Q(x) +a(x) a(x) =(x2+x) x2. =(x2+x) 1 +x. x x3. =(x2+x) (x+1) +x x+1. x3+x2. =(x2+x) x x4. =(x2+x) (x2+x+1) +x x2+1. x4+x2. =(x2+x) (x2+x) x2+x. x4+x3. =(x2+x) x x2+x+1. x4+x3+x2. =(x2+x) (x2+1) +x.")
108
Codage systématique : exemple
3/ Codage par : c(x)=x2.i(x)+a(x) i x2.i(x) a(x) c(x)=x2.i(x)+a(x) c 0 0 0 0+0 0 0 1 x2 x x2+x 0 1 0 x3 x3+x 0 1 1 x3+x2 1 0 0 x4 x4+x 1 0 1 x4+x2 1 1 0 x4+x3 1 1 1 x4+x3+x2 x4+x3+x2+x
=x2.i(x)+a(x) i. x2.i(x) a(x) c(x)=x2.i(x)+a(x) c x2. x. x2+x x3. x3+x x3+x x4. x4+x x4+x x4+x x4+x3+x2. x4+x3+x2+x")
109
Détection d'erreurs Par matrice de contrôle (cf. codes linéaires)
Par division de polynômes : Soit m(x) le message reçu m(x) = g(x).Q(x) + R(x) avec R(x) = 0 ou deg(R) < deg(g) si R(x) = 0 , m(x) est un polynôme du code, m(x) accepté si R(x) ≠ 0, m(x) est un message erroné Fonction syndrome soit s= deg(g), R(x) Ps-1, R(x) = m(x) mod g(x) l'application qui à chaque m(x) fait correspondre le reste de la division de m(x) par g(x) est une application linéaire de Pn-1 dans Ps-1 dont le code est le noyau, propre au code polynomial et toute matrice associée à cette application est une matrice de contrôle du code
 le message reçu. m(x) = g(x).Q(x) + R(x) avec R(x) = 0 ou deg(R) < deg(g) si R(x) = 0 , m(x) est un polynôme du code, m(x) accepté. si R(x) ≠ 0, m(x) est un message erroné. Fonction syndrome. soit s= deg(g), R(x) Ps-1, R(x) = m(x) mod g(x) l application qui à chaque m(x) fait correspondre le reste de la division de m(x) par g(x) est une application linéaire de Pn-1 dans Ps-1 dont le code est le noyau, propre au code polynomial et toute matrice associée à cette application est une matrice de contrôle du code.")
110
CODES CYCLIQUES ou CRC Cyclic Redundancy Check
Codes polynomiaux + propriété de stabilité par permutation circulaire des mots. Leur polynôme générateur divise xn+1 (n longueur du code). => construction immédiate de la matrice de contrôle Définition 1 : un code est dit cyclique si il est linéaire il est stable par permutation circulaire des mots. Notation k , c C k(c) C, où k est une rotation de k positions Définition 2 : un code est cyclique si code polynomial le poly générateur divise xn+1
. => construction immédiate de la matrice de contrôle. Définition 1 : un code est dit cyclique si. il est linéaire. il est stable par permutation circulaire des mots. Notation. k , c C k(c) C, où k est une rotation de k positions. Définition 2 : un code est cyclique si. code polynomial. le poly générateur divise xn+1.")
111
Contrôle des codes cycliques
Comme code polynomial, un code cyclique admet un poly. de contrôle p(x) défini par xn+1 = p(x).g(x). Donc c(x) C p(x).c(x) mod(xn+1) = 0
 défini par xn+1 = p(x).g(x). Donc c(x) C p(x).c(x) mod(xn+1) = 0.")
112
Exemples de codes cycliques
Exemples de polynômes générateurs - Code BCH (Bose-Chaudhuri - Hocquenghem) l=15, k=10, e=3 R = 33% - Code Golay l=23, k=11, e=3 R = 52 % X25 (HDLC) (ex: RNIS) - CRC-32 (Ethernet) : X32 + X26 + X23 + X22 + X16 + X12 + X11 + X10 + X8 + X7 + X5 + X4 + X2 + X + 1
 l=15, k=10, e=3. R = 33% - Code Golay. l=23, k=11, e=3. R = 52 % X25 (HDLC) (ex: RNIS) - CRC-32 (Ethernet) : X32 + X26 + X23 + X22 + X16 + X12 + X11 + X10 + X8 + X7 + X5 + X4 + X2 + X + 1.")
113
Exercice Soit un code polynomial de dimension 3 de poly. générateur x2+x+1 Quel est la taille des codes ? Calculer les codes par multiplication de polys et par matrice génératrice Proposer une structure pour le codage et le détection d'erreurs implantation parallèle implantation série vérifier les structures sur des exemples significatifs.

114
Applications Test : compression de réponses de test => syndrome
générateurs aléatoires

Présentations similaires