Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Moteurs de recherche fédérée
Florence Galand Bibliothèque Chevaleret-Jussieu Paris Centre Rencontres RNBM 2007 1er - 5 octobre 2007

2
Plan Contexte et enjeux Quelques aspects techniques Illustrations
Perspectives

3
Contexte de la recherche sur l’Internet
Hétérogénéité Des formats : texte, images, vidéos, sons Des sources de diffusion d’information scientifique: web institutionnels, éditeurs, archives ouvertes, sites perso, blogs, wikis, etc. Des contenus : différents type de documents : article scientifiques, validés ou non par les pairs, de vulgarisation, etc. Tout n’est pas indexé dans les principaux moteurs de recherche Web profond: nos catalogues, web dynamique, bases de données d’éditeurs Difficulté de trouver

4
Enjeux des moteurs de recherche web
« Recherche Universelle » : Google Indexer le maximum de pages Numériser le maximum de livres des bibliothèques Fidéliser les internautes : spécialisation et diversification (images, actualités, maps, blogs…), personnalisation, services, gadgets, etc. Monopole de Google
, personnalisation, services, gadgets, etc. Monopole de Google.")
5
Google Scholar Classement par type de document : BOOK, CITATION, article Référence d’article Toutes les versions d’un même article Citation = nb de fois où l’article ou l’ouvrage en question est littéralement « cité » (et non plus simplement lié) par d’autres Localisation : par ex dans le SUDOC Limites Recherche uniquement les articles et ouvrages scientifiques moissonnés dans les différentes sources (universités, éditeurs…) par le moteur de recherche.
 par d’autres. Localisation : par ex dans le SUDOC. Limites. Recherche uniquement les articles et ouvrages scientifiques moissonnés dans les différentes sources (universités, éditeurs…) par le moteur de recherche.")
6
Alternatives ? Moteurs avec d’autres algorithmes, d’autres présentations des résultats… Yahoo Recherche par facettes: Exalead, Vivissimo Moteurs de cartographie: Kartoon

7
En parallèle Des moteurs développés par les éditeurs Web sémantique
Scopus (Elsevier, sur abonnement) Scirus (Elsevier, technologie FAST) Web sémantique Des moteurs propulsés par les usagers Moteurs alternatifs dits « sociaux » du web 2.0 centrés sur les réseaux, les communautés d’intérêt Search Wikia, janvier 2007 par Jimmy Wales (Wikipédia) + services (tags, digg, …) Un chercheur fait l’hypothèse que la sémantique du Web (métadonnées formelles) qui sera la plus utile et efficace, sera celle qui sera co-crée et enrichie en permanence au sein de communautés. Il a donc écarté volontairement le sens philosophique des ontologies en étudiant une variante des ontologies de domaine de part le partage de connaissances. Cela signifie alors d'inventer de nouvelles formes pour que les utilisateurs participent à leur univers informationnel. La solution présentée par Jean Pierre Cahier est basée sur la co-construction des "Ontologies Sémiotiques". Vu sur
 Scirus (Elsevier, technologie FAST) Web sémantique. Des moteurs propulsés par les usagers. Moteurs alternatifs dits « sociaux » du web 2.0. centrés sur les réseaux, les communautés d’intérêt. Search Wikia, janvier 2007 par Jimmy Wales (Wikipédia) + services (tags, digg, …) Un chercheur fait l’hypothèse que la sémantique du Web (métadonnées formelles) qui sera la plus utile et efficace, sera celle qui sera co-crée et enrichie en permanence au sein de communautés. Il a donc écarté volontairement le sens philosophique des ontologies en étudiant une variante des ontologies de domaine de part le partage de connaissances. Cela signifie alors d inventer de nouvelles formes pour que les utilisateurs participent à leur univers informationnel. La solution présentée par Jean Pierre Cahier est basée sur la co-construction des Ontologies Sémiotiques . Vu sur")
8
Quid des technologies web 2.0 ?
Répercussion sur les moteurs Ajax = réduit les temps de requête/affichage des données Agrégation = Protocole RSS Mashup = Mixage des services ou entre un moteur et des services d’info (ex : Journal.info) Digg = Proposition de ressources et vote Personnalisation fabriquer son propre moteur et le partager avec la communauté pour interaction = Do it yourself Google Co-op : choix de ses sources LiveSearch (MSN): insérer ses propres macros Toutes ces technologies sont autant d’idées qu’on voit reprises ou qui seront peu à peu reprises par les moteurs de recherche fédérées Ajax -> affiner sa recherche Agrégation -> abonnement à des requêtes Digg -> faire remonter des ressources par vote Personnalisation -> « son » moteur
 Digg = Proposition de ressources et vote. Personnalisation. fabriquer son propre moteur et le partager avec la communauté pour interaction = Do it yourself. Google Co-op : choix de ses sources. LiveSearch (MSN): insérer ses propres macros. Toutes ces technologies sont autant d’idées qu’on voit reprises ou qui seront peu à peu reprises par les moteurs de recherche fédérées. Ajax -> affiner sa recherche. Agrégation -> abonnement à des requêtes. Digg -> faire remonter des ressources par vote. Personnalisation -> « son » moteur.")
9
Limites du web 2.0 Web 2 vs web sémantique Mais, que cherche-t-on ?
Susciter l’intérêt des scientifiques pour le signalement des ressources dans un système interactif Limites de l’indexation (folksonomie – ajouts de tags) par les usagers La recherche « médiée » par les utilisateurs ne sera jamais aussi exhaustive que la recherche « motorisée » par les algorithmes Web 2 vs web sémantique par rapport à la recherche scientifique ? Processus de vulgarisation, cf.wikipédia Mais, que cherche-t-on ? Exhaustivité ou pertinence ? Web 2 = web béta -> intérêt : web participatif Certaines bibliothèques ouvrent leur système de référencement de sites web. Mais on peut être sceptique quand à l’interaction avec les scientifiques à l’indexation par les usagers des ressources documentaires, mais si cela vient en complément d’une indexation institutionnelle, cela peut être très riche en terme d’interactivité avec l’usager Ces deux tendances web 2 qui nous incitent à reposer la question / remise en question Processus de validation scientifique et professionnelle Question des institutions dépositaires du savoir et du classement/conservation de celui-ci -> que cherche-t-on ? Exhaustivité selon le modèle de Google Pertinence : selon un modèle de sélection des ressources par des professionnels ou Un modèle ouvert aux passionnés
 par les usagers. La recherche « médiée » par les utilisateurs ne sera jamais aussi exhaustive que la recherche « motorisée » par les algorithmes. Web 2 vs web sémantique. par rapport à la recherche scientifique Processus de vulgarisation, cf.wikipédia. Mais, que cherche-t-on Exhaustivité ou pertinence Web 2 = web béta. -> intérêt : web participatif. Certaines bibliothèques ouvrent leur système de référencement de sites web. Mais on peut être sceptique. quand à l’interaction avec les scientifiques. à l’indexation par les usagers des ressources documentaires, mais si cela vient en complément d’une indexation institutionnelle, cela peut être très riche en terme d’interactivité avec l’usager. Ces deux tendances web 2 qui nous incitent à reposer la question / remise en question. Processus de validation scientifique et professionnelle. Question des institutions dépositaires du savoir et du classement/conservation de celui-ci. -> que cherche-t-on Exhaustivité selon le modèle de Google. Pertinence : selon un modèle de sélection des ressources par des professionnels ou. Un modèle ouvert aux passionnés.")
10
Conclusion sur la recherche d’information
Les moteurs et les usages sont en train de changer de logique pageRank filtrage en amont des sources par les utilisateurs selon un principe de pertinence différent qui leur est propre navigation facilitée avec des interfaces à facettes personnalisation On est en train d’assister à des changements de logiques qui peuvent se compléter

11
Usages Problèmes de l’usager Trop de ressources éparpillées
Difficultés pour identifier les ressources : Un article/ouvrage ? Ou/et une référence bibliographique ? Difficultés pour accéder au document lui-même Passer de la phase « bibliographique » à la phase « localisation » Et donc, changer de base de consultation Quel est le problème qui se pose dans nos bibliothèques ? Quels sont les usages des étudiants et des chercheurs ? Les étudiants ne savent pas chercher: Ils ne connaissent pas les ressources Ne savent pas identifier leur besoin Et quand ils ont une référence : pb comment y accéder ?

12
Pratiques des mathématiciens
Mathscinet ou / et Zentralblatt Google et / ou Google Scholar Catalogue de la bibliothèque de leur institution Catalogue fusionné des ouvrages du RNBM Ressources de la Cellule Mathdoc Pratiques des professionnels des bibliothèques ? Idem + autres catalogues comme Sudoc, Library of Congress, Worldcat, etc. Que se soit pour rechercher un document ou la référence d’un doc, les chercheurs/étudiants vont consulter 3-4 ressources ou moteurs de recherche

13
Autres constats : Liés aux usages de la consultation/recherche dans plusieurs bases de données ou moteurs de recherche Longueur de l’entreprise Requiert des compétences techniques : reposer les requêtes dans chaque outils connaître la syntaxe si ressources spécialisées

14
Questions On sait que les chercheurs consultent ce qu’ils utilisent le plus souvent et vice-versa Mathscinet, Zentralblatt Google Catalogue de la bibliothèque (ouvrages) Voire les sites des revues scientifiques (nouveautés) Pourquoi et dans quels cas, les chercheurs et les étudiants auraient-ils besoin d’un outil de recherche fédérée ? une interrogation en une seule fois sur les sources sélectionnées aide à la recherche à la marge de leur domaine de compétences Dans quels cas, les chercheurs et les étudiants auraient-ils besoin d’un outil de recherche fédérée ? Quand ils ont besoin de consulter l’ensemble de ces ressources Quand ils ne connaissent pas ni les auteurs, ni des mots clés d’un domaine de connaissance hors de leur champ de recherche
 Voire les sites des revues scientifiques (nouveautés) Pourquoi et dans quels cas, les chercheurs et les étudiants auraient-ils besoin d’un outil de recherche fédérée une interrogation en une seule fois sur les sources sélectionnées. aide à la recherche à la marge de leur domaine de compétences. Dans quels cas, les chercheurs et les étudiants auraient-ils besoin d’un outil de recherche fédérée Quand ils ont besoin de consulter l’ensemble de ces ressources. Quand ils ne connaissent pas ni les auteurs, ni des mots clés d’un domaine de connaissance hors de leur champ de recherche.")
15
Il existe une solution Une interface de recherche unique
Une recherche simultanée vers toutes les ressources possédées / gérées par la bibliothèque et les consortiums Une seule liste de résultats homogénéisés avec des liens directs sur le document lui-même Il existe une solution : un outil qui présenterait une interface de recherche unique Pointant vers des ressources pertinentes en math Une liste de résultat avec les liens vers la « disponibilité » des documents référencés Est-ce que cette solution serait intéressante

16
…le moteur de recherche fédérée
Outil intégré dans le système documentaire Objectifs : Pertinence Rapidité Services

17
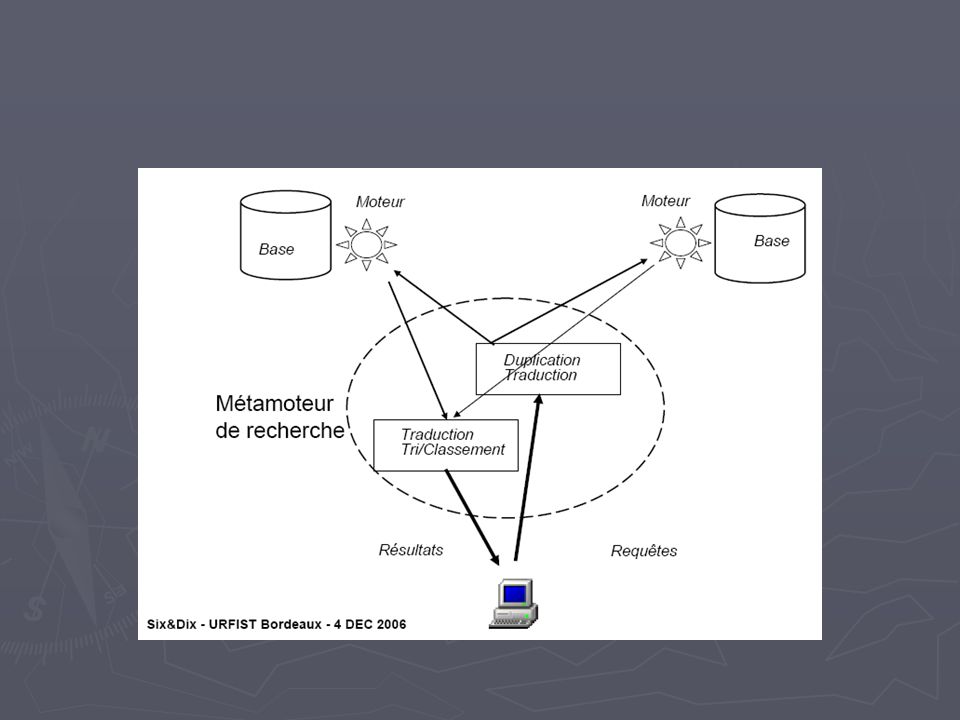
2. Aspects techniques Principes du moteur fédéré : Connecteur :
Repose sur des connecteurs qui font le lien entre la requête de l’utilisateur et les sources extérieures Connecteur : Traduit la requête de l’usager en autant de langages qu’il existe de cibles Traduit la réponse donnée par chaque source dans un format standardisé Cibles : catalogues de bibliothèque autres bases de données de la bibliothèque (GED, bibliothèques numériques, signets, etc.) bases de données bibliographiques système de diffusion de l’édition scientifique (plateforme des éditeurs) archives ouvertes pages web moteurs de recherche
 bases de données bibliographiques. système de diffusion de l’édition scientifique (plateforme des éditeurs) archives ouvertes. pages web. moteurs de recherche.")
19
Trois temps : Traduction de la requête Dédoublonnage des résultats
Moulinage XML des résultats pour être intégrés dans l’interface de recherche du portail

20
Différents types de connecteurs
Z 39-50 XML HTML web services Autre façon de collecter l’information Moissonnage OAI Réindexer certaines bases de données (SIGB ou l’OPAC)
")
21
Différentes fonctionnalités :
Cibles de recherche (base de données bibliographique, texte intégral) Types de recherche (chaîne de mots, booléenne) Critères de recherche (auteur, titre, sujet…) Filtres de recherche (par date, type de doc, format, source)
 Types de recherche (chaîne de mots, booléenne) Critères de recherche (auteur, titre, sujet…) Filtres de recherche (par date, type de doc, format, source)")
22
Services (options) autour du moteur
OpenURL gestion de liens dynamiques vers les textes intégraux limite les ruptures entre l’utilisateur et le document lui-même Time-out sur une ressource qui ne répond pas Tri ou classement des réponses Exploitation des résultats Impressions Envoi par mail Export dans un format bibliographique Services personnalisés Panier PEB

23
Limites des moteurs fédérés
certains critères de recherche pointus ne peuvent être pris en charge par les connecteurs Ne permet pas toujours l’exploitation fine d’une ressource -> nécessité de se connecter directement à la source pour poser sa requête de façon précise

24
Quelle est l’offre du marché ?
Trois catégories de moteurs de recherche fédérée Commerciaux Commercial open source Open source universitaire

25
Moteurs commerciaux Les « traditionnels » :
Metalib d’Ex-Libris ( + résolveur de lien OpenUrl : SFX) SCD Strasbourg Institut Max Planck Primo d’Exlibris Université de Vanderbildt Respons de Jouve BU Paris 6 BU Nantes Incipio d’Archimed Portail Sudoc
 SCD Strasbourg. Institut Max Planck. Primo d’Exlibris. Université de Vanderbildt. Respons de Jouve. BU Paris 6. BU Nantes. Incipio d’Archimed. Portail Sudoc.")
26
Les plus « innovants » : Exalead Vivissimo Fast, AlltheWeb
moteur sémantique BAAGZ : réseau social basé sur la notion de centres d’intérêts partagés Vivissimo Fast, AlltheWeb Deux exemples Moteur de recherche scientifique, Base-Search Catalogues des bibliothèques allemandes /autrichiennes /suisses Exalead fait partie des 70 sociétés sélectionnées pour le prestigieux DEMOFall sur BAAGZ se définit comme un nouveau type de réseau social basé sur la notion de centres d’intérêts partagés et reposant sur la puissante technologie de recherche sémantique d’Exalead. BAAGZ vous permet d’une part de matérialiser vos centres d’intérêts dans des baagz et d’autre part de trouver de l’information plus facilement en tirant partie de la communauté des baagerz, utilisateurs de BAAGZ. FAST, La société norvégienne Fast a édité un moteur de recherche quasiment aussi puissant que Google (plus de 2,2 milliards de pages indexées). L'indexation est très fréquente ce qui garanti une réelle fraicheur de l'information. AllTheWeb indique dans ses pages de résultats quand le site à été visité par ses robots (ex : Indexed: 6 hours ago ou Indexed: , 10:20 GMT). Les "Fast Topics" c'est-à dire des catégories associées que l'on retrouve sur de nombreux moteurs (related topics de NorthernLight par ex.) utilisant comme base de classement l'Open Directory (Dmoz.org). La fonction Advanced permet de déterminer les langues de rechercher ainsi que certains filtres (domaines, mots). Customize permet de personnaliser tous les paramètres de recherches proposés dans Advanced. Ce moteur méconnu rappelle Google par ses innovations et sa qualité et fait maintenant partie des moteurs de recherche majeurs. AlltheWeb appartient à Overture depuis février Yahoo! Inc a racheté Overture en juillet Depuis le printemps 2004, l'index d'AlltheWeb est celui de Yahoo!. il figure parmi les leaders du Magic Quadrant for Information Access Technology 2007, édité chaque année par le Gartner. Ce rapport, qui fait référence dans le domaine des moteurs de recherche, permet d’avoir une perception globale du marché. Il classe les éditeurs et leurs solutions en quatre catégories : leaders, challengers, visionnaires et acteurs de la niche. Il est basé sur la vision que les acteurs ont de l’évolution du marché et sur leur capacité de mise en oeuvre de cette vision.
. L indexation est très fréquente ce qui garanti une réelle fraicheur de l information. AllTheWeb indique dans ses pages de résultats quand le site à été visité par ses robots (ex : Indexed: 6 hours ago ou Indexed: , 10:20 GMT). Les Fast Topics c est-à dire des catégories associées que l on retrouve sur de nombreux moteurs (related topics de NorthernLight par ex.) utilisant comme base de classement l Open Directory (Dmoz.org). La fonction Advanced permet de déterminer les langues de rechercher ainsi que certains filtres (domaines, mots). Customize permet de personnaliser tous les paramètres de recherches proposés dans Advanced. Ce moteur méconnu rappelle Google par ses innovations et sa qualité et fait maintenant partie des moteurs de recherche majeurs. AlltheWeb appartient à Overture depuis février Yahoo! Inc a racheté Overture en juillet Depuis le printemps 2004, l index d AlltheWeb est celui de Yahoo!. il figure parmi les leaders du Magic Quadrant for Information Access Technology 2007, édité chaque année par le Gartner. Ce rapport, qui fait référence dans le domaine des moteurs de recherche, permet d’avoir une perception globale du marché. Il classe les éditeurs et leurs solutions en quatre catégories : leaders, challengers, visionnaires et acteurs de la niche. Il est basé sur la vision que les acteurs ont de l’évolution du marché et sur leur capacité de mise en oeuvre de cette vision.")
27
Moteur commercial Open source
MasterKey Développé par Index Data au Danemark Nouvelle génération (AJAX) : très rapide Recherche à facettes (sources, auteurs, etc.) openURL Exemple : bibliothèque du Texas
 : très rapide. Recherche à facettes (sources, auteurs, etc.) openURL. Exemple : bibliothèque du Texas.")
28
Moteurs open source dbWIZ LibraryFind
Développé par Simon Fraser University Library, Canada LibraryFind Développé par Oregon State University Libraries

29
Illustrations - Exemples

30
SCD Strasbourg, Bibliothèque virtuelle, http://doculp.u-strasbg.fr/
Metalib d’Ex-Libris

31
Max Planck Virtual Library http://vlib.mpg.de
Metalib d’Ex-Libris

32
Max Planck Virtual Library http://vlib.mpg.de
Metalib d’Ex-Libris

33
Université de Vanderbilt, http://alphasearch.library.vanderbilt.edu/
Primo, Alphasearch

34
Portail documentaire Jubil, Paris 6, http://jubil.upmc.fr/
Jouve

35
Nantilus, BU Nantes http://nantilus.univ-nantes.fr/
Jouve

36
Portail Sudoc, http://www.portail-sudoc.abes.fr/
Incipio, Archimed Les connecteurs ne fonctionnent pas toujours (Springer, arxiv…)
")
37
Fast, Dreilaender http://suchen. hbz-nrw. de/dreilaender/dreilaender
FAST société norvégienne

38
MasterKey, site de démo http://masterkey.indexdata.com/
Trois catalogues Library of Congress MELVYL Oxford University Contenus en accès libre Open Content Alliance OAISter Project Gutenberg Wikipedia Open Directory MasterKey, danois ?

40
Library of Texas, http://libraryoftexas.org/
MasterKey

41
Oregon State University http://search2. library. oregonstate
Library Find

42
Université Simon Fraser, http://www.lib.sfu.ca/
dbWIZ

43
dbWiz : accès public à tester , http://dbwiz. lib. sfu

44
Trois démonstrations : 1. Test à la bibli de math Chevaleret
(accès réservé) Développé à partir du moteur de Jouve, personnalisation pour les maths de Jubil, portail documentaire de Paris 6
 Développé à partir du moteur de Jouve, personnalisation pour les maths de Jubil, portail documentaire de Paris 6.")
45
8 sources : Jubil 1 4 sources : Jubil 3 Mathscinet Zentralblatt
Springer ScienceDirect Blackwell Google Scholar Catalogue BIUSJ 4 sources : Jubil 3 Mathscinet Zentralblatt Google Scholar Catalogue BIUSJ

46
Observations : Sur la rapidité Bouton « Disponibilité ? » Services
Enregistrer dans un panier Envoi par mail Exporter (Zotero)
")
47
2. LibraryFind, Univ. Oregon

48
Recherche multifacettes
Par type de document : articles, livres Par base de données : Ebsco, catalogue Thèmes associés Auteurs Possibilités de classement des résultats Sauvegarde Pour les articles Affichage titre + résumé PEB

49
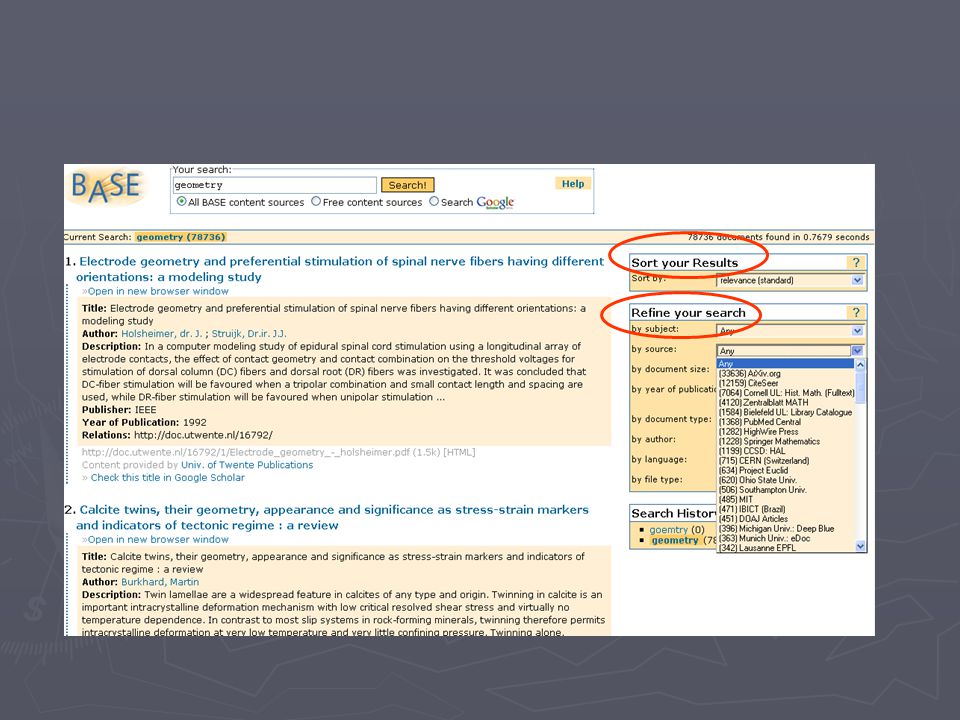
3. Fast, ex. Projet Base-search
Base-Search (Bielefeld Academic Search Engine), métamoteur de recherche scientifique, développé par l’Université de Bielefeld Initiative allemande qui contribue également au projet européen "Digital Repository Infrastructure Vision for European Research" (DRIVER) depuis juin 2006
, métamoteur de recherche scientifique, développé par l’Université de Bielefeld. Initiative allemande qui contribue également au projet européen Digital Repository Infrastructure Vision for European Research (DRIVER) depuis juin")
50
Base-search, + 500 sources indexées http://www.base-search.net/
Cibles internationales moissonnées serveurs de publication des universités serveurs d’archives ouvertes Bases de données et catalogues allemandes et internationales Springer mathematics Zentralblatt BNF, Numdam EuclidProjet Liste complète :

51
Recherche multilingue (21 langues en même temps)
Consultation par répertoires Dewey

52
Base-Search http://www.base-search.net/

54
Performances Navigation Classement Rapidité
Moissonnage Convivialité : pour chaque résultat Lien direct avec le texte intégral Métadonnées des différents systèmes d’information Provenance (cible) Rebonds vers Google Scholar
 Rebonds vers Google Scholar.")
55
Conclusion sur les technologies et les outils
Intérêts : Vers plus d’intelligence et de pertinence Choix des sources Sélection scientifique et par les professionnels des bibliothèques Vers plus de services Navigation par sources, mots clés, etc. grâce à la classification des sources et la catégorisation automatique (MasterKey, LibraryFind, Fast) Alerte, abonnement
 Alerte, abonnement.")
56
Limites Lenteur de certains systèmes « traditionnels » (Métalib et Jouve) liés aux nombre de connecteurs demandés Moteurs « traditionnels » restent « pauvres » en matière d’interface Résultats sous forme de liste à consulter Pas de catégorisation Cf la conclusion de l’INIST Conclusion INIST A cause de ces inconvénients (lenteur, difficulté d’accéder au texte intégral), les solutions n’ont pas provoqué d’enthousiasme
, les solutions n’ont pas provoqué d’enthousiasme.")
57
Alors, que peut-on imaginer pour les math ?
Un moteur de recherche fédérée qui serait basé sur performance et services L’accès direct à l’article Recherche multifacette Exploitation des résultats avec un minimum de connecteurs pour la rapidité 2 bases de données bibliographiques auxquelles toutes les bibliothèques de math sont abonnées Mathscinet Zentralblatt Google + Google Scholar arXiv + HAL

58
Ports forts : Inconvénients :
on couvrirait à peu près l’ensemble de la production en math, éditoriale, open access et perso Inconvénients : risque d’incomplétude et problème d’accès universels Mathscinet et Zentralblatt : accès réservés aux matheux du réseau et des universités abonnées Google Scholar ne moissonne pas toutes les ressources scientifiques Il manquerait quelques liens OpenURL vers certains articles Bruit

59
Et si on pensait à … … un projet résolument orienté web
S’inspirer des initiatives intéressantes au niveau des bibliothèques scientifiques Base-Search, université Bielefied WorldWideScience, British Library, MiniDML, cellule MathDoc,

60
Pour poursuivre : lire le résumé du « Rêve bleu » sur Figoblog Repose la question des missions des bibliothèques scientifiques à l’heure de l’Internet Propose de Capitaliser la technique des moteurs de recherche pour donner à voir un autre Google Créer un web scientifique, non pas en faisant de la recherche fédérée ou des bases de données distribuées ou en constituant des entrepôts de métadonnées OAI

61
Mais, créer un web scientifique qui serait
une sélection de ressources de qualité validées adaptés à la préservation à long terme pourvues de métadonnées Web 2.0 scientifique, documenté et ouvert coopération internationale normes fiables et ouvertes, interopérables techniques actuelles des moteurs de recherche principes participatifs Web sémantique ?

62
… Si tous les bibliothécaires du monde s’y mettaient …
Et pourquoi pas ? Le projet Wikipédia existe bien Les archives ouvertes scientifiques existent bien … Si tous les bibliothécaires du monde s’y mettaient …

Présentations similaires






 Blandine.>")











 26/03/2013Service commun de la documentation.>")

