Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
ASSEMBLEUR (ARM)
")
2
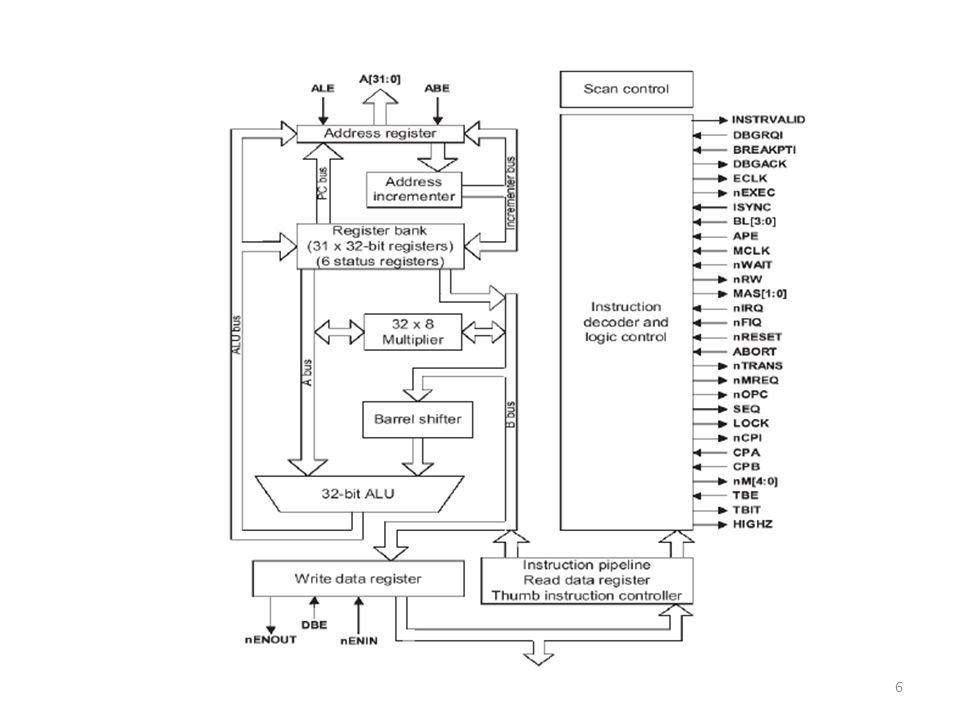
Introduction (1) Le cours d’architecture a illustré la conception d’un microprocesseur avec pour outil de modélisation les FSM le mot placé dans IR (mot instruction) contient toute l’information sur le travail a accomplir (+ opérandes) Comment éviter l’écriture directe du mot instruction + opérande (ex : E1A ) pour coder un algorithme ? utilisation d’un mnémonique + opérandes réduisant l’effort de codage (ex : movnes R0,R1,ROR R2 ) le mnémonique + op n’est qu’une représentation différente de la même information le microprocesseur n’utilise que la première représentation, c’est l’opération d’assemblage qui traduit (c’est un compilateur qui génère un code du premier type) le code assembleur en code machine
 contient toute l’information sur le travail a accomplir (+ opérandes) Comment éviter l’écriture directe du mot instruction + opérande. (ex : E1A0 0271) pour coder un algorithme utilisation d’un mnémonique + opérandes réduisant l’effort de codage (ex : movnes R0,R1,ROR R2 ) le mnémonique + op n’est qu’une représentation différente de la même information. le microprocesseur n’utilise que la première représentation, c’est l’opération d’assemblage qui traduit (c’est un compilateur qui génère un code du premier type) le code assembleur en code machine.")
3
Introduction (2) L’ensemble (mnémonique + opérandes) constitue le langage ASSEMBLEUR Rem : pour un même microprocesseur plusieurs langages assembleurs possibles (ils se distinguent surtout par les directives, macros, les pseudo-instructions …) (org 300), (a : ds.b 1), ( .data)
 (org 300), (a : ds.b 1), ( .data)")
4
Points clefs du ARM Architecture load-store
Instructions de traitement à 3 adresses Instructions conditionnelles (et branchement) Load et store multiples APCS (ARM Procedure Call Standard) En un cycle horloge: opération ALU+shift Interfaçage avec coproc. simplifié (ajout de registres, de type, …) Combine le meilleur du RISC et du CISC On le trouve dans la GBA, routeurs, Pockets PC, PDA, …
 Load et store multiples. APCS (ARM Procedure Call Standard) En un cycle horloge: opération ALU+shift. Interfaçage avec coproc. simplifié (ajout de registres, de type, …) Combine le meilleur du RISC et du CISC. On le trouve dans la GBA, routeurs, Pockets PC, PDA, …")
5
Que manipule-t-on ? Des registres Des adresses Des données
Des instructions assembleurs (32 bits) Des directives Des pseudo-instructions
 Des directives. Des pseudo-instructions.")
7
Des registres (mode User)
16 Registres de 32 bits : R0-R10, R12 : généraux R11 (fp) Frame pointer R13 (sp) Stack pointer R14 (lr) Link register R15 (pc) Program counter Current Program Status Register 7 6 5 N Z C V Pas utilisés IF T Mode
 Frame pointer. R13 (sp) Stack pointer. R14 (lr) Link register. R15 (pc) Program counter. Current Program Status Register N Z C V. Pas utilisés. IF. T. Mode.")
8
Des adresses et données
232 bytes de mémoire maxi Un word = 32 bits Un half-word = 16 bits Un byte = 8 bits Little endian (0x01AA Ad+ AA 01) En hexa (0x0F), déc (15), bin (0b )
 En hexa (0x0F), déc (15), bin (0b )")
9
Organisation mémoire adresse bit31 bit0 23 22 21 20 19 18 17 16 word16
15 14 13 12 Half-word14 Half-word12 11 10 9 8 word8 7 6 5 4 Byte6 3 2 1 byte3 byte2 byte1 byte0 adresse

10
Chaque instruction est codée sur 32 bits (uniquement) !!!
 !!!")
11
Cond (toutes les instructions !)
")
12
OpCode (data processing)
")
13
Environnement de Prog. ldrb R0,te ldrb R1,boul adc R0,R0,R1
.text directive .globl _main _start: label b _main _main: code op opmrs R0,CPSR opérandes #attention à la taille des immédiats !! ldr R1,=0xDFFFFFFF and R0,R0,R1 msr CPSR_f,R0 #autre solution:pas de masquage, on force tous les bits # msr CPSR_f,#0xD ldrb R0,mys ldrb R1,re adds R0,R0,R1 strb R0,de ldrb R0,te ldrb R1,boul adc R0,R0,R1 strb R0,gom mov pc,lr .align mys: .space 1 te: .space 1 re: .space 1 boul: .space 1 de: .space 1 gom: .space 1 .ltorg .end

14
Environnement de Prog. En « cross-compilant » (outil GNU)
En « linkant » (outil GNU) En simulant le processeur ARM EmBest Ide
 En simulant le processeur ARM. EmBest Ide.")
15
ARM-meste-2005

16
Les directives principales
Les directives sont des intructions pour l’assembleur (compilateur) uniquement, elles commencent par « . ». .align: permet d’aligner en mémoire des données de types différents .byte 0x55 .align sinon erreur à l’assemblage .word 0xAA55EE11 .ascii: permet de saisir des caractères (sans le NULL) . ascii "JNZ" insère les octets 0x4A, 0x4E, 0x5A .asciz: comme .ascii mais insère à la fin le caractère NULL . Asciz "JNZ" insère les octets 0x4A, 0x4E, 0x5A, 0x00
 uniquement, elles commencent par « . ». .align: permet d’aligner en mémoire des données de types différents. .byte 0x55. .align sinon erreur à l’assemblage. .word 0xAA55EE11. .ascii: permet de saisir des caractères (sans le NULL) . ascii JNZ insère les octets 0x4A, 0x4E, 0x5A. .asciz: comme .ascii mais insère à la fin le caractère NULL. . Asciz JNZ insère les octets 0x4A, 0x4E, 0x5A, 0x00.")
17
Les directives principales
.byte: déclare une variable type octet et initialisation var1: .byte 0x11 var2: .byte 0x22,0x33 .hword: déclare une variable type deux octets et initialisation var3: .hword 0x1122 var4: .hword 0x44 .word: déclare une variable type word (32bits) et initialisation var5: .word 0x .space: déclare une variable de taille quelconque (pas d’ initialisation) var6: .space 10 réserve 10 octets
 et initialisation. var5: .word 0x space: déclare une variable de taille quelconque (pas d’ initialisation) var6: .space 10 réserve 10 octets.")
18
Les directives principales
.equ: associe une valeur à un symbol .equ dix, 5+5 mov R3,#dix .global (ou .globl): l’étiquette (symbol) est visible globalement .global _start _start est reconnue par le linker GNU _start doit apparaître le code principal .text, .data, .bss : début de section text, data, bss (pour le linker) .end : fin du code source .ltorg : insère « ici » les constantes temporaires pour LDR = ldr R1,=0x .ltorg
: l’étiquette (symbol) est visible globalement. .global _start _start est reconnue par le linker GNU. _start doit apparaître le code principal. .text, .data, .bss : début de section text, data, bss (pour le linker) .end : fin du code source. .ltorg : insère « ici » les constantes temporaires pour LDR = ldr R1,=0x ltorg.")
19
Pseudo-instructions NOP: No operation. En ARM est remplacé par MOV R0,R0 LDR = : charge dans un registre une valeur immédiate ou une addresse ldr R0,=42 mov R0, #42 ldr R1,=0x9988CDEF ldr R1,[PC, #4] (pipeline !!!) nop .ltorg c’est ici que l’on trouve #0x9988CDEF
 nop. .ltorg c’est ici que l’on trouve #0x9988CDEF.")
20
Pseudo-instructions ldr R3,var3 ldr R3,[PC, #0]
charge dans R3 la valeur de var3 str R4,=var3 str R4,[PC, #0] écrit en mémoire l’adresse de var3 charge l’adresse de var3 var3: .word 0xAAAAAAAA .ltorg on trouve ici l’adresse de var3 REM: l’adresse de var3 est connue par l’assembleur, on peut mieux faire
![Pseudo-instructions ldr R3,var3 ldr R3,[PC, #0]](http://slideplayer.fr/slide/2825569/10/images/20/Pseudo-instructions+ldr+R3%2Cvar3+%EF%83%9E+ldr+R3%2C%5BPC%2C+%230%5D.jpg "charge dans R3 la valeur de var3. str R4,=var3 str R4,[PC, #0] écrit en mémoire l’adresse de var3. charge l’adresse de var3. var3: .word 0xAAAAAAAA. .ltorg on trouve ici l’adresse de var3. REM: l’adresse de var3 est connue par l’assembleur, on peut mieux faire.")
21
Pseudo-instructions ADR : charge dans un registre l’adresse d’une variable (load/store) adr R4, var5 add R4,PC,# (des fois sub !!!) ldr R6,[R4] nop var5: .word 0xBBBBBBBB PAS de .ltorg car l’adresse n’est pas en mémoire REM: les valeurs immédiates sont limitées en taille, si les variables sont dans .data adrl ou ldr =

22
Module de décalage Cela s’explique grâce au registre à décalage
-Le registre à décalage peut réaliser des rotations à droite également -Ne rajoute pas de cycle horloge -Ne s’utilise pas en tant qu’instruction -Permet de charger des constantes >8b -Permet des MUL rapides Opérande 1 Opérande 2 Registre à décalage C’est l’ALU

23
Module de décalage En fait 12 bits disponibles
Ils sont décomposés en 4 bits de rotations et 8 bit de valeur immédiate C’est à dire: [0-0xFF] sur 8 bits et 0 rotation Mais encore: 256, 260, …, 1020 [0x100-0x3FC]=[0x40-0xFF] ROR #30 0x3FC: 0xFF: 0xFF ror #1 ……. 0xFF ror #30 1 1 1 1

24
Module de décalage Et ainsi: 1024, 1040, …, 4080 [0x400-0xFF0]=[0x40-0xFF] ROR #28 4096, 4160, …, [0x1000-0x3FC0]=[0x40-0xFF] ROR #26 Ex: mov R1, #0x1000 mov R1,#40,26 (pas une vraie syntaxe) mov R2, #0xFFFFFFFF mvn R2,#0 mov R2, #0x génère une erreur !!! ldr R2, # 0x on a déjà vu, pas d’erreur De plus LDR gère le registre à décalage on utilise si possible LDR pour charger des constantes
![Module de décalage Et ainsi: 1024, 1040, …, 4080 [0x400-0xFF0]=[0x40-0xFF] ROR # , 4160, …, [0x1000-0x3FC0]=[0x40-0xFF] ROR #26.](http://slideplayer.fr/slide/2825569/10/images/24/Module+de+d%C3%A9calage+Et+ainsi%3A+1024%2C+1040%2C+%E2%80%A6%2C+4080+%5B0x400-0xFF0%5D%3D%5B0x40-0xFF%5D+ROR+%23+%2C+4160%2C+%E2%80%A6%2C+%5B0x1000-0x3FC0%5D%3D%5B0x40-0xFF%5D+ROR+%2326..jpg "Ex: mov R1, #0x1000 mov R1,#40,26 (pas une vraie syntaxe) mov R2, #0xFFFFFFFF mvn R2,#0. mov R2, #0x génère une erreur !!! ldr R2, # 0x on a déjà vu, pas d’erreur. De plus LDR gère le registre à décalage. on utilise si possible LDR pour charger des constantes.")
25
Module de décalage Remplace un MUL avantageusement (MOV, ADD, SUB, RSB) Ex1: R0 = R1*5 R0 = R1+(R1*4) add R0, R1, R1 lsl #2 Ex2: R2 = R3*105 R2 = R3*15*7 R2 = R3*(16-1)*(8-1) R2=(R3*16) - R3 puis R2=(R2*8)-R2 rsb R2, R3, R3, lsl #4 puis rsb R2, R2, R2, lsl #3 N’est pas remplacé par l’Assembleur !!!
*(8-1) R2=(R3*16) - R3 puis R2=(R2*8)-R2. rsb R2, R3, R3, lsl #4 puis rsb R2, R2, R2, lsl #3. N’est pas remplacé par l’Assembleur !!!")
26
Instructions On les rassemble en 3 groupes: Mouvements de données
Opérations de traitements (arith. & log.) Instructions de contrôles
 Instructions de contrôles.")
27
Instructions Règles pour le traitement des données:
Les opérandes sont 32 bits, constantes ou registres Le résultat 32 bits dans un registre 3 opérandes: 2 sources et 1 destination En signé ou non signé Peut mettre à jour les Flags (S) Le registre destination peut être un des registres sources
 Le registre destination peut être un des registres sources.")
28
Instructions (Data Flow)
Des LDR (indirect pour source), STR (indirect pour destination) Des MOV (constantes ou registre) Les LDR sont souvent remplacés par des MOV (sauf adressage indirect) LDR R1,R2 Error MOV R1,R2 OK LDR R1,=0x00FFFFFF ldr r1, [pc, #4] LDR R1,= mov r1, #1020 LDR R1,[R2] ldr r1, [r2]
, STR (indirect pour destination) Des MOV (constantes ou registre) Les LDR sont souvent remplacés par des MOV (sauf adressage indirect) LDR R1,R2 Error. MOV R1,R2 OK. LDR R1,=0x00FFFFFF ldr r1, [pc, #4] LDR R1,=1020 mov r1, #1020. LDR R1,[R2] ldr r1, [r2]")
29
Instructions (Data Flow)
En fait LDR/STR LDR/STR simple (un seul registre) SWAP simple LDR/STR multiple (une liste de registres) On utilise un registre contenant une adresse mémoire registre de base LDR R0,[R1] On charge dans R0 le word (32bits) mem[R1] STR R0,[R1] On range dans mem[R1] (4 octets) R0 L’adresse est placée dans R1 avec un ADR ou LDR (voir directives)
 SWAP simple. LDR/STR multiple (une liste de registres) On utilise un registre contenant une adresse mémoire registre de base. LDR R0,[R1] On charge dans R0 le word (32bits) mem[R1] STR R0,[R1] On range dans mem[R1] (4 octets) R0. L’adresse est placée dans R1 avec un ADR ou LDR (voir directives)")
30
Instructions (Data Flow)
Si R1 « pointe » (ADR R1,tab) sur une zone mémoire (vecteur, matrice) Rem: une zone mémoire = vecteur, matrice, tableau, … ADD R1, R1, #2 R1 pointe maintenant sur le prochain half-word LDRH R0, [R1] R0 reçoit le half-word : R0=mem16[R1] On peut utiliser une pré-indexation (R1 est modifié avant le transfert): LDRH R0, [R1,#2] R0=mem16[R1+2] R1 mis à jour ??? Quelle syntaxe ???
 sur une zone mémoire (vecteur, matrice) Rem: une zone mémoire = vecteur, matrice, tableau, … ADD R1, R1, #2 R1 pointe maintenant sur le prochain half-word. LDRH R0, [R1] R0 reçoit le half-word : R0=mem16[R1] On peut utiliser une pré-indexation (R1 est modifié avant le transfert): LDRH R0, [R1,#2] R0=mem16[R1+2] R1 mis à jour Quelle syntaxe")
31
Instructions (Data Flow)
? Rem: [R1,#4] ne modifie pas R1 ?

32
Instructions (Data Flow)
Si on veut modifier R1 « automatiquement » auto-incrémentation LDRH R0, [R1,#2]! R0=mem16[R1+2] puis R1=R1+2 Si R1 pointe toujours sur le prochain élément à charger (pile) post-indexation LDRH R0,[R1],#2 R0=mem16[R1] puis R1=R1+2 Si l’offset est variable, un registre peut le remplacer LDRH R0,[R1,R2]! R0=mem16[R1+R2] puis R1=R1+R2
 post-indexation. LDRH R0,[R1],#2 R0=mem16[R1] puis R1=R1+2. Si l’offset est variable, un registre peut le remplacer. LDRH R0,[R1,R2]! R0=mem16[R1+R2] puis R1=R1+R2.")
33
Instructions (Data Flow)
Résumé: LDR R0,[R1] indirect LDR R0, [R1, #offset] indirect pré-indexé LDR R0, [R1, #offset]! indirect pré-indexé et auto-incrémenté LDR R0, [R1], #offset indirect post-indexé et auto-incrémenté LDR R0, [R1, -R2]! indirect pré-indexé et auto-incrémenté LDR R0, [R1], -R2 indirect post-indexé et auto-incrémenté

34
Instructions (Data Flow)
Encore plus complexe : format Word

35
Instructions (Data Flow)
Un LOAD/STORE particulier: SWAP SWP R1,R2,[R3] R1 mémoire[R3] mémoire[R3] R2 Pour échanger le contenu de la mémoire avec un registre SWP R2, R2, [R3]

36
Instructions Logiques
Elles opèrent bit à bit (Elles sont très utilisées pour les E/S) Des instructions en soit: -TST, TEQ (and et eor) pas de destination, CPSR mis à jour -AND, EOR, ORR, BIC (and not) destination, CPSR mis à jour si {S} Des instructions indirectes: MOV R2,R1 LSL #5 , MOV R3,R4 LSR R6 LSL, LSR, ASR, ROR, RRX
 Des instructions en soit: -TST, TEQ (and et eor) pas de destination, CPSR mis à jour. -AND, EOR, ORR, BIC (and not) destination, CPSR mis à jour si {S} Des instructions indirectes: MOV R2,R1 LSL #5 , MOV R3,R4 LSR R6. LSL, LSR, ASR, ROR, RRX.")
37
Instructions Logiques
LSR: logical shift right ASR: arithmetic shift right ROR: rotate right RRX: rotate right extended Un seul bit remplacé par ROR #0 C C C C

38
Instructions Arithmétiques
Elles permettent l’addition, la soustraction, la multiplication Elles peuvent prendre en compte le flag C (retenue) et le mettre à jour -ADD, ADC: addition, addition plus C -SUB, SBC, RSB, RSC: soustraction, soustraction –NOT(C), inversée, … SUBS R1,R2,R3 R1=R2-R3 RSBS R1,R2,R3 R1=R3-R2 -multiplications
 et le mettre à jour. -ADD, ADC: addition, addition plus C. -SUB, SBC, RSB, RSC: soustraction, soustraction –NOT(C), inversée, … SUBS R1,R2,R3 R1=R2-R3. RSBS R1,R2,R3 R1=R3-R2. -multiplications.")
39
Multiplications MUL rd,r1,r2 rd=r1*r2 sur 32bits
MLA rd,r1,r2,r3 rd=r1*r2 + r3 sur 32bits Signés: SMULL rdlo,rdhi,r1,r2 rd=r1*r2 sur 64bits SMLAL rdlo,rdhi,r1,r2,r3 rd=r1*r2 + r3 sur 64bits NON Signés: UMULL rdlo,rdhi,r1,r2 rd=r1*r2 sur 64bits UMLAL rdlo,rdhi,r1,r2,r3 rd=r1*r2 + r3 sur 64bits

40
Instructions Arithmétiques
Un exemple de MLA: MOV R11, #20 MOV R10, #0 LOOP: LDR R0,[R8], #4 LDR R1,[R9], #4 MLA R10,R0,R1,R10 R10=R10+R0*R1 SUBS R11,R11,#1 SUB et CMP car {S} BNE LOOP C’est le produit scalaire de deux vecteurs

41
Instructions Arithmétiques
Les flags sont mis à jour avec {S} on peut également utiliser CMP (SUBS) ou CMN (ADDS) CMP R1,#5 R1-5 : les flags sont mis à jour, résultat non stocké Utilisé avant une instruction conditionnelle (ARM) Utilisé avant un branchement conditionnel (B{cond} ou B{cond}L) Associé aux structures de contrôles REM: TST (and) et TEQ (eor) pour comparaisons logiques
 ou CMN (ADDS) CMP R1,#5 R1-5 : les flags sont mis à jour, résultat non stocké. Utilisé avant une instruction conditionnelle (ARM) Utilisé avant un branchement conditionnel (B{cond} ou B{cond}L) Associé aux structures de contrôles. REM: TST (and) et TEQ (eor) pour comparaisons logiques.")
42
Inst./struct. de contrôles
Elles déroutent le cours normal du programme Basées sur le couple (CMP, B{cond}) Tests complexes (CMP{cond}) (voir TD) Elles cassent le pipeline (peut mieux faire ?) Elles servent à réaliser Les alternatives (if, case) Les itérations (for, while, repeat) Les procédures (BL) normalisation
 Tests complexes (CMP{cond}) (voir TD) Elles cassent le pipeline (peut mieux faire ) Elles servent à réaliser. Les alternatives (if, case) Les itérations (for, while, repeat) Les procédures (BL) normalisation.")
43
Inst./struct. de contrôles
If: CMP R0,R1 CMP Rn,<Operand2 BHS Else Then: B Endif Else: Endif: If Then Else: If R0 < R1 Then Else

44
Inst./struct. de contrôles
Case Of: Case R2 Of -2: -3: Otherwise: Case: mDeux: CMP R2,#-2 (remplacé par CMN R1,#2) !! BNE mTrois B Endcase mTrois: CMP R2,#-3 BNE Otherwise B Endcase Otherwise: Endcase:
 !! BNE mTrois. B Endcase. mTrois: CMP R2,#-3. BNE Otherwise. B Endcase. Otherwise: Endcase:")
45
Inst./struct. de contrôles
While do: While R3 R1 do While: CMP R3,R1 CMP Rn,<Operand2> BLT Endwhile si Rn LT Operand2 en signé # BLO Endwhile si Rn LO Operand2 en nonsigné do: B While Endwhile:

46
Inst./struct. de contrôles
For: For R3 = 1 to nfin do LDR R3,=nfin For: SUBS R3,R3,#1 décrémentation de 1 BNE For Endfor:

47
Appels de procédures, les Piles
Les procédures sont appelées avec Branch + Link (BL) Les paramètres sont passés par: Adresses (noms de variables) Par registres (taille et nombre limités) Par adresse dans des registres (nombre limité) Par adresse ou valeur dans la pile notion de pile
 Les paramètres sont passés par: Adresses (noms de variables) Par registres (taille et nombre limités) Par adresse dans des registres (nombre limité) Par adresse ou valeur dans la pile notion de pile.")
48
Appels de procédures, les Piles
.globl _start .globl _main _start: B _main _main: MOV R1,#2 MOV R2,#3 BL proc branchement à proc et LR (R14)=PC-4 (Pipeline) STR R3,res Nombre de registres limité utilisation des piles (C, JAVA) proc: ADD R3,R1,R2 MOV PC,LR
=PC-4 (Pipeline) STR R3,res. Nombre de registres limité utilisation des piles (C, JAVA) proc: ADD R3,R1,R2. MOV PC,LR.")
49
Appels de procédures, les Piles
LDR et STR n’utilisent qu’un seul registre LDM et STM utilisent plusieurs registres LDMIA R1,{R0,R2,R4} (r0=mem32[r1], r2=mem32[r1+4], r4=mem32[r1+8]) De même STMIA R1,{R0,R2,R4} (mem32[r1]=r0, mem32[r1+4]=r2, mem32[r1+8]=r4) R4 R3 R2 R1 Adresse de base R0 mémoire
 De même. STMIA R1,{R0,R2,R4} (mem32[r1]=r0, mem32[r1+4]=r2, mem32[r1+8]=r4) R4. R3. R2. R1. Adresse de base. R0. mémoire.")
50
Appels de procédures, les Piles
L’instruction LDMIA est en fait LDM + I + A LDM : Load Multiple I : Incrémentation de l’adresse de base A: l’adresse de base est incrémentée après utilisation (offset temporaire) Si LDMIA R1 !, {R2-R9} alors on charge 8 registres (32 octets) et l’offset est définitif (R1=R1+32) après utilisation Le I+A peut se remplacer par: Increment-After LDMIA STMIA Increment-Before LDMIB STMIB Decrement-After LDMDA STMDA Decrement-Before LDMDB STMDB
 Si LDMIA R1 !, {R2-R9} alors on charge 8 registres (32 octets) et l’offset est définitif (R1=R1+32) après utilisation. Le I+A peut se remplacer par: Increment-After LDMIA STMIA. Increment-Before LDMIB STMIB. Decrement-After LDMDA STMDA. Decrement-Before LDMDB STMDB.")
51
Appels de procédures, les Piles
STMIA r9!,{r0,r1,r5} R1 R9 R0 R9’ R5 R1 STMIB r9!,{r0,r1,r5} R0 R9 STMDA r9!,{r0,r1,r5} R9 R5 R1 R0 R9’ STMDB r9!,{r0,r1,r5} R9 R5 R1 R9’ R0

52
Appels de procédures, les Piles
Ces instructions permettent l’implémentation de Piles (PUSH et POP) : PUSH : STMIA POP : LDMDB Le sommet de pile est un emplacement vide et on empile vers les add A ou B ??? Pas si simple Dans la terminologie ARM, les instructions de piles sont des STM STMIA STMED (E: emplacement Empty; D: adresses Descending) LDMIB LDMED Et R13 (SP) est considéré comme le pointeur de pile
 : PUSH : STMIA. POP : LDMDB. Le sommet de pile est un emplacement vide et on empile vers les add. A ou B Pas si simple. Dans la terminologie ARM, les instructions de piles sont des STM. STMIA STMED (E: emplacement Empty; D: adresses Descending) LDMIB LDMED. Et R13 (SP) est considéré comme le pointeur de pile.")
53
Appels de procédures, les Piles
On obtient alors les couples (PUSH/POP) possibles avec: emplacement Empty (E),Full (F) adresses Descending (D),Ascending (A) STMFA/LDMFA STMFD/LDMFD STMEA/LDMEA STMED/LDMED Ces piles sont utilisées pour le passage de paramètres aux procédures avec normalisation (ARM Procedure Call Standard) ou non
 possibles avec: emplacement Empty (E),Full (F) adresses Descending (D),Ascending (A) STMFA/LDMFA. STMFD/LDMFD. STMEA/LDMEA. STMED/LDMED. Ces piles sont utilisées pour le passage de paramètres aux procédures. avec normalisation (ARM Procedure Call Standard) ou non.")
54
Appels de procédures, les Piles
Utilisation efficace des piles en appel de procédure : On passe les paramètres par la pile, ou les registres La procédure sauvegarde tous les registres de travail (le prog appelant ne voit pas les changements) La procédure sauvegarde le LR (elle peut appeler une autre procédure) La procédure restaure les registres sauvegardés avant le retour
 La procédure sauvegarde le LR (elle peut appeler une autre procédure) La procédure restaure les registres sauvegardés avant le retour.")
55
Appels de procédures, les Piles
.globl _start .globl _main _start: B _main _main: MOV R1,#2 MOV R2,#3 (A) STMED R13!,{R1,R2} (B) BL proc (F) ADD R13,R13,#8 (G) STR R3,res proc: STMED R13!,{R1-R2,R14} LDR R1,[R13,#16] LDR R2,[R13,#20] ADD R3,R1,R2 (C) LDMED R13!,{R1-R2,R14} MOV PC,R14 Rem: (C) et (D) peuvent être remplacé par: LDMED R13!,{R1-R2,PC} R13 (C) (B),(D) (A),(G) AD+ 4 octets R1 R2 R14
 STMED R13!,{R1,R2} (B) BL proc. (F) ADD R13,R13,#8. (G) STR R3,res. proc: STMED R13!,{R1-R2,R14} LDR R1,[R13,#16] LDR R2,[R13,#20] ADD R3,R1,R2. (C) LDMED R13!,{R1-R2,R14} MOV PC,R14. Rem: (C) et (D) peuvent être remplacé par: LDMED R13!,{R1-R2,PC} R13. (C) (B),(D) (A),(G) AD+ 4 octets. R1. R2. R14.")
56
Appels de procédures,APCS (réduit)
Le APCS (ARM Procedure Call Standard) fournit un mécanisme standardisé permettant d’associer des routines C, assembleur, … En définissant: Restrictions sur l’utilisation des registres Convention d’utilisation de la pile Convention de passage de paramètres Structuration du contexte de la procédure dans la pile Il existe plusieurs versions de APCS
 fournit un mécanisme standardisé permettant d’associer des routines C, assembleur, … En définissant: Restrictions sur l’utilisation des registres. Convention d’utilisation de la pile. Convention de passage de paramètres. Structuration du contexte de la procédure dans la pile. Il existe plusieurs versions de APCS.")
57
Appels de procédures, APCS
Les registres prennent des noms particuliers: R10 : SL (stack limit) R11 : FP (frame pointer) R12 : IP (scratch register) R13 : SP (stack pointer) R14 : LR (link register) R15 : PC Et R0-R3 : A1-A4 arguments de proc/registres de travails/résultats R4-R9 : V1-V variable registre
 R11 : FP (frame pointer) R12 : IP (scratch register) R13 : SP (stack pointer) R14 : LR (link register) R15 : PC. Et R0-R3 : A1-A4 arguments de proc/registres de travails/résultats. R4-R9 : V1-V6 variable registre.")
58
Appels de procédures, APCS
La pile (et les différents registres) permet de conserver une structure d’appel pour les appels imbriqués: Sauvegarde PC LR SP FP … Contexte p4 Sauvegarde PC LR SP FP … Contexte p3 Sauvegarde PC LR SP FP … Contexte p2 Sauvegarde PC LR SP FP … Contexte p1
 permet de conserver une structure d’appel pour les appels imbriqués: Sauvegarde PC. LR. SP. FP. … Contexte p4. Sauvegarde PC. LR. SP. FP. … Contexte p3. Sauvegarde PC. LR. SP. FP. … Contexte p2. Sauvegarde PC. LR. SP. FP. … Contexte p1.")
59
Appels de procédures, APCS
Exemple int somme(int x1, int x2, int x3, int x4, int x5) { return x1+x2+x3+x4+x5; } //extern int somme(int x1, int x2, int x3, int x4, int x5); int __main() { somme(2,3,4,5,6); } .text .global somme .type somme,function somme: mov ip, sp stmfd sp!, {fp, ip, lr, pc} sub fp, ip, #4 sub sp, sp, #16 str r0, [fp, #-16] str r1, [fp, #-20] str r2, [fp, #-24] str r3, [fp, #-28] ldr r2, [fp, #-16] ldr r3, [fp, #-20] add r3, r2, r3 ldr r2, [fp, #-24] add r3, r3, r2 ldr r2, [fp, #-28] ldr r2, [fp, #4] mov r0, r3 ldmea fp, {fp, sp, pc} .global __main __main: mov ip, sp stmfd sp!, {fp, ip, lr, pc} sub fp, ip, #4 sub sp, sp, #4 mov r3, #6 str r3, [sp, #0] mov r0, #2 mov r1, #3 mov r2, #4 mov r3, #5 bl somme ldmea fp, {fp, sp, pc}
 { return x1+x2+x3+x4+x5; } //extern int somme(int x1, int x2, int x3, int x4, int x5); int __main() { somme(2,3,4,5,6); } .text. .global somme. .type somme,function. somme: mov ip, sp. stmfd sp!, {fp, ip, lr, pc} sub fp, ip, #4. sub sp, sp, #16. str r0, [fp, #-16] str r1, [fp, #-20] str r2, [fp, #-24] str r3, [fp, #-28] ldr r2, [fp, #-16] ldr r3, [fp, #-20] add r3, r2, r3. ldr r2, [fp, #-24] add r3, r3, r2. ldr r2, [fp, #-28] ldr r2, [fp, #4] mov r0, r3. ldmea fp, {fp, sp, pc} .global __main. __main: mov ip, sp. stmfd sp!, {fp, ip, lr, pc} sub fp, ip, #4. sub sp, sp, #4. mov r3, #6. str r3, [sp, #0] mov r0, #2. mov r1, #3. mov r2, #4. mov r3, #5. bl somme. ldmea fp, {fp, sp, pc}")
60
Appels de procédures, APCS
Restauration des registres somme: mov ip, sp SP(1) stmfd sp!, {fp, ip, lr, pc} SP(2) (STMDB) sub fp, ip, #4 FP(1) . FP(1) ldmea fp, {fp, sp, pc} SP(1) (LDMDB) SP(2) FP(1) SP(1) AD+ 4 octets FP IP (sp(1)) LR PC
 stmfd sp!, {fp, ip, lr, pc} SP(2) (STMDB) sub fp, ip, #4 FP(1) . FP(1) ldmea fp, {fp, sp, pc} SP(1) (LDMDB) SP(2) FP(1) SP(1) AD+ 4 octets. FP. IP (sp(1)) LR. PC.")
61
Appels de procédures, APCS
.text .global somme .type somme,function somme: mov ip, sp SP(3) stmfd sp!, {fp, ip, lr, pc} SP(4) sub fp, ip, #4 FP(2) sub sp, sp, #16 SP(5) str r0, [fp, #-16] str r1, [fp, #-20] str r2, [fp, #-24] str r3, [fp, #-28] ldr r2, [fp, #-16] ldr r3, [fp, #-20] add r3, r2, r3 ldr r2, [fp, #-24] add r3, r3, r2 ldr r2, [fp, #-28] ldr r2, [fp, #4] mov r0, r3 ldmea fp, {fp, sp, pc} SP(3) __main: mov ip, sp SP(1) stmfd sp!, {fp, ip, lr, pc} SP(2) sub fp, ip, #4 FP(1) sub sp, sp, #4 SP(3) mov r3, #6 str r3, [sp, #0] mov r0, #2 mov r1, #3 mov r2, #4 mov r3, #5 bl somme ldmea fp, {fp, sp, pc} SP(1) SP(5) SP(4) FP(2) SP(3) SP(2) FP(1) SP(1) R3so R2so R1so R0so FPso IPso LRso PCso R3ma Fpma IPma LRma PCma
 stmfd sp!, {fp, ip, lr, pc} SP(4) sub fp, ip, #4 FP(2) sub sp, sp, #16 SP(5) str r0, [fp, #-16] str r1, [fp, #-20] str r2, [fp, #-24] str r3, [fp, #-28] ldr r2, [fp, #-16] ldr r3, [fp, #-20] add r3, r2, r3. ldr r2, [fp, #-24] add r3, r3, r2. ldr r2, [fp, #-28] ldr r2, [fp, #4] mov r0, r3. ldmea fp, {fp, sp, pc} SP(3) __main: mov ip, sp. SP(1) stmfd sp!, {fp, ip, lr, pc} SP(2) sub fp, ip, #4 FP(1) sub sp, sp, #4 SP(3) mov r3, #6. str r3, [sp, #0] mov r0, #2. mov r1, #3. mov r2, #4. mov r3, #5. bl somme. ldmea fp, {fp, sp, pc} SP(1) SP(5) SP(4) FP(2) SP(3) SP(2) FP(1) SP(1) R3so. R2so. R1so. R0so. FPso. IPso. LRso. PCso. R3ma. Fpma. IPma. LRma. PCma.")
62
Appels de procédures, APCS
Dans ce cas, on passe l’adresse du résultat !!! (5 arguments) void somme(int x1, int x2, int x3, int x4, int *x) { *x= x1+x2+x3+x4; } int __main() { int c; somme(2,3,4,5,&c); } .text .global somme .type somme,function somme: mov ip, sp SP(3) stmfd sp!, {fp, ip, lr, pc} SP(4) sub fp, ip, #4 FP(2) sub sp, sp, #16 SP(5) str r0, [fp, #-16] str r1, [fp, #-20] str r2, [fp, #-24] str r3, [fp, #-28] ldr r2, [fp, #-16] ldr r3, [fp, #-20] add r2, r2, r3 ldr r3, [fp, #-24] add r2, r2, r3 ldr r3, [fp, #-28] ldr r3, [fp, #4] str r2, [r3, #0] ldmea fp, {fp, sp, pc} SP(3) __main: mov ip, sp SP(1) stmfd sp!, {fp, ip, lr, pc} SP(2) sub fp, ip, #4 FP(1) sub sp, sp, #4 SP(3) sub r3, fp, #16 str r3, [sp, #0] mov r0, #2 mov r1, #3 mov r2, #4 mov r3, #5 bl somme ldmea fp, {fp, sp, pc} SP(1)
 void somme(int x1, int x2, int x3, int x4, int *x) { *x= x1+x2+x3+x4; } int __main() { int c; somme(2,3,4,5,&c); } .text. .global somme. .type somme,function. somme: mov ip, sp. SP(3) stmfd sp!, {fp, ip, lr, pc} SP(4) sub fp, ip, #4 FP(2) sub sp, sp, #16 SP(5) str r0, [fp, #-16] str r1, [fp, #-20] str r2, [fp, #-24] str r3, [fp, #-28] ldr r2, [fp, #-16] ldr r3, [fp, #-20] add r2, r2, r3. ldr r3, [fp, #-24] add r2, r2, r3. ldr r3, [fp, #-28] ldr r3, [fp, #4] str r2, [r3, #0] ldmea fp, {fp, sp, pc} SP(3) __main: mov ip, sp. SP(1) stmfd sp!, {fp, ip, lr, pc} SP(2) sub fp, ip, #4 FP(1) sub sp, sp, #4 SP(3) sub r3, fp, #16. str r3, [sp, #0] mov r0, #2. mov r1, #3. mov r2, #4. mov r3, #5. bl somme. ldmea fp, {fp, sp, pc} SP(1)")
63
Procédures particulières
Les Exceptions et les Interruptions auxquelles on associe: Des modes particuliers (autres que normal user mode) privilégiés Des valeurs particulières des bits [4:0] du CPSR De nouveaux registres Elles sont générées: Comme étant un résultat d’une instruction (SWI, instruction illégale, erreur mémoire en FETCH) Par un effet de bord d’une instruction (erreur mémoire data, division par zéro) En réponse à un signal extérieure (reset, Fast Interrupt FIQ, Normal interrupt)
 privilégiés. Des valeurs particulières des bits [4:0] du CPSR. De nouveaux registres. Elles sont générées: Comme étant un résultat d’une instruction (SWI, instruction illégale, erreur mémoire en FETCH) Par un effet de bord d’une instruction (erreur mémoire data, division par zéro) En réponse à un signal extérieure (reset, Fast Interrupt FIQ, Normal interrupt)")
64
Procédures particulières
De nouveaux registres

65
Procédures particulières
Quand une exception est levée: Le mode système est modifié (fonction du type) PC est sauvegardé dans le R14 correspondant CPSR est sauvegardé dans un Save Processor Status Register (SPSR) Utilise la notion de priorité Force le PC à l’adresse de l’exception correspondante (Branch) Cette adresse est stockée dans un tableau d’adresses (vecteurs) Le microprocesseur « détermine » quel vecteur pour quelle exception (reset: premier vecteur du tableau donc 0x , …)
 PC est sauvegardé dans le R14 correspondant. CPSR est sauvegardé dans un Save Processor Status Register. (SPSR) Utilise la notion de priorité. Force le PC à l’adresse de l’exception correspondante (Branch) Cette adresse est stockée dans un tableau d’adresses (vecteurs) Le microprocesseur « détermine » quel vecteur pour quelle exception. (reset: premier vecteur du tableau donc 0x , …)")
Présentations similaires


![[number 1-100].](/1/172887/big_thumb.jpg "[number 1-100].>")









 UE 303 Promo. M2 IST-IE 2005/06 Conception dun système d'information multimédia Architecture trois-tiers : PHP/MySQL &>")






