Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Traitement Automatique des Langues
Évaluation et Traitement Automatique des Langues Patrick Paroubek Laboratoire pour la Mécanique et les Sciences de l’Ingénieur Centre National de la Recherche Scientifique Patrick Paroubek / Limsi-CNRS

2
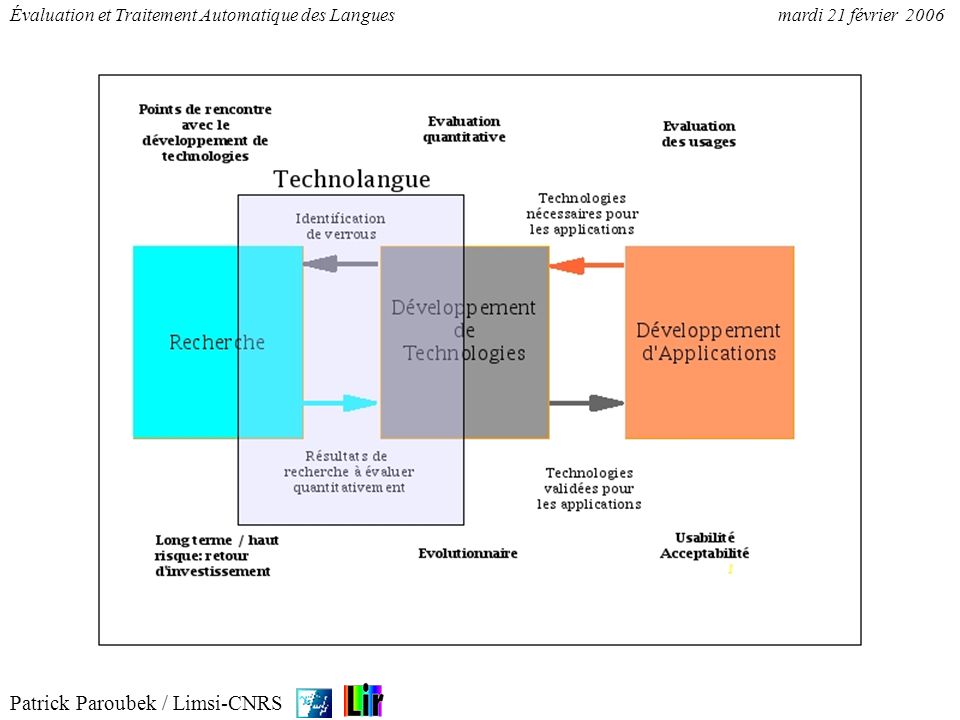
Le paradigme d’évaluation
Contrastes Historiques Europe / États-Unis Le traitement de l’écrit Annoter (Kappa) & Aligner (Prog. Dyn.) & Évaluer (Précision/Rappel) Morphosyntaxe Syntaxe Remarque sur l’évaluation des systèmes de dialogue
 & Aligner (Prog. Dyn.) & Évaluer (Précision/Rappel) Morphosyntaxe. Syntaxe. Remarque sur l’évaluation des systèmes de dialogue.")
3
1. Le paradigme d’évaluation

4
Évaluation : subst fém. Action d’évaluer, d’apprécier la valeur (d’un chose); technique, méthode d’estimation. [TLFI] L’évaluation est "une formalisation" d’un processus de sélection naturelle. L’évaluation est inhérente au processus scientifique. Trouver une réponse (optimale) à un problème. Comment comparer les réponses ? L’évaluation nécessite l’adoption d’un système de valeurs.
![Évaluation : subst fém. Action d’évaluer, d’apprécier la valeur (d’un chose); technique, méthode d’estimation. [TLFI]](http://slideplayer.fr/slide/507708/2/images/4/%C3%89valuation+%3A+subst+f%C3%A9m.+Action+d%E2%80%99%C3%A9valuer%2C+d%E2%80%99appr%C3%A9cier+la+valeur+%28d%E2%80%99un+chose%29%3B+technique%2C+m%C3%A9thode+d%E2%80%99estimation.+%5BTLFI%5D.jpg "L’évaluation est une formalisation d’un processus de. sélection naturelle. L’évaluation est inhérente au processus scientifique. Trouver une réponse (optimale) à un problème. Comment comparer les réponses L’évaluation nécessite l’adoption d’un système de valeurs.")
5
Qu’évalue t’on ? (identifier la frontière du système et la tâche effectuée par le système)
Évalue t’on un système ou un couple système-utilisateur ? Par rapport à quel système de valeurs ? Par rapport à quel objectif ? (réponse apportée par l’évaluation). Rem. L’évaluation n’est pas une compétition (compétition = qui ? , évalution = comment ?)
. Rem. L’évaluation n’est pas une compétition (compétition = qui , évalution = comment )")
6
L’évaluation fait peur (sélection/compétition).
Le rapport ALPAC 1966 a engendré un arrêt des financements aux USA pour la Traduction Automatique pendant 20 ans. Mais ce qui est dangereux n’est pas l’évaluation, mais la manière dont on utilise ses résultats. Par ex. une lecture abusive du livre de Minsky & Papert (Perceptrons) a retardé l’avènement des réseaux de neurones multi-couches d’une dizaine d’années. Maghi King, « When is the next ALPAC report due? », 10th International Conference on Computational Linguistics, Proceedings of Coling84, July 1984, Stanford University, Ca (ACL 1984); p
 a retardé l’avènement des réseaux de neurones multi-couches d’une dizaine d’années. Maghi King, « When is the next ALPAC report due », 10th International Conference on Computational Linguistics, Proceedings of Coling84, July 1984, Stanford University, Ca (ACL 1984); p")
7
Les campagnes d’évaluations sont un accélérateur du processus scientifique: ressources, outils, standards, infrastructure, synergie. LDC (http :// aux USA et ELRA/ELDA en Europe (http :// ou Objectif : créer, maintenir, distribuer, partager des ressources linguistiques. LDC = Linguistic Data Consortium, consortium ouvert de laboartoires de recherche, univsertités, industriels et agences gouvernementales, fondé en 1992 (ARPA et NSF), hébergé à l’Université Pennsylvania.
, hébergé à l’Université Pennsylvania.")
8
ELRA association à buts non lucratifs (loi 1901), basée au Luxembourg, fondée en février 1995.
ELDA, S.A. fondée en février 1995, instrument exécutif d’ELRA. Financement Européen initial, puis auto-financement. Objectif: pérenniser/partager les ressources produites par les projets Européens, ainsi que produire de nouvelles ressources. Impact de l’évaluation : Ex. Progrès en reconnaissance de Parole grace aux évaluations DARPA aux USA qui ont amené la technologie sur le marché.

9
Compétition: 1 critère, ordre total, pas d’audit de performance, pas de reproductibilité
Validation : plusieurs critères, ordre partiel, seuil de performance, réponse oui/non, reproductibilité Évaluation: plusieurs critères, ordre partiel, audit de performance, reproductibilité.

10
ELSE distingue : 5 types d’évaluations:
ELSE: http: //

11
Évaluation en recherche de base, pour valider des idées nouvelles et quantifier leur apport,
Évaluation de technologie, mesure de la performance et de l’adéquation de méthodes pour résoudre un problème bien défini, simplifié et abstrait, Évaluation orientée utilisateur, utilisabilité d’une technologie pour résoudre un problème de terrain, en conditions réelles d’utilisation, Évaluation d’impact, conséquences socio-économique du déploiement d’une technologie, Évaluation de programme, évaluation d’impact des technologies supportées par un programme institutionnel.

12
« extrinsic » / « intrinsic » evaluation criteria,
Intrinsèque = critère lié uniquement à la fonction propre du système Extrinsèque = critère lié à la fonction du système, considérée dans son environnement de déploiement usuel. Karen Spark-Jones & Julia R. Galliers, « Evaluating Natural Language Processing Systems », Springer, 1995.

13
EAGLES distingue 3 types d’évaluation:
« adequacy » evaluation, adéquation d’un système pour une fonction donnée « diagnostic » evaluation, identification des raisons de dysfonctionnement « progress » evaluation, mesure des progrès en performance EAGLES : http: // (evalutation of NLP systems : final report, )
")
14
Qualitative (morpholympics)
Quantitative (NIST/DARPA, Technolangue-EVALDA) Comparative (NIST/DARPA, Technolangue-EVALDA) Boîte « noire » (NIST/DARPA, Technolangue-EVALDA) Boîte « blanche » (DISC) Subjective (morpholympics) Objective (NIST/DARPA, Technolangue-EVALDA)
 Comparative (NIST/DARPA, Technolangue-EVALDA) Boîte « noire » (NIST/DARPA, Technolangue-EVALDA) Boîte « blanche » (DISC) Subjective (morpholympics) Objective (NIST/DARPA, Technolangue-EVALDA)")
15
Le paradigme d’évaluation (Joseph Mariani)
Assembler des acteurs (évaluateurs, participants, producteurs de ressources) Organiser une campagne d’évaluation sur de données communes Définir une mesure de performance commune Joseph Mariani, Patrick Paroubek, "Human Language Technologies Evaluation in the European Framework", actes de l'atelier DARPA Broadcast News Workshop, Whashington, February 1999, Morgan Kaufman Publishers, ISBN , pp
 Organiser une campagne d’évaluation sur de données communes. Définir une mesure de performance commune. Joseph Mariani, Patrick Paroubek, Human Language Technologies Evaluation in the European Framework , actes de l atelier DARPA Broadcast News Workshop, Whashington, February 1999, Morgan Kaufman Publishers, ISBN , pp")
16
Une infrastructure pour l ’évaluation en ingéniérie
linguistique : Comparative & Collaborative Tâche/Application Indépendente Semi-Automatique & Reproduisible Boîte Noire + Conférence Quantitative Multilingue Oral & écrit

17
Actors in the infrastructure
European Commission ELRA Evaluators Participants (EU / non EU) L. R. Producers Research Industry Citizens Users & Customers
 L. R. Producers. Research. Industry. Citizens. Users & Customers.")
18
Attentes: Renforcement de l’utilisation des standards Des informations et des connaissances sur les applications et les technologies disponibles de meilleur qualité et plus abondantes Des produits et des ressources de meilleurs qualité Un accroissement de la quantité de ressources linguistiques annotées et validées

19
Structure d’une campagne
Phase 1 - Développement (distribution calibrage / données d’entrainement) Phase 2 - Essais + première Adjudication (+ Conférence/Atelier) Phase 3 - Tests + seconde Adjudication Conférence/Atelier Phase 4 - Valorisation (distribution des données produites et des résultats) Phase 4 - Étude d ’Impact
 Phase 2 - Essais + première Adjudication (+ Conférence/Atelier) Phase 3 - Tests + seconde Adjudication + Conférence/Atelier. Phase 4 - Valorisation (distribution des données produites et des résultats) Phase 4 - Étude d ’Impact.")
20
La tâche de contrôle La fonction de traitement du language doit être facile a comprendre Elle peut être réalisée manuellement Il peut s’agir d’une tâche « artificielle » Il existe un formalisme commun, facilement accessible (projection/transcodage aisé) Il est « facile » de définir une mesure de performance
 Il est « facile » de définir une mesure de performance.")
21
2. Contrastes Historiques Europe / États-Unis

22
Contexte international
États-Unis Campagnes d ’évaluation NIST - DARPA Depuis 1987, ouvertes en 1992 Ecrit / Oral Production / distribution des ressources (LDC) Organisation des campagnes (NIST) Traitement du Langage Parlé Dictée Vocale (RM, WSJ, NAB) Compréhension de la langue parlée (ATIS) Transcription infos radio/télédiffusées (BN) Reconnaissance de conversations (switchboard) Reconnaissance du locuteur Reconnaissance de la langue parlée
 Organisation des campagnes (NIST) Traitement du Langage Parlé. Dictée Vocale (RM, WSJ, NAB) Compréhension de la langue parlée (ATIS) Transcription infos radio/télédiffusées (BN) Reconnaissance de conversations (switchboard) Reconnaissance du locuteur. Reconnaissance de la langue parlée.")
24
Contexte international
États-Unis Traitement du Langage Écrit Recherche d’Informations Textuelles (TREC) Compréhension de Messages (MUC) Traduction Automatique Traitement du Langage Écrit + Parlé Extraction d’Entités Nommées (dans BN) Détection et Suivi de Thèmes (TDT) (dans BN) Reconnaissance de caractères etc...
 Compréhension de Messages (MUC) Traduction Automatique. Traitement du Langage Écrit + Parlé. Extraction d’Entités Nommées (dans BN) Détection et Suivi de Thèmes (TDT) (dans BN) Reconnaissance de caractères etc...")
25
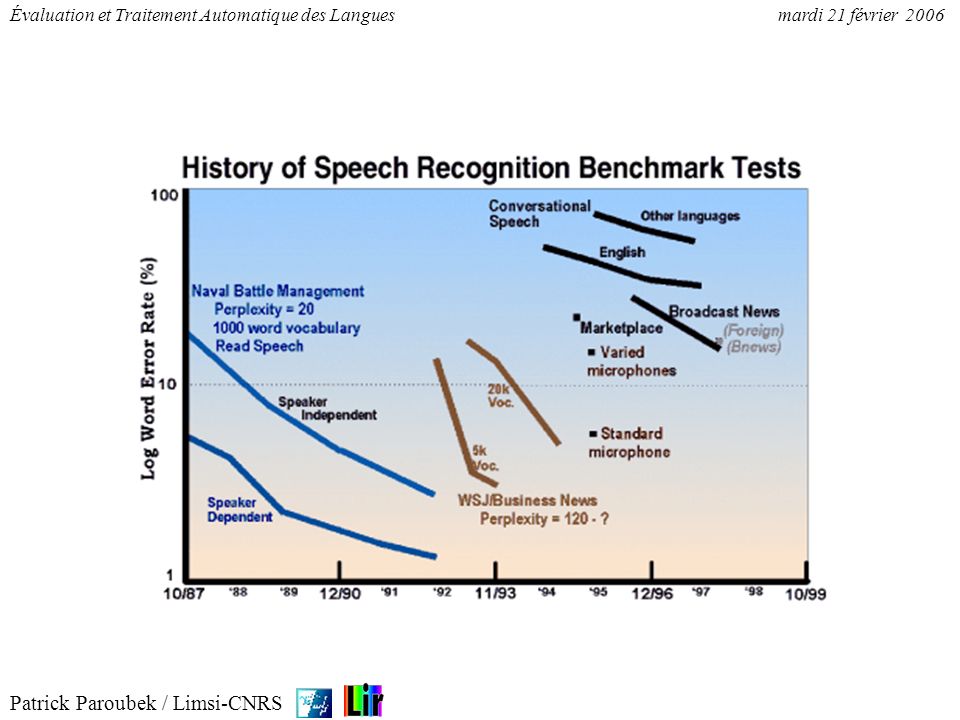
Évaluation aux USA (Parole)
CSR (DARPA) read & found english, 89-97 LVCSR conversationel, multilingue ATIS (DARPA) DARPA/NSF en 1998 (multilingue): Extraction d ’entité nommées Détection et suivit de thèmes Transcription de nouvelles COMMUNICATOR
 read & found english, LVCSR conversationel, multilingue. ATIS (DARPA) DARPA/NSF en 1998 (multilingue): Extraction d ’entité nommées. Détection et suivit de thèmes. Transcription de nouvelles. COMMUNICATOR.")
26
Traitement Automatique des Langues
et Industrie de la Langue Évaluation (USA) COMMUNICATOR dialogue oral pour la réservation de transport, l’hébergement et planification d’itinéraire TIDES extraction d’information interlingue, traduction et résumé automatique Patrick Paroubek / Limsi-CNRS
 COMMUNICATOR dialogue oral pour la réservation de transport, l’hébergement et planification d’itinéraire. TIDES extraction d’information interlingue, traduction et résumé automatique. Patrick Paroubek / Limsi-CNRS.")
27
ITR (NSF) recherche en technologie de l'information)
Traitement Automatique des Langues et Industrie de la Langue Évaluation (USA) AQUAINT (Defense Ministry) programme de l’ ARDA, extraction d'information étendue en amont et en aval sur des données multimodales, pour incorporer des connaissances à des données factuelles du types de celles manipulées dans les évaluations TREC ITR (NSF) recherche en technologie de l'information) Patrick Paroubek / Limsi-CNRS
 AQUAINT (Defense Ministry) programme de l’ ARDA, extraction d information étendue en amont et en aval sur des données multimodales, pour incorporer des connaissances à des données factuelles du types de celles manipulées dans les évaluations TREC. ITR (NSF) recherche en technologie de l information) Patrick Paroubek / Limsi-CNRS.")
28
Traitement Automatique des Langues
et Industrie de la Langue Évaluation (USA) SYMPHONY (DARPA) suite de COMMUNICATOR et dont les objectifs sont : la reconnaissance de la parole robuste en milieu bruité, le compte rendu automatique de réunion, la fusion de données multimodales, l'interprète automatique, les interfaces homme-machine dialogiques, la traduction automatique (déjà présente dans le programme TIDES), et l'exploitation rapide et automatique de langues nouvelles Patrick Paroubek / Limsi-CNRS
 SYMPHONY (DARPA) suite de COMMUNICATOR et dont les objectifs sont : la reconnaissance de la parole robuste en milieu bruité, le compte rendu automatique de réunion, la fusion de données multimodales, l interprète automatique, les interfaces homme-machine dialogiques, la traduction automatique (déjà présente dans le programme TIDES), et l exploitation rapide et automatique de langues nouvelles. Patrick Paroubek / Limsi-CNRS.")
29
Évaluation aux USA (écrit)
Tipster program (DARPA & NIST) MUC-1 (1987) to MUC-7 (1998) MET-1 (1995) and MET-2 (1998) TREC-1 (1992) to TREC-7 (1998) SUMMAC MT Evaluation (1992, 1993, 1994)
 MUC-1 (1987) to MUC-7 (1998) MET-1 (1995) and MET-2 (1998) TREC-1 (1992) to TREC-7 (1998) SUMMAC. MT Evaluation (1992, 1993, 1994)")
30
Les directions de recherche favorisées par le DARPA:
Traitement Automatique des Langues et Industrie de la Langue Évaluation (USA) Les directions de recherche favorisées par le DARPA: les technologies robustes à large couverture, les technologie de base largement réutilisables, la multilingualité, le partage des données ( LDC) les corpus arborés (U. Penn) les évaluation comparatives supportées par des métriques quantitatives, les expériences d'intégration et de faisabilité L’objectif à plus long terme étant la compréhension du langage Patrick Paroubek / Limsi-CNRS
 Les directions de recherche favorisées par le DARPA: les technologies robustes à large couverture, les technologie de base largement réutilisables, la multilingualité, le partage des données ( LDC) les corpus arborés (U. Penn) les évaluation comparatives supportées par des métriques quantitatives, les expériences d intégration et de faisabilité L’objectif à plus long terme étant la compréhension du langage. Patrick Paroubek / Limsi-CNRS.")
31
Contexte international
Japon, National Institute of Informatics (http :// Research Center for Information Ressources (test collection for IR systems) Research Center for Testbeds and Prototyping (scholarly information retrieval) Cocosda / Oriental Cocosda (International Committee for the Coordination and Standardisation of Speech Databases and Assesment Techniques) Conférences : HLT workshop 02, 03, 04, 06 LREC conference 98, 00, 02, 04, 06 LangTech conference 02, 03,
 Research Center for Testbeds and Prototyping (scholarly information retrieval) Cocosda / Oriental Cocosda (International Committee for the Coordination and Standardisation of Speech Databases and Assesment Techniques) Conférences : HLT workshop 02, 03, 04, 06. LREC conference 98, 00, 02, 04, 06. LangTech conference 02, 03,")
32
Évaluation en Europe EAGLES TSNLP DIET TEMAA SQALE SPARKLE DISC MATE COCOSDA SAM & SAM-A Morpholympics Actions de recherche concerté de l’AUPELF GRACE (CNRS) VerbMobil
 VerbMobil.")
33
Pilot Senseval / Romanseval
Task: Word Sense Disambiguating (Senseval/English) 20 nouns, 20 adjectives and 20 verbs Romanseval, same task in French & Italian. 8 month (December September 1998) 35 teams interested / 21 systems evaluated Senseval: FR, USA, IT, UK, CH, KO, MA, CA, SP, NL Romanseval: FR, IT, CH Budget :61 KEuros(English) Data, hardware and computing for free. Evaluatees not funded.
 20 nouns, 20 adjectives and 20 verbs. Romanseval, same task in French & Italian. 8 month (December September 1998) 35 teams interested / 21 systems evaluated. Senseval: FR, USA, IT, UK, CH, KO, MA, CA, SP, NL. Romanseval: FR, IT, CH. Budget :61 KEuros(English) Data, hardware and computing for free. Evaluatees not funded.")
34
SQALE Project Duration 1993 to 1995. Evaluation of 3 different ASR
3 languages + 1 common (Fr., Germ., UK Eng. + US Eng.) TNO-IZF (NL), Philips (D), U. Cambridge (UK), Limsi-CNRS (F) Task: dictation of newspaper texts Result: If a system is better on the common language than another system, it will also be better on its own language. Comparison with human performance was studied.
 TNO-IZF (NL), Philips (D), U. Cambridge (UK), Limsi-CNRS (F) Task: dictation of newspaper texts. Result: If a system is better on the common language than another system, it will also be better on its own language. Comparison with human performance was studied.")
35
DISC Project Reference methodology for SLDS development.
Best practice development and evaluation (existing components & procedures) Results: Guidelines and Heuristics 2 Guiding principles: Grid Aspects of SLDS components and Development Lifecycle of SLDS 7 Participants: NIS (DK), LIMSI (F), IMS (D), KTH (S), Vocalis (UK), D-Benz (D), ELSNET (NL) Duration: 1 year (1998) Follow-up: DISC-2 (January 1999) information update, packaging, access and usability
 Results: Guidelines and Heuristics. 2 Guiding principles: Grid Aspects of SLDS components and Development Lifecycle of SLDS. 7 Participants: NIS (DK), LIMSI (F), IMS (D), KTH (S), Vocalis (UK), D-Benz (D), ELSNET (NL) Duration: 1 year (1998) Follow-up: DISC-2 (January 1999) information update, packaging, access and usability.")
36
DISC Project

37
EAGLES Evaluation WG EAGLES was launched in 1993
Aim: standards for NLP technology (including evaluation) Eval. working group started from ISO 9126 (software) User-oriented methodology (consumer report paradigm) for adequacy evaluation or progress evaluation Formalism (based on feature structures) for classifying products and users. Case studies on: spelling checkers (LRE-TEMAA), grammar checkers and translators’ aids. Follow-up: EAGLES-II ( ), consolidate, extend and disseminate EAGLES results.
 Eval. working group started from ISO 9126 (software) User-oriented methodology (consumer report paradigm) for adequacy evaluation or progress evaluation. Formalism (based on feature structures) for classifying products and users. Case studies on: spelling checkers (LRE-TEMAA), grammar checkers and translators’ aids. Follow-up: EAGLES-II ( ), consolidate, extend and disseminate EAGLES results.")
38
ELSE Project Evaluation in Language and SpeechEngineering 8 partners: MIP (DK), LIMSI (FR), DFKI (D), U. Pisa (I), EPFL (CH), XRCE (FR), U. Sheffiel (UK), CECOJI (FR) + ELSNET & ELRA Duration: January April Budget: 414 KECU Draw a blueprint for an evaluation infrastructure (IST Key Actions of FP5 ?) Evaluation Paradigm: contrastive quantitative Technology Evaluation.
, LIMSI (FR), DFKI (D), U. Pisa (I), EPFL (CH), XRCE (FR), U. Sheffiel (UK), CECOJI (FR) + ELSNET & ELRA. Duration: January April Budget: 414 KECU. Draw a blueprint for an evaluation infrastructure (IST Key Actions of FP5 ) Evaluation Paradigm: contrastive quantitative Technology Evaluation.")
39
Actors in the infrastructure
European Commission ELRA Evaluators Participants (EU / non EU) L. R. Producers Research Industry Citizens Users & Customers
 L. R. Producers. Research. Industry. Citizens. Users & Customers.")
40
Actions de recherche concerté de l ’AUPELF
Traitement Automatique des Langues et Industrie de la Langue Évaluation (Europe) COCOSDA SAM & SAM-A Morpholympics Actions de recherche concerté de l ’AUPELF GRACE (CNRS) VerbMobil ELSE EAGLES TSNLP DIET TEMAA SQALE SPARKLE DISC MATE Patrick Paroubek / Limsi-CNRS
 COCOSDA. SAM & SAM-A. Morpholympics. Actions de recherche concerté de l ’AUPELF. GRACE (CNRS) VerbMobil. ELSE. EAGLES. TSNLP. DIET. TEMAA. SQALE. SPARKLE. DISC. MATE. Patrick Paroubek / Limsi-CNRS.")
41
CLASS Evaluation URL: http: //www.limsi.fr/TLP/CLASS
Traitement Automatique des Langues et Industrie de la Langue Évaluation (Europe) CLASS Evaluation URL: http: // Disponibles sur le site : Actes de LREC2000 CLASS atelier satellite sur l’évaluation. Actes de EACL 2OO1, Toulouse, atelier « Evaluation for Language & Dialog Systems » Présentations du Bullet Course on the paradigm of Evaluation in Speech and Language, Juillet, Paris 02 et Patrick Paroubek / Limsi-CNRS
 CLASS Evaluation URL: http: // Disponibles sur le site : Actes de LREC2000 CLASS atelier satellite sur l’évaluation. Actes de EACL 2OO1, Toulouse, atelier « Evaluation for Language & Dialog Systems » Présentations du Bullet Course on the paradigm of Evaluation in Speech and Language, Juillet, Paris 02 et Patrick Paroubek / Limsi-CNRS.")
42
CLEF: recherche d’information interlingue
Traitement Automatique des Langues et Industrie de la Langue Évaluation (Europe) CLEF: recherche d’information interlingue SENSEVAL: désambiguïsation sémantique SMARTKOM: nouveau projet allemand. TCSTAR technologie pour interprète automatique ECOM (ELRA) évaluation Patrick Paroubek / Limsi-CNRS
 CLEF: recherche d’information interlingue. SENSEVAL: désambiguïsation sémantique. SMARTKOM: nouveau projet allemand. TCSTAR technologie pour interprète automatique. ECOM (ELRA) évaluation. Patrick Paroubek / Limsi-CNRS.")
43
Coordinator: J. Mariani, F. Néel
FRANCIL Program Created : June 1994 Coordinator: J. Mariani, F. Néel Networking (70 laboratories, 9 countries) Training Collaborative Research Actions (ARP) Strategic Research Actions (ARC) Budget: 4 Meuro / 4 years - 2 Meuro ARC
 Training. Collaborative Research Actions (ARP) Strategic Research Actions (ARC) Budget: 4 Meuro / 4 years - 2 Meuro ARC.")
44
Use of the evaluation paradigm for accompanying research :
Infrastructure for evaluation (protocols, metrics, organization...) Language Resources for systems development and evaluation Discussion of the advantages and disadvantages of different approaches based on objective evaluation conducted on common data Written and spoken language
 Language Resources for systems development and evaluation. Discussion of the advantages and disadvantages of different approaches based on objective evaluation conducted on common data. Written and spoken language.")
45
ARC ILEC (Written Language)
Language Resources for written French language and system evaluation: A1 (Amaryllis): Natural Language Access to textual information A2 (Arcade): (Bi/Multi)lingual (French-English) corpus alignment A3: Automated terminological database design A4: Text understanding
: Natural Language Access to textual information. A2 (Arcade): (Bi/Multi)lingual (French-English) corpus alignment. A3: Automated terminological database design. A4: Text understanding.")
46
ARC ILOR (Spoken language)
Language Resources for spoken French language and system evaluation B1: Voice Dictation (large vocabulary recognition) B2: Vocal Dialog B3: Text-to-Speech synthesis
 B2: Vocal Dialog. B3: Text-to-Speech synthesis.")
47
ARC: Calendar & Budget Call for proposals in July 1994, selection in November 1994 of 50 proposals (34 labs) out of 89 proposals. 2 evaluation campaigns of a two year time span ( and ) Total budget (6 ARCs) = 2 Meuros ( 4 years) 167 Keuros / campaign / control task (1 evaluator, ~ 7 evaluatees, 3 different countries)
 Total budget (6 ARCs) = 2 Meuros ( 4 years) 167 Keuros / campaign / control task (1 evaluator, ~ 7 evaluatees, 3 different countries)")
48
CNRS CCIIL GRACE Action
Control Task: POS tagging for French. Corpora: Train.= 10 Mw, D.R.= 450Kw, T.= 650 Kw Call for tenders November Training January 1996. Dry run October Workshop (JST April 1997). Tests December Workshop in May 1998. First results disclosed on the WEB in November 1998. 18+3 participants, 5 countries (CA, USA, D, CH, FR). Budget 800 Keuros Byproducts: eval. results, com. prod., 1 Mw valid. corpus
. Tests December Workshop in May First results disclosed on the WEB in November participants, 5 countries (CA, USA, D, CH, FR). Budget 800 Keuros. Byproducts: eval. results, com. prod., 1 Mw valid. corpus.")
49
TechnoLangue TECHNOLANGUE Programme d’infrastructure en soutien à la R&D, la R&D restant dans les RRIT et le programme spécifique« Veille » RNRT RNTL RIAM VSE

51
Programme d’évaluation TECHNOLANGE:
EVALDA ARCADE II alignement de documents CESART acquisition de terminologie CESTA traduction automatique EASy analyse syntaxique Equer Question-Réponses ESTER transcription émission radio Evasy Synthétiseur de parole français MEDIA compréhension du dialogue

52
Le traitement de l’écrit
Annoter (kappa et segmentation) Aligner (Programmation Dynamique) Évaluer (Précision/Rappel) Morphosyntaxe (GRACE) Syntaxe (EASY)
 Aligner (Programmation Dynamique) Évaluer (Précision/Rappel) Morphosyntaxe (GRACE) Syntaxe (EASY)")
53
Le (coefficient) Kappa est une mesure permettant de quantifier la plus ou moins grande similarité entre deux systèmes d’annotation (accord inter-annotateur). Le kappa est fréquemment utilisée en TALN. Il a été défini par [Cohen 1960]. Le principe est de relativiser la valeur effectivement observée pour le taux d’accord en la rapportant à celle qui aurait été obtenue en comparant deux systèmes affectant les étiquettes de façon aléatoire dans les mêmes proportions que les systèmes effectivement comparés.

54
Barbara Di Eugenio and Michael Glass (2004)
Barbara Di Eugenio and Michael Glass (2004). The kappa statistic: A second look. Computational Linguistics, 30(1): Véronis, J. (1998a). A study of polysemy judgements and inter-annotator agreement. Senseval workshop, 2-4 Sept Herstmonceux Castle, England. Bruce, R., Wiebe, J. (1998). Word sense distinguishability and inter-coder agreement. Proceedings of the 3rd Conference on Empirical Methods in Natural Language Processing (EMNLP-98). ACL SIGDAT, Granada, Spain, June 1998. Carletta, J. (1996). Assessing agreement on classification tasks: the kappa statistics. Computational Linguistics, 22(2),
. The kappa statistic: A second look. Computational Linguistics, 30(1): Véronis, J. (1998a). A study of polysemy judgements and inter-annotator agreement. Senseval workshop, 2-4 Sept Herstmonceux Castle, England. Bruce, R., Wiebe, J. (1998). Word sense distinguishability and inter-coder agreement. Proceedings of the 3rd Conference on Empirical Methods in Natural Language Processing (EMNLP-98). ACL SIGDAT, Granada, Spain, June Carletta, J. (1996). Assessing agreement on classification tasks: the kappa statistics. Computational Linguistics, 22(2),")
55
Jones, A. P. , Johnson, L. A. , Butler, M. C. , & Main,D. S. 1983
Jones, A. P., Johnson, L. A., Butler, M. C., & Main,D. S Apples and oranges: An empirical comparison of commonlyused indices of interrater agreement. Academy of Management Journal, 26(3): Davies, M., Fleis, J. L. (1982). measuring agreement for multinomial data. Biometrics, 38, Brenann, R. L. & Prediger, D.J. (1981). Coefficient Kappa : Some uses,misuses and alternatives. Educational and Psychological Measurement,4, Hubert, L Kappa revisited. Psychological Bulletin, 84(2):
: Davies, M., Fleis, J. L. (1982). measuring agreement for multinomial data. Biometrics, 38, Brenann, R. L. & Prediger, D.J. (1981). Coefficient Kappa : Some uses,misuses and alternatives. Educational and Psychological Measurement,4, Hubert, L Kappa revisited. Psychological Bulletin, 84(2):")
56
Landis J.R.; Koch G.G. (1977) The measurement of observer agreement for categorial data. Biometrics 45: Fleiss, J. L.; Cohen, J.; and Everitt, B. S. Largesample standard errors of kappa and weighted kappa. Psychological Bulletin 72 (1969): Cohen, J. (1960) A coefficient of agreement for nominal scales. Educational and Psychological Measurements 20(1):
: Cohen, J. (1960) A coefficient of agreement for nominal scales. Educational and Psychological Measurements 20(1):")
57
qualifier « l’indépendance » de 2 annotations (o/n)
quantifier l’accord de 2 annotations Pour (1) pas de pb, mais pour (2) hypothèse d’indépendance des annotateurs suscite des questions Valeurs de kappa, accord [Landis & Koch, 77]: faible modéré substantiel (poser des hypothèses) presque parfait (les vérifier)
 pas de pb, mais pour (2) hypothèse. d’indépendance des annotateurs suscite des questions. Valeurs de kappa, accord [Landis & Koch, 77]: faible modéré substantiel (poser des hypothèses) presque parfait (les vérifier)")
58
K = (P(A) - P(E) ) / (1 - P(E)) P(A) = probabilité d’accord mesurée
P(E) = probabilité estimée d’un accord du au hasard - V 45 4 15 301 365 occurrences de la forme « est » annotées par 2 systèmes en V (verbe) ou autre (-) A2 A1
 = probabilité estimée d’un accord du au hasard. - V occurrences de la forme « est » annotées par 2 systèmes en V (verbe) ou autre (-) A2. A1.")
59
Kappa = 0.7, en estimant les probabilités par la fréquence avec la loi des grands nombres (risque 5%) et en supposant les annotations indépendantes. … V V V V – – V V V V V V V –

60
En TALN, analyser c’est de manière générale :
Segmenter (par ex. frontières de mots) Identifier ( par ex. lister les étiquettes morpho-syntaxiques possibles) Désambiguïser, éventuellement (par ex. choisir la bonne étiquette morpho-syntaxique) Le problème est circulaire! A la base: Qu’est-ce qu’un mot ? Importance en TALN du choix des unités élémentaires, les (tokens).
 Identifier ( par ex. lister les étiquettes morpho-syntaxiques possibles) Désambiguïser, éventuellement (par ex. choisir la bonne étiquette morpho-syntaxique) Le problème est circulaire! A la base: Qu’est-ce qu’un mot Importance en TALN du choix des unités élémentaires, les (tokens).")
61
0 I Nkms 1 où Pr-mp-- l Pp3msn-/1.3 ' Pp3msn-/2.3 4 on Pp3msn-/3.3 5 commence Vmip3s- 6 à Sp 7 ne Rpn 8 pas Rgn 9 comprendre Vmn---- 10 ce Pd-ms-- 11 n Rpn/1.2 12 ' Rpn/2.2 13 est Vmip3s- 14 pas Rgn 15 sans Sp 16 une Da-fs-i 17 certaine Ai-fs 18 émotion Ncfs 19 que Pr-fs-- 20 je Pp1msn-

62
Nombre de mots en fonction du participant (GRACE)
")
63
Nombre de phrases en fonction du participant (GRACE)
")
64
Outil d’alignement acquis de l’évaluation de l’oral pour lequel beaucoup de travail a été fait sur la mesure fondamentale en transcription de parole, le taux d’erreur de transcription (Word Error Rate). La meilleur mesure (fidélité) : mesure du nombre d’insertions, de suppressions et de substitutions. [J. Makhoul and F. Kubala and R. Schwartz and R. Weischedel, Performance measures for information extraction, Proceedings of DARPA Broadcast News Workshop, 1999, Herndon, VA, February, http ://citeseer.ist.psu.edu/makhoul99performance.html]
 : mesure du nombre d’insertions, de suppressions et de substitutions. [J. Makhoul and F. Kubala and R. Schwartz and R. Weischedel, Performance measures for information extraction, Proceedings of DARPA Broadcast News Workshop, 1999, Herndon, VA, February, http ://citeseer.ist.psu.edu/makhoul99performance.html]")
65
Cette mesure repose sur le réalignement des données produites par un système avec la transcription de référence au moyen de l’algorithme de Programmation Dynamique (réalignement optimal, minimum de distortions introduites) DP utilise une métrique de Levenshtein (ou distance d'édition de Seller) [allison90] L. Allison and C. S. Wallace and C. N. Yee,When is a String Like a String?, Proceedings of International Symposium on Artificial Intelligence in Mathematics (AIM)},1990,Ft. Lauderdale, Florida, January, http ://
 [allison90] L. Allison and C. S. Wallace and C. N. Yee,When is a String Like a String , Proceedings of International Symposium on Artificial Intelligence in Mathematics (AIM)},1990,Ft. Lauderdale, Florida, January, http ://")
66
Fonction de coût : c( x, x )=0 // annotation correcte c( vide, x )=3 // insertion c( x, vide )=3 // omission c( x, y )=4 // substitution Soit la matrice M(i,j), 0<i<L, 0<j<N, représentant le coût de l'alignement des sous-sequences hypothèse h(j) sur la sous-séquence de référence r(i) M(0,0) = 0 // condition limite M(0,j) = M(0, j-1) + c( vide, h(j) ) // condition limite, insertion M(i,0) = M(i-1, 0) + c( r(i), vide) ) // condition limite, omission M{i,j) = min( (M(i-1, j-1d) + c( r(i), h(j))), // correcte ou substitution (M(i-1, j) + c( r(i), vide )), // omission (M(i, j-1) + c( vide, h(j) ))), // insertion
=4 // substitution. Soit la matrice M(i,j), 0<i<L, 0<j<N, représentant le coût de l alignement des sous-sequences hypothèse h(j) sur la sous-séquence de référence r(i) M(0,0) = 0 // condition limite. M(0,j) = M(0, j-1) + c( vide, h(j) ) // condition limite, insertion. M(i,0) = M(i-1, 0) + c( r(i), vide) ) // condition limite, omission. M{i,j) = min( (M(i-1, j-1d) + c( r(i), h(j))), // correcte ou substitution. (M(i-1, j) + c( r(i), vide )), // omission. (M(i, j-1) + c( vide, h(j) ))), // insertion.")
67
La somme des coûts d'une insertion (3) et d'une délétion (3) est supérieur au coût d'une substitution (4), on utilisera donc de préférence des substitution à la place de paires insertion-omission, qui seront présentes uniquement pour réaligner les deux flux de données . L'alignement est obtenu en identifiant dans la matrice M(i,j) le chemin de coût minimal, allant de M(L,N) à M(0,0). Pour l'oral, le résultat de l'évaluation pour un tour de parole est donné par le décompte des nombres d'insertion, d'omission et de substitution, pondéré par le nombre de mots présents dans la référence . [Makhoul et al. 99]
 le chemin de coût minimal, allant de M(L,N) à M(0,0). Pour l oral, le résultat de l évaluation pour un tour de parole est donné par le décompte des nombres d insertion, d omission et de substitution, pondéré par le nombre de mots présents dans la référence . [Makhoul et al. 99]")
68
Alignement (15 systèmes différents pour les tests)
Au DTC:sg cours SBC:sg de PREP Alignement (15 systèmes différents pour les tests) Au Sp+Da-ms-d cours Ncfs|Ncms de Da----i|Da-fp-i|Da-mp-i|Sp Projection des étiquettes dans le jeu GRACE Combinaison Vote & mesure de confiance Au Sp/1.3 6/14[ ] cours Ncms|Sp/2.3 6/15[0.4] de Sp 7/13[ ] TALANA 24/01/2001 P.Paroubek / Limsi-CNRS
 Au Sp+Da-ms-d cours Ncfs|Ncms de Da----i|Da-fp-i|Da-mp-i|Sp. Projection des étiquettes dans le jeu GRACE. Combinaison. Vote & mesure de. confiance Au Sp/1.3 6/14[ ] cours Ncms|Sp/2.3 6/15[0.4] de Sp 7/13[ ] TALANA 24/01/2001. P.Paroubek / Limsi-CNRS.")
69
Des mesures d’évaluation des annotations issues de l’IR : Précision et Rappel
nbr de paires correctes ( mot-annotation ) hypothèse Rappel = nbr total de paires (mot-annotation) référence Si la référence n’est pas ambigue (souvent), alors : rappel = proportion d’annotations contenant au moins une annotation correcte nbr de paires correctes ( mot-annotation ) hypothèse Précision = nbr total de paires (mot-annotation) hypothèse Si ni la référence, ni l’hypothèse ne sont ambigues alors : Précision = Rappel
 hypothèse Rappel = nbr total de paires (mot-annotation) référence. Si la référence n’est pas ambigue (souvent), alors : rappel = proportion d’annotations contenant au moins une annotation correcte. nbr de paires correctes ( mot-annotation ) hypothèse Précision = nbr total de paires (mot-annotation) hypothèse. Si ni la référence, ni l’hypothèse ne sont ambigues alors : Précision = Rappel.")
70
17 participants aux essais, 13 participants aux tests finaux
GRACE, évaluation d'étiquettage morphosyntaxique pour le français, 21 participants, 5 pays: 3 phases: entrainements (10 millions de mots),essais ( ), test ( ) 17 participants aux essais, 13 participants aux tests finaux mesure précision/décision, sur mots, puis mots.étiquettes EAGLES et MULTEXT TALANA 24/01/2001 P.Paroubek / Limsi-CNRS
,essais ( ), test ( ) 17 participants aux essais, 13 participants aux tests finaux. mesure précision/décision, sur mots, puis mots.étiquettes EAGLES et MULTEXT. TALANA 24/01/2001. P.Paroubek / Limsi-CNRS.")
71
Meilleur (P, Dmax): score( P, D ): (0. 948489 , 1
Meilleur (P, Dmax): score( P, D ): ( , ) intervalle[Pmin, Pmoy, Pmax]: [ , , ] Meilleur P: score( P, D ): ( , ) intervalle[Pmin, Pmoy, Pmax]: [ , , ] Vote 15 systèmes: score( P, D ): ( , ) intervalle[Pmin, Pmoy, Pmax]: [ , , ] Vote 5 meilleurs P: score( P, D ): ( , ) [Pmin, Pmoy, Pmax]: [ , , ] TALANA 24/01/2001 P.Paroubek / Limsi-CNRS
: score( P, D ): ( , ) intervalle[Pmin, Pmoy, Pmax]: [ , , ] Meilleur P: score( P, D ): ( , ) intervalle[Pmin, Pmoy, Pmax]: [ , , ] Vote 15 systèmes: score( P, D ): ( , ) intervalle[Pmin, Pmoy, Pmax]: [ , , ] Vote 5 meilleurs P: score( P, D ): ( , ) [Pmin, Pmoy, Pmax]: [ , , ] TALANA 24/01/2001. P.Paroubek / Limsi-CNRS.")
72
TALANA 24/01/2001 P.Paroubek / Limsi-CNRS

73
Annotation Morpho-syntaxique
P. Paroubek / Limsi-CNRS 27 / 03 / 01

74
000000 Au Sd{1}|Sd/1. 3{2}|Sp{1}|Sp+D[ad]-ms-d{1}|Sp+Da-ms-d{5}|Sp/1
Au Sd{1}|Sd/1.3{2}|Sp{1}|Sp+D[ad]-ms-d{1}|Sp+Da-ms-d{5}|Sp/1.2{1}| Sp/1.3{6}|Sp/1.4+Sp/2.4{1} cours Ncfp{3}|Ncfs{1}|Ncmp{2}|Ncms{6}|Sd/2.3{2}|Sp/2.2{1}|Sp/2.3{6}| Sp/3.4{1}|Vmip1s-{2}|Vmip2s-{2}|Vmmp2s-{2} de Da----i{3}|Da-fp-i{2}|Da-mp-i{3}|Di-fp--{1}|Di-fs--{1}| Di-mp--{1}|Di-ms--{1}|Sd/3.3{2}|Sp{7}|Sp/3.3{6}|Sp/4.4{1} Apprentissage Automatique / Combiner plusieurs méthodes pour améliorer les résultats Ada Boost (Schwenk, 1999), cascade de sytèmes similaires pour la reconnaissance de parole. Plus loin dans le temps, stratégie du Winner Take All compétition en unités similaires de traitement (Simpson 1990) TALANA 24/01/2001 P.Paroubek / Limsi-CNRS
![Au Sd{1}|Sd/1. 3{2}|Sp{1}|Sp+D[ad]-ms-d{1}|Sp+Da-ms-d{5}|Sp/1](http://slideplayer.fr/slide/507708/2/images/74/Au+Sd%7B1%7D%7CSd%2F1.+3%7B2%7D%7CSp%7B1%7D%7CSp%2BD%5Bad%5D-ms-d%7B1%7D%7CSp%2BDa-ms-d%7B5%7D%7CSp%2F1.jpg "Au Sd{1}|Sd/1.3{2}|Sp{1}|Sp+D[ad]-ms-d{1}|Sp+Da-ms-d{5}|Sp/1.2{1}| Sp/1.3{6}|Sp/1.4+Sp/2.4{1} cours Ncfp{3}|Ncfs{1}|Ncmp{2}|Ncms{6}|Sd/2.3{2}|Sp/2.2{1}|Sp/2.3{6}| Sp/3.4{1}|Vmip1s-{2}|Vmip2s-{2}|Vmmp2s-{2} de Da----i{3}|Da-fp-i{2}|Da-mp-i{3}|Di-fp--{1}|Di-fs--{1}| Di-mp--{1}|Di-ms--{1}|Sd/3.3{2}|Sp{7}|Sp/3.3{6}|Sp/4.4{1} Apprentissage Automatique / Combiner plusieurs méthodes pour améliorer les résultats. Ada Boost (Schwenk, 1999), cascade de sytèmes similaires pour la reconnaissance de parole. Plus loin dans le temps, stratégie du Winner Take All compétition en unités similaires de traitement (Simpson 1990) TALANA 24/01/2001. P.Paroubek / Limsi-CNRS.")
75
Combiner pour améliorer NIST, reconnaissance de la parole
ROVER - Recognizer Output Voting Error Reduction (Fiscus 1997) Sytème composite, meilleur performance que le meilleur des systèmes. Graphe de mot (alignement), vote à majorité (pondéré par la fréquence maximale d'occurence et un score de confiance). Réduction d'erreur mesurée par Fiscus: 5,6 % en absolu (et 12,5% en relatif). Principe de combinaison de systèmes utilisé par Marquez & Prado (combinaison de 2 étiquetteurs pour marquer un corpus) Tufis (plusieurs versions du même système entraîné sur des données différentes) TALANA 24/01/2001 P.Paroubek / Limsi-CNRS
 Sytème composite, meilleur performance que le meilleur des systèmes. Graphe de mot (alignement), vote à majorité (pondéré par la fréquence maximale d occurence et un score de confiance). Réduction d erreur mesurée par Fiscus: 5,6 % en absolu (et 12,5% en relatif). Principe de combinaison de systèmes utilisé par Marquez & Prado 1998 (combinaison de 2 étiquetteurs pour marquer un corpus) Tufis 1999 (plusieurs versions du même système entraîné sur des données différentes) TALANA 24/01/2001. P.Paroubek / Limsi-CNRS.")
76
Phase 1: 38643 formes (4 % des 836500 formes) relues pour la catégorie et la sous-catégorie
Phase 2: formes (8 % des formes) relues pour les indications de genre, nombre et personne Validation: selection aléatoire de 511 formes, 53 formes identifiées commes douteuses (pas de décision de vote); 27 d'entres elles n'étaient pas correctement étiquettées (erreur de relecture, ou erreur ou ambiguité résiduelle; traits autres que G, N, P), c.a.d. env. 50 % (+-13% avec risque 95%) Inversement sur 458 formes qui n'étaient pas à relire, seules 10 étaient mal étiquettées, ce qui représente un taux d'erreur résiduelle de 2,18% (+-1.34% avec risque 95%) TALANA 24/01/2001 P.Paroubek / Limsi-CNRS
 relues pour les indications de genre, nombre et personne. Validation: selection aléatoire de 511 formes, 53 formes identifiées commes douteuses (pas de décision de vote); 27 d entres elles n étaient pas correctement étiquettées (erreur de relecture, ou erreur ou ambiguité résiduelle; traits autres que G, N, P), c.a.d. env. 50 % (+-13% avec risque 95%) Inversement sur 458 formes qui n étaient pas à relire, seules 10 étaient mal étiquettées, ce qui représente un taux d erreur résiduelle de 2,18% (+-1.34% avec risque 95%) TALANA 24/01/2001. P.Paroubek / Limsi-CNRS.")
77
CONCLUSION La campagne GRACE et l'expérience MULTITAG ont prouvé que le paradigme d'évaluation peut servir à produire de manière économique des ressources linguistiques validées de qualité. La généralisation à d'autre tâches de contrôle permet d'augmenter rapidement la quantité de données annotées et validées tout en permettant de déployer le paradigme d'évaluation plus avant. TALANA 24/01/2001 P.Paroubek / Limsi-CNRS

78
La campagne EASY Annotations pour l’analyse syntaxique Les données Les résultats préliminiaires

79
Objectif: évaluation d’analyse syntaxique
5 fournis. corpus, 13 participants, 16 systèmes évalués France Telcom R&D GREYC INRIA (ATOLL 1,2) LATL LIC2M LIRMM LORIA XEROX LPL (1,2 & 3) PERTIMM SYNAPSE ERSS TAGMATICA
 LATL. LIC2M. LIRMM. LORIA. XEROX. LPL (1,2 & 3) PERTIMM. SYNAPSE. ERSS. TAGMATICA.")
80
Les fournisseurs de corpus :
ATILF (littéraire) DELIC (oral transcrit, s) ELDA (oral ESTER, MLCC, sénat, questions TREC traduites, questions Amaryllis, web) LLF (Le Monde) STIM (médical) Il arrive en retard, avec, dans sa poche, un discours qu’il est obligé de garder.
 DELIC (oral transcrit, s) ELDA (oral ESTER, MLCC, sénat, questions TREC traduites, questions Amaryllis, web) LLF (Le Monde) STIM (médical) Il arrive en retard, avec, dans sa poche, un discours qu’il est obligé de garder.")
81
Guide d’annotation (A. Vilnat) :
5 types de constituants GN groupe nominal GP groupe prépositionnel NV noyau verbal GA groupe adjectival GR groupe adverbial

82
14 types de relations Sujet - Verbe Auxiliaire - Verbe Objet direct - Verbe Complément - Verbe Modifieur – Verbe Complémenteur Attribut -Sujet/Objet Modifieur - Nom Modifieur - Adjectif Modifieur – Adverbe Modifieur – Préposition Coordination Apposition Juxtaposition

83
Outil d’annotation : éditeur HTML + conversion XML (I. Robba)
Annotation manuelle en constituants Énoncé 1 En quelle année Desmond Mpilo Tutu a-t-il reçu le prix Nobel … GP GN NV3 NV4 GN5 Et en relations etc… 1 2 3 4 5 6 7 8 8 9 10 11 sujet verbe GN2 F7 F8 F7

84
Représentation interne des données au format XML / UTF8 (DTD EASY).
Énoncé 12 NV1 GN2 NV3 GR4 GA5 Je pense que monsieur est très inquiet . 1 2 3 4 5 6 7 8 COD Verbe NV 3 NV1 Complémenteur NV prop. sub. NV 3 NV1 Représentation interne des données au format XML / UTF8 (DTD EASY).
.")
85
Outils de validation : éditeur graphique (E. Giguet)
")
86
Les données ont été fournies aux participants :
Brut Segmentées en énoncés Segmentées en mots et en énoncés Segmentées en mots et en énoncés et annotées morphosyntaxiquement (WinBrill + étiquettes GRACE) Corpus de test annoté par les participants : formes énoncés Corpus de mesure : formes énoncés
 Corpus de test annoté par les participants : formes énoncés. Corpus de mesure : formes énoncés.")
87
Corpus de test Corpus de mesure
Genre Formes Enoncés Formes Enoncés Web 16 786 836 2 104 77 Journal 86 273 2 950 10 081 380 Parlement 81 310 2 818 8 875 298 Littéraire 8 062 24 236 881 7 976 9 243 852 médical 48 858 2 270 11 799 554 Oral man. 8 106 522 Oral auto 97 053 11 298 5 365 502 Questions 51 546 3 528 4 116 203

88
Les énoncés sont définis à partir de la typographie au moyen d’expressions régulières.
Les formes sont définies avec ces mêmes expressions et avec une liste pour les formes composées (non nominales). Les données DELIC ont été segmentées en énoncé manuellement (manque de ponctuation). Toutes les autres données ont été segmentées automatiquement avec les outils EASY
. Les données DELIC ont été segmentées en énoncé manuellement (manque de ponctuation). Toutes les autres données ont été segmentées automatiquement avec les outils EASY.")
89
a_contrario Rgp A_contrario Rgp à_contre-pied Rgp À_contre-pied Rgp à_côté_d' Sp À_côté_d' Sp à_côté_de Sp À_côté_de Sp à_côté_des Sp À_côté_des Sp à_côté_du Sp À_côté_du Sp à_coup_sûr Rgp À_coup_sûr Rgp à_court_terme Rgp Liste des formes composées pour la segmentation de référence. 1730 formes 38 Adjectifs 218 Conjonctions 8 Interjections 184 Déterminants 128 Pronoms 626 Adverbes 528 Prépositions 2 Prepositions ou Adverbes

90
<DOCUMENT fichier="oral_delic_1.xml">
<E ID="E1"> <F ID="E1F1">fref-f-c3</F> </E> <E ID="E2"> <F ID="E2F1">voilà </F> <E ID="E3"> <F ID="E3F1">ben</F> <F ID="E3F2">je</F> <F ID="E3F3">travaille</F> <F ID="E3F4">dans</F> <F ID="E3F5">un</F> <F ID="E3F6">pressing</F>

91
<DOCUMENT fichier="oral_elda_1.xml">
<E ID="E1"> <F ID="E1F1">14</F> <F ID="E1F2">heures</F> <F ID="E1F3">À </F> <F ID="E1F4">Paris</F> <F ID="E1F5">,</F> <F ID="E1F6">midi</F> <F ID="E1F7">en</F> <F ID="E1F8">temps</F> <F ID="E1F9">universel</F> <F ID="E1F10">,</F> <F ID="E1F11">l'</F> <F ID="E1F12">information</F> <F ID="E1F13">continue</F> <F ID="E1F14">sur</F> <F ID="E1F15">RFI</F> <F ID="E1F16">.</F> </E>

92
ANNOTATIONS EN CONSTITUANTS
<?xml version="1.0" encoding="UTF-8"?> <DOCUMENT fichier="\Oral Elda\oral_elda_1EASY.UTF8.xml" xmlns:xlink=" <E id="E1"> <constituants> <Groupe type="GN" id="E1G1"> <F id="E1F1">14</F> <F id="E1F2">heures</F> </Groupe> <Groupe type="GP" id="E1G2"> <F id="E1F3">Ã </F> <F id="E1F4">Paris</F> <F id="E1F5">,</F> <Groupe type="GN" id="E1G3"> <F id="E1F6">midi</F> <Groupe type="GP" id="E1G4"> <F id="E1F7">en</F> <F id="E1F8">temps</F> <Groupe type="GA" id="E1G5"> <F id="E1F9">universel</F> <F id="E1F10">,</F> <Groupe type="GN" id="E1G6"> <F id="E1F11">l'</F> <F id="E1F12">information</F> <Groupe type="NV" id="E1G7"> <F id="E1F13">continue</F> ANNOTATIONS EN CONSTITUANTS

93
ANNOTATIONS EN RELATIONS
<Groupe type="GP" id="E1G8"> <F id="E1F14">sur</F> <F id="E1F15">RFI</F> </Groupe> <F id="E1F16">.</F> <F id="E1F17">§</F> </constituants> <relations> <relation xlink:type="extended" type="MOD-N" id="E1R2"> <modifieur xlink:type="locator" xlink:href="E1G4"/> <nom xlink:type="locator" xlink:href="E1F6"/> <a-propager booleen="faux"/> </relation> <relation xlink:type="extended" type="SUJ-V" id="E1R3"> <sujet xlink:type="locator" xlink:href="E1G6"/> <verbe xlink:type="locator" xlink:href="E1G7"/> </relation> <relation xlink:type="extended" type="CPL-V" id="E1R4"> <verbe xlink:type="locator" xlink:href="E1G7"/> <complement xlink:type="locator" xlink:href="E1G8"/> </relation> <relation xlink:type="extended" type="MOD-N" id="E1R5"> <modifieur xlink:type="locator" xlink:href="E1G5"/> <nom xlink:type="locator" xlink:href="E1F8"/> <a-propager booleen="faux"/> </relation> <relation xlink:type="extended" type="MOD-N" id="E1R6"> <modifieur xlink:type="locator" xlink:href="E1F1"/> <nom xlink:type="locator" xlink:href="E1F2"/> <a-propager booleen="faux"/> </relation> </relations> </E> ANNOTATIONS EN RELATIONS

94
Mesures de précision et rappel :
par participant, type de constituant, par type de corpus. Mesures strictes (égalité stricte des adresses) et relachement de contrainte sur les adresses de début et de fin de groupes (+/-1). Pour les relations, sugérnération pour certaines relation de la référence (modifieur nom-adjectif intra groupe).
 et relachement de contrainte sur les adresses de début et de fin de groupes (+/-1). Pour les relations, sugérnération pour certaines relation de la référence (modifieur nom-adjectif intra groupe).")
95
Evaluation en constituants pour 12 systèmes
(prec., rap., f-mes., et les mêmes en mode relaché)
")
96
Evaluation préliminaire en relations pour 11 systèmes sur sénat, mlcc et littéraire1.

97
5. Les systèmes de dialogue

98
Pour les systèmes de dialogue oral (SLDS), 2 points essentiels:
évaluation de possible sous de nombreux aspects ( variété des fonctionalités/module, cf figure suivante) problème : comment décorréler les facteurs humains (ergonomie) et les aspects propres à l’application réalisée (ex. réservation) de ceux liés au traitement du dialogue proprement dit
 problème : comment décorréler les facteurs humains (ergonomie) et les aspects propres à l’application réalisée (ex. réservation) de ceux liés au traitement du dialogue proprement dit.")
99
Architecture générique d’une application de dialogue oral
Patrick Paroubek / Limsi-CNRS

Présentations similaires



 388/2006 établissant un plan pluriannuel pour lexploitation durable du stock de sole du golfe de Gascogne : Évaluation du plan mis.>")
>")














