Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Surveillance des performances. Maintenance proactive.
SOUKAINA KHALLOUFI HOUDA ECHERRADI MERIYAM GUEDIRA FATIMA-EZZEHRA RACHDANI Proposé par: Mr. Mustapha HANOUNE

2
Surveillance des performances
Première partie Surveillance des performances

3
Problèmes d’allocation mémoire
Conflits de périphériques d’entré/sortie Conflits de ressources DBA Pour administrer la base de données Oracle Database 10g et garantir son bon fonctionnement, l'administrateur de base de données doit surveiller régulièrement les performances afin de localiser les goulets d'étranglement et de corriger les problèmes. Le DBA peut examiner des centaines d'indicateurs de performances, allant des performances réseau au temps passé sur les opérations individuelles des applications, en passant par la vitesse d'entrée/sortie des disques. Ces indicateurs de performances sont généralement appelés mesures de performance de la base de données problèmes de code d'application Saturation du réseau

4
Les méthodologies de surveillance
Réactive : réponse à un problème connu résolution des problèmes après avoir affectés le système Proactive: détection de problèmes avant qu'ils se produisent résolution des problèmes avant la production Alertes La base de données Oracle Database 10g prend en charge la surveillance proactive et la surveillance réactive. La surveillance réactive est une réponse à un problème connu ou signalé. Vous pouvez commencer à surveiller les mesures de performance en réaction à des plaintes des utilisateurs concernant le temps de réponse, à des échecs d'instance ou aux erreurs trouvées dans le fichier d'alertes. La surveillance réactive est parfois nécessaire, mais votre objectif doit être de détecter et de résoudre les problèmes avant qu'ils n'affectent le fonctionnement du système. La résolution des problèmes avant qu'ils ne se produisent, ou du moins avant qu'ils ne soient perçus à grande échelle, constitue une approche proactive de la maintenance du système. Oracle Database 10g inclut plusieurs outils qui facilitent la surveillance proactive. En voici deux d'entre eux : les alertes générées par le serveur et ADDM (Automated Database Diagnostic Monitor). La surveillance proactive sera étudiée dans le chapitre suivant.
. La surveillance proactive sera étudiée dans le chapitre suivant.")
5
Mesures de performances de base de données et d'instance
Plusieurs centaines de statistique de performance différents sont disponible via: Le dictionnaire de données les vues dynamiques des performances les statistiques destinés à l'optimisateur : Des centaines de mesures de performance différentes sont disponibles pour la surveillance du système. Le dictionnaire de données fournit des informations sur la consommation d'espace et le statut des objets. Les mesures de performance en temps réel concernant l'utilisation de la mémoire, les événements Wait, le débit des périphériques d'entrée/sortie et l'activité des instances sont disponibles par l'intermédiaire de vues dynamiques des performances, également appelées vues v$. Les bases de données Oracle peuvent être extrêmement volumineuses (des tailles de plusieurs téraoctets sont courantes et des tailles de plusieurs exaoctets sont possibles). Avec des jeux de données aussi volumineux, il est essentiel que l'instance localise le plus efficacement possible la donnée dont l'utilisateur a besoin. La partie de l'instance qui décide comment rechercher les données est appelée l'optimiseur. Les mesures de performance de répartition des données sont utilisées pour aider l'optimiseur Oracle Database 10g à choisir le moyen le plus efficace pour extraire les données ; elles sont donc généralement appelées "statistiques destinées à l'optimiseur".
. Avec des jeux de données aussi volumineux, il est essentiel que l instance localise le plus efficacement possible la donnée dont l utilisateur a besoin. La partie de l instance qui décide comment rechercher les données est appelée l optimiseur. Les mesures de performance de répartition des données sont utilisées pour aider l optimiseur Oracle Database 10g à choisir le moyen le plus efficace pour extraire les données ; elles sont donc généralement appelées statistiques destinées à l optimiseur .")
6
Longueur moyenne des lignes
Les statistiques destinées à l'optimiseur qui affichent la répartition des données de chaque table sont les suivantes : Nombre de lignes Longueur moyenne des lignes Quantité d'espace libre allouée à la table Nombre de lignes "chaînées" Par exemple, l'optimiseur peut être amené à choisir entre un balayage complet de table (full table scan), qui consiste à lire l'ensemble de la table afin de rechercher une ligne particulière,et un balayage d'index, qui consiste à rechercher la ligne d'abord dans un index, puis à accéder directement au bloc de données dans la table contenant la ligne. Dans le cas de petites tables,un balayage complet de table est généralement plus efficace que la recherche via un index,puis l'accès au bloc approprié. En revanche, dans le cas d'une table volumineuse (rappelezvous que cela peut signifier des centaines de millions de lignes), un balayage d'index est probablement plus judicieux.
, qui consiste à lire l ensemble de la table afin de rechercher une ligne particulière,et un balayage d index, qui consiste à rechercher la ligne d abord dans un index, puis à accéder directement au bloc de données dans la table contenant la ligne. Dans le cas de petites tables,un balayage complet de table est généralement plus efficace que la recherche via un index,puis l accès au bloc approprié. En revanche, dans le cas d une table volumineuse (rappelezvous que cela peut signifier des centaines de millions de lignes), un balayage d index est probablement plus judicieux.")
7
Préambule Mesures de performance du dictionnaire de données
Objets non valides et inutilisables Statistiques destinées à l'optimiseur

8
Mesures de performance du dictionnaire de données
L'une des plus importantes mesures de performance du dictionnaire de données concerne le statut des objets. Statut des objets: Objet de code PL/SQL Index Les index de base de données et les procédures stockées doivent tous deux présenter le statut VALID pour pouvoir être utilisés.

9
Index Index UNUSABLE Objet de code PL/SQL PL/SQL INVALID
Les index peuvent devenir UNUSABLE en raison d'opérations normales de maintenance sur les tables. Les index contiennent des pointeurs vers l'emplacement physique des lignes individuelles de données. Si le DBA provoque un changement d'emplacement de ces lignes en raison d'opérations de maintenance telles que la commande MOVE, les pointeurs ne sont plus valides et l'index ne peut plus être utilisé tant qu'il n'est pas reconstruit. Les objets de code PL/SQL présentent le statut INVALID pour différentes raisons. Si le code contient une erreur de programmation, l'objet PL/SQL n'est pas compilé correctement et est marqué comme non valide. Une procédure valide peut devenir non valide si un objet auquel la procédure fait référence change. Supposons qu'une procédure référence la colonne salary de la table employees. Si la précision de la colonne est modifiée ou que la colonne est supprimée, il n'existe aucune garantie que la procédure qui fonctionnait correctement sur l'ancienne définition de la table fonctionnera toujours sur la nouvelle définition de la table. Les index inutilisables ainsi que les objets PL/SQL non valides nécessitent l'intervention du DBA afin de les rétablir dans un état valide. PL/SQL INVALID

10
Objets non valides et inutilisables
Les objets de code PL/SQL sont recompilé Les index sont reconstruits Si vous trouvez des objets PL/SQL dont le statut est INVALID, la première question à vous poser est de savoir si cet objet a déjà présenté le statut VALID. Il est fréquent que le développeur d'une application néglige de nettoyer le code qui ne fonctionne pas. Si l'objet PL/SQL est non valide en raison d'une erreur dans le code, vous ne pouvez pas faire grand chose tant que l'erreur n'est pas résolue. Si la procédure a été valide par le passé et qu'elle est devenue non valide récemment, vous pouvez résoudre le problème de deux façons différentes :

11
PL/SQL Ne rien faire. La plupart des objets PL/SQL sont recompilés automatiquement si nécessaire lors d'un appel. Les utilisateurs percevront simplement un léger retard dû à la recompilation des objets (dans la plupart des cas, ce retard n'est même pas perceptible). 2. Recompiler manuellement l'objet non valide. Les objets PL/SQL non valides peuvent être recompilés manuellement via Enterprise Manager ou par l'intermédiaire de commandes SQL : La recompilation manuelle de packages PL/SQL nécessite deux étapes : ALTER PROCEDURE HR.updatesalary COMPILE; ALTER PACKATE HR.maintainemp COMPILE; ALTER PACKATE HR.maintainemp COMPILE BODY;
. 2. Recompiler manuellement l objet non valide. Les objets PL/SQL non valides peuvent être recompilés manuellement via Enterprise Manager ou par l intermédiaire de commandes SQL : La recompilation manuelle de packages PL/SQL nécessite deux étapes : ALTER PROCEDURE HR.updatesalary COMPILE; ALTER PACKATE HR.maintainemp COMPILE; ALTER PACKATE HR.maintainemp COMPILE BODY;")
13
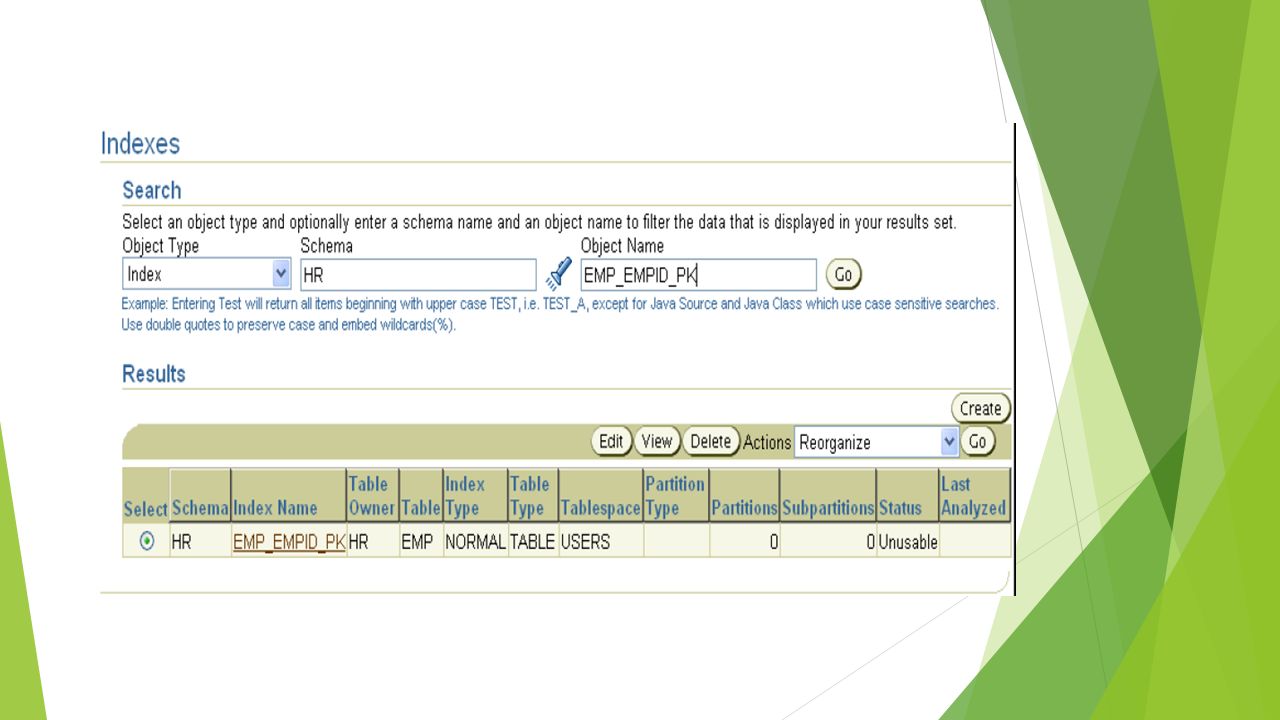
Les Index Les index inutilisables sont rendus valides via leur reconstruction, qui permet de recalculer les pointeurs. La reconstruction d'un index inutilisable recrée l'index dans un nouvel emplacement, puis l'index inutilisable est supprimé. Cette opération peut être effectuée via Enterprise Manager ou par l'intermédiaire de commandes SQL. Si la clause TABLESPACE est omise, l'index est reconstruit dans le même tablespace. La clause REBUILD ONLINE permet aux utilisateurs de continuer de mettre à jour la table de l'index pendant la reconstruction (sans le mot-clé ONLINE, les utilisateurs doivent attendre la fin de la reconstruction afin d'effectuer une opération LMD sur la table affectée). ALTER INDEX HR.emp_empid_pk REBUILD; ALTER INDEX HR.emp_empid_pk REBUILD ONLINE; ALTER INDEX HR. REBUILD TABLESPACE USERS;
. ALTER INDEX HR.emp_empid_pk REBUILD; ALTER INDEX HR.emp_empid_pk REBUILD ONLINE; ALTER INDEX HR. REBUILD TABLESPACE USERS;")
15
Statistiques destinées à l'optimiseur
A QUOI SERVENT LES STATISTIQUES ORACLE ? Statistiques de l'optimiseur décrivent en détail la base de données et ses objets. L'optimiseur de requêtes utilise ces statistiques pour choisir le meilleur plan d'exécution pour chaque instruction SQL. Les statistiques destinées à l'optimiseur concernant les tables et les index sont stockées dans le dictionnaire de données. Ces statistiques ne sont pas destinées à fournir des données en temps réel. Elles fournissent à l'optimiseur un cliché (snapshot) statistiquement correct du stockage et de la répartition des données, que l'optimiseur peut utiliser pour prendre des décisions concernant le mode d'accès aux données.
 statistiquement correct du stockage et de la répartition des données, que l optimiseur peut utiliser pour prendre des décisions concernant le mode d accès aux données.")
16
Les mesures de performance collectées
Statistiques des index Nombre de blocs de feuilles niveaux facteur de regroupement Statistiques du système Performances E / S et l'utilisation Les performances du processeur et de l'utilisation Statistiques des tables Nombre de lignes Nombre de blocs Longueur moyenne des lignes Les statistiques de colonne Nombre de valeurs distinctes (NDV) dans la colonne Nombre de valeurs NULL dans la colonne La distribution des données (histogramme) A mesure que les données sont insérées, supprimées et modifiées, ces valeurs changent. L'impact, en termes de performances, de la maintenance de statistiques en temps réel concernant la répartition des données serait prohibitif ; ces statistiques sont donc mises à jour via la collecte périodique de statistiques sur les tables et les index.
 dans la colonne. Nombre de valeurs NULL dans la colonne. La distribution des données (histogramme) A mesure que les données sont insérées, supprimées et modifiées, ces valeurs changent. L impact, en termes de performances, de la maintenance de statistiques en temps réel. concernant la répartition des données serait prohibitif ; ces statistiques sont donc mises à jour. via la collecte périodique de statistiques sur les tables et les index.")
17
La collecte de statistiques
Collecte automatique Collecte manuelle Les statistiques destinées à l’optimiseur permettent de mieux décrire les objets de la base de données , ces statistiques sont stockées dans le dictionnaire de données ,

18
La collecte automatique des statistiques
L'approche recommandée pour la collecte de statistiques est de permettre à Oracle de collecté automatiquement les statistiques. Statistiques de l'optimiseur sont recueillies automatiquement avec le GATHER_STATS_JOB . Si la base de données a été créée avec l'assistant DBCA (Database Creation Assistant), les statistiques destinées à l’optimiseur sont collectées automatiquement une fois par jour Le travail GATHER_STATS_JOB met a jour les statistiques de l’optimiseur pour les objets comportant des statistiques périmées ou manquantes , Ce travail est automomatiquement programmé à la création de la base de données
, les statistiques destinées à l’optimiseur sont collectées automatiquement une fois par jour. Le travail GATHER_STATS_JOB met a jour les statistiques de l’optimiseur pour les objets comportant des statistiques périmées ou manquantes , Ce travail est automomatiquement programmé à la création de la base de données.")
19
La collecte de statistiques manuellement avec « DBMS_STATS »
DBMS_Starts Recueillir Affiche Modifier Exporter Importer Supprimer

20
Automatiser la collecte des statistiques destinées à l’optimiseur
Le programmateur Oracle automatise aussi les tâches répétitives, copier le code généré par la collecte manuelle des statistiques, puis le coller dans la section de commande. Le programmateur Oracle automatise la collecte des statistiques destinées à l’optimiseur . Dans la page Administration, cliquez sur Jobs et créez un nouveau travail.

21
Programmer la collecte des statistiques destinées à l’optimiseur
Il faut programmer la collecte des statistiques destinées à l'optimiseur selon une fréquence suffisante pour permettre à l'optimiseur de prendre des décisions appropriées quant aux méthodes d'accès aux données. la collecte de statistiques implique un travail de la part de l'instance. Il faut éviter de programmer la collecte des statistiques pendant les heures de forte activité, afin de limiter l'impact sur les opérations normales.

22
Vues dynamiques des performances

23
Vues dynamiques des performances
Les vues dynamiques des performances fournissent un cliché de données en temps réel. chaque accès à une vue dynamique des performances donne des résultats à jour. Dans le cas des statistiques illustrées ci dessus, la sélection des informations avec la clause ORDER BY a entraîné l'incrémentation de la valeur sorts (memory). Comme vous pouvez le voir dans l'exemple de la diapositive ci-dessus,
. Comme vous pouvez le voir dans l exemple de la diapositive ci-dessus,")
24
Les données dynamiques des performances ne sont pas persistantes.
Une fois l'instance arrêtée, les vues sont réinitialisées et le comptage recommence. Cela signifie que les données de performances obtenues par l'intermédiaire des vues dynamiques des performances ne doivent pas être utilisées pour prendre des décisions de configuration tant que l'instance n'a pas fonctionné pendant un certain temps. Les mesures dynamiques de performance ne sont généralement pas significatives en soi. Elles doivent être évaluées en termes de tendance (augmentation, diminution) ou par rapport à des données de référence
 ou par rapport à des données de référence.")
25
Afficher les mesures de performance

26
Afficher les mesures de performance :
Alors pour afficher les mesures de performance il suffit d’accéder a la page maintenance d’Entreprise Manager, cliquer sur le lien All metrics dans la région Related Links et procédez à une hiérarchisation descendante afin d’effectuer une analyse approfondie.

27
Afficher les mesures de performance :
La page All Metrics d'Enterprise Manager regroupe les mesures de performance par domaine fonctionnel. 1. Développez le domaine qui vous intéresse. 2. Cliquez sur le lien correspondant à la mesure de performance que vous souhaitez afficher. les valeurs maximale et minimale!! La représentation graphique de la mesure porte sur une période définie par l'utilisateur. La page de détails affiche : • La dernière valeur connue • Les valeurs des repères high-water mark et low-water mark. • Le nombre moyen de lectures

28
Réagir aux problèmes de performance :

29
Réagir aux problèmes de performance :
Alors pour réagir aux problèmes de performance il est donc nécessaire de détecter ces problèmes : La page Performance d'Enterprise Manager est le meilleur point de départ si vous constatez une dégradation des performances du système. La page Performance est divisée en trois régions principales :

30
Réagir aux problèmes de performance :
La page Performance est divisée en trois régions principales : • Host : mesures de performance du serveur, indiquant le nombre de processus en attente et la quantité de pagination mémoire. • Active Sessions : Waiting and Working : vue d'ensemble des performances de l'instance, indiquant les mesures de performance regroupées par catégories. • Instance Throughput : informations sur les sessions en cours, la génération de fichier de journalisation (redo log) et l'activité de lecture des fichiers de données. • Active Sessions : Waiting and Working : vue d'ensemble des performances de l'instance, indiquant les mesures de performance regroupées par catégories. Si une catégorie consomme une portion significative du temps d'attente de l'instance, commencez la résolution des problèmes par cette catégorie.
 et l activité de lecture des fichiers de données. • Active Sessions : Waiting and Working : vue d ensemble des performances de l instance, indiquant les mesures de performance regroupées par catégories. Si une catégorie consomme une portion significative du temps d attente de l instance, commencez la résolution des problèmes par cette catégorie.")
31
Réagir aux problèmes de performance :
Chacune de ces sections peut faire l'objet d'une hiérarchisation descendante via un clic sur la mesure de performance qui vous intéresse. Dans l'exemple de la diapositive, les utilisateurs passent une part importante de leur temps à attendre suite à un problème de configuration. Alors Pour déterminer l'origine du problème il suffit de cliquez sur la catégorie Configuration afin de procéder à une hiérarchisation descendante.

32
Réagir aux problèmes de performance :
La hiérarchisation descendante sur le temps d'attente lié à la configuration révèle que la majeure partie du temps d'attente est due à un manque d'espace dans le tampon De journalisation (redo log buffer). Dans ce cas, le DBA doit déterminer si le problème concerne le tampon de journalisation proprement dit, c.à.d. l'allocation de mémoire ou bien les fichiers de journalisation car il se peut que le temps d'écriture dans les fichiers soit trop élevé pour permettre au processus LGWR de faire face à la demande
. Dans ce cas, le DBA doit déterminer si le problème concerne le tampon de journalisation proprement dit, c.à.d. l allocation de mémoire ou bien les fichiers de journalisation car il se peut que le temps d écriture dans les fichiers soit trop élevé pour permettre au processus LGWR de faire face à la demande.")
33
Conclusion: Méthodologies de surveillance : Réactive . Proactive.
Mesures de performance de base de données et d'instance. la collecte des statistiques de performance destinées à l'optimiseur: dictionnaire de données. Vues dynamiques des performances. Afficher les mesures de performance. Réagir aux problèmes de performance.

34
Maintenance Proactive
Deuxième partie Maintenance Proactive

35
Deuxième Partie

36
Maintenance proactive

37
La plupart des opérations de maintenance qu'un DBA doit réaliser s'effectuent en production, c'est-à-dire sans interrompre le service des données. Les exigences en matière de disponibilité visant bien souvent 99,999 % du temps (soit 5 minutes d'interruption par an), et c’est normal car les SGBD sont conçus pour ne jamais devoir être arrêtés quelles que soient les opérations à effectuer, et c’est la d’où vient l’importance et la nécessité d’une maintenance proactive.
, et c’est normal car les SGBD sont conçus pour ne jamais devoir être arrêtés quelles que soient les opérations à effectuer, et c’est la d’où vient l’importance et la nécessité d’une maintenance proactive..")
38
Objectifs Définir des seuils d’avertissement et d’alerte critique.
Collecter et utiliser des mesures de performance référence Utiliser les fonctions de conseil de réglage et de diagnostic. Utiliser ADDM (Automatic Database Diagnostic Monitor). Gérer le référentiel AWR (Automatic Workload repository). Oracle Database fournit a l'administrateur de la base de données les possibilités de : Objectifs : Afin de maintenir sa base d’une façon proactive.
. Gérer le référentiel AWR (Automatic Workload repository). Oracle Database fournit a l administrateur de la base de données les possibilités de : Objectifs : Afin de maintenir sa base d’une façon proactive.")
39
Alertes générées par le serveur

40
Alertes générées par le serveur :
Oracle Database 10g permit à l'administrateur de recevoir des alertes sur les problèmes via la console Enterprise Manager Database Control.

41
Alertes générées par le serveur :
Enterprise Manager peut aussi être configuré pour envoyer à l'administrateur des messages électroniques concernant les problèmes, ainsi que pour afficher des informations d'alerte sur la console.

42
Alertes générées par le serveur :
Il suffit de cliquer sur configuration de la page EM

43
Alertes générées par le serveur :
Puis cliquer sur le lien méthodes de notification

44
Alertes générées par le serveur :
Et saisir votre adresse pour recevoir les alertes

45
Définir des seuils

46
Définir des seuils : Les seuils sont des valeurs limite auxquelles sont comparées les mesures de performance surveillées. Vous pouvez également définir des seuils sur nombre des mesures de performance importantes du système de sorte qu'une alerte soit générée lorsqu'une mesure de performance surveillée dépasse ces seuils. Cette alerte vous informe alors des problèmes imminents, que vous pouvez résoudre rapidement avant même que les utilisateurs ne les remarquent.

47
Définir des seuils : Les seuils d'avertissement : sont généralement utilisés pour fournir une notification précoce lorsque les tendances des performances commencent à dévier des valeurs relatives à l'activité normale. En général, aucune action n'est requise pour ces avertissements, qui sont destinés à alerter le DBA afin qu'il commence à surveiller de plus près la situation. Les alertes critiques : doivent être utilisées pour indiquer des problèmes qui nécessitent une attention immédiate. Vous pouvez définir des actions de réponse automatisée qui seront exécutées si les seuils critiques sont atteints. Deux seuils peuvent être affectés à chaque mesure de performance : L'objectif de l'administrateur doit être de résoudre les problèmes avant que les seuils critiques ne soient atteints.

48
Définir des seuils : Lorsque les seuils sont atteints, les alertes sont déclenchées et signalées comme suit : Des notifications apparaissent dans la région Alerts de la page d’accueil Database Control Envoi facultatif d’alertes par courrier électronique.

49
Définir des seuils : La page de propriétés Manage Metrics d’Entreprise Manager permet l’accès aux paramètres de seuil. Cliquez sur le bouton Edit Threshold dans la page Manage Metrics afin de définir des seuils d'avertissement ou des seuils critiques.

50
Préambule: Mesures de référence Utiliser des mesures de référence
Fonctions de conseil de réglage et de diagnostic SQL Tuning Advisor et Access Advisor

51
Mesures de référence Les mesure de référence fournissent des recommandations et des conseils concernant les seuils , en fonction des données réelles des performances . Les seuils sont des valeurs limite auxquelles sont comparées les mesures de performance surveillées.

52
Pour capturer une mesure de référence :
Appelez l'assistant Create Baseline Wizard à partir de la page Manage Metrics. Indiquez une date et éventuellement une heure correspondant à une charge globale et à des performances normales. Indiquez un pourcentage d'écart d'avertissement et un pourcentage d'écart critique, puis cliquez sur le bouton Go. WARNING POURCENTAGE: vous pouvez définir des seuils afin d'être averti lorsque les performances de la base se dégradent de 10 % par rapport aux performances de ce jour particulier CRITICAL POURCENTAGE:afin de recevoir une alerte critique si les performances se dégradent de 25 %. L'assistant Create Baseline Wizard vous permet de capturer des statistiques de performances moyennes pour une heure donnée ou, si vous ne sélectionnez pas d'heure, pour la période de 24 heures indiquée par le champ Date. Il calcule alors l'écart d'avertissement et l'écart critique par rapport aux performances moyennes.

53
4. Sélectionnez la ou les mesures de performance que vous souhaitez capturer (par défaut, une mesure de référence est capturée pour toutes les mesures de performance). valeurs de seuil sont remplies automatiquement à partir des pourcentages d'écart indiqués à l'étape 3. Vous pouvez les personnaliser si nécessaire. 5. Une fois que vous avez apporté les éventuelles modifications souhaitées aux seuils calculés, cliquez sur le bouton OK.

54
Utiliser des mesures de référence
Pour activer une mesure de référence stockée: Une fois que vous avez créé une mesure de référence, vous pouvez l'appliquer en cliquant sur le bouton Copy Thresholds From Baseline dans la page Edit Thresholds, puis en sélectionnant la mesure de référence que vous souhaitez utiliser. Les valeurs de seuil calculées à partir de la mesure de référence sont appliquées à toutes les mesures de performance contenues dans la mesure de référence. Bien entendu, vous pouvez modifier les valeurs de seuil des différentes mesures de performance, si nécessaire.

55
Fonctions de : Conseil / Réglage / Diagnostique
Memory Advisor (MTTR) Advisor SQL Tuning Advisor SQL Access Advisor ADDM : fonction de conseil basée sur le serveur. SQL Tuning Advisor : analyse des instructions SQL individuellement et fournit des recommandations pour l'amélioration des performances. Memory Advisor : un ensemble de plusieurs fonctions qui permettent de déterminer les réglages les plus efficaces pour différentes zones de mémoire. SQL Access Advisor : analyse toutes les instructions SQL exécutées au cours d'une période donnée. Segment Advisor : recherche les tables et les index qui consomment plus d'espace que nécessaire. Undo Management Advisor : aide à déterminer la taille requise pour le tablespace d'annulation afin de prendre en charge une période de conservation donnée. Mean-Time-To-Recover (MTTR) Advisor : aide à définir la durée nécessaire pour la récupération de la base de données suite à l'échec d'une instance ADDM Segment Advisor Fonctions
 Advisor. SQL Tuning Advisor. SQL Access Advisor. ADDM : fonction de conseil basée sur le serveur. SQL Tuning Advisor : analyse des instructions SQL individuellement et fournit des recommandations pour l amélioration des performances. Memory Advisor : un ensemble de plusieurs fonctions qui permettent de déterminer les réglages les plus efficaces pour différentes zones de mémoire. SQL Access Advisor : analyse toutes les instructions SQL exécutées au cours d une période donnée. Segment Advisor : recherche les tables et les index qui consomment plus d espace que nécessaire. Undo Management Advisor : aide à déterminer la taille requise pour le tablespace d annulation afin de prendre en charge une période de conservation donnée. Mean-Time-To-Recover (MTTR) Advisor : aide à définir la durée nécessaire pour la récupération de la base de données suite à l échec d une instance. ADDM. Segment Advisor. Fonctions.")
56
SQL Tuning Advisor et Access Advisor

57
L'objectif de l'analyse des instructions SQL est d'identifier les instructions SQL qui consomment le plus et de proposer des suggestions pour améliorer leurs performances. On peut améliorer les performances des instructions SQL en: Ajoutant ou en modifiant l'indexation Fournissant des données agrégées temporaires par l'intermédiaire de vues matérialisées Réécrivant les instructions SQL afin qu'elles soient plus efficaces, ou encore en corrigeant les défauts de configuration.

58
Les assistants SQL Tuning Advisor et Access Advisor:
Facilitent la recherche des instructions SQL qui consomment le plus Détectent les erreurs courantes dans la construction des instructions SQL Recommandent l'utilisation appropriée d'index ou de vues matérialisées et informent le DBA du coût associé à l'ajout de ces objets L'analyse et le réglage manuels des instructions SQL est une opération fastidieuse qui nécessite une expérience approfondie. Les assistants SQL Tuning Advisor et Access Advisor :

59
MEMORY Advisor Une mémoire SGA trop petite entraîne une dégradation importante des performances il est souvent difficile de déterminer la quantité de mémoire suffisante l'affectation d'une trop grande quantité de mémoire à la mémoire SGA peut entraîner une dégradation des performances du système au même titre qu'une quantité trop petite, suite à la consommation inutile de ressources mémoire précieuses. Mais il est souvent difficile de déterminer la quantité de mémoire suffisante En fait, l'affectation d'une trop grande quantité de mémoire à la mémoire SGA peut entraîner

60
Conseil sur la taille du cache de tampon
Les fonctions de conseil concernant la mémoire vous permettent d'affecter la taille la plus efficace aux différentes composantes de la mémoire SGA. Chacune de ces fonctions de conseil présente à l'administrateur un graphique illustrant l'intérêt de l'augmentation de la mémoire par rapport à la quantité de mémoire requise pour y parvenir

61
L'administrateur doit essayer de dimensionner les différentes mémoires cache en
fonction du point de la courbe correspondant à la stabilisation des performances ou à l'amélioration minimale des performances pour le coût de l'allocation de mémoire.

62
Segment Advisor Cette fonction de conseil recherche les tables et les index qui consomment plus d'espace que nécessaire. Elle recherche toute consommation inutile d'espace au niveau tablespace ou schéma et génère des scripts permettant de réduire cette consommation lorsque cela s'avère possible Le conseiller segment identifie les segments qui ont un espace disponible pour la remise en état. Il effectue son analyse en examinant les statistiques d'utilisation et de croissance dans le Workload Repository automatique (REA), et en échantillonnant les données dans le segment. Il est configuré pour fonctionner pendant des fenêtres de maintenance comme une tâche de maintenance automatisée. Lorsque des lignes sont supprimées d'une table ou lorsque les données d'une ligne sont mises à jour avec une valeur qui consomme moins d'espace que la valeur originale Avec le temps, l'espace alloué aux tables devient supérieur à l'espace nécessaire
, et en échantillonnant les données dans le segment. Il est configuré pour fonctionner pendant des fenêtres de maintenance comme une tâche de maintenance automatisée. Lorsque des lignes sont supprimées d une table ou lorsque les données d une ligne sont mises. à jour avec une valeur qui consomme moins d espace que la valeur originale. Avec le temps, l espace alloué aux tables devient supérieur à l espace nécessaire.")
63
AWR (Automatic Workload Repository)
la base de données capture automatiquement les informations statistiques de la mémoire SGA ces informations sont stockées dans le référentiel AWR (Automatic Workload Repository) sous la forme de clichés (snapshots). Ces clichés sont stockés sur le disque et sont conservés pendant sept jours Le référentiel AWR contient des centaines de tables, appartenant toutes au schéma SYSMAN et stockées dans le tablespace SYSAUX.
 sous la forme de clichés (snapshots). Ces clichés sont stockés sur le disque et sont conservés pendant sept jours. Le référentiel AWR contient des centaines de tables, appartenant toutes au schéma SYSMAN et stockées dans le tablespace SYSAUX.")
64
Gérer le référentiel AWR
Période de conservation 7 jours par défaut Tenez compte des besoins en termes de stockage Intervalle de collecte 60 minutes par défaut Tenez compte des besoins en termes de stockage et de l’impact sur les performances Niveau de collecte Basic (désactive la plupart des fonctionnalités ADDM) Typical (recommandé) ALL (ajouter aux clichés des informations complémentaires de réglage des instruction SQL) Ouvrez la page de propriétés Administration et cliquez sur le lien Workload Repository afin d'accéder à la page des paramètres AWR. Les paramètres AWR incluent la période de conservation, l'intervalle de collecte et le niveau de collecte. L'augmentation de la valeur des paramètres peut donner lieu à des recommandations plus efficaces par les fonctions de conseil, mais cela a un coût en ce qui concerne l'espace requis pour les clichés et les performances consacrées à la collecte des clichés. Vous pouvez utiliser le niveau de collecte ALL lors du réglage d'une nouvelle application. La valeur ALL entraîne la collecte de plans d'exécution SQL et de statistiques temporelles qui améliorent les recommandations des fonctions de conseil SQL. Une fois le réglage terminé, rétablissez la valeur TYPICAL.
 Typical (recommandé) ALL (ajouter aux clichés des informations complémentaires de réglage des instruction SQL) Ouvrez la page de propriétés Administration et cliquez sur le lien Workload Repository afin. d accéder à la page des paramètres AWR. Les paramètres AWR incluent la période de conservation, l intervalle de collecte et le niveau. de collecte. L augmentation de la valeur des paramètres peut donner lieu à des recommandations plus. efficaces par les fonctions de conseil, mais cela a un coût en ce qui concerne l espace requis. pour les clichés et les performances consacrées à la collecte des clichés. Vous pouvez utiliser le niveau de collecte ALL lors du réglage d une nouvelle application. La. valeur ALL entraîne la collecte de plans d exécution SQL et de statistiques temporelles qui. améliorent les recommandations des fonctions de conseil SQL. Une fois le réglage terminé, rétablissez la valeur TYPICAL.")
65
ADDM (Automatic Database Diagnostic Monitor)
fonction de conseil basée sur le serveur, qui examine les performances de la base de données toutes les 60 minutes. L'objectif d'ADDM est de détecter de manière précoce les goulets d'étranglement du système recommander des corrections avant toute dégradation perceptible des performances du système.

66
Automatic Database Diagnostic Monitor (titre)
Exécution après chaque cliché AWR Surveillance de l’instance de détection des goulets d’étranglement Stockage des résultats dans le référentiel AWR Commentaire :ADDM s'exécute automatiquement après chaque cliché AWR. Chaque fois qu'un cliché est pris, ADDM procède à l'analyse de la période correspondant aux deux derniers clichés. ADDM surveille l'instance de manière proactive et détecte les goulets d'étranglement avant qu'ils ne posent un réel problème. Les résultats de chaque analyse ADDM sont stockés dans le référentiel AWR et sont également accessibles via la console Enterprise Manager

67
Automatic Database Diagnostic Monitor
Dans de nombreux cas, ADDM recommande des solutions pour les problèmes détectés et quantifie même les avantages liés aux recommandations. Voici quelques-uns des problèmes courants détectés par ADDM : Goulets d'étranglement CPU Gestion inefficace des connexions Oracle Net Contention liée aux verrous (les verrous seront étudiés dans un prochain chapitre) Capacité d'E/S Sous-dimensionnement des structures mémoire Oracle Instructions SQL à forte consommation de ressources Temps PL/SQL et Java élevé Nombreux points de reprise (checkpoints) et cause, par exemple des fichiers journaux trop petits
 Capacité d E/S. Sous-dimensionnement des structures mémoire Oracle. Instructions SQL à forte consommation de ressources. Temps PL/SQL et Java élevé. Nombreux points de reprise (checkpoints) et cause, par exemple des fichiers journaux. trop petits.")
68
ADDM commence son analyse par l'étude des activités auxquelles la base de données consacre le plus de temps, puis navigue dans un arbre sophistiqué de classification des problèmes pour déterminer les causes premières des problèmes. La capacité d'ADDM à découvrir la cause réelle expliquant les problèmes de performance plutôt que de simplement signaler les symptômes représente l'une des raisons de sa supériorité sur tous les autres outils ou utilitaires de gestion des performances Oracle. L'arbre de classification des problèmes utilisé par ADDM encapsule des décennies d'expérience d'optimisation des performances des propres experts Oracle, il a été spécialement conçu pour diagnostiquer précisément les problèmes les plus courants tels que les goulets d'étranglement de CPU et d'E/S, la mauvaise gestion des connexions, le sous-dimensionnement de la mémoire, les instructions SQL mobilisant beaucoup de ressources, le blocage de verrous, etc. Chaque résultat d'ADDM est associé à une mesure d'impact et d'avantage permettant de définir les priorités dans le traitement des problèmes les plus critiques.

69
Résultats ADDM Dans la page ADDM Findings, vous pouvez voir les résultats détaillés de la dernière exécution d'ADDM. Database Time représente le temps d'activité total passé par les sessions dans la base de données au cours de la période d'analyse. Un pourcentage d'impact spécifique est indiqué pour chacun des résultats. L'impact représente le temps consommé par le problème correspondant, par rapport au temps base de données au cours de la période d'analyse. En cliquant sur un résultat particulier, vous accédez à la page ADDM Finding Details, qui contient davantage d'informations sur le résultat, ainsi que les éventuelles recommandations générées par ADDM.

70
Recommandations ADDM Dans la page ADDM Finding Details, des recommandations indiquent comment résoudre le problème correspondant. Les recommandations sont regroupées en différentes catégories : SCHEMA, SQL Tuning, DB configuration et beaucoup d'autres. La colonne Benefit indique le gain de temps base de données maximal pouvant être obtenu via l'implémentation de la recommandation

71
Synthèse Définir des seuils d'avertissements et d'alertes critiques
Collecter et utiliser les mesures de performance et de référence Utiliser les fonctions de conseil de réglage et de diagnostic Gérer le référentiel AWR Utiliser ADDM

72
Merci pour votre attention

Présentations similaires




 sont des facteurs critiques de réussite.>")














 N° fact, N° Client, N° Cde, date Cde, date fact, date réglement,>")
