Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Régression logistique et modèle de Cox Jean-François TIMSIT Réanimation médicale INSERM/UJF U823 CHU Albert Michallon Grenoble Paris, SRLF Janvier 2009

2
747 patients ventilés plus de 48 heures 153 au moins une PNVM Question: –Parmi les variables age, sexe, utilisation de cephalosporines dans les 48 premières heures de VM lesquels sont des facteurs de risque de PNVM?? Outcomes of VAP CID 2004:38 (15 May) 1401
")
3
Les variables DSREA: durée de séjour en réanimation SEXMASC: sexe masculin Age (année) PN (0/1) EOP/LOP ( =7jours) CEPHALO48: utilisation de céphalosporines dans les 48 premières heures de séjour
 PN (0/1) EOP/LOP ( =7jours) CEPHALO48: utilisation de céphalosporines dans les 48 premières heures de séjour")
4
Variable : AGE Sample size = 747 Lowest value = 16,5257 Highest value = 100,0000 Arithmetic mean = 65,3941 95% CI for the mean = 64,3005 to 66,4878 Median = 68,7817 95% CI for the median = 67,1589 to 69,7324 Variance = 231,5221 Standard deviation = 15,2158 Relative standard deviation = 0,2327 (23,27%) Standard error of the mean = 0,5571 Coefficient of Skewness = -0,7248 (P<0,0001) Coefficient of Kurtosis = 0,0229 (P=0,8308) Kolmogorov-Smirnov test for Normal distribution : reject Normality (P<0,001) Percentiles 95% Confidence Interval 2,5 = 30,3368 27,5104 to 32,9601 5 = 34,7625 32,1306 to 38,4000 10 = 42,3387 40,3694 to 44,8183 25 = 56,4435 53,6353 to 58,6242 75 = 76,5914 75,5473 to 77,2365 90 = 82,3691 80,5334 to 84,2325 95 = 86,1684 84,7553 to 87,5371 97,5 = 88,6290 87,1381 to 90,4577
 Standard error of the mean = 0,5571 Coefficient of Skewness = -0,7248 (P<0,0001) Coefficient of Kurtosis = 0,0229 (P=0,8308) Kolmogorov-Smirnov test for Normal distribution : reject Normality (P<0,001) Percentiles 95% Confidence Interval 2,5 = 30, ,5104 to 32, = 34, ,1306 to 38, = 42, ,3694 to 44, = 56, ,6353 to 58, = 76, ,5473 to 77, = 82, ,5334 to 84, = 86, ,7553 to 87, ,5 = 88, ,1381 to 90,4577")
5
Variable DS rea Variable : DSREA Sample size = 747 Lowest value = 2,0000 Highest value = 111,0000 Arithmetic mean = 16,4712 95% CI for the mean = 15,2883 to 17,6541 Median = 11,0000 95% CI for the median = 10,0000 to 12,0000 Variance = 271,2147 Standard deviation = 16,4686 Relative standard deviation = 0,9998 (99,98%) Standard error of the mean = 0,6026 Coefficient of Skewness = 2,2130 (P<0,0001) Coefficient of Kurtosis = 6,0827 (P<0,0001) Kolmogorov-Smirnov test for Normal distribution : reject Normality (P<0,001) Percentiles 95% Confidence Interval 2,5 = 2,0000 2,0000 to 2,0000 5 = 3,0000 2,0000 to 3,0000 10 = 3,0000 3,0000 to 4,0000 25 = 6,0000 5,0000 to 6,0000 75 = 21,0000 19,0000 to 23,0000 90 = 37,8000 33,0000 to 44,0000 95 = 51,1500 45,0000 to 58,0000 97,5 = 62,8250 57,0000 to 71,0353
 Standard error of the mean = 0,6026 Coefficient of Skewness = 2,2130 (P<0,0001) Coefficient of Kurtosis = 6,0827 (P<0,0001) Kolmogorov-Smirnov test for Normal distribution : reject Normality (P<0,001) Percentiles 95% Confidence Interval 2,5 = 2,0000 2,0000 to 2, = 3,0000 2,0000 to 3, = 3,0000 3,0000 to 4, = 6,0000 5,0000 to 6, = 21, ,0000 to 23, = 37, ,0000 to 44, = 51, ,0000 to 58, ,5 = 62, ,0000 to 71,0353")
6
Vous souhaitez présenter une première table avec les données des groupes (avec et sans pneumonies): quels caractéristiques allez vous garder pour l’age et la durée de séjour? Moyenne (SD) pour les deux Moyenne (SD) pour age et médiane (IQR) pour la DS Moyenne (SD) pour DS et médiane (IQR) pour l’age Médiane (IQR) pour les deux Les deux
 pour les deux Moyenne (SD) pour age et médiane (IQR) pour la DS Moyenne (SD) pour DS et médiane (IQR) pour l’age Médiane (IQR) pour les deux Les deux.")
7
Comparaison age/PNobs Sample 1 Variable : AGE Select : pnobs=0 Sample size = 594 Lowest value = 17,0000 Highest value = 93,0000 Median = 69,0000 95% CI for the median = 67,0000 to 70,0000 ---------------------------------------------------------- Sample 2 Variable : age Select : pnobs=1 Sample size = 153 Lowest value = 25,0000 Highest value = 100,0000 Median = 70,0000 95% CI for the median = 68,0000 to 73,0000 ---------------------------------------------------------- Mann-Whitney test (independent samples) Average rank of first group = 364,4537 Average rank of second group = 411,0621 Large sample test statistic Z = 2,382441 Two-tailed probability P = 0,0172 Sample 1 Variable : age Select : pnobs=0 Sample size = 594 Arithmetic mean = 65,1734 95% CI for the mean = 63,9445 to 66,4023 Standard deviation = 15,2496 Standard error of the mean = 0,6257 ------------------------------------------------------------ Sample 2 Variable : AGE Select : pnobs=1 Sample size = 153 Arithmetic mean = 69,0523 95% CI for the mean = 67,0019 to 71,1027 Standard deviation = 12,8369 Standard error of the mean = 1,0378 ------------------------------------------------------------ Independent samples t-test F-test for equal variances P = 0,010 T-test (assuming equal variances) Difference = 3,8789 95% CI of difference = 1,2466 to 6,5111 Test statistic t = 2,893 Degrees of Freedom (DF) = 745 Two-tailed probability P = 0,0039 Test t de student Test de Mann Whitney
 Average rank of first group = 364,4537 Average rank of second group = 411,0621 Large sample test statistic Z = 2, Two-tailed probability P = 0,0172 Sample 1 Variable : age Select : pnobs=0 Sample size = 594 Arithmetic mean = 65, % CI for the mean = 63,9445 to 66,4023 Standard deviation = 15,2496 Standard error of the mean = 0, Sample 2 Variable : AGE Select : pnobs=1 Sample size = 153 Arithmetic mean = 69, % CI for the mean = 67,0019 to 71,1027 Standard deviation = 12,8369 Standard error of the mean = 1, Independent samples t-test F-test for equal variances P = 0,010 T-test (assuming equal variances) Difference = 3, % CI of difference = 1,2466 to 6,5111 Test statistic t = 2,893 Degrees of Freedom (DF) = 745 Two-tailed probability P = 0,0039 Test t de student Test de Mann Whitney")
8
Vous voulez comparer l’age en fonction de PNVM Votre logiciel vous propose 2 tests et 2 sorties laquelle choisissez vous et pourquoi? 1.Test t de Student car c’est le plus puissant 2.Test de Kruskal Wallis car c’est le plus puissant 3.Test t de Student car les effectifs sont supérieurs à 30 4.Test de Kruskal Wallis, car la normalité n’est pas vérifiée 5.Je sais pas

9
PNVM=0PNVM=1p Age69 (56-77)70 (63-77)0.017 SAPS II50 (38-63)48 (39-57)0,14 Sexe masc.352 (59%)114 (75%)0.0005 Cefalo48136 (23%)27 (18%)0.16 L’analyse univariée est jointe vous souhaitez réaliser une analyse multivariée: HommeFemme PNVM A=114B=39 NON C=352D=242 OR=2.01
70 (63-77)0.017 SAPS II50 (38-63)48 (39-57)0,14 Sexe masc.352 (59%)114 (75%) Cefalo48136 (23%)27 (18%)0.16 L’analyse univariée est jointe vous souhaitez réaliser une analyse multivariée: HommeFemme PNVM A=114B=39 NON C=352D=242 OR=2.01")
10
? ? Très proche du risque relatif 1234 La probabilité de PNVM si homme sur la probabilité de PNVM globale La probabilité d’absence de PNVM si homme rapportée à la probabilité d’absence de PNVM si femmes La probabilité de PNVM si homme sur la probabilité de PNVM si femme 5 Aucune des affirmations n’est vraie L’Odds ratio est :

11
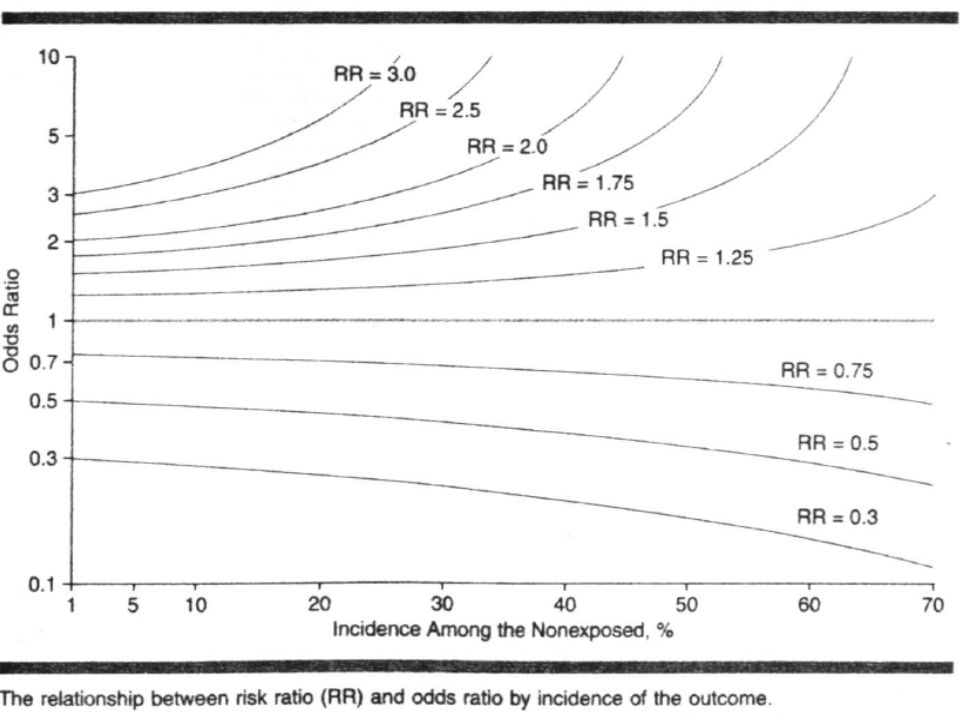
Le risque relatif (RR) de PNVM est égal à la probabilité de PNVM si homme rapportée à la probabilité de PNVM si femme L’odds ratio (0R) de décès est égal au rapport des cotes X et Y X=(proba de PNVM/homme)/(proba de pas de PNVM /homme) Y=(proba de PNVM/femme)/(proba de PNVM /femme) RR=(A/A+C)/(B/B+D)=(114/466)/(39/281)= 1.71 OR=X/Y= (A/C)/(B/D)=AD/BC= 2.01 L’OR n’est proche du RR que si le risque mesuré est très petit +++++ HommeFemme PNVM A=114B=39 NON C=352D=242
 de PNVM est égal à la probabilité de PNVM si homme rapportée à la probabilité de PNVM si femme L’odds ratio (0R) de décès est égal au rapport des cotes X et Y X=(proba de PNVM/homme)/(proba de pas de PNVM /homme) Y=(proba de PNVM/femme)/(proba de PNVM /femme) RR=(A/A+C)/(B/B+D)=(114/466)/(39/281)= 1.71 OR=X/Y= (A/C)/(B/D)=AD/BC= 2.01 L’OR n’est proche du RR que si le risque mesuré est très petit HommeFemme PNVM A=114B=39 NON C=352D=242")
13
Adjustement using a magic « multivariate model » x y z Truth universe in your sample

14
Adjustement using a magic « multivariate model » x y z

15
x y z

16
x y z

17
x y z

18
x y z Model using interactions and polynomes…

19
Validation using external samples x y z Other representative sample of the truth universe

20
Messages As many possible models as individuals (even more!!) Parcimony decreases model discrimination but improves external validity the statistical analyses should be precisely designed a priori Primary and secondary analyses should be precisely planned
 Parcimony decreases model discrimination but improves external validity the statistical analyses should be precisely designed a priori Primary and secondary analyses should be precisely planned")
21
Rules for multivariate models Select the model according to the end point Check for its hypotheses The explanatory variables should be –Precisely defined –Not related one to another –Sufficiently frequent in both groups (problem with perfect or quasi perfect discrimination)
")
22
Que pensez vous de l’inclusion dans le modèle de l’age et du SAPSII? C’est logique C’est illogique puisque le SAPS est NS (comme cephalo) C’est illogique puisque le SAPS comprend l’age J’sais pas?
 C’est illogique puisque le SAPS comprend l’age J’sais pas .")
23
Utilisation de variables dans un modele Dans un but exploratoire: (facteur de risque de quelque chose), il vaut mieux utiliser des modèles « parcimonieux » –Sélectionner des covariables associées avec la variable à expliquer au seuil 0.05 voir 0.01 si vous testez beaucoup de variables ou beaucoup de sujets Dans un but de prédiction, il vaut mieux introduire largement les variables explicatives –Covariables avec p<0.1 voir 0.20 –Variables retrouvées dans la littérature comme pronostique –Procédure de sélection des variables: attention aux logiciels, attention aux variables colinéaires
, il vaut mieux utiliser des modèles « parcimonieux » –Sélectionner des covariables associées avec la variable à expliquer au seuil 0.05 voir 0.01 si vous testez beaucoup de variables ou beaucoup de sujets Dans un but de prédiction, il vaut mieux introduire largement les variables explicatives –Covariables avec p<0.1 voir 0.20 –Variables retrouvées dans la littérature comme pronostique –Procédure de sélection des variables: attention aux logiciels, attention aux variables colinéaires")
24
Vous choisissez une régression logistique (une réponse fausse) Ce modèle permet d’expliquer une variable binaire (0/1) avec des variables qualitatives? Ce modèle permet d’expliquer une variable binaire (0/1) avec des variables quantitatives? Ce modèle ne fait pas d’hypothèse sur la normalité des variables explicatives Ce modèle ne tient pas compte de la durée d’exposition au risque Ce modèle ne fait aucune hypothèse
 avec des variables quantitatives. Ce modèle ne fait pas d’hypothèse sur la normalité des variables explicatives Ce modèle ne tient pas compte de la durée d’exposition au risque Ce modèle ne fait aucune hypothèse.")
25
Analyse des estimations du maximum de vraisemblance Erreur Khi 2 Paramètre DF Estimation std de Wald Pr >Khi2 Intercept 1 -2.6357 0.4629 32.4281 <.0001 AGE 1 0.0190 0.00664 8.2315 0.0041 Estimations des rapports de cotes Point 95% Limites de confiance Effet Estimate de Wald AGE 1.019 1.006 1.033 Association des probabilités prédites et des réponses observées Percent Concordant 55.6 Somers' D 0.126 Percent Discordant 43.0 Gamma 0.128 Percent Tied 1.4 Tau-a 0.041 Pairs 90882 c 0.563 Age OR= 1.019 (1.006-1.033); p=0.0041
; p=0.0041")
26
Que veux dire l’odds ratio pour l’age? C’est l’ OR de PNVM entre les plus agés et les moins agés Ca veux rien dire??? J’ai appuyé sur les mauvaises touches c’est l’augmentation du risque par année: si l’age augmente de 10 ans, l’OR est de 10.2 (10 X 1.02) c’est l’augmentation du risque par année: si l’age augmente de 10 ans, l’OR est de 1.22 Age OR= 1.019 (1.006-1.033); p=0.0041
 c’est l’augmentation du risque par année: si l’age augmente de 10 ans, l’OR est de 1.22 Age OR= ( ); p=")
27
Modèle logistique Modèle de régression linéaire –Y= + X –X est une variable quantitative ou discrète –La variable à expliquer va de 0 à l’infini Comment expliquer une variable binaire avec un modèle de régression? Modèle logistique –On transforme la variable de façon à avoir une réponse [0-1] –Notion de Logit: Log (p/1-p) –On a toujours: Probabilité p [0-1] alors que logit [- , + ] –Log (p/1-p)) = + X –p= exp ( + X)/ (1+ exp( + X)) (ici p=proba (DC) varie de 0 à 1) X 0 Y p Log (p/1-p)
 –On a toujours: Probabilité p [0-1] alors que logit [- , + ] –Log (p/1-p)) = + X –p= exp ( + X)/ (1+ exp( + X)) (ici p=proba (DC) varie de 0 à 1) X 0 Y p Log (p/1-p).")
28
où E = {X 1 =1} par exemple sexe masculin = OUI et D = {événement} Dans le modèle logistique, le coefficient de la régression est le logarithme de l’odds ratio mesurant l ’association entre le test diagnostique et la maladie

29
où E = {X 1 =n} par exemple rales crépitants = OUI et D = {événement} Dans le modèle logistique, le coefficient de la régression est le logarithme de l’odds ratio mesurant l ’association entre le test diagnostique et la maladie Pour les variables quantitatives il mesure l’OR d’une élévation de 1. Variables continues n PNVM n)
.")
30
Catégorisation des variables continues

31
Variables continues dans un modèle logistique Age et PAVM: OR= 1.0310, p<10 -4 Avant d’introduire une variable continue dans un modèle toujours regarder la loglinéarité de cette variable+++

32
Choix des cut-points A déterminer a priori +++ –Sinon ils deviennent complétement dépendants de l’échantillon et –surestiment systématiquement les résultats validation externe +++ –Risquent de conclure à tort à la significativité de la variable En fonction d’un seuil de la littérature ou en fonction de la médiane –La notion de cut-point est tout à fait non réaliste si age=54,43 ans!!! En 3 ou 4 ou 5 ou En fonction des quartiles de la population En fonction des quartiles de survenue d’évènements Altman DG Br J Cancer 1991; 64:975

33
On fait « tourner » le modèle

34
Propriétés du modèle logistique Calibration: Chi 2 de Hosmer - Lemeshow: On coupe en 10 tranches d ’effectifs identiques On compare proba observés et proba calculés pour chaque tranche par un test du Chi 2 (à 8 ddl) Discrimination Capacité de p à séparer pour un seuil donné les DCD et les VV. Courbes ROC: Construire courbes Se / 1-Sp en faisant varier le seuil de positivité DC observés (%) DC prédits (%) Se 1-Sp AUC d 1
 DC prédits (%) Se 1-Sp AUC d 1.")
35
Test d'adéquation d'Hosmer et de Lemeshow Khi 2 DF Pr > Khi 2 1.0645 4 0.8999

36
AUC-ROC=C statistique= 0.633

37
Variable DS rea Variable : DSREA Sample size = 747 Lowest value = 2,0000 Highest value = 111,0000 Arithmetic mean = 16,4712 95% CI for the mean = 15,2883 to 17,6541 Median = 11,0000 95% CI for the median = 10,0000 to 12,0000 Variance = 271,2147 Standard deviation = 16,4686 Relative standard deviation = 0,9998 (99,98%) Standard error of the mean = 0,6026 Coefficient of Skewness = 2,2130 (P<0,0001) Coefficient of Kurtosis = 6,0827 (P<0,0001) Kolmogorov-Smirnov test for Normal distribution : reject Normality (P<0,001) Percentiles 95% Confidence Interval 2,5 = 2,0000 2,0000 to 2,0000 5 = 3,0000 2,0000 to 3,0000 10 = 3,0000 3,0000 to 4,0000 25 = 6,0000 5,0000 to 6,0000 75 = 21,0000 19,0000 to 23,0000 90 = 37,8000 33,0000 to 44,0000 95 = 51,1500 45,0000 to 58,0000 97,5 = 62,8250 57,0000 to 71,0353
 Standard error of the mean = 0,6026 Coefficient of Skewness = 2,2130 (P<0,0001) Coefficient of Kurtosis = 6,0827 (P<0,0001) Kolmogorov-Smirnov test for Normal distribution : reject Normality (P<0,001) Percentiles 95% Confidence Interval 2,5 = 2,0000 2,0000 to 2, = 3,0000 2,0000 to 3, = 3,0000 3,0000 to 4, = 6,0000 5,0000 to 6, = 21, ,0000 to 23, = 37, ,0000 to 44, = 51, ,0000 to 58, ,5 = 62, ,0000 to 71,0353")
38
PNVM=0PNVM=1p Age69 (56-77)70 (63-77)0.017 SAPS II50 (38-63)48 (39-57)0,14 Sexe masc.352 (59%)114 (75%)0.0005 Cefalo48136 (23%)27 (18%)0.16 DS réa9 (5-17)22 (13-38)<0.0001 La durée de séjour est très différente entre PNVM et les autres
70 (63-77)0.017 SAPS II50 (38-63)48 (39-57)0,14 Sexe masc.352 (59%)114 (75%) Cefalo48136 (23%)27 (18%)0.16 DS réa9 (5-17)22 (13-38)< La durée de séjour est très différente entre PNVM et les autres")
39
La date de début de suivi Est fixé à la date de ventilation mécanique Est situé après 24 heures car le SAPS doit être mesurable avant le début du suivi Est situé à la 48eme heure car toutes les variables doivent être mesurables avant Est situé à l’acquisition de la PNVM (chez les PNVM +) Je ne sais pas
 Je ne sais pas")
40
T=adm VI-PN=0 VNI-PN=0 VNI-PN=1 Temps VI-PN=1 VNI echec -PN=1 VNI échec-PN=0 Intub. VNI

41
Biais du temps passé (lead-time biais) Toutes les covariables fixes doivent être mesurable à l’ensemble des temps de suivi
 Toutes les covariables fixes doivent être mesurable à l’ensemble des temps de suivi")
42
PN Données censurées PN t 1 2 3 4 5 6 DC VV DC VV J30 J3

44
Principe des modèles pour données censurées Et Zi ( 0 + 1 Age 56 + 2 Sexe + 3 cefalo48)
")
45
Hazard ratio et risque relatif h h Le HR est le rapport des risques instantané en présence de l’exposition et en son absence. Comme la prévalence de l’événement à un instant t est petit c’est très proche du RR

46
Les patients sont censurés à la sortie de réanimation ou à J30… C’est bien, car la censure n’est pas informative Peu importe le modèle ne fait aucune hypothèse sur la censure Cela peu poser un problème de censure informative Cela est délétère puisque l’on ne tient pas compte des durées de séjours longues et des PNVM très tardives J’sais pas

47
Censure non informative Hypothèse de tous les modèles de survie++++ Hypothèse que si un individu i est censuré au temps t son risque d’événement au temps t+1 est identique à celui des individus encore exposés au temps t+1 ++++ Censure, fixée à priori, non dépendant de l ’état du patient au temps t….. Intérêt des modèles à risques compétitifs

48
Cox Vous pensez que l’utilisation de céphalosporine dans les 48 premières heures protègent de la PNVM, au moins précoce, Cela va à l’encontre de la litérature..votre modèle…

49
Votre modèle (une réponse fausse) 1.Est faux 2.Est juste…l’échantillon n’est pas représentatif des populations explorées précédemment 3.Est juste, il faudra discuter ce résultat à partir d’autres papiers cliniques 4.Ca ne s’applique que si la PNVM est précoce…ici le risque mesuré est un risque global 5.Il y a peut être un problème de proportionnalité des risques
 1.Est faux 2.Est juste…l’échantillon n’est pas représentatif des populations explorées précédemment 3.Est juste, il faudra discuter ce résultat à partir d’autres papiers cliniques 4.Ca ne s’applique que si la PNVM est précoce…ici le risque mesuré est un risque global 5.Il y a peut être un problème de proportionnalité des risques")
50
Hypothèses des risques proportionnels

51
Le risque de survenue d’une pneumonie nosocomiale à un temps t est plus grand si l’age est > 57 ans, chez les hommes. L’utilisation de céphalosporines dans les 48 premières heures protège de la PNVM précoce mais ne protège pas de la PNVM tardive (voire même l’augmente un peu)
.")
52
Interactions Votre modèle suppose qu’il y a indépendance entre les variables explicatives On doit aussi tester l’interaction entre les covariables dans l’explication de l’effet on crée des variables –inter1=age56*sexe,inter2=age56*sexe;inter3=sexe*cefalo48;inter 4=age56*sexe*cefalo48;

53
Modèle logistique ou Cox: check list Choix du modèle –censuré si temps d’exposition très variable et censure à priori non informative Choix de variables –non colinéaires (ou pas trop) –Pas de données manquantes –Bonne reproductibilité –Si quantitatif: log-linéarité des variables, sinon, transformation en variables binaires (dummy) ou en classes, ne pas optimiser le seuil mais plutôt en proportions égales Tester la proportionnalité des risques (Cox) Expliquer le mode de sélection des variables, ne pas laisser faire la machine Recherche des interactions entre les variables dans le modèle final (surtout si elles sont cliniquement plausibles, définir a priori) Tester les propriétés du modèle (calibration et discrimination) Rapporter les méthodes utilisés et les étapes éventuelles…
 –Pas de données manquantes –Bonne reproductibilité –Si quantitatif: log-linéarité des variables, sinon, transformation en variables binaires (dummy) ou en classes, ne pas optimiser le seuil mais plutôt en proportions égales Tester la proportionnalité des risques (Cox) Expliquer le mode de sélection des variables, ne pas laisser faire la machine Recherche des interactions entre les variables dans le modèle final (surtout si elles sont cliniquement plausibles, définir a priori) Tester les propriétés du modèle (calibration et discrimination) Rapporter les méthodes utilisés et les étapes éventuelles…")
Présentations similaires