Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Econométrie P13 Test de Fisher, test de Chow, variables indicatrice, hétéroscédasticité, autocorrélation des erreurs De nombreux éléments sont empruntés aux ouvrages de Régis Bourbonnais, Econométrie Brigitte Dormont INTRODUCTION A L'ECONOMETRIE. ainsi que Walter Enders Applied Econometric Time Series, 3rd Edition Je n’invente pas l’économétrie, je l’utilise et tente de vous transmettre cette pratique. Il est possible que des erreurs subsistent. Veuillez me les indiquer Comme j’ai mis en ligne les calculs du nombre de vecteurs de cointégration, je considère que ceci est acquis et pourra faire l’objet d’une évaluation. Mickaël Clévenot

2
Calcul de Fisher empirique à partir du R²
F* = (R²/k)/[(1-R²)/(n-k-1)] n : nombre de période en série temporelle k : nombre de variable explicative Si le R² = 0,8 ; n = 30, k = 4 que vaut le Fisher ? (0,8/4)/(1-0,8)/(30-4-1) = 25 Fisher théorique v1 = k = 4; v2 = n = 30 à 5 % = 2,69 à 1 % =4,02 25 > 4,02 les coefficients de cette régression sont globalement significatif. Tout les coefficient ne sont pas non significativement différent de 0.
/[(1-R²)/(n-k-1)] n : nombre de période en série temporelle. k : nombre de variable explicative. Si le R² = 0,8 ; n = 30, k = 4 que vaut le Fisher (0,8/4)/(1-0,8)/(30-4-1) = 25. Fisher théorique v1 = k = 4; v2 = n = 30. à 5 % = 2,69 à 1 % =4, > 4,02 les coefficients de cette régression sont globalement significatif. Tout les coefficient ne sont pas non significativement différent de 0.")
3
Sur ce type d’exercice pour vérifier que vous maîtrisez le test on peut inversé la problématique
Il manque l’une des données du problème, il faut la définir. Par exemple le Fisher tabulé vaut 4,48 pour une probabilité de 1 % avec 4 variable explicative quel est le nombre de pas de la série ? Dans ce cas, quelle serait la valeur minimale du R² pour que la régression soit globalement significative ? Dans le même esprit on pourra donner des infos sur SCT et SCR ou SCE. En fonction de infos Fournies il faudra alors retrouver le R². Les indications sur le nombre de variables explicative et Sur le nombre de pas seront également fournies. Avec le test de Fisher on pouvoir identifier quelle est la meilleur spécification d’un modèle c’est À dire voir quel est le nombre de variable à retenir. Pour réaliser ce test qui correspond à un test de Fisher on va vérifier que l’écart entre un modèle Avec n variable et un modèle avec n + . On prend pour cela la différences de la somme des carrées résiduels ou la somme des carrés expliqués En fonction des indications données dans l’exercice. Ici encore, on pourrait vérifier que vous maîtriser les relations entre les R² et le calcul SCT; SCE et SCR.

4
Les deux formulations possibles du test de Fisher :
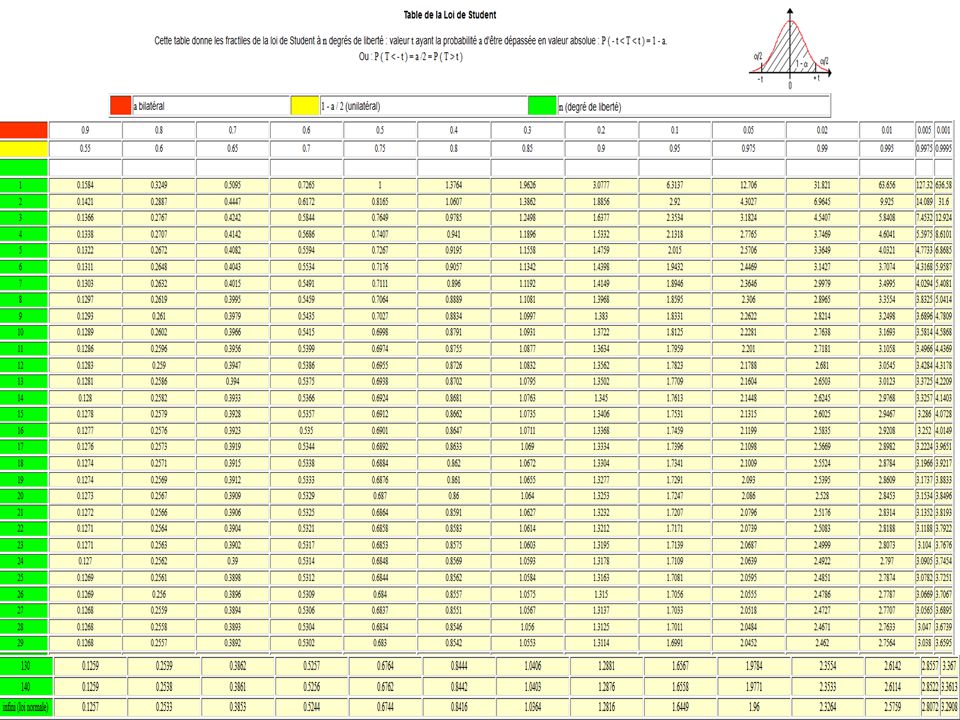
F* = [(SCE – SCE’)/(k-k’)]/(SCR/(n-k-1)) Avec R² = 0,8 si SCT = 100, cela implique que SCE = 80 et SCR = 20. On rappelle n= 30 et k = 4 On veut comparer au modèle avec seulement 3 variables : Dont le R² vaudrait 0,6 et la SCR 14. Trouver la somme des SCE ou passer directement par le calcul avec SCR. SCE => (SCT – SCR)/SCT = 0,6 (SCT -14)/SCT = 0,6 => SCT = 35 et donc SCE = 35-14=21 Ici k = 3, une variable de moins F*=[(SCR’-SCR)/(k’-k)]/[(SCR/(n-k-1)] = [(20-14)/1]/[14/(30-4-1)]= 10,71 Ft v1 = 1 v2 = 25, p = 0,05 => 4, F* > Ft la différence est significative, la variable supplémentaire apporte une information significative.
/(k-k’)]/(SCR/(n-k-1)) Avec R² = 0,8 si SCT = 100, cela implique que SCE = 80 et SCR = 20. On rappelle n= 30 et k = 4. On veut comparer au modèle avec seulement 3 variables : Dont le R² vaudrait 0,6 et la SCR 14. Trouver la somme des SCE ou passer directement par le calcul avec SCR. SCE => (SCT – SCR)/SCT = 0,6 (SCT -14)/SCT = 0,6 => SCT = 35 et donc SCE = 35-14=21. Ici k = 3, une variable de moins. F*=[(SCR’-SCR)/(k’-k)]/[(SCR/(n-k-1)] = [(20-14)/1]/[14/(30-4-1)]= 10,71. Ft v1 = 1 v2 = 25, p = 0,05 => 4,24 F* > Ft la différence est significative, la variable supplémentaire apporte une information significative.")
5
Test de Chow de rupture structurelle
Il n’est pas rare de voir des comportements se transformer à travers le temps. Il est d’ailleurs utile de pouvoir dater c’est changement. C’est l’objet des tests de rupture de Chow. Y a –t-il une différence significative entre la SCR sur l’ensemble de l’échantillon par rapport à l’addition de la SCR de 2 sous échantillons? Autrement dit le fait d’estimer un modèle sur 2 périodes permet-il de réduire la SCR ? Ceci aurait donc tendance à indiquer une changement de comportement.

6
Y a –t-il égalité entre les paramètres sur l’ensemble de la période et sur les sous périodes ?
Pour le vérifier il faut réaliser un test de Fisher à partir de la SCR des différents modèles F* = ([SCR – (SCR1 + SCR2)]/ddl_n)/[(SCR1+SCR2)/ddl_d] ddl_n = k +1 et ddl_d= n-2*(k+1) F* = ([67,45-(27,31+20,73)]/4)/(27,31+20,73)/6 = 4,852/8 = 0,606 < F(4,6;0,05)=4,53 Il n’y a pas de rupture H0 acceptée.
]/ddl_n)/[(SCR1+SCR2)/ddl_d] ddl_n = k +1 et ddl_d= n-2*(k+1) F* = ([67,45-(27,31+20,73)]/4)/(27,31+20,73)/6 = 4,852/8 = 0,606 < F(4,6;0,05)=4,53. Il n’y a pas de rupture H0 acceptée.")
7
L’autocorrélation des erreurs ou la remise en cause de H5 : E(εtεt’)=0 si t≠t
Si H5 n’est pas vérifiée, la matrice des variances covariances des erreurs n’est plus une matrice diagonale, les erreurs ne sont pas indépendantes. Cette situation remet en cause les tests d’inférences car la variance des erreurs n’est pas minimale. En effet, les tests repose sur la détermination d’intervalle de confiance liés à la variance des erreurs. On pourrait donc croire à tord qu’une variable est significative alors qu’elle ne l’est pas. Ωε = E(εε’) = Les estimateurs obtenus restent sans biais mais ne sont à variance minimum.
 = Les estimateurs obtenus restent sans biais mais ne sont à variance minimum.")
8
Les causes possibles de l’autocorrélation des erreurs
Cette situation n’est pas rare. Elle peut avoir plusieurs causes : une mauvaise spécification du modèle, on lie une variables à évolution quadratique à une variable à progression arithmétique des variables manquantes des erreurs de mesure systématiques dans les variables. Ici le non respect de H5 proviendrait du non respect de H2 des variables avec tendance temporelle. Un dernier élément, les variables peuvent être non-stationnaires. On verra plus loin.

9
Comment établir la présence d’une autocorrélation des erreurs ?
Le test de Durbin-Watson ( ) Le test de Breusch-Godfrey La première détection peut être réalisée visuellement en essayant d’identifier une phénomène de mémoire, les erreurs ont souvent le même signe (autocorrélation positive), leur signe change de systématiquement de manière alternative (autocorrélation négative)
 Le test de Breusch-Godfrey. La première détection peut être réalisée visuellement en essayant d’identifier une phénomène de mémoire, les erreurs ont souvent le même signe (autocorrélation positive), leur signe change de systématiquement de manière alternative (autocorrélation négative)")
10
Construction de résidus autocorrélés à partir de la régression d’une variable linéaire et d’une variable quadratique

11
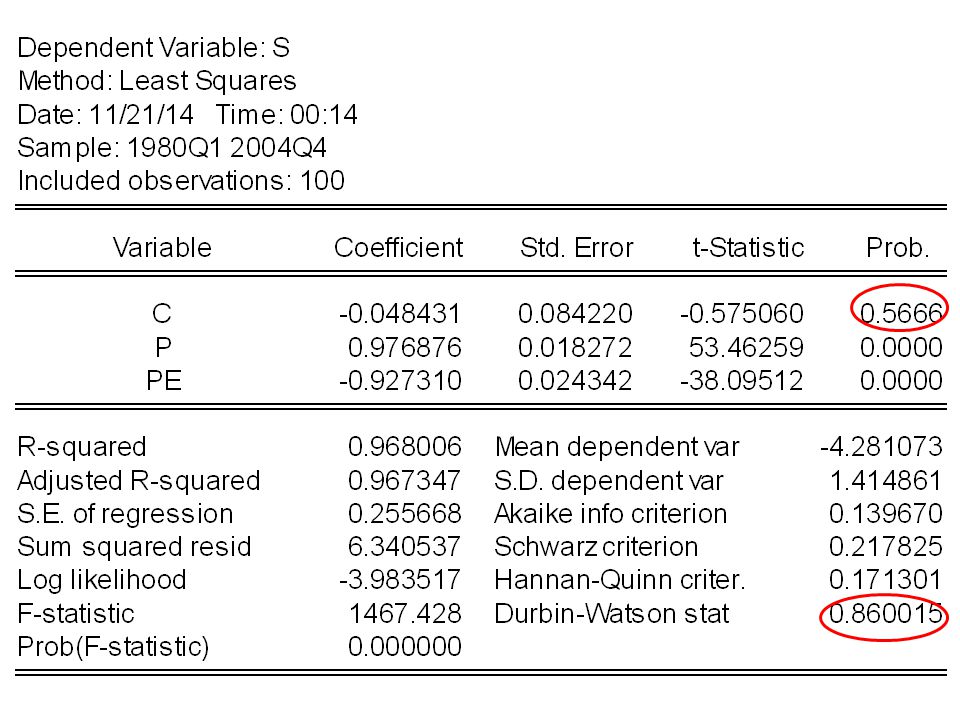
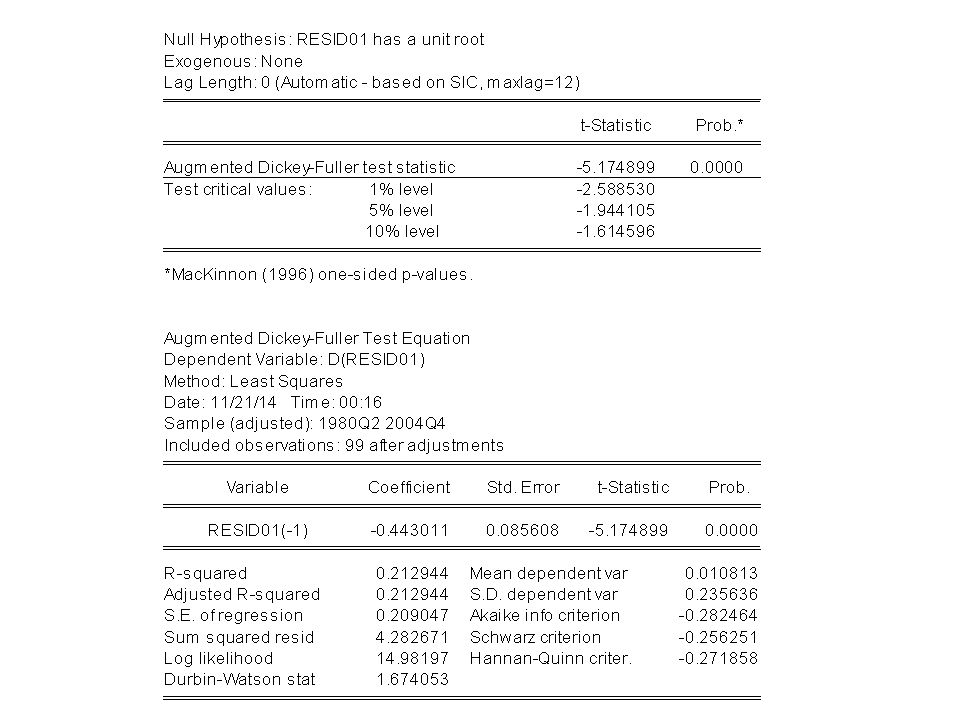
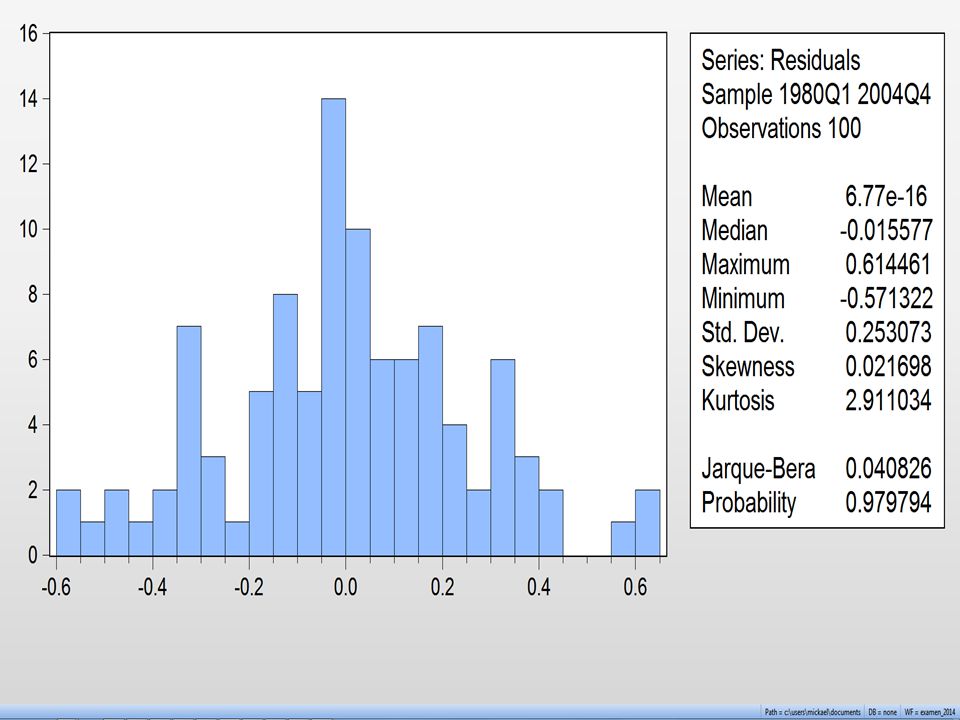
Le DW ne peut se calculer que pour une séries temporelle avec au moins 15 pas et avec une constante.
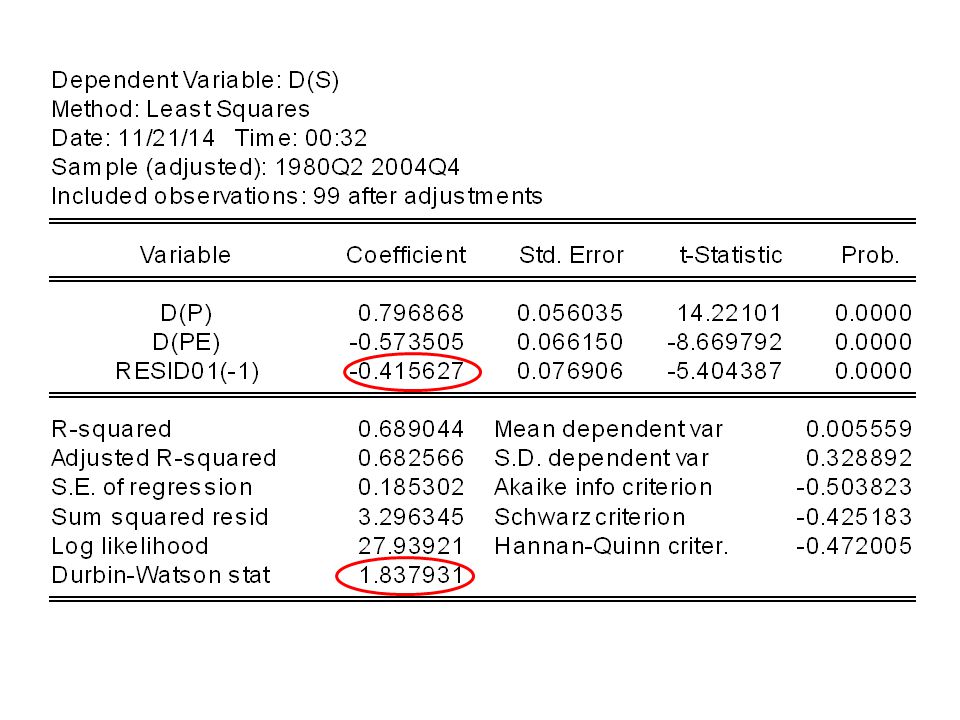
Les résidus obtenus dans la régression précédente on a un DW nettement inférieur à 2 et proche de 0, on identifie donc une autocorrélation positive. Afin de générer une autocorrélation négative, j’ai pris les résidus et les ai multiplié alternativement par 1 et -1. Dans ce cas, le graphique décrit bien une autocorrélation négative. Le DW est proche de 4. Tel qu’il est écrit le test de DW permet de détecter uniquement autocorrélation d’ordre 1.

12
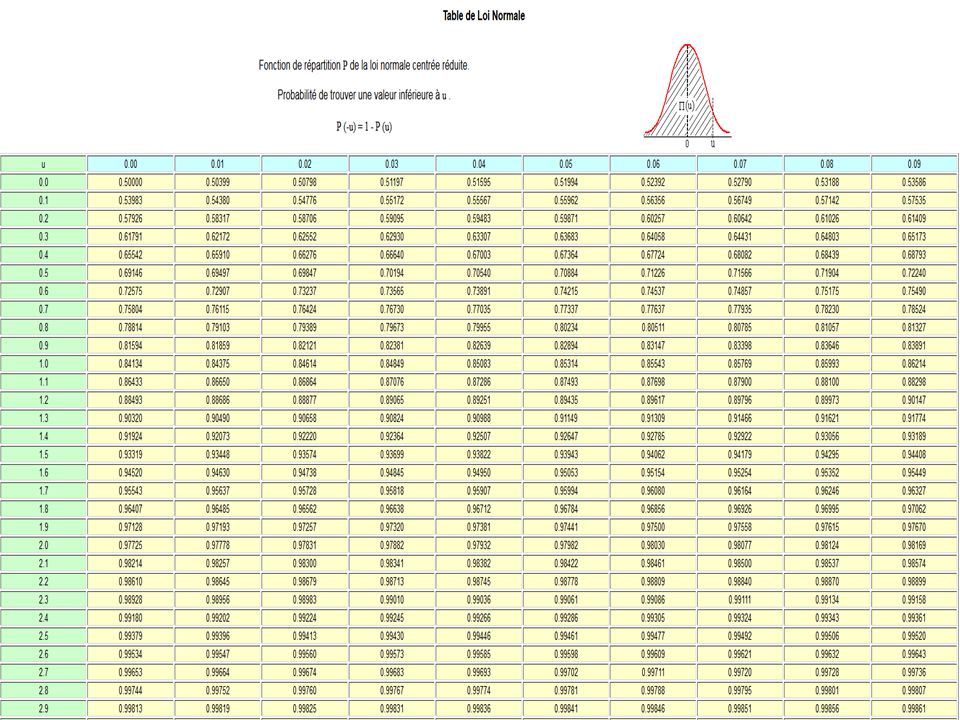
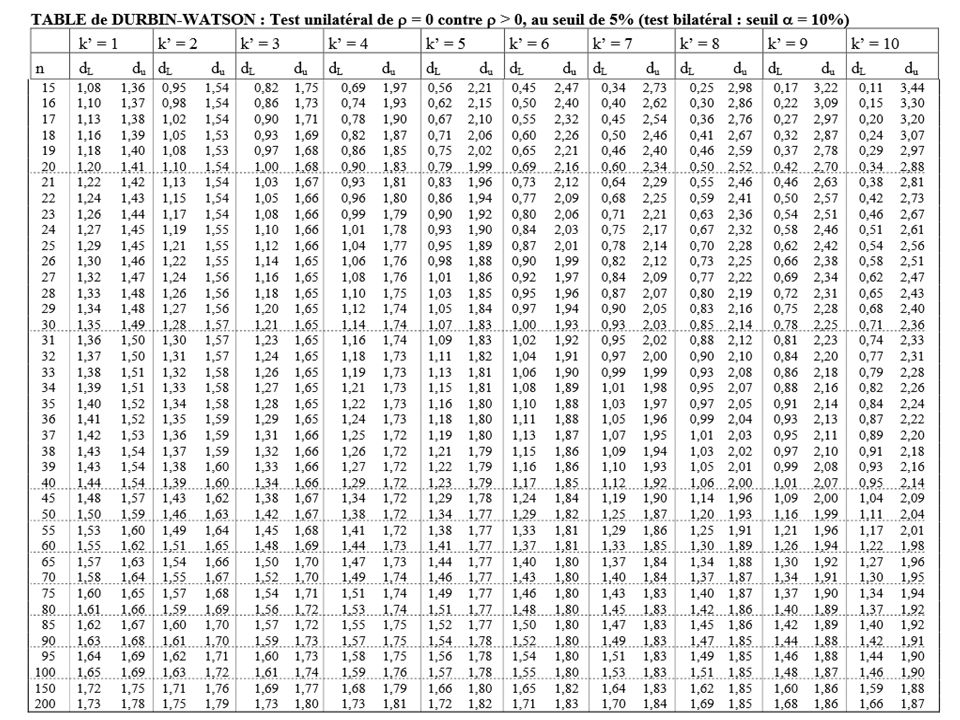
D’un point de vue théorique le DW peut être analysé en fonction de la tabulation de la distribution de cet indicateur. D’un point de vue opérationnel, si DW est nettement ≠ 2 on rejette l’indépendance des erreurs. Si DW <<2 on est en présence d’une autocorrélation positive. Si DW >> 2 on est en présence d’une autocorrélation négative. Si on suit la règle, il faut comparer le DW à d1 et d2 qui sont fonction du nb de période et du nb de variables. Pour un modèle qui serait estimé sur 40 période avec 4 variables, on lit dans la table DW : d1 =1,29 d2 =1,72 Si le DW empirique < d1 autocorrélation +, Si d2 >DW empirique >4-d2 indépendance, Si 4- d2 < DW empirique < 4 autocorrélation – Entre d1 et d2 zone d’incertitude entre 4-d2 et 4-d1 incertitude

13
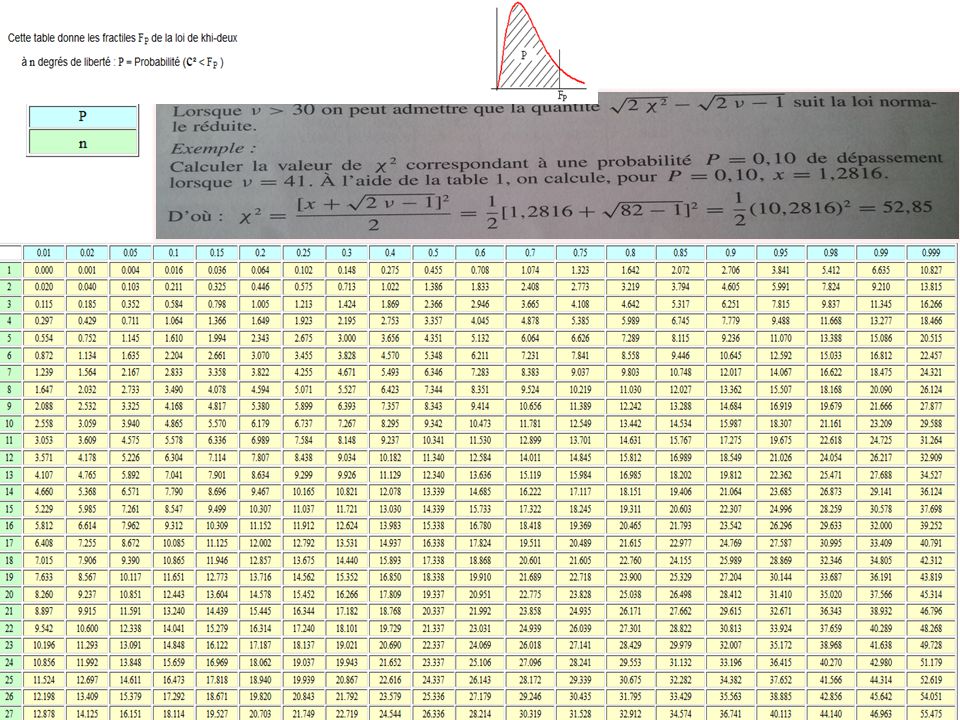
Pour détecter une autocorrélation d’ordre supérieur on peut recourir au teste de Breush-Godfrey celui-ci peut-être réalisé suivant 2 méthodes, un test de Fisher pour lequel on va vérifier que les coefficients des erreurs retard sont tous non différents de 0. Où à travers le multiplicateur de Lagrange qui est distribué comme un χ² Dans les 2 cas puisqu’on ne connait pas les erreurs, il nécessaire de réaliser l’estimation des MCO et d’extraire les résidus.

14
On ne revient pas sur le test de Fisher vu précédemment, il porte sur la même équation que le test de Breusch-Godfrey. On estime les MCO puis on retire les résidus pour estimer cette nouvelle équation: et = a1.x1t + a2.x2t + a3.x3t + a0+ ρ1.et(-1) + ρ2.et(-2) + ρ3.et(-3) A chaque retard on perd une période. Sur un petit échantillon pour éviter de perdre des degrés de liberté, on peut remplacer le résidu par 0 pour éviter cette déperdition. Le test consiste à vérifier si n.R² > χ² (p)
 + ρ2.et(-2) + ρ3.et(-3) A chaque retard on perd une période. Sur un petit échantillon pour éviter de perdre des degrés de liberté, on peut remplacer le résidu par 0 pour éviter cette déperdition. Le test consiste à vérifier si n.R² > χ² (p).")
15
Les tests économétriques de la parité des pouvoirs d'achat
La PPA constitue la théorie de détermination des taux de change d'équilibre la plus couramment utilisée du fait de sa simplicité. La version absolue de la PPA repose sur la loi du prix unique. Un même produit doit être vendu au même prix sur le marché domestique et sur les marchés étrangers par les effets de la concurrence internationale. Si une voiture coûte 5000 euros en France et le même modèle coûte dollars aux États-Unis, selon la loi de prix unique, le prix du taux de change PPA devrait être 5000 euros = dollars ⇒ 0,50 euro pour 1 dollar. Supposons que le taux de change soit plus élevé, à 0,60 euro = 1 dollar. Dans cette situation ce serait intéressent pour le résident des États-Unis d'acheter une voiture en France en économisant 1666,67 dollars pour un achat comparable aux États-Unis. Selon loi du prix unique, les résidents des États-Unis exploiteraient cette possibilité d'arbitrage en achetant des euros et en vendant des dollars. En change flottant, l'euro devrait s'apprécier jusqu'à ce que plus aucune possibilité d'arbitrage soit possible soit un euro équivalent à 2 dollars.

16
Soient P le niveau des prix domestiques d'un panier de biens et P ∗ le niveau des prix étrangers
du même panier de biens (i = 1,2...N), la PPA absolue conduit à l'égalité suivante : avec S taux de change nominal côté à l'incertain du point de vue de la monnaie nationale (1 dollar pour 0,77 euro, ↑ S ⇒ dépréciation nominal) La PPA lie donc le taux de change nominal entre deux monnaies au rapport des prix des deux économies considérées. L'évolution du taux de change nominal doit donc exactement correspondre au rapport des prix dans les 2 pays. A partir de loi du prix unique il vient :
, la PPA absolue conduit à l égalité suivante : avec S taux de change nominal côté à l incertain du point de vue de la monnaie nationale (1. dollar pour 0,77 euro, ↑ S ⇒ dépréciation nominal) La PPA lie donc le taux de change nominal entre deux monnaies au rapport des prix des deux. économies considérées. L évolution du taux de change nominal doit donc exactement correspondre au rapport des prix dans les 2 pays. A partir de loi du prix unique il vient :")
18
5 0,015 -0,025 0,02 0,2 -0,07 0,3 0,05 0,03 250 0,75 -1,25 1 0,075 -3,5 15 2,5 0,005 0,075 -3,5 2,5 0,005

25
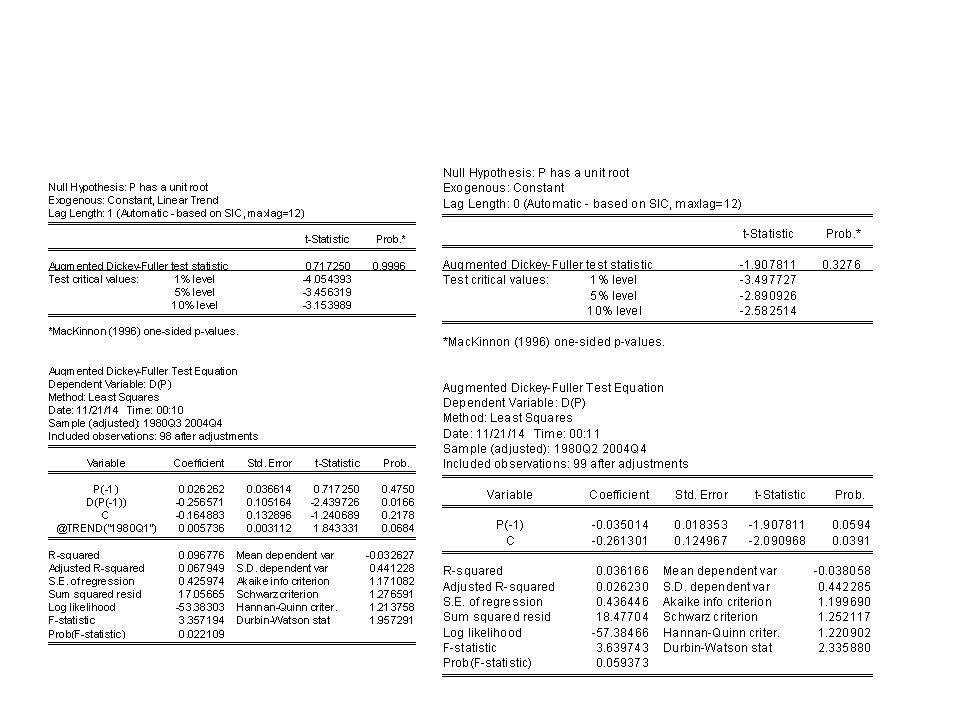
S as stationnaire en niveau

26
S stationnaire en différence avec constante et trend modèle 3

28
P stationnaire en difference avec trend et constante

29
Dans ce cadre on se trouve typiquement dans la situation d’une régression fallacieuse
Les résidus de l’équation sont stationnaires, Mais le ADF est mauvais et finalement les variables ne sont pas stationnaires. Il faut donc traiter cette non stationnarité avec l’intuition qu’il pourrait s’agir de la présence d’une cointégration.

32
Cette technique n’est possible que lorsqu’on a un modèle seulement 2 variables explicatives. Car elle ne retient qu’un vecteur de cointégration. Au-delà on doit recourir à la méthode Johansen et vérifier s’il existe plusieurs vecteurs de cointégration.

33
VECM Théorème de représentation de Granger si des variables sont cointégrées on peut représenter leur dynamique :

34
Pour qu’on puisse envisager le présence d’une cointégration, il est nécessaire que tous les éléments de la matrice A ne soit pas nulle. Si c’est le cas, le problème de la cointégratoin ne se pose pas. Si le rang de la matrice A est égal au nombre de variable, chaque variable à une dynamique propre et l’écriture du modèle VAR contraint ne se justifie pas non plus. Dans ce cas on doit passer à un modèle VAR en différence. La cointégration sera justifiée si on a un nombre de vecteur de cointégration supérieur à 0 mais inférieur au nombre totale de variables du modèle. C’est le test de la trace qui permet de déterminer le nombre de vecteur de cointégration.

35
Le test de Johansen Rang 0 => -28*(LN(1-0,6)+LN(1-0,2293)+LN(1-0,1385)) = 37,12 Rang 1 => =-28*(LN(1-0,2293)+LN(1-0,1385)) = 11,46 Rang 2 => =-28*(LN(1-0,1385)) = 4,17
) = 4,17.")
36
Test de cointégration

40
Fisher à 5 %

41
Fisher à 1 %

43
je reviens vers vous suite au dernier cours d'économétrie où nous butions sur la covariance. Après relecture il s'avère que : Esp[(X'X)^-1 X'Y(Mx*u)'] en remplaçant Y par X*b + u nous obtenons (X'X)^-1X'(X*b+u)(u'*Mx) [b+(X'X)^-1X'u](u'Mx) b*u'MX+(X'X)^-1X'uu'Mx b, X, X' et Mx sont des constantes et peuvent donc être sorties de l'espérance D'après les hypothèses du modèle : E(u') = 0 (attention vous avez, il me semble mis 1 dans votre présentation) E(uu')= sigma^2 * It (identité) la partie de gauche est bien égale à 0 reste l'autre partie : (X'X)^-1X' It Mx par construction Mx = It - X(X'X)^-1 X' X' It = X' (X'X)^-1 X' [It - X(X'X)^-1 X']=(X'X)^-1X' - (X'X)^-1 X' X(X'X)^-1 X' or X' X(X'X)^-1 =It => (X'X)^-1 X' - (X'X)^-1 X' = 0 Correction Clément, merci!
![je reviens vers vous suite au dernier cours d économétrie où nous butions sur la covariance. Après relecture il s avère que : Esp[(X X)^-1 X Y(Mx*u) ] en remplaçant Y par X*b + u nous obtenons (X X)^-1X (X*b+u)(u *Mx) [b+(X X)^-1X u](u Mx) b*u MX+(X X)^-1X uu Mx b, X, X et Mx sont des constantes et peuvent donc être sorties de l espérance D après les hypothèses du modèle : E(u ) = 0 (attention vous avez, il me semble mis 1 dans votre présentation) E(uu )= sigma^2 * It (identité) la partie de gauche est bien égale à 0 reste l autre partie : (X X)^-1X It Mx par construction Mx = It - X(X X)^-1 X X It = X (X X)^-1 X [It - X(X X)^-1 X ]=(X X)^-1X - (X X)^-1 X X(X X)^-1 X or X X(X X)^-1 =It => (X X)^-1 X - (X X)^-1 X = 0](http://slideplayer.fr/slide/2675484/10/images/43/je+reviens+vers+vous+suite+au+dernier+cours+d+%C3%A9conom%C3%A9trie+o%C3%B9+nous+butions+sur+la+covariance.+Apr%C3%A8s+relecture+il+s+av%C3%A8re+que+%3A+Esp%5B%28X+X%29%5E-1+X+Y%28Mx%2Au%29+%5D+en+rempla%C3%A7ant+Y+par+X%2Ab+%2B+u+nous+obtenons+%28X+X%29%5E-1X+%28X%2Ab%2Bu%29%28u+%2AMx%29+%5Bb%2B%28X+X%29%5E-1X+u%5D%28u+Mx%29+b%2Au+MX%2B%28X+X%29%5E-1X+uu+Mx+b%2C+X%2C+X+et+Mx+sont+des+constantes+et+peuvent+donc+%C3%AAtre+sorties+de+l+esp%C3%A9rance+D+apr%C3%A8s+les+hypoth%C3%A8ses+du+mod%C3%A8le+%3A+E%28u+%29+%3D+0+%28attention+vous+avez%2C+il+me+semble+mis+1+dans+votre+pr%C3%A9sentation%29+E%28uu+%29%3D+sigma%5E2+%2A+It+%28identit%C3%A9%29+la+partie+de+gauche+est+bien+%C3%A9gale+%C3%A0+0+reste+l+autre+partie+%3A+%28X+X%29%5E-1X+It+Mx+par+construction+Mx+%3D+It+-+X%28X+X%29%5E-1+X+X+It+%3D+X+%28X+X%29%5E-1+X+%5BIt+-+X%28X+X%29%5E-1+X+%5D%3D%28X+X%29%5E-1X+-+%28X+X%29%5E-1+X+X%28X+X%29%5E-1+X+or+X+X%28X+X%29%5E-1+%3DIt+%3D%3E+%28X+X%29%5E-1+X+-+%28X+X%29%5E-1+X+%3D+0.jpg "Correction Clément, merci!")
Présentations similaires






 r =>")

>")











 Section 3 Tests dhypothèses et lhypothèse linéaire générale Version: 26 janvier 2007.>")



