Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
L’association

2
Plan Définition et Objectifs Association simple
Association séquentielle Filtrage collaboratif Autres méthodes Applications Exemple

3
Définition et Objectifs
Rechercher les relations « stables » existant entre les caractéristiques d’un invididu Applications typiques Personnalisation Connaissant certaines caractéristiques individuelles d’un client, comment prévoir les produits qui vont l’intéresser ? Vente croisée Si un client a déjà acheté certains produits, quels sont les autres produits qui pourraient l’intéresser ?

4
Caractérisation L’association est un problème non supervisé (comme la segmentation) La nature fondamentale du problème est un calcul de probabilité conditionnelle. En fonction des applications : Les résultats attendus Règles d’association Recommandations directes La méthode utilisée Ou comment estimer P(.|.) ?
")
5
Association simple

6
Association simple Méthode issue d’une application: Définition
Le “market basket analysis” (analyse du panier de la ménagère) Définition Découverte de règles du type « Un client qui achète les produits A et B va également acheter le produit C, avec une probabilité p »
 Définition. Découverte de règles du type. « Un client qui achète les produits A et B va également acheter le produit C, avec une probabilité p »")
7
Caractérisation Application Méthode
C’est un problème typique de vente croisée Méthode Uniquement basée sur les données (méthode descriptive ensembliste) Pas d’approche probabiliste formalisée (hypothèse de distribution, etc.)
 Pas d’approche probabiliste formalisée (hypothèse de distribution, etc.)")
8
Difficultés pratiques
Les données Les références produits Nombre Organisation hiérarchique Les transactions Volumes énormes : tickets de caisse, visites de pages web Conséquence Nombre de règles potentiellement énorme Evaluer la pertinence des règles

9
Les clients qui achètent X achètent aussi Y
Evaluation des règles Forme des règles Les clients qui achètent X achètent aussi Y Deux critères fondamentaux Support Nombre de cas où X et Y sont présents Confiance Support (X et Y) / Support (X) (autrement dit P(Y|X))
 / Support (X) (autrement dit P(Y|X))")
10
Formalisation Notations (1)
={x1, x2, …xn} est le catalogue des articles X est un itemset (ensemble d’articles) T=(id,xT) est une transaction ssi id est un identifiant xT est un itemset D est l’ensemble des transactions, appelé base de données
 T=(id,xT) est une transaction ssi. id est un identifiant. xT est un itemset. D est l’ensemble des transactions, appelé base de données.")
11
Formalisation Notations (2)
Une transaction T=(id,xT) supporte X ssi X xT (noté aussi X T) Le support d’un itemset X est le pourcentage de transactions de D qui supportent X Une règle associative est une expression XY, où X et Y sont disjoints
 supporte X ssi X xT (noté aussi X T) Le support d’un itemset X est le pourcentage de transactions de D qui supportent X. Une règle associative est une expression XY, où X et Y sont disjoints.")
12
Exemple Nom Notation Exemple Catalogue D
{crèmerie, poissonnerie, fruits, papeterie, boucherie,conserves, surgelés, bière, vin, eau} Itemset X {crèmerie, eau} Transaction T (10225, {crèmerie,conserves,eau}) Base de données (10221, {fruits,crèmerie, eau}) (10222, {fruits,eau, poissonnerie, papeterie}) (10223, {conserves,crèmerie, eau}) (10224, {fruits, surgelés, crèmerie, eau}) (10225, {crèmerie, conserves, eau}) Support Supp(X) 80% Règle associative X=>Y {crèmerie, eau} {fruits}
 Base de données. (10221, {fruits,crèmerie, eau}) (10222, {fruits,eau, poissonnerie, papeterie}) (10223, {conserves,crèmerie, eau}) (10224, {fruits, surgelés, crèmerie, eau}) (10225, {crèmerie, conserves, eau}) Support. Supp(X) 80% Règle associative. X=>Y. {crèmerie, eau} {fruits}")
13
Reformulation du problème
Rechercher les règles associatives qui sont “vraies” dans la base de données Intuitivement, X=>Y est d’autant plus “vraie” que le pourcentage de transactions contenant Y parmi les transactions contenant X est proche de 1 S’exprime par la confiance de la règle: Confiance(X=>Y) = Supp(XY)/Supp(X) i.e. P(YT|XT)
 = Supp(XY)/Supp(X) i.e. P(YT|XT)")
14
Confiance (X=>Y)=50%
Retour à l’exemple (1) Nom Notation Exemple Catalogue D {crèmerie, poissonnerie, fruits, papeterie, boucherie,conserves, surgelés, bière, vin, eau} Itemset X {crèmerie, eau} Transaction T (10225, {crèmerie,conserves,eau}) Base de données (10221, {fruits,crèmerie, eau}) (10222, {fruits,eau, poissonnerie, papeterie}) (10223, {conserves,crèmerie, eau}) (10224, {fruits, surgelés, crèmerie, eau}) (10225, {crèmerie, conserves, eau}) Support Supp(X) 80% Règle associative X=>Y {crèmerie, eau} {fruits} Confiance (X=>Y)=50%
 Nom. Notation. Exemple. Catalogue. D. {crèmerie, poissonnerie, fruits, papeterie, boucherie,conserves, surgelés, bière, vin, eau} Itemset. X. {crèmerie, eau} Transaction. T. (10225, {crèmerie,conserves,eau}) Base de données. (10221, {fruits,crèmerie, eau}) (10222, {fruits,eau, poissonnerie, papeterie}) (10223, {conserves,crèmerie, eau}) (10224, {fruits, surgelés, crèmerie, eau}) (10225, {crèmerie, conserves, eau}) Support. Supp(X) 80% Règle associative. X=>Y. {crèmerie, eau} {fruits} Confiance (X=>Y)=50%")
15
Confiance (papeterie=>poissonnerie)=100%
Retour à l’exemple (2) Nom Notation Exemple Catalogue D {crèmerie, poissonnerie, fruits, papeterie, boucherie,conserves, surgelés, bière, vin, eau} Itemset X {crèmerie, eau} Transaction T (10225, {crèmerie,conserves,eau}) Base de données (10221, {fruits,crèmerie, eau}) (10222, {fruits,eau, poissonnerie, papeterie}) (10223, {conserves,crèmerie, eau}) (10224, {fruits, surgelés, crèmerie, eau}) (10225, {crèmerie, conserves, eau}) Support Supp(X) 80% Règle associative X=>Y {crèmerie, eau} {fruits} Confiance (papeterie=>poissonnerie)=100%
 Nom. Notation. Exemple. Catalogue. D. {crèmerie, poissonnerie, fruits, papeterie, boucherie,conserves, surgelés, bière, vin, eau} Itemset. X. {crèmerie, eau} Transaction. T. (10225, {crèmerie,conserves,eau}) Base de données. (10221, {fruits,crèmerie, eau}) (10222, {fruits,eau, poissonnerie, papeterie}) (10223, {conserves,crèmerie, eau}) (10224, {fruits, surgelés, crèmerie, eau}) (10225, {crèmerie, conserves, eau}) Support. Supp(X) 80% Règle associative. X=>Y. {crèmerie, eau} {fruits} Confiance (papeterie=>poissonnerie)=100%")
16
Sélection des règles (suite)
La “confiance” d’une règle n’est pas une mesure suffisante Les règles doivent être : Bien représentées (support élevé) Fiables (confiance élevée)
 Fiables (confiance élevée)")
17
Résumé Nom Définition ou formule Commentaire Support d’une règle
Supp(XY)=Supp(XY) Nombre de transactions pour lesquels les deux membres de la règle sont présents. Confiance d’une règle Conf(XY)= Supp(XY)/Supp(X) Probabilité conditionnelle qu’une transaction contienne les articles Y, sachant qu’elle contient les articles X. Itemset fréquent Un itemset dont le support est supérieur à un seuil fixé, minsupp Pour la recherche d’une règle « intéressante », la condition la plus restrictive est que l’itemset associé soit fréquent. La recherche d’itemsets fréquents est donc la premièré étape essentielle de la recherche de règles.
=Supp(XY) Nombre de transactions pour lesquels les deux membres de la règle sont présents. Confiance d’une règle. Conf(XY)= Supp(XY)/Supp(X) Probabilité conditionnelle qu’une transaction contienne les articles Y, sachant qu’elle contient les articles X. Itemset fréquent. Un itemset dont le support est supérieur à un seuil fixé, minsupp. Pour la recherche d’une règle « intéressante », la condition la plus restrictive est que l’itemset associé soit fréquent. La recherche d’itemsets fréquents est donc la premièré étape essentielle de la recherche de règles.")
18
Mise en oeuvre Principe Difficultés
Rechercher les itemsets fréquents Z Chercher les décompositions de Z en X et Y ayant une confiance élevée Difficultés Espace de recherche énorme Nb références~ k.104 Nb transactions ~ k.106 Le nombre d’itemsets est le nombre de parties d’un ensemble (2N) ! Calcul du support : évaluer pour chaque transaction si un itemset y est présent ou pas
 ! Calcul du support : évaluer pour chaque transaction si un itemset y est présent ou pas.")
19
Algorithme APriori IBM Idée fondamentale (très simple)
Projet QUEST (datamining) A conduit au développement de IntelligentMiner Idée fondamentale (très simple) Tous les sous-ensembles d’un itemset fréquent sont fréquents Les surensembles d’un itemset non fréquent ne sont pas fréquents (contraposée)
 A conduit au développement de IntelligentMiner. Idée fondamentale (très simple) Tous les sous-ensembles d’un itemset fréquent sont fréquents. Les surensembles d’un itemset non fréquent ne sont pas fréquents (contraposée)")
20
Principe d’APriori

21
Algorithme APriori Recherche des singletons fréquents (i.e. les articles les plus consommés) Soit Lk = {itemsets fréquents à k éléments} A partir de Lk, on calcule un ensemble de candidats Ck+1 On considère deux éléments de Lk qui diffèrent par un seul élément et on en fait l’union pour obtenir un candidat ck+1 On considère alors tous les sous-ensembles à k éléments de ck+1. S’ils sont tous dans Lk, on conserve ck+1 dans Ck+1. Sinon, on passe au candidat suivant. Les éléments de Ck+1 de support supérieur à minsupp forment Lk+1.

22
Exemple L2={{1,2}, {1,3}, {1,4}, {2,3}, {2,4}} Construction de C3
{1,2,3} OK {1,2,4} OK {1,3,4} rejeté ({3,4} L2) {2,3,4} rejeté ({3,4} L2) C3={{1,2,3}, {1,2,4}} Test de support sur C3 : passe seulement sur {1,2,4}
 {2,3,4} rejeté ({3,4} L2) C3={{1,2,3}, {1,2,4}} Test de support sur C3 : passe seulement sur {1,2,4}")
23
Apport d’information d’une règle
Nom Notation Exemple Catalogue D {crèmerie, poissonnerie, fruits, papeterie, boucherie,conserves, surgelés, bière, vin, eau} Itemset X {crèmerie, eau} Transaction T (10225, {crèmerie,conserves,eau}) Base de données (10221, {fruits,crèmerie, eau}) (10222, {fruits,eau, poissonnerie, papeterie}) (10223, {conserves,crèmerie, eau}) (10224, {fruits, surgelés, crèmerie, eau}) (10225, {crèmerie, conserves, eau}) Support Supp(X) 80% Règle associative X=>Y {crèmerie, eau} {fruits} Confiance ({fruits,crèmerie}=> {eau})=100% Mais Support({eau})=100% !!!
 Base de données. (10221, {fruits,crèmerie, eau}) (10222, {fruits,eau, poissonnerie, papeterie}) (10223, {conserves,crèmerie, eau}) (10224, {fruits, surgelés, crèmerie, eau}) (10225, {crèmerie, conserves, eau}) Support. Supp(X) 80% Règle associative. X=>Y. {crèmerie, eau} {fruits} Confiance ({fruits,crèmerie}=> {eau})=100% Mais Support({eau})=100% !!!")
24
Apport d’information d’une règle
Lift = Confiance(XY)/Support(Y) Exemple Nombre de transactions : 1000 Transactions contenant {Lait}: 200 Transactions contenant {Bière}: 50 Transactions contenant {Lait,Bière}: 20 Support(Y) = 50/1000 = 5% Confiance(XY) = 20/200 = 10% Lift = 10%/5% = 2
/Support(Y) Exemple. Nombre de transactions : Transactions contenant {Lait}: 200. Transactions contenant {Bière}: 50. Transactions contenant {Lait,Bière}: 20. Support(Y) = 50/1000 = 5% Confiance(XY) = 20/200 = 10% Lift = 10%/5% = 2.")
25
Améliorations de l’algorithme APriori
Noyau de l’algorithme Apriori : Utiliser les (k – 1)-itemsets fréquents pour générer des k-itemsets candidats Parcourir la base de données pour calculer le support des candidats et les évaluer. Limites Génération des candidats toujours énorme Parcours de la BD pour évaluer le support Améliorations possibles Ordonner les articles Elimination des candidats contenant des sous-ensembles non-fréquents Supprimer les transactions ne contenant pas d’itemsets fréquents
-itemsets fréquents pour générer des k-itemsets candidats. Parcourir la base de données pour calculer le support des candidats et les évaluer. Limites. Génération des candidats toujours énorme. Parcours de la BD pour évaluer le support. Améliorations possibles. Ordonner les articles. Elimination des candidats contenant des sous-ensembles non-fréquents. Supprimer les transactions ne contenant pas d’itemsets fréquents.")
26
Améliorations de l’algorithme APriori
Algorithme FP Growth (Han, Pei, Yin 2000) Avantage : recherche d’ensembles fréquents sans génération de candidats Principe : résumer la BD sous forme d’un arbre (Frequent Pattern Tree) Démarche : Parcourir une fois la BD pour ordonner les articles par fréquence décroissante Organiser les transactions de la base (triées suivant l’ordre précédent) en un arbre
 Avantage : recherche d’ensembles fréquents sans génération de candidats. Principe : résumer la BD sous forme d’un arbre (Frequent Pattern Tree) Démarche : Parcourir une fois la BD pour ordonner les articles par fréquence décroissante. Organiser les transactions de la base (triées suivant l’ordre précédent) en un arbre.")
27
Construction de l’arbre FP
ID Articles 1 {A,B} 2 {B,C,D} 3 {A,C,D,E} 4 {A,D,E} 5 {A,B,C} 6 {A,B,C,D} 7 {B,C} 8 9 {A,B,D} 10 {B,C,E} A:1 B:1 B:1 A:1 B:1 C:1 D:1

28
Construction de l’arbre FP
ID Articles 1 {A,B} 2 {B,C,D} 3 {A,C,D,E} 4 {A,D,E} 5 {A,B,C} 6 {A,B,C,D} 7 {B,C} 8 9 {A,B,D} 10 {B,C,E} A:7 B:1 B:5 C:1 C:1 D:1 C:3 D:1 D:1 D:1 D:1

29
Exploration de l’arbre FP
Préconditions pour C AB:3 A:1 B:1 Itemsets fréquents contenant C ABC:3 AC:4 BC:4 A:7 B:1 B:5 C:1 C:1 D:1 C:3 D:1 D:1 D:1 D:1

30
Introduction de hiérarchies
Vêtements VilleChaussures Villes peut être valide, même si: Chemises Chaussures Villes Pantalons Chaussures Villes ne sont pas valides

31
Conclusion Recherche de règles d’association
Approche ensembliste Apparentée à l’interrogation de base de données Peu ou pas de fondement statistique Distribution sous-jacente ? Significativité des règles ? L’une des méthodes de datamining les plus utilisées Consommation (supermarchés) Analyse de pannes Web usage mining
 Analyse de pannes. Web usage mining.")
32
Association séquentielle

33
Association séquentielle
Application typique : Web usage Mining Analyse des séquences de navigation sur un site (A→B→C≠ A→C→B) Forme générale d’une séquence d’action: <(A) (B C) (D)> Le client a effectué l’action A, puis simultanément les actions B et C, puis l’action D. Notion de simultanéité : même commande, même visite, même période de temps ?
 Forme générale d’une séquence d’action: <(A) (B C) (D)> Le client a effectué l’action A, puis simultanément les actions B et C, puis l’action D. Notion de simultanéité : même commande, même visite, même période de temps")
34
Association séquentielle
Web Usage Mining Utilisation de fichiers « access log » Equivalence : « panier de la ménagère » ~ « comportement d’un visiteur sur un serveur » Applications reconception ou modification dynamique de la structure d’un site préchargement des données

35
Recherche de séquences
Support = 60% (3 clients) => <(10 30) (20) (60 20)>
 => <(10 30) (20) (60 20)>")
36
Filtrage collaboratif

37
Le filtrage collaboratif
Ou “filtrage par communauté de préférence” Méthode développée pour une application concrète : estimation de l’intérêt de clients pour un produit donné. Utilisé essentiellement pour des produits culturels : livres (Amazon), films (moviecritic)
, films (moviecritic)")
38
Exemple: Amazon

39
Position du problème Système de recommandation
Conseiller un produit “culturel” à quelqu’un Le conseil est bon si le produit a “plu” à la personne Différent de la recommandation commerciale classique où le conseil est bon si le produit recommandé est acheté Comment évaluer la qualité d’un tel système ?

40
Evaluation d’un système de recommandation
La recommandation est bonne si le spectateur : Va voir le film Confirme qu’il lui a plu Le système est comparé avec : Recommandation aléatoire Recommandation majoritaire (hit-parade)
")
41
Améliorer la recommandation majoritaire
“Hit-parade” conditionnel Exemple : proposer aux jeunes le hit-parade des jeunes Filtrer la population sur laquelle on établit le hit-parade Filtrage par communautés de préférence Sélectionner ceux qui ont les mêmes goûts que le spectateur considéré

42
Principe du filtrage collaboratif

43
Avantages & Inconvénients
Aucune connaissance sur les spectateurs n’est nécessaire Aucune analyse des contenus n’est nécessaire Inconvénients Nécessite un volume de données initial important (impossible de conseiller quelqu’un qui n’a vu aucun film) Ne permet pas de prendre en compte la proximité entre les contenus (pour gérer les cas de faible intersection)
 Ne permet pas de prendre en compte la proximité entre les contenus (pour gérer les cas de faible intersection)")
44
Formalisation Un algorithme de filtrage collaboratif se définit par :
Le calcul de la proximité entre deux personnes (« spectateurs ») La méthode de filtrage (sélection des individus dits « proches ») La méthode de prévision (production d’une note pour un film)
 La méthode de filtrage (sélection des individus dits « proches ») La méthode de prévision (production d’une note pour un film)")
45
Formalisation On utilise en général
Un coefficient de corrélation entre deux utilisateurs comme proximité, Un seuillage comme méthode de filtrage Une moyenne pondérée par les distances comme méthode de prévision

46
Exemple de formalisation
Proximité La proximité entre l’utilisateur a et l’utilisateur u est calculée comme un coefficient de corrélation entre leurs notations (représente la notation de l’utilisateur a pour l’article i, représente la moyenne des notes de l’utilisateur a , et l’écart-type des notes de l’utilisateur a. Sélection On sélectionne comme « voisins » de l’utilisateur a ceux dont la proximité est supérieure à un certain seuil. Prévision La prévision de note du système pour l’utilisateur a et l’article i est calculée comme la moyenne des notes que l’article i a obtenu parmi les voisins de l’utilisateur a. (noter qu’on a recentré les notes par rapport à la moyenne des notes de chaque utilisateur considéré).
.")
47
GroupLens Créé en 1995 à l’University of Minnesota
Site de recommandation Fonctionnement Evaluation de 15 films minimum Proposition de recommandations

48
Améliorations Problème Idée Organisation arborescente des contenus
Intersection des évaluations vide “Ceux qui ont acheté ces livres …”= Idée Organisation arborescente des contenus Ceux qui ont acheté Ces livres ou … des livres dans cette catégorie ou … des livres dans cet ensemble de catégories

49
Autres techniques

50
Les réseaux bayésiens Aujourd’hui Cours “Classification”
Une présentation intuitive Sur un exemple Cours “Classification” Formalisation complète

51
Etude “club-java.com” Site de contenu technique sur Java
Objectif de l’application Personnaliser les contenus offerts aux visiteurs A partir d’un modèle de leurs préférences

52
Introduction aux réseaux bayésiens
Un modèle graphique probabiliste de connaissances Acquisition de la connaissance Utilisation de la connaissance

53
Modèles graphiques probabilistes de connaissance
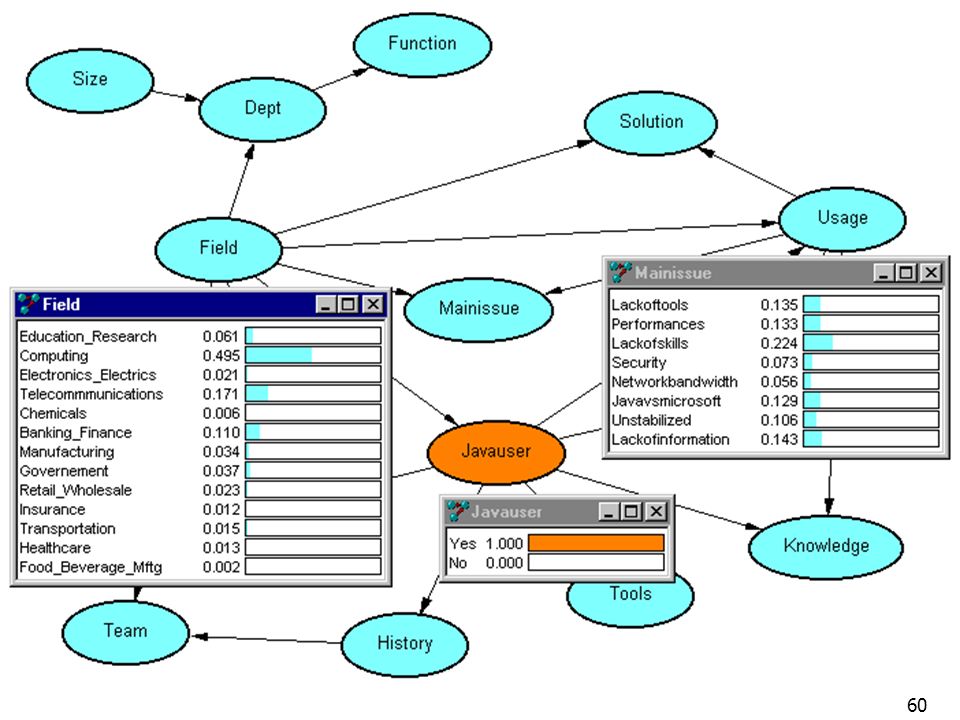
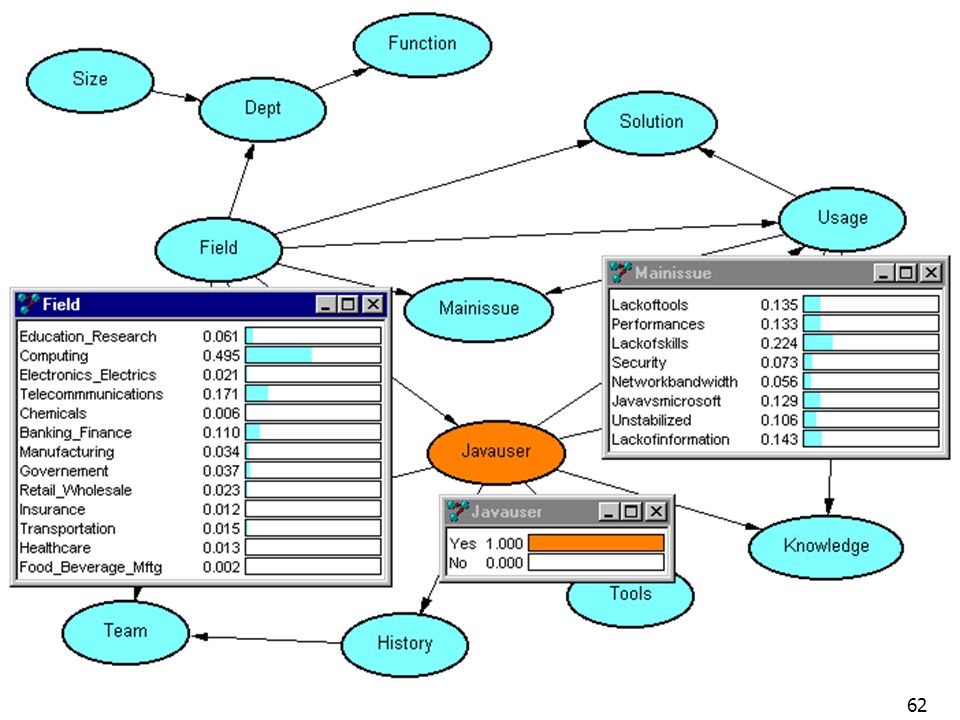
Mainissue Solution Usage JavaUser Field Le graphe représente la structure de la connaissance “ le principal problème perçu (MainIssue) dépend du domaine d’activité (Field) et de l’usage de Java (Usage) ” La connaissance est quantifiée par des probabilités P(MainIssue|Field, Usage) Le réseau bayésien est une distribution de probabilités factorisée suivant le graphe P(Field).P(JavaUser|Field).P(Usage|JavaUser).P(MainIssue|Field,Usage).P(Solution|FieldUsage)
 dépend du. domaine d’activité (Field) et de l’usage de Java (Usage) La connaissance est quantifiée par des probabilités. P(MainIssue|Field, Usage) Le réseau bayésien est une distribution de probabilités factorisée suivant le graphe. P(Field).P(JavaUser|Field).P(Usage|JavaUser).P(MainIssue|Field,Usage).P(Solution|FieldUsage)")
54
Acquisition de la connaissance
Apprentissage de la structure Expertise Données ?? Apprentissage des paramètres Données Expertise ?? Mainissue Solution Usage JavaUser Field P(Field=Telecommunications), P(Field=Computing), ... P(MainIssue=LackofTools|Field=Computing, Usage=B2C), P(MainIssue=LackofTools|Field=Computing, Usage=B2B),
, P(Field=Computing), ... P(MainIssue=LackofTools|Field=Computing, Usage=B2C), P(MainIssue=LackofTools|Field=Computing, Usage=B2B),")
55
Utilisation de la connaissance
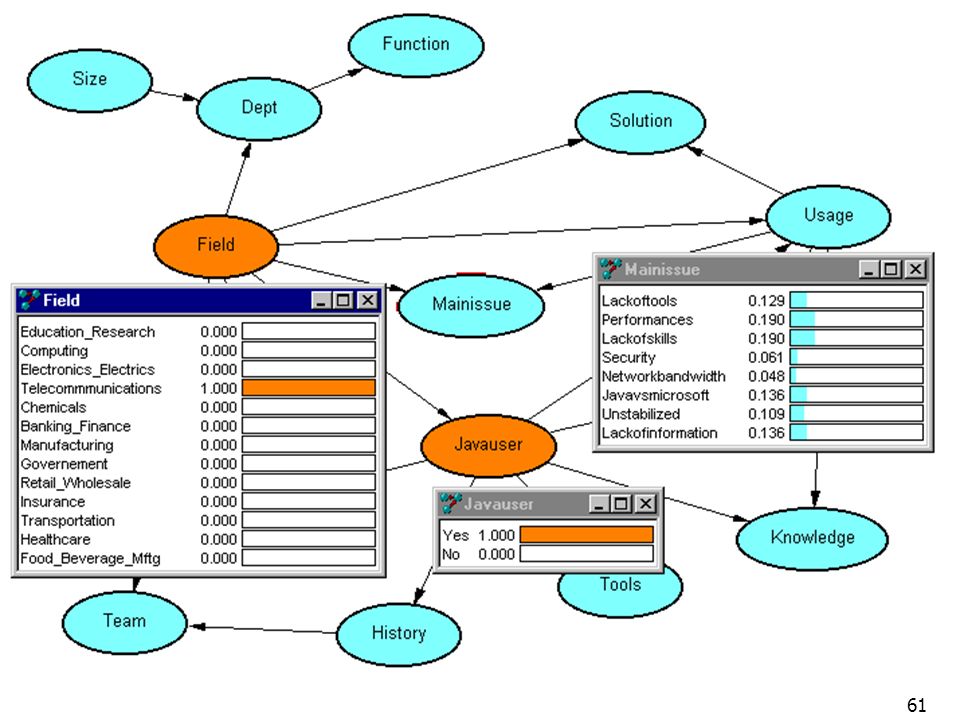
Mise à jour des probabilités : P(X|e) Calculer la probabilité de variables non observées, à partir d’une information partielle Inférences avancées Maximum a posteriori Analyse de sensibilité Gain d’information etc. Probabilité (X|e) ? Field observation(e) Mainissue Solution Usage JavaUser Field
 Calculer la probabilité de variables non observées, à partir d’une information partielle. Inférences avancées. Maximum a posteriori. Analyse de sensibilité. Gain d’information. etc. Probabilité (X|e) Field. observation(e) Mainissue. Solution. Usage. JavaUser. Field.")
56
Données Environ 1000 questionnaires
21 questions, la plupart à réponses multiples 116 questions à réponse simple Q1.1 For what kind of application do you feel Java may be useful for ? B2B Customer care … Q2.15 What kind of tools or solutions are you using ? Application servers Java-enabled databases ...

57
JESS 99 : Connaissances Analyse des données Expertise
Axes factoriels principaux Classification hiérarchique Expertise Pas d’expertise spécifique Connaissance de “bon sens” Les données sont supposées représenter : la distribution des visiteurs de Jess par extension, celle des utilisateurs de Java

58
Mise au point du modèle Apprentissage de structure
apprentissage automatique addition “manuelle” de liens : bon sens, évolution Apprentissage de paramètres Outil utilisé Bayesian Knowledge Discoverer

59
Le modèle obtenu Mainissue Solution Usage JavaUser Field Tools History
Team Success Dept Size Function Knowledge Need

64
La mise en ligne du modèle
Principe Personnalisation du site Club-Java 4. recommandation 1. navigation Exemple de mise en oeuvre fonctionnelle 2. observation 3. inférence

Présentations similaires