Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
RECONNAISSANCE DE FORMES
approche statistique pour les objets « simples » : mesure sur des objets par exemple en chaîne de production « bons » et « mauvais » B. approche structurelle : description d’objets complexes sous forme de graphes liant des objets plus simples pour représenter ces objets complexes ECRITURE MANUSCRITE SIGNATURE VISAGES, BIOMETRIE OBJETS ET ENVIRONNEMENT EN ROBOTIQUE idée à retenir : tout cela ne marche pas très bien les approches sont encore élémentaires ; on ne sait pas encore mimer le fonctionnement cérébral

2
A. approche statistique
approche standard en reconnaissance de formes d’objets « simples » (classification) un objet analysé à reconnaître est représenté sous la forme d’un vecteur de paramètres nécessité d’un apprentissage dans le même espace, on dispose de formes types, apprises au préalable correspondant aux objets à reconnaître reconnaître l’objet c’est décider que le vecteur caractérisant l’objet analysé à reconnaître est suffisamment proche d’un des vecteur mémorisés lors de l’apprentissage approche probabiliste ; théorie de la décision (critère de bayes et de neyman pearson) problèmes : bruit, préanalyse incorrecte (contours, régions) fluctuations importantes d’un objet à l’autre
 un objet analysé à reconnaître est représenté sous la forme. d’un vecteur de paramètres. nécessité d’un. apprentissage. dans le même espace, on dispose de formes types, apprises au préalable correspondant aux objets à reconnaître. reconnaître l’objet c’est décider que le vecteur caractérisant l’objet analysé à reconnaître est suffisamment proche d’un des vecteur mémorisés lors de l’apprentissage. approche probabiliste ; théorie de la décision (critère de bayes. et de neyman pearson) problèmes : bruit, préanalyse incorrecte (contours, régions) fluctuations importantes d’un objet à l’autre.")
3
Reconnaissance de formes Approche statistique
Un objet est décrit comme un ensemble de paramètres (un vecteur de dimension réduite) longueur largeur
 longueur. largeur.")
4
Il y a des fluctuations d’un objet à l’autre
Chaque groupe (classe) est associée à un nuage de points Comment décide t on de l’appartenance à une classe ? longueur longueur L L R R largeur largeur Formalisation probabiliste
 est associée à un nuage de points. Comment décide t on de l’appartenance à une classe longueur. longueur. L. L. R. R. largeur. largeur. Formalisation probabiliste.")
5
séparation de l’espace des paramètres en régions mesure de paramètres objet représenté par un vecteur

6
représenter les classes sous forme de densités de probabilités

7
maximiser la probabilité d’appartenance à une classe

8
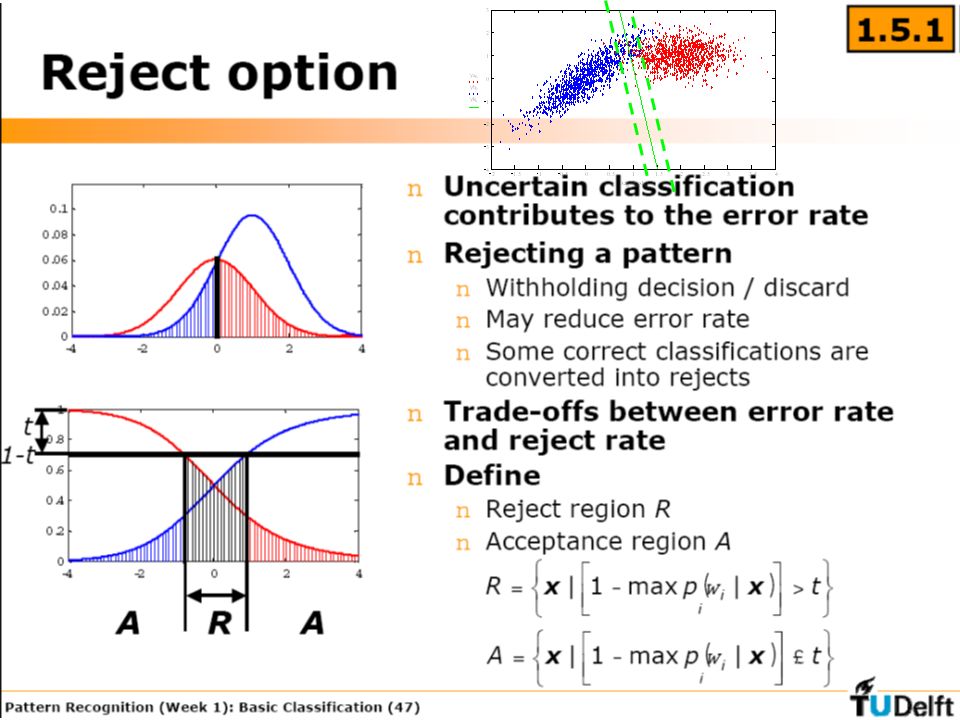
Probabilité d’appartenance à un des deux groupes

9
Seuil s en dessous duquel on décide que x appartient à la classe L
Evaluation de la probabilité d’erreur Rapport de vraisemblance Extension : test d’hypothèse en statistique (critère de Neyman Pearson)
")
10
Notions de Théorie de la Décision
décider si un élément caractérisé par un vecteur de paramètres appartient à une classe ou à une autre séparatrice

11
probabilité d’erreur évaluer le coût des erreurs de décision en déduire le critère de décision deux approches classiques élémentaire : Bayes plus élaboré : Neyman Pearson

12
Si la cause est u = 0 , la loi de probabilité de y est p(y|u = 0)
Approche bayesienne y réel, peut être produit uniquement par une cause u qui ne prend que les valeurs 0 ou 1 ; probabilités pour que u = 0 ou 1, q0 et q1, connues Si la cause est u = 0 , la loi de probabilité de y est p(y|u = 0) si la cause est u = 1 , la loi de probabilité de y est p(y|u = 1)
 si la cause est u = 1 , la loi de probabilité de y est p(y|u = 1)")
13
Le problème de la décision : on a mesuré y ;
choisir parmi les deux propositions (d = 0 et d = 1): ‘y a été causé par u = 0’ ou ‘y a été causé par’ u = 1 ; il faut se donner une fonction de pénalité : les quatre coûts associés aux situations possibles c(0|0) quand on choisit d = 0 et que la vraie valeur est u = 0 c(0|1) quand on choisit d = 0 et que la vraie valeur est u = 1 c(1|0) quand on choisit d = 1 et que la vraie valeur est u = 0 c(1|1) quand on choisit d = 1 et que la vraie valeur est u = 1
: ‘y a été causé par u = 0’ ou ‘y a été causé par’ u = 1 ; il faut se donner une fonction de pénalité : les quatre coûts associés aux situations possibles. c(0|0) quand on choisit d = 0 et que la vraie valeur est u = 0. c(0|1) quand on choisit d = 0 et que la vraie valeur est u = 1. c(1|0) quand on choisit d = 1 et que la vraie valeur est u = 0. c(1|1) quand on choisit d = 1 et que la vraie valeur est u = 1.")
14
Pour une valeur de y mesurée,
on choisira d = 0 si le coût associé à ce choix est moins élevé que le coût associé au choix d = 1 Calcul de la valeur moyenne du coût associé au choix u = 0 en tenant compte du fait que cette valeur de y a pu avoir une des deux causes

15
les quatre possibilités de choix
les probabilités associées u=0 & d=0 u=0 & d=1 u=1 & d=0 u=1 & d=1 p(y|u=0).q0 p(y|u=1).q1
.q0. p(y|u=1).q1.")
16
Les coûts moyens associés aux décisions sont obtenus
en considérant pour chaque décision les probabilités des valeurs possibles de u : c(1|0) p(y|u=0).q0 + c(1|1)p(y|u=1).q1 d = 1 d = 0 c(0|0) p(y|u=0).q0+ c(0|1)p(y|u=1).q1 On choisit d = 0 si, en moyenne, cela coûte moins que de choisir d = 1, c(0|0) p(y|u=0).q0+ c(0|1)p(y|u=1).q1 < c(1|0) p(y|u=0).q0 + c(1|1)p(y|u=1).q1,
 p(y|u=0).q0 + c(1|1)p(y|u=1).q1. d = 1. d = 0. c(0|0) p(y|u=0).q0+ c(0|1)p(y|u=1).q1. On choisit d = 0 si, en moyenne, cela coûte moins que de choisir d = 1, c(0|0) p(y|u=0).q0+ c(0|1)p(y|u=1).q1. < c(1|0) p(y|u=0).q0 + c(1|1)p(y|u=1).q1,")
17
(c(0|1) - c(1|1))p(y|u=1).q1 < (c(1|0) - c(0|0) )p(y|u=0).q0 .
c(0|0) p(y|u=0).q0+ c(0|1)p(y|u=1).q1< c(1|0) p(y|u=0).q0 + c(1|1)p(y|u=1).q1, (c(0|1) - c(1|1))p(y|u=1).q1 < (c(1|0) - c(0|0) )p(y|u=0).q0 . hypothèse : coûts des mauvaises décisions plus élevés que coûts des décisions correctes (c(0|0)< c(1|0) et c(1|1)< c(0|1)), on choisira d = 0 lorsque
 p(y|u=0).q0+ c(0|1)p(y|u=1).q1< c(1|0) p(y|u=0).q0 + c(1|1)p(y|u=1).q1, (c(0|1) - c(1|1))p(y|u=1).q1 < (c(1|0) - c(0|0) )p(y|u=0).q0 . hypothèse : coûts des mauvaises décisions plus élevés. que coûts des décisions correctes. (c(0|0)< c(1|0) et c(1|1)< c(0|1)), on choisira d = 0 lorsque.")
18
Un exemple : deux lois de probabilités conditionnelles gaussiennes

19
choix des valeurs des pénalités
Pour minimiser le critère, on choisira l’hypothèse u = 1 si y est dans l’intervalle (ymin=0.87 , ymax=1.21) ; si y est en dehors de cet intervalle, on choisira u = 0.
 ; si y est en dehors de cet intervalle, on choisira u = 0.")
20
probabilité de détection correcte
probabilité d’erreur (fausse alarme)
")
21
Règle de Bayes : définition des probabilités conditionnelles
On écrit de deux manières différentes p(u = 0| y) peut être écrit en fonction de p(y|u = 0) la probabilité p(y) s’écrit en fonction des probabilités conditionnelles et on en déduit .
 peut être écrit en fonction de p(y|u = 0) la probabilité p(y) s’écrit en fonction des probabilités conditionnelles. et on en déduit. .")
22
Critère de Neyman Pearson
probabilités a priori des causes q0 = p(u=0) et q1 = p(u=1) inconnues. décider si une mesure x correspond à l’émission d’une donnée u = 0, et dans ce cas la densité de probabilité de x est p0(x) ; ou si elle correspond à l’émission u = 1, et dans ce cas la densité de probabilité de x est p1(x) ; maximiser la probabilité de détection correcte (ici u=1) sous la contrainte que la probabilité de fausse alarme ne dépasse pas un seuil fixé a priori
 et q1 = p(u=1) inconnues. décider. si une mesure x correspond à l’émission d’une donnée u = 0, et dans ce cas la densité de probabilité de x est p0(x) ; ou si elle correspond à l’émission u = 1, et dans ce cas la densité de probabilité de x est p1(x) ; maximiser la probabilité de détection correcte (ici u=1) sous la contrainte que la probabilité de fausse alarme. ne dépasse pas un seuil fixé a priori.")
23
les densités de probabilités
des événements : rouge : il y a erreur vert : la détection est correcte quand faut il décider qu’il y a effectivement détection? (elle ne peut pas toujours être correcte) calcul sur un domaine xmin<xmax des probabilités de fausse alarme et de détection correcte
 calcul sur un domaine xmin<xmax des probabilités. de fausse alarme et de détection correcte.")
24
calcul sur un domaine xmin<xmax des probabilités
de fausse alarme et de détection correcte xmin xmin xmax<xmin xmax<xmin xmax probabilité de fausse alarme probabilité de décision correcte xmax

25
domaine où la probabilité de fausse alarme
est en dessous d’un seuil fixé à 0.1 sur ce domaine : probabilité de détection correcte xmin xmin xmax<xmin xmax<xmin xmax xmax probabilité de fausse alarme probabilité de décision correcte sur la frontière (pfa =0.1niveau rouge sur la figure de gauche) on trouve le maximum de la probabilité de décision correcte
 on trouve le maximum de la probabilité de décision correcte.")
26
Critère de Neyman Pearson
probabilités a priori des causes q0 = p(u=0) et q1 = p(u=1) inconnues. décider si une mesure x correspond à l’émission d’une donnée u = 0, et dans ce cas la densité de probabilité de x est p0(x) ; ou si elle correspond à l’émission u = 1, et dans ce cas la densité de probabilité de x est p1(x) ; on décidera que d = 1 si dépasse un seuil s donné de la manière suivante
 et q1 = p(u=1) inconnues. décider. si une mesure x correspond à l’émission d’une donnée u = 0, et dans ce cas la densité de probabilité de x est p0(x) ; ou si elle correspond à l’émission u = 1, et dans ce cas la densité de probabilité de x est p1(x) ; on décidera que d = 1 si. dépasse un seuil s donné de la manière suivante")
27
maximiser la probabilité pdc
de détection correcte (d = 1 quand u = 1) ; ( la probabilité pem d’un événement manqué (d = 0 alors que u = 1) vaut 1 - pdc;) pour chaque mesure x, considérer la probabilité pfa d’une fausse alarme (d = 1 alors que u = 0) probabilité de fausse alarme pfa : probabilité que u = 0 alors que dépasse le seuil s pfaest l’intégrale de la densité de probabilité p0(x) calculée pour l’ensemble des valeurs (domaine D) de x pour lequel ce seuil est dépassé
 ; ( la probabilité pem d’un événement manqué. (d = 0 alors que u = 1) vaut 1 - pdc;) pour chaque mesure x, considérer la probabilité. pfa d’une fausse alarme (d = 1 alors que u = 0) probabilité de fausse alarme pfa : probabilité que u = 0. alors que. dépasse le seuil s. pfaest l’intégrale de la densité de probabilité p0(x) calculée pour l’ensemble des valeurs (domaine D) de x. pour lequel ce seuil est dépassé")
28
les probabilités a priori des causes ne sont pas prises en compte ;
Exemple de densités de probabilité et de leur rapport utilisé pour illustrer l’approche de Neyman Pearson si le seuil s est choisi égal à 2, on décide d = 1 lorsque x est dans l’interv. (0.7, 1.4) probabilité de détection correcte probabilité de fausse alarme = 0.158
 probabilité de détection correcte. probabilité de fausse alarme. =")
29
Neyman Pearson : on se donne un seuil a
que cette probabilité de fausse alarme pfa ne doit pas dépasser et on en déduit le seuil s utilisé dans la décision cas où r(x) (rapport des densités de probabilités) est une fonction croissante puis décroissante le domaine D se réduit à un segment borne inférieure xmin borne supérieure xmax dans l’intervalle [xmin, xmax] : r(x) > s une fois a fixé maximiser la probabilité de décision correcte
 (rapport des densités de probabilités) est une fonction croissante puis décroissante. le domaine D se réduit à un segment. borne inférieure xmin. borne supérieure xmax. dans l’intervalle [xmin, xmax] : r(x) > s. une fois a fixé maximiser la probabilité de décision correcte.")
30
comment ajuster s et par conséquent les bornes xmin et xmax
pour maximiser la probabilité de décision correcte, tout en assurant que la probabilité de fausse alarme ne dépasse pas le seuil a. illustration sur un exemple (lois gaussiennes) si s est fixé : calculer les valeurs xmin et xmax entre lesquelles on décidera d=1 Le dépassement du seuil par le rapport des deux lois :
 si s est fixé : calculer les valeurs xmin et xmax. entre lesquelles on décidera d=1. Le dépassement du seuil par le rapport des deux lois :")
31
soit, en logarithmes : en fonction des puissances de x Les deux valeurs du dépassement du seuil sont racines d’une équation du deuxième degré

32
pour tous les seuils s calculer xmin et xmax - en déduire la proba de fausse alarme - trouver la valeur de s pour laquelle cette pfa atteint la borne qu’on s’est fixé (calcul complémentaire pdc)
")
33
Valeur des limites xmin et xmax du domaine de décision d =1, en fonction du seuil s
probabilité de fausse alarme et probabilité de détection correcte en fonction du seuil s. Si la probabilité de fausse alarme est de 0.1, on choisira un seuil de décision à 4.5, ce qui correspondra aux bornes xmin = et xmax = 1.259 et une probabilité de décision correcte de 0.709

34
Dans le cas multidimensionnel Séparatrices entre les Nuages de points
longueur L Dans le cas multidimensionnel Séparatrices entre les Nuages de points (souvent, mais pas nécessairement Des droites ou des plans) R largeur gaussiennes dans un espace de dimension élevée distance de mahalanobis
 R. largeur. gaussiennes dans un espace de dimension élevée. distance de mahalanobis.")
36
essayer de quantifier les décisions correctes (hypothèses 1 et 2 les erreurs (1 ou lieu de 2 ou 2 au lieu de 1) à partir des probabilités d’erreur et les conséquences de ces fausses décisions (par exemple risque de faux diagnostic médical) règle de probas à ne pas oublier : ‘‘ la loi des grands nombres ne s’applique pas aux petits ! ’’
 règle de probas à ne pas oublier : ‘‘ la loi des grands nombres ne s’applique pas aux petits ! ’’")
37
analyse en composantes
principales réduire le nombre de composantes d’un vecteur en essayant de garder l’information la plus pertinente pour ne pas détériorer la discrimination entre classes

38
(vecteurs propres de la
matrice de covariance)
")
39
apprentissage Trouver les paramètres des lois de probabilités des classes ou les séparatrices de ces classes A. Si un « superviseur » connaît les classes d’échantillons test On déduit de ces échantillons les moyennes et les variances caractérisant les différentes classes ; voir les enseignements sur les estimations de paramètres B. génération automatique de la description des classe envisageable si les classes sont assez bien séparées (voir la présentation sur les champs de Markov) à appliquer avec précaution ; éviter de traiter des vecteurs de grande dimension
 à appliquer avec précaution ; éviter de traiter des vecteurs de grande dimension.")
40
d (x,y, ci) première classification par les k-means
chaque échantillon (x,y) a une valeur f (x,y) initialisation affecter un numéro de classe i à chaque échantillon au hasard boucle calculer la moyenne sur les valeurs des échantillons (centre ci) de chacune des classes pour chaque échantillon, affecter maintenant le numéro de la classe dont le centre ci est le plus proche de cet échantillon ; test d’arrêt réitérer ce processus jusqu’à stabilisation la distance de chaque échantillon à chacun des centres de classe ci est calculée d (x,y, ci)
 a une valeur f (x,y) initialisation. affecter un numéro de classe i à chaque échantillon au hasard. boucle. calculer la moyenne sur les valeurs des échantillons. (centre ci) de chacune des classes. pour chaque échantillon, affecter maintenant. le numéro de la classe dont le centre ci. est le plus proche de cet échantillon ; test d’arrêt. réitérer ce processus jusqu’à stabilisation. la distance de chaque échantillon à chacun des centres de classe ci est calculée. d (x,y, ci)")
41
convergence non garantie !

42
méthodologie générale de l’apprentissage ’’expectation maximization’’

43
nombre de gaussienne K fixé a priori on recherche un maximum local
calcul itératif : Catherine Aaron Université Paris I

45
Introduction aux \Support Vector Machines" (SVM)

46
Support Vector Machines" (SVM)
1. transformation non linéaire des données pour trouver une séparation linéaire des données d’apprentissage dans un nouvel espace 2. chercher un hyperplan dont la distance minimale aux exemples d’apprentissage est maximale H. Mohamadally B. Fomani, U. Versailles St Quentin

47
SYNTHESE

48
B. Approche structurelle
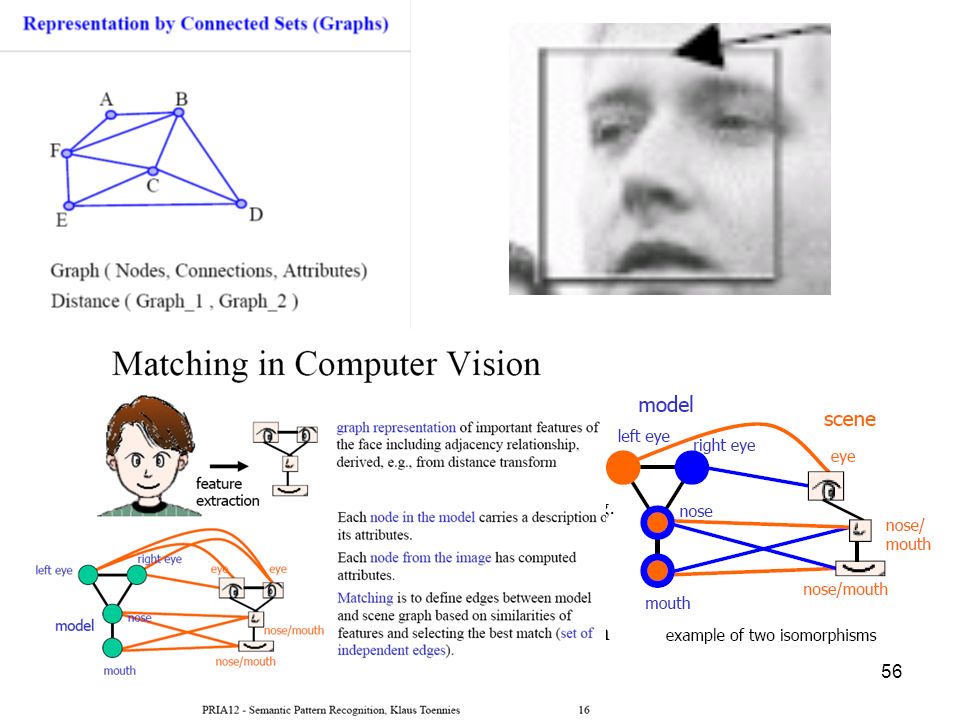
Un objet complexe est décrit comme un mot composé de lettres d’un alphabet prédéfini et des relations de position entre ces lettres Mais ... lettres manquantes, relations de position erronées ... Distances entre graphes rechercher dans la base des graphes, celui qui est le plus proche du graphe déduit des données analysées Schalkoff, Pattern Recognition: Statistical, Structural and Neural Approaches, 1992

49
http://wwwisg. cs. uni-magdeburg

50
Sous le bloc interne, quatre traits qui forment la clef n° 61 (coeur)
A gauche, et se prolongeant en dessous, la clef n°162 (marcher vite) sous sa forme simplifiée (trois ou quatre traits, suivant comment on le dessine). Le bloc interne qu'il isole est une composition verticale. Sous le bloc interne, quatre traits qui forment la clef n° 61 (coeur) Au dessus de ce même bloc, la clef 116 (trou), cinq traits. Le bloc interne est une composition horizontale. A gauche, une clef de quatre traits qui est soit la clef n°74 (lune), soit plus probablement la clef n° 130 (chair). A droite, une clef de deux traits, la clef n° 18 (couteau), qui en position latérale se trace simplement sous forme de deux traits verticaux. Enfin, le bloc interne est une composition verticale en triptyque, où un caractère est encadré par deux exemplaires d'un autre. Au centre, une autre superposition verticale de la clef n° 149 (mot), sept traits, et de la clef n° 187 (cheval) de neuf traits. Cette combinaison ne figure pas dans les dictionnaires courants. De part et d'autre, une superposition verticale de la clef n° 52 (petit), de trois traits, et de la clef n° 168 (long) de huit traits. Cette combinaison ne figure pas non plus dans les dictionnaires courants.
 sous sa forme simplifiée (trois ou quatre traits, suivant comment on le dessine). Le bloc interne qu il isole est une composition verticale. Sous le bloc interne, quatre traits qui forment la clef n° 61 (coeur) Au dessus de ce même bloc, la clef 116 (trou), cinq traits. Le bloc interne est une composition horizontale. A gauche, une clef de quatre traits qui est soit la clef n°74 (lune), soit plus probablement la clef n° 130 (chair). A droite, une clef de deux traits, la clef n° 18 (couteau), qui en position latérale se trace simplement sous forme de deux traits verticaux. Enfin, le bloc interne est une composition verticale en triptyque, où un caractère est encadré par deux exemplaires d un autre. Au centre, une autre superposition verticale de la clef n° 149 (mot), sept traits, et de la clef n° 187 (cheval) de neuf traits. Cette combinaison ne figure pas dans les dictionnaires courants. De part et d autre, une superposition verticale de la clef n° 52 (petit), de trois traits, et de la clef n° 168 (long) de huit traits. Cette combinaison ne figure pas non plus dans les dictionnaires courants.")
51
la reconnaissance d’objets complexes
nécessité d’une représentation structurée élément simple p ex morceau de contour regroupement regroupement objet complexe élément simple p ex morceau de contour regroupement relations entre éléments regroupés regroupement progression dans la reconnaissance il faut pouvoir remettre en cause une décision qui a été prise antérieurement (processus itératif) nécessité de prendre en compte les erreurs de prétraitement
 nécessité de prendre en compte les erreurs de prétraitement.")
58
Abdenaim EL YACOUBI (la poste nantes)
exemple de reconnaissance d’écriture manuscrite contours haut et bas segmentation reconnaissance des « segments » dans une base de segments mémorisés et de leurs enchaînements (modèles de markov) Abdenaim EL YACOUBI (la poste nantes) ftp://ftp.irisa.fr/local/IMADOC/lorette/elyacoubi/MOUNIM.PPT
 Abdenaim EL YACOUBI (la poste nantes) ftp://ftp.irisa.fr/local/IMADOC/lorette/elyacoubi/MOUNIM.PPT.")
59
http://www. cs. bilkent. edu
Schalkoff, Pattern Recognition: Statistical, Structural and Neural Approaches, 1992

60
recognition and classification are done using:
I Parsing (analyse syntaxique, compilation) (for formal grammars), I Relational graph matching (for relational descriptions).
 (for formal grammars), I Relational graph matching (for relational descriptions).")
61
String matching: Given string x and text, determine whether
x is a factor of text, and if so, where it appears. I String edit distance: Given two strings x and y, compute the minimum number of basic operations — character insertions, deletions and exchanges — needed to transform x into y. I String matching with errors: Given string x and text, find the locations in text where the “distance” of x to any factor of text is minimal. I String matching with the “don’t care” symbol: This is the same as basic string matching but the special “don’t care” symbol can match any other symbol.

62
I Substitutions: A character in x is replaced by the corresponding character in y.
I Insertions: A character in y is inserted into x, thereby increasing the length of x by one character. I Deletions: A character in x is deleted, thereby decreasing the length of x by one character.

63
Techniques based on tree search
The basic idea A partial match (initially empty) is iteratively expanded by adding to it new pairs of matched nodes. The pair is chosen using some necessary conditions, usually also some heuristic condition to prune unfruitful search paths. Eventually, either the algorithm finds a complete matching, or no further vertex pairs may be added (backtracking) For PR the algorithm may consider the attributes of nodes and edges in constraining the desired matching. In meinem Vortrag werde ich zunächst.... based on tree search 63
 is iteratively expanded by adding to it new pairs of matched nodes. The pair is chosen using some necessary conditions, usually also some heuristic condition to prune unfruitful search paths. Eventually, either the algorithm finds a complete matching, or no further vertex pairs may be added (backtracking) For PR the algorithm may consider the attributes of nodes and edges in constraining the desired matching. In meinem Vortrag werde ich zunächst based on tree search. 63.")
65
Reconnaissance de séquences fondée sur les Modèles de Markov Cachés
Hidden Markov Models Formulation en reconnaissance de séquence 2.1 Reconnaissance (Viterbi) 2.2 Probabilité d’une séquence 2.3 Apprentissage
 2.2 Probabilité d’une séquence. 2.3 Apprentissage.")
66
2. Automates utilisés dans les modèles de Markov cachés
mesures n’ n états m’ m (Probabilités) transition Séquence d’états : Séquence de mesures : probabilité de transition de l’état m’ à l’état m probabilité de mesurer ‘n’ quand l’automate est dans l’état m probabilité que l’état initial soit m
 transition. Séquence d’états : Séquence de mesures : probabilité de transition de l’état m’ à l’état m. probabilité de mesurer ‘n’ quand l’automate est. dans l’état m. probabilité que l’état initial soit m.")
67
Modèles de Markov Cachés (HMM Hidden Markov Models)
par exemple pour mesurer la ressemblance entre deux contours de lettres On écarte les portions de contour qui ne sont pas des côtés parallèles d’un segment modèle de Markov Un état = Une mesure tenir compte du fait qu’un état peut produire plusieurs mesures possibles

68
Les trois problèmes : Séquence d’états : Séquence de mesures :
1. Reconnaissance : Y donné quelle est la S la plus probable ? 2. Quelle est la probabilité d’observer Y avec l ’automate (a,b,d) ? 3. Apprentissage : comment calculer a(m,m’), b(m,n) et d(m)
 3. Apprentissage : comment calculer a(m,m’), b(m,n) et d(m)")
69
SHAPE MATCHING BASED ON GRAPH ALIGNMENT USING HIDDEN MARKOV MODELS
Xiaoning Qian and Byung-Jun Yoo University of South Florida

70
L'algorithme de Needleman et Wunsch (programmation dynamique)
Laurent Bloch, 2006 savoir si deux mots se ressemblent, quel est leur degré de ressemblance, ou de trouver, dans un ensemble de mots, celui qui ressemble le plus à un mot-cible un score de ressemblance un alignement des deux chaînes (qui n’ont pas forcément la même longueur) selon la configuration qui procure le meilleur score ; La programmation dynamique résout des problèmes en combinant des solutions de sous-problèmes. (Thomas Cormen, Charles Leiserson, Ronald Rivest et Clifford Stein, Introduction à l’algorithmique)
 selon la configuration. qui procure le meilleur score ; La programmation dynamique résout des problèmes. en combinant des solutions de sous-problèmes. (Thomas Cormen, Charles Leiserson, Ronald Rivest. et Clifford Stein, Introduction à l’algorithmique)")
71
séquence n° 1 : G A A T T C A G T T A séquence n° 2 : G G A T C G A
1. Remplir la matrice séquence n° 1 : G A A T T C A G T T A séquence n° 2 : G G A T C G A la « prime de score » pour la comparaison du résidu de rang i de la première séquence avec le résidu de rang j de le seconde séquence sera Si,j = 1 si les deux résidus sont identiques, sinon Si,j = 0 (score de discordance) ; w = 0 (pénalité de gap). Initialisation 2.Déterminer l'alignement optimal
 ; w = 0 (pénalité de gap). Initialisation. 2.Déterminer l alignement optimal.")
72
a titre d’illustration :
un exemple simple dans le cas de l’écriture manuscrite - extraction des contours - quantification en fonction de la pente - description sous forme d’un graphe comparaison avec un graphe mémorisé (éventuellement prise en compte de la distance entre graphes)
")
73
QUANTIFICATION DES PENTES DES CONTOURS
4 5 3 8 ANGLES 6 2 1 1 7 0.67 TANGENTES 0.41 0.2 -0.1 QUANTIFICATION DES PENTES DES CONTOURS

74
QUANTIFICATION DES PENTES DES CONTOURS
16 ANGLES 1 0.82 0.67 TANGENTES 0.53 0.41 0.3 0.2 0.1 -0.1 QUANTIFICATION DES PENTES DES CONTOURS

75
A. Mesure et quantification des pentes des contours
par exemple huit pentes possibles (horizontale, verticale, oblique gauche et oblique droite) B. Recherche de tronçons aux côtés parallèles l’un en face de l’autre (typiquement analyse du type morphologie mathématique) puis élimination dans la description des autres éléments de contours
 B. Recherche de tronçons aux côtés parallèles l’un en face de l’autre. (typiquement analyse du type morphologie mathématique) puis élimination dans la description des autres éléments de contours.")
76
Recherche de la forme dans une base en mémoire :
g b a b d d a 7 g 3 a b b a g d a b b a 3 5 4 g d d g g b b a d a a b d g b 3 5 a b d g g a 6 b 3 g d g3b g3b a5d a5d d3a d0a b5g d g d g d a d3a b5g g0b a3d a0d g6b g 4b g 3b g 0b a7d b3g b0g d6a d4a d3a d0a b7g plusieurs contours un seul contour Recherche de la forme dans une base en mémoire : on peut avoir des milliers voire des millions de formes type

77
Si on ne trouve pas la séquence de la forme en mémoire
On cherche si il y a une forme proche, La méthode la plus ‘reconnue’ est celle des ‘Modèles de Markov Cachées’ Coopération entre différents niveaux Module de reconnaissance 5 ‘A’ ! 1 ? Forme inconnue 4 2 Morphologie mathématique : Ici l’extension de région Peut fermer la boucle et permettre la reconnaissance 3

78
Ecriture manuscrite cursive
Découpe en formes élémentaires plus simples Par exemple en cassant des segments horizontaux Ou obliques situés sur le contour extérieur En supposant que le mot existe dans le dictionnaire : Trouver le mot du dictionnaire dont la séquence ressemble le plus à celle qui a été analysée la plupart du temps, elle ne sera pas telle quelle dans le dictionnaire ; là encore les modèles de markov cachés Sont un outil efficace

79
reconnaissance de visages
approche statistique (eigenfaces) approche structurelle (relations entre éléments caractéristiques)
 approche structurelle. (relations entre éléments caractéristiques)")
80
point de départ : détection des éléments de contour
F 1. recherche par corrélation d’éléments simples : en « balayant » l’image, est ce que le médaillon analysé ressemble à l’image simple à laquelle on le compare (sourcil, œil, nez, bouche) (on peut avoir plusieurs formes pour ces images simples) B D A C F E au dessus 2. Vérification de la cohérence au dessus B D au dessus à gauche au dessus à droite A 3. Retour à l’image initiale pour essayer d’affiner l’analyse en dessous C
 (on peut avoir plusieurs formes pour ces images. simples) B. D. A. C. F. E. au dessus. 2. Vérification de la cohérence. au dessus. B. D. au dessus à gauche. au dessus à droite. A. 3. Retour à l’image initiale. pour essayer d’affiner l’analyse. en dessous. C.")
81
détection de visage images grossières avec peu de détails
apprendre à partir de visages types comment caractériser la notion de « visage » comment rechercher dans l’image les domaines qui présentent ces caractéristiques et les différencier de ceux qui ne les présentent pas ? faut il décrire le visage ? ou bien en faire une présentation paramétrique approximative (avec peu de paramètres) (approche statistique) représentation paramétrique dans un espace de dimension réduite
 (approche statistique) représentation paramétrique dans un espace de dimension réduite.")
82
détection de visage images grossières peu de détails apprendre à partir de visages types un classifieur va apprendre ce qu’est un visage (Neural Networks, Support Vector Machine, Principal Component Analysis - Eigenfaces...). représentation dans un espace de dimension réduite
. représentation dans un espace de dimension réduite.")
83
approche statistique de la reconnaissance de visages
analyse en composantes principales : représenter les visages sur une base de vecteur orthogonaux en essayant de prendre en compte les caractéristiques les plus significatives des visages

84
analyse en composantes principales de visages : eigenfaces
une image = un vecteur de paramètres (opérations préalables : cadrer les images et soustraire la moyenne de chaque image)
")
85
matrice rectangulaire W
RECHERCHE DES VECTEURS PROPRES e1, ...,eM (orthogonaux) DE LA MATRICE (carrée MxM) WT.W N image 1 image 2 image 3 image M les vecteurs propres associés aux valeurs propres les plus grandes contiennent l’information la plus significative de l’ensemble des images ayant servi à les construire (composantes de plus grand écart type)
 DE LA MATRICE (carrée MxM) WT.W. N. image 1. image 2. image 3. image M. les vecteurs propres associés aux valeurs propres les plus grandes contiennent. l’information la plus significative de l’ensemble des images ayant servi à les construire. (composantes de plus grand écart type)")
86
une nouvelle image est projetée sur cette base
elle est caractérisée par le vecteur de paramètres (les images de la base d’apprentissage peuvent être caractérisées de la même manière par une projection sur cette base : ) les images et sont ressemblantes si la distance est petite
 les images et sont ressemblantes. si la distance est petite.")
87
vecteurs propres associés aux valeurs propres les plus grandes de la matrice de covariance des « vecteurs » représentant les images représentation d’une image dans cette base les composantes suivant les vecteurs propres associés aux valeurs propres plus petites sont moins informatives et sont négligées la distance entre deux images qui se ressemblent est « petite »

88
(calcul de distance entre points dans l’espace de dimension réduite M)
AT&T Laboratories,Cambridge at Original training images Eigenface - The first eigenface account for the maximal variation of the training vectors,and the second one for the second Reconstructed images of training images- they are almost same as their original images reconnaissance représentation sur la base (calcul de distance entre points dans l’espace de dimension réduite M)
")
89
base de données visages inconnus de la base limitations : fond, éclairage, cadrage, utilité d’un prétraitement (filtrage passe haut pour mettre en évidence les contours, normalisation de l’histogramme, recentrage de l’image, etc. ...°

90
Résultats pour la détection de visages
Voir utilisation des fonctions de Haar

92
prétraitement utile filtrage passe haut (mise en évidence des contours) prétraitement utile filtrage passe bas (caractérisation du « type visage »)
")
93
mais il peut y avoir des erreurs !
the face on mars ...

94
Conclusion Tout ça marche assez bien quand le problème n’est pas trop difficile Mais les algorithmes tombent facilement dans les pièges les plus simples On est très loin d’atteindre les performances d’un animal Il y a encore beaucoup à comprendre sur le fonctionnement cérébral Ce qu’on sait sur les neurones et le cerveau

95
stanislas dehaene

Présentations similaires







 Combiner des apprenants: le boosting.>")


>")

>")





>")




