Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Vers des dossiers patients «interopérables» Enjeux et solutions
C.Daniel INSERM, UMR_S 872, Eq. 20, Université Paris Descartes, France AP-HP, Paris, ASIP Santé Recent advances in standards for collaborative pathology Context. The concept of Collaborative Digital Anatomic Pathology refers to the use of information technology that supports the creation, sharing or exchange of information, including data and images, in order to support technicians and pathologists within a complex workflow from specimen reception to Anatomic Pathology report transmission. In the context of Collaborative Digital Anatomic Pathology, Whole Slide Images offer promising new perspectives that can only be fully realized using medical informatics standards and following the recommendations of Integrating the Healthcare Enterprise (IHE) initiative for Anatomic Pathology. Objective. To define the best use of medical informatics standards for Collaborative Digital Anatomic Pathology Methods. Working groups from multiple standards organizations modeled end-users’ information needs and defined standard-based informatics transactions to integrate Anatomic Pathology information into the electronic healthcare enterprise. Results. The integration profile “Anatomic Pathology Workflow (APW) addresses basic image acquisition and reporting processes in hospitals. The objective of the content profile “Anatomic Pathology Structured Report” (APSR) based on the ISO standard HL7 Clinical Document Architecture (CDA) is to provide an international standard solution for “cross enterprise” exchange or sharing of structured anatomic pathology reports. It addresses the issue of binding textual observations to digital images or regions of interest. During the next cycle, IHE anatomic pathology will address advice request using whole slide images in order to standardize telepathology.
 initiative for Anatomic Pathology. Objective. To define the best use of medical informatics standards for Collaborative Digital Anatomic Pathology. Methods. Working groups from multiple standards organizations modeled end-users’ information needs and defined standard-based informatics transactions to integrate Anatomic Pathology information into the electronic healthcare enterprise. Results. The integration profile Anatomic Pathology Workflow (APW) addresses basic image acquisition and reporting processes in hospitals. The objective of the content profile Anatomic Pathology Structured Report (APSR) based on the ISO standard HL7 Clinical Document Architecture (CDA) is to provide an international standard solution for cross enterprise exchange or sharing of structured anatomic pathology reports. It addresses the issue of binding textual observations to digital images or regions of interest. During the next cycle, IHE anatomic pathology will address advice request using whole slide images in order to standardize telepathology.")
2
Plan Contexte Interopérabilité sémantique
Systèmes d’Information de Santé développés en silo, non partagés ,non “intéropérables” Interopérabilité sémantique Qu’est ce que c’est Pourquoi faire? Comment ? Rolés des organismes de standardisation, d’IHE, de l’ASIP Santé Un example : production du réferentiel “CR d’anatomie pathologique” 5 règles d’or de la production de réferentiels d’interopérabilité sémantique Interopérabilité sémantique & medecine translationnelle

3
Contexte Systèmes d’Information de Santé
Gestion de données de santé multimodales (textes, signaux, images, etc.) Coordination des soins Recherche biologique Recherche clinique, épidémiologique ou de veille sanitaire Un patient , combien de dossiers? Les Systèmes d’Information de Santé gèrent des données de santé de la recherche biologique gèrent des données multimodales (textes, signaux, images, etc.) relatives aux molécules, cellules et tissus. Les systèmes d’information cliniques gèrent des données multimodales relatives aux patients et aux tissus (échantillons biologiques) qui sont des sources de données importantes de nature à alimenter les systèmes d’information de la recherche clinique et épidémiologiques gérant des données agrégées relatives à des populations. Quelque soit le domaine d’activité de santé (recherche en biologie, recherche clinique, pratique clinique, épidémiologie ou santé publique), l’informatique biomédicale a pour objectif constant l’élaboration d’un ensemble de méthodes et d’outils de gestion des données, d’informations et de connaissances exploitées par les professionnels de santé
 Coordination des soins. Recherche biologique. Recherche clinique, épidémiologique ou de veille sanitaire. Un patient , combien de dossiers Les Systèmes d’Information de Santé gèrent des données de santé. de la recherche biologique gèrent des données multimodales (textes, signaux, images, etc.) relatives aux molécules, cellules et tissus. Les systèmes d’information cliniques gèrent des données multimodales relatives aux patients et aux tissus (échantillons biologiques) qui sont des sources de données importantes de nature à alimenter les systèmes d’information de la recherche clinique et épidémiologiques gérant des données agrégées relatives à des populations. Quelque soit le domaine d’activité de santé (recherche en biologie, recherche clinique, pratique clinique, épidémiologie ou santé publique), l’informatique biomédicale a pour objectif constant l’élaboration d’un ensemble de méthodes et d’outils de gestion des données, d’informations et de connaissances exploitées par les professionnels de santé.")
4
Contexte: Informatique clinique
Systèmes d’Information gérant les données de santé individuelles relatives à des patients ou des tissus (échantillons biologiques) Dossier Patient Informatisé, système de gestion de plateaux techniques, SIH, Dossier Patient de réseau de soins, Dossier Médical Personnel, etc Informatique clinique Clinicien Informaticien biomédical
 Dossier Patient Informatisé, système de gestion de plateaux techniques, SIH, Dossier Patient de réseau de soins, Dossier Médical Personnel, etc. Informatique. clinique. Clinicien. Informaticien biomédical.")
5
Contexte: Bio-informatique
Systèmes d’Information gérant des données relatives à des gènes, molécules, cellules et tissus Génomique, protéomique, etc Biologiste Bio-informatique Clinicien Informatique clinique Informaticien biomédical

6
Contexte: Informatique de la recherche clinique et épidémiologique
Système d’Information gérant des données de santé individuelles anonymisées relatives à des patients & données agrégées relatives à des populations Biologiste Bio-informatique Informatique clinique Clinicien Informaticien biomédical Informatique de la recherche clinique, épidémiologique et santé publique Investigateur/ épidémiologiste Chercheur en santé publique

7
Contexte: des Systèmes d’Information de Santé développés en “silo”
Méthodes et outils COMMUNS de gestion des données, d’informations et de connaissances exploitées par les professionnels de santé … Traitement des données et des signaux Intégration de données hétérogènes distribuées Recherche d’information dans des bases de données et d’images Fouille de données et de texte etc … MAIS développement « EN SILO » de Systèmes d’Information non « intéropérables » Quelque soit le domaine d’activité de santé (recherche en biologie, recherche clinique, pratique clinique, épidémiologie ou santé publique), l’informatique biomédicale a pour objectif constant l’élaboration d’un ensemble de méthodes et d’outils de gestion des données, d’informations et de connaissances exploitées par les professionnels de santé L’informatique biomédicale couvre donc tout le champ de la médecine translationnelle puisqu’elle apporte aux professionnels de santé des solutions permettant de gérer et intégrer des données complexes, multimodales, hétérogènes afin de générer de nouvelles connaissances (innovation), d’en vérifier l’impact en pratique clinique (validation) et de les utiliser efficacement dans la définition et l’adoption de bonnes pratiques cliniques et les choix de politiques de santé (adoption). Les verrous restant à lever en ce qui concerne la pratique de la médecine translationnelle sont bien sur liés à la complexité et à l’hétérogénéité des processus de pratique clinique et de recherche biomédicale mais surtout à leur caractère encore souvent très cloisonnés et le fait qu’ils soient supportés par une prolifération d’applications implémentées sur des plateformes différentes et selon des standards différents (figure 1).
, l’informatique biomédicale a pour objectif constant l’élaboration d’un ensemble de méthodes et d’outils de gestion des données, d’informations et de connaissances exploitées par les professionnels de santé. L’informatique biomédicale couvre donc tout le champ de la médecine translationnelle puisqu’elle apporte aux professionnels de santé des solutions permettant de gérer et intégrer des données complexes, multimodales, hétérogènes afin de générer de nouvelles connaissances (innovation), d’en vérifier l’impact en pratique clinique (validation) et de les utiliser efficacement dans la définition et l’adoption de bonnes pratiques cliniques et les choix de politiques de santé (adoption). Les verrous restant à lever en ce qui concerne la pratique de la médecine translationnelle sont bien sur liés à la complexité et à l’hétérogénéité des processus de pratique clinique et de recherche biomédicale mais surtout à leur caractère encore souvent très cloisonnés et le fait qu’ils soient supportés par une prolifération d’applications implémentées sur des plateformes différentes et selon des standards différents (figure 1).")
8
Informaticien biomédical
INNOVATION “Bench” (molécules & cellules, tissus) Biologiste Verrou 1 “Du génotype vers le phénotype” Bio-informatique “Bedside”(prélèvements, patients (données cliniques, biologiques et d’imagerie)) “Bedside”(patients ) Informatique clinique Clinicien Informaticien biomédical Informatique de la recherche clinique, épidémiologique et santé publique Verrou 2 Nécessité d’une “Info-structure” (plateforme d’interopérabilité sémantique) pour lever les verrous de la médecine translationnelle Pour une médecine basée sur des faits prouvés Intégrant plus rapidement les connaissances récentes validées issues de la recherche biomédicale Pour une médecine personnalisée Tenant compte des caractéristiques génotypiques et phénotypiques individuelles du patient L’informatique biomédicale couvre donc tout le champ de la médecine translationnelle puisqu’elle apporte aux professionnels de santé des solutions permettant de gérer et intégrer des données complexes, multimodales, hétérogènes afin de générer de nouvelles connaissances (innovation), d’en vérifier l’impact en pratique clinique (validation) et de les utiliser efficacement dans la définition et l’adoption de bonnes pratiques cliniques et les choix de politiques de santé (adoption). Les verrous restant à lever en ce qui concerne la pratique de la médecine translationnelle sont bien sur liés à la complexité et à l’hétérogénéité des processus de pratique clinique et de recherche biomédicale mais surtout à leur caractère encore souvent très cloisonnés et le fait qu’ils soient supportés par une prolifération d’applications implémentées sur des plateformes différentes et selon des standards différents (figure 1). Investigateur/ épidémiologiste “Community” (populations) Chercheur en santé publique “Policy” (populations) Verrou 3 VALIDATION ADOPTION Continuum de la médecine translationnelle (d’après Sarkar 2010)
 Biologiste. Verrou 1. Du génotype vers le phénotype Bio-informatique. Bedside (prélèvements, patients (données cliniques, biologiques et d’imagerie)) Bedside (patients ) Informatique. clinique. Clinicien. Informaticien biomédical. Informatique. de la recherche clinique, épidémiologique et santé publique. Verrou 2. Nécessité d’une Info-structure (plateforme d’interopérabilité sémantique) pour lever les verrous de la médecine translationnelle. Pour une médecine basée sur des faits prouvés. Intégrant plus rapidement les connaissances récentes validées issues de la recherche biomédicale. Pour une médecine personnalisée. Tenant compte des caractéristiques génotypiques et phénotypiques individuelles du patient. L’informatique biomédicale couvre donc tout le champ de la médecine translationnelle puisqu’elle apporte aux professionnels de santé des solutions permettant de gérer et intégrer des données complexes, multimodales, hétérogènes afin de générer de nouvelles connaissances (innovation), d’en vérifier l’impact en pratique clinique (validation) et de les utiliser efficacement dans la définition et l’adoption de bonnes pratiques cliniques et les choix de politiques de santé (adoption). Les verrous restant à lever en ce qui concerne la pratique de la médecine translationnelle sont bien sur liés à la complexité et à l’hétérogénéité des processus de pratique clinique et de recherche biomédicale mais surtout à leur caractère encore souvent très cloisonnés et le fait qu’ils soient supportés par une prolifération d’applications implémentées sur des plateformes différentes et selon des standards différents (figure 1). Investigateur/ épidémiologiste. Community (populations) Chercheur en santé publique. Policy (populations) Verrou 3. VALIDATION. ADOPTION. Continuum de la médecine translationnelle (d’après Sarkar 2010)")
9
Interopérabilité sémantique Qu’est ce que c’est?

10
Interopérabilité des Systèmes d’information de Santé
Capacité de ces systèmes à offrir aux acteurs de santé (professionnels de santé, patients, citoyens, autorités sanitaires, structures de recherche ou de formation, etc) des solutions d’échange ou de partage de données de santé L’interopérabilité des Systèmes d’Information de Santé (SIS) est la capacité de ces systèmes à offrir aux acteurs de santé (professionnels de santé, patients, citoyens, autorités sanitaires, structures de recherche ou de formation, etc) des solutions d’échange ou de partage de données dans le respect des exigences de confidentialité et de sécurité
 des solutions d’échange ou de partage de données de santé. L’interopérabilité des Systèmes d’Information de Santé (SIS) est la capacité de ces systèmes à offrir aux acteurs de santé (professionnels de santé, patients, citoyens, autorités sanitaires, structures de recherche ou de formation, etc) des solutions d’échange ou de partage de données dans le respect des exigences de confidentialité et de sécurité.")
11
3 niveaux d’interopérabilité
Absence d’interopérabilité Interopérabilité technique et syntaxique Accès à des données de santé dématérialisées, interprétables par l’humain e.g un compte rendu d’hospitalisation textuel Dans son rapport « Semantic Interoperability for Better Health and Safer Healthcare. Research and Deployment RoadMap for Europe - Semantic Health Report » de janvier 2009, la commission européenne définit quatre niveaux d’interopérabilité: absence d’interopérabilité ; interopérabilité technique et syntaxique (accès à des données de santé dématérialisées, en texte libre, interprétables par l’humain e.g un compte rendu d’hospitalisation textuel) ; interopérabilité sémantique partielle (accès à des données de santé dématérialisées en partie codées en utilisant un système de codage interprétable par la machine e.g diagnostics codés en CIM-10, actes codés en CCAM, résultats de biologie codés en LOINC, diagnostics anatomo-pathologiques codés en ADICAP, etc) et interopérabilité sémantique totale (accès à des données de santé dématérialisées codées en totalité en utilisant un système de codage interprétable par la machine) [EuropeanCommunity09]. Cette définition est pratique pour parler de dossiers interopérables totalement ou pas. Mais le mot « totale » porte sur toutes les données que l’on peut interpréter et non sur l’interopérabilité proprement dite. Je veux dire que toutes les données d’un dossier peuvent être codées avec un même système de codage et pour autant poser des question d’interopérabilité par exemple parce que les données sont codées au fil du temps et que le référentiel a évolué dans le temps. A la limite : si les données peuvent être codées avec un seul système et si elles le sont de manière non ambiguë, la question de l’interopérabilité n’existe pas à proprement parler. L’interopérabilité concerne l’échange entre des systèmes qui a priori n’ont pas forcément exactement le même système de codage et le même référentiel. Dans le cas contraire si les différents systèmes utilisent les mêmes concepts, codées avec les mêmes règles de codage et les mêmes référentiels, la question de l’interopérabilité est résolue. On sait que dans la vie ce n’est pas comme ça que ça se passe et que l’alignement sémantique est une nécessité soit entre référentiels soit pour un même référentiel qui a pu évoluer au fil du temps. Ces alignements ne peuvent avoir lieu que si les référentiels à aligner sont construits de manière cohérente, évoluent de même et sont peu nombreux (d’où l’intérêt des référentiels standards détaillés et maintenus de manière systématique) « Semantic Interoperability for Better Health and Safer Healthcare. Research and Deployment RoadMap for Europe - Semantic Health Report » de janvier 2009
 ; interopérabilité sémantique partielle (accès à des données de santé dématérialisées en partie codées en utilisant un système de codage interprétable par la machine e.g diagnostics codés en CIM-10, actes codés en CCAM, résultats de biologie codés en LOINC, diagnostics anatomo-pathologiques codés en ADICAP, etc) et interopérabilité sémantique totale (accès à des données de santé dématérialisées codées en totalité en utilisant un système de codage interprétable par la machine) [EuropeanCommunity09]. Cette définition est pratique pour parler de dossiers interopérables totalement ou pas. Mais le mot « totale » porte sur toutes les données que l’on peut interpréter et non sur l’interopérabilité proprement dite. Je veux dire que toutes les données d’un dossier peuvent être codées avec un même système de codage et pour autant poser des question d’interopérabilité par exemple parce que les données sont codées au fil du temps et que le référentiel a évolué dans le temps. A la limite : si les données peuvent être codées avec un seul système et si elles le sont de manière non ambiguë, la question de l’interopérabilité n’existe pas à proprement parler. L’interopérabilité concerne l’échange entre des systèmes qui a priori n’ont pas forcément exactement le même système de codage et le même référentiel. Dans le cas contraire si les différents systèmes utilisent les mêmes concepts, codées avec les mêmes règles de codage et les mêmes référentiels, la question de l’interopérabilité est résolue. On sait que dans la vie ce n’est pas comme ça que ça se passe et que l’alignement sémantique est une nécessité soit entre référentiels soit pour un même référentiel qui a pu évoluer au fil du temps. Ces alignements ne peuvent avoir lieu que si les référentiels à aligner sont construits de manière cohérente, évoluent de même et sont peu nombreux (d’où l’intérêt des référentiels standards détaillés et maintenus de manière systématique) « Semantic Interoperability for Better Health and Safer Healthcare. Research and Deployment RoadMap for Europe - Semantic Health Report » de janvier")
12
Une information compréhensible pour l’être humain…
Hépatotoxicité du Doliprane Blb augmentée ALAT augmentées Inférences rapides permettant l’interprétation d’informations multi-sources, multi-format Hépatite cholestatique : oui Peflacine pour une infection urinaire à E.coli résistant aux quinolones Dans son rapport « Semantic Interoperability for Better Health and Safer Healthcare. Research and Deployment RoadMap for Europe - Semantic Health Report » de janvier 2009, la commission européenne définit quatre niveaux d’interopérabilité: absence d’interopérabilité ; interopérabilité technique et syntaxique (accès à des données de santé dématérialisées, en texte libre, interprétables par l’humain e.g un compte rendu d’hospitalisation textuel) ; interopérabilité sémantique partielle (accès à des données de santé dématérialisées en partie codées en utilisant un système de codage interprétable par la machine e.g diagnostics codés en CIM-10, actes codés en CCAM, résultats de biologie codés en LOINC, diagnostics anatomo-pathologiques codés en ADICAP, etc) et interopérabilité sémantique totale (accès à des données de santé dématérialisées codées en totalité en utilisant un système de codage interprétable par la machine) Stent actif sur l’IVA Peflacine E.Coli – Quinolones - R
 ; interopérabilité sémantique partielle (accès à des données de santé dématérialisées en partie codées en utilisant un système de codage interprétable par la machine e.g diagnostics codés en CIM-10, actes codés en CCAM, résultats de biologie codés en LOINC, diagnostics anatomo-pathologiques codés en ADICAP, etc) et interopérabilité sémantique totale (accès à des données de santé dématérialisées codées en totalité en utilisant un système de codage interprétable par la machine) Stent actif sur l’IVA. Peflacine. E.Coli – Quinolones - R.")
13
…et aussi pour la machine
Référentiel d’interopérabilité sémantique (« model of meaning ») Formats hétérogènes (« model of use ») Cette patiente a une hépatite cholestatique 1000 1 101001 Hépatite cholestatique : oui Modèles d’utilisation hétérogènes 1000 1 101001 Structure de données + Vocabulaire (terminologie de référence e.g CIM-10, SNOMED, LOINC, ADICAP, etc) Atteinte hépatique: Hépatite cholestatique
 Formats hétérogènes. (« model of use ») Cette patiente a une hépatite cholestatique Hépatite cholestatique : oui. Modèles d’utilisation hétérogènes Structure de données. + Vocabulaire. (terminologie de référence e.g CIM-10, SNOMED, LOINC, ADICAP, etc) Atteinte hépatique: Hépatite cholestatique.")
14
3 niveaux d’interopérabilité
Interopérabilité sémantique Accès à des données de santé dématérialisées codées en utilisant un système de codage interprétable par la machine e.g diagnostics codés en CIM-10, actes codés en CCAM, résultats de biologie codés en LOINC, diagnostics anatomo-pathologiques codés en ADICAP, etc) Dans son rapport « Semantic Interoperability for Better Health and Safer Healthcare. Research and Deployment RoadMap for Europe - Semantic Health Report » de janvier 2009, la commission européenne définit quatre niveaux d’interopérabilité: absence d’interopérabilité ; interopérabilité technique et syntaxique (accès à des données de santé dématérialisées, en texte libre, interprétables par l’humain e.g un compte rendu d’hospitalisation textuel) ; interopérabilité sémantique partielle (accès à des données de santé dématérialisées en partie codées en utilisant un système de codage interprétable par la machine e.g diagnostics codés en CIM-10, actes codés en CCAM, résultats de biologie codés en LOINC, diagnostics anatomo-pathologiques codés en ADICAP, etc) et interopérabilité sémantique totale (accès à des données de santé dématérialisées codées en totalité en utilisant un système de codage interprétable par la machine) [EuropeanCommunity09]. Cette définition est pratique pour parler de dossiers interopérables totalement ou pas. Mais le mot « totale » porte sur toutes les données que l’on peut interpréter et non sur l’interopérabilité proprement dite. Je veux dire que toutes les données d’un dossier peuvent être codées avec un même système de codage et pour autant poser des question d’interopérabilité par exemple parce que les données sont codées au fil du temps et que le référentiel a évolué dans le temps. A la limite : si les données peuvent être codées avec un seul système et si elles le sont de manière non ambiguë, la question de l’interopérabilité n’existe pas à proprement parler. L’interopérabilité concerne l’échange entre des systèmes qui a priori n’ont pas forcément exactement le même système de codage et le même référentiel. Dans le cas contraire si les différents systèmes utilisent les mêmes concepts, codées avec les mêmes règles de codage et les mêmes référentiels, la question de l’interopérabilité est résolue. On sait que dans la vie ce n’est pas comme ça que ça se passe et que l’alignement sémantique est une nécessité soit entre référentiels soit pour un même référentiel qui a pu évoluer au fil du temps. Ces alignements ne peuvent avoir lieu que si les référentiels à aligner sont construits de manière cohérente, évoluent de même et sont peu nombreux (d’où l’intérêt des référentiels standards détaillés et maintenus de manière systématique) « Semantic Interoperability for Better Health and Safer Healthcare. Research and Deployment RoadMap for Europe - Semantic Health Report » de janvier 2009
 Dans son rapport « Semantic Interoperability for Better Health and Safer Healthcare. Research and Deployment RoadMap for Europe - Semantic Health Report » de janvier 2009, la commission européenne définit quatre niveaux d’interopérabilité: absence d’interopérabilité ; interopérabilité technique et syntaxique (accès à des données de santé dématérialisées, en texte libre, interprétables par l’humain e.g un compte rendu d’hospitalisation textuel) ; interopérabilité sémantique partielle (accès à des données de santé dématérialisées en partie codées en utilisant un système de codage interprétable par la machine e.g diagnostics codés en CIM-10, actes codés en CCAM, résultats de biologie codés en LOINC, diagnostics anatomo-pathologiques codés en ADICAP, etc) et interopérabilité sémantique totale (accès à des données de santé dématérialisées codées en totalité en utilisant un système de codage interprétable par la machine) [EuropeanCommunity09]. Cette définition est pratique pour parler de dossiers interopérables totalement ou pas. Mais le mot « totale » porte sur toutes les données que l’on peut interpréter et non sur l’interopérabilité proprement dite. Je veux dire que toutes les données d’un dossier peuvent être codées avec un même système de codage et pour autant poser des question d’interopérabilité par exemple parce que les données sont codées au fil du temps et que le référentiel a évolué dans le temps. A la limite : si les données peuvent être codées avec un seul système et si elles le sont de manière non ambiguë, la question de l’interopérabilité n’existe pas à proprement parler. L’interopérabilité concerne l’échange entre des systèmes qui a priori n’ont pas forcément exactement le même système de codage et le même référentiel. Dans le cas contraire si les différents systèmes utilisent les mêmes concepts, codées avec les mêmes règles de codage et les mêmes référentiels, la question de l’interopérabilité est résolue. On sait que dans la vie ce n’est pas comme ça que ça se passe et que l’alignement sémantique est une nécessité soit entre référentiels soit pour un même référentiel qui a pu évoluer au fil du temps. Ces alignements ne peuvent avoir lieu que si les référentiels à aligner sont construits de manière cohérente, évoluent de même et sont peu nombreux (d’où l’intérêt des référentiels standards détaillés et maintenus de manière systématique) « Semantic Interoperability for Better Health and Safer Healthcare. Research and Deployment RoadMap for Europe - Semantic Health Report » de janvier")
15
Codage de l’information médicale

16
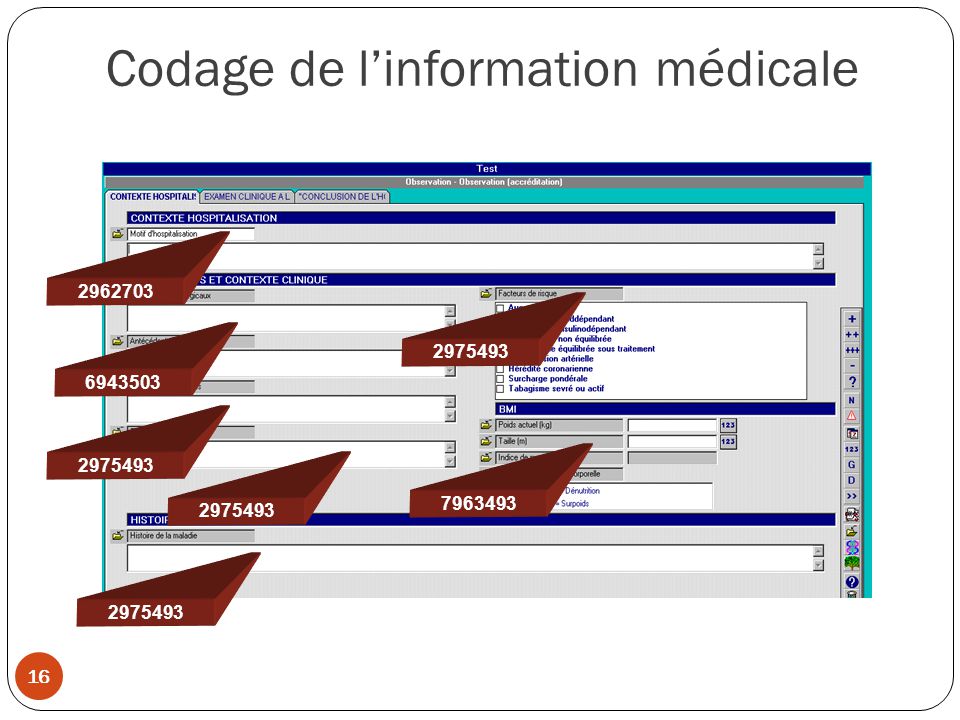
Codage de l’information médicale
17
Codage de l’information médicale Etape 1: Standardisation des variables
Tabac ? oui/non Variable 2 Variable 3 Variable 4 Variable 5 Fumeur / Non fumeur ? QUE CE SOIT L’UTILISATEUR FINAL OU LE PARAMETREUR Variable 6 Nombre de cigarette / jour ? Variable 7 Variable 8

18
Codage de l’information médicale Etape 1: Standardisation des variables
Vous sentez vous fatigué ? Souvent / parfois / rarement /jamais Variable 2 Variable 3 Vous sentez vous fatigué ? Souvent / jamais Variable 4 Variable 5 Variable 6 Variable 7 Variable 8

19
Codage de l’information médicale Etape 1: Standardisation des variables
PAS couché (mmHg)? (min/max) Variable 3 Variable 4 Variable 5 Variable 6 Pression artérielle systolique en position couchée au repos (mmHg) ? (min/max) Variable 7 Variable 8
 (min/max) Variable 3. Variable 4. Variable 5. Variable 6. Pression artérielle systolique en position couchée au repos (mmHg) (min/max) Variable 7. Variable 8.")
20
Codage de l’information médicale Etape 2: Codage des variables et des données (e.g SNOMED
« Automatique » Simple Athérome M atherome Grammaire compositionnelle permettant le codage d’expressions complexe Athérome de l’artère rénale M-52100|atherome| |localisé à|T artère rénale Ovariectomie droite au laser |oophorectomy| |method|= |laser excision – action| |procedure site|= |structure of right ovary| WE NEED+++ Athérome des artères rénales : M athérome + T artère rénale, SAI MORE SPECIFIC TO IT +++ coming from SDE forms Mapping IT to RT is often a tedious manual mapping You have to deal with labels with abreviatioins, local terms, spelling errors (accents) before finding their corresponding concept in the RT e.g AVC stending for accident cerebrovasculaire e.G Aldosterone couchée stends for aldosterone dosage for a lying down patient but aldosterone couché with our tool is mapped to aldosterone as a substance and to diaper (couché lying down without without accent is couché that means diaper) Dosage de l’aldosterone, position en décubitus is correcl=tly mapped to aldosterone mesearement and recumbent body position 20
 before finding their corresponding concept in the RT. e.g AVC stending for accident cerebrovasculaire. e.G Aldosterone couchée stends for aldosterone dosage for a lying down patient but aldosterone couché with our tool is mapped to aldosterone as a substance and to diaper (couché lying down without without accent is couché that means diaper) Dosage de l’aldosterone, position en décubitus is correcl=tly mapped to aldosterone mesearement and recumbent body position. 20.")
21
Codage de l’information médicale Etape 2: Codage des variables et des données
Automatique + manuel Abréviation, termes locaux AVC D accident cérébrovasculaire Connaissance implicite, expressions elliptiques Aldostérone couché F-B2970 aldostérone (substance) A couche (dispositif) Dosage de l’aldostérone, position en décubitus P dosage de l’aldostérone (procédure) F position en décubitus (signe) Information temporelle Accident coronarien père (avant 55 ans) Diagnostic DFM porté <2ans avant inclusion – F-B2970 aldosterone (substance) – A diaper, device (physical object) It is not always as simple as : Athérome des artères rénales : M athérome + T artère rénale, SAI MORE SPECIFIC TO IT +++ coming from SDE forms More precise Mapping IT to RT is often a tedious manual mapping You have to deal with labels with abreviatioins, local terms, spelling errors (accents) before finding their corresponding concept in the RT e.g AVC stending for accident cerebrovasculaire e.G Aldosterone couchée stends for aldosterone dosage for a lying down patient but aldosterone couché with our tool is mapped to aldosterone as a substance and to diaper (couché lying down without without accent is couché that means diaper) Dosage de l’aldosterone, position en décubitus is correcl=tly mapped to aldosterone mesearement and recumbent body position 21
 A couche (dispositif) Dosage de l’aldostérone, position en décubitus. P dosage de l’aldostérone (procédure) F position en décubitus (signe) Information temporelle. Accident coronarien père (avant 55 ans) Diagnostic DFM porté <2ans avant inclusion – F-B2970 aldosterone (substance) – A diaper, device (physical object) It is not always as simple as : Athérome des artères rénales : M athérome + T artère rénale, SAI. MORE SPECIFIC TO IT +++ coming from SDE forms. More precise. Mapping IT to RT is often a tedious manual mapping. You have to deal with labels with abreviatioins, local terms, spelling errors (accents) before finding their corresponding concept in the RT. e.g AVC stending for accident cerebrovasculaire. e.G Aldosterone couchée stends for aldosterone dosage for a lying down patient but aldosterone couché with our tool is mapped to aldosterone as a substance and to diaper (couché lying down without without accent is couché that means diaper) Dosage de l’aldosterone, position en décubitus is correcl=tly mapped to aldosterone mesearement and recumbent body position. 21.")
22
Bibliothèque de variables standardisées codées
Projet SHARE : Shared Health And Clinical Research Electronic Library “SHARE is a global, accessible, electronic library, which through advanced technology, enables precise and standardized data element definitions that can be used within applications and across studies to improve biomedical research and its link with healthcare”. Dès lors que cet effort de codage est réaliser. La tentation est grande de partager, de mettre à disposition ce travail++++ Partager des structures de données codées

23
Bibliothèque de variables standardisées HEGP (Recherche clinique/Soin)
Terminologies à aligner Nb. Termes RC alignés Taux (%) IT-RC/IT-S (n=3.739/8.587) 648 17.3% Arcadia/Visite (n=236/367) 26 15.7% -> 11.0% Arcadia/Visite (SNOMED) 71 30.0% -> 13.1% The semantic interoperability framework provided automatic mapping for 15.7% of the items of the ARCADIA ODM templates (“Arcadia-IT”, n=236) with the items of PatientCare-IT. Automatic pre-population was available for 13.1% of the items of the Arcadia eCRF Thanks to the use of SNOMED v3.5 as a pivot reference terminology the mapping between the two template interface terminologies increased from 11.0 to 13.1%. After expert validation the mapping between Arcadia-IT and PatientCare-IT was of 11%. The automatic mapping between PC-IT and RC-IT if of 17,3% (table 1). 861 forms 8,587 terms or expressions 16 specialties >2,000,000 doc since 2000 16 eCRF 3,739 terms or expressions 367 terms or expression “Visite-IT” 4,345 instanciated eCRF since 2001 derived from seven Arcadia eCRFs templates 236 termes “Arcadia-IT” Negative Positive Study terms 3739 CR-IT/PC-IT Positive/Study terms (%) 648 a/a 17.3 3091 199 37 236 15.7 15 135 b/b 11.1 120 In experimental settings A, after expert validation the mapping between CR-IT terms of the electronic clinical research form (eCRF)(a=Arcadia) and PC-IT terms used for data capture in the hypertension department (a= Visite) is evaluated to 10%. The precision and recall of the algorithm are respectively of 70 and 100%. In experimental settings B, after expert validation the mapping between CR-IT terms of the minimum data elements for cancer registries (b=AP checklists) and PC-IT terms used to capture structured anatomic pathology diagnostic findings for cancer (b=AP reports) is evaluated to xxxx%. The sensitivity and specificity of the algorithm are respectively of xxx and xxxx%. TP TP+FN/study terms FN Precision FP TN Recall 26 26/236 (11%) 1 0.7 11 16 16/135 (11.8%) The automatic mapping between the interface terminologies (a (Arcadia), a (Visite), b (AP checklists) and b (AP reports)) and SNOMED v3.5 are from 25 to 70% (table 3). CR-IT/SNOMED v3.5 PC-IT/SNOMED v3.5 a/SNOMED v3.5 25 190 59 149 87 249 34,9 181 536 b/SNOMED v3.5 33 355 92 68,1 43 In the experimental setting A, after expert validation the mapping between CR-IT terms of the electronic clinical research form (eCRF)(a=Arcadia) and SNOMED v3.5 increases to 27% (precision : 0.73 and recall 0.76). The mapping between PC-IT terms used for data capture in the hypertension department (a= Visite) and SNOMED v3.5 increases to 17% (precision: 0.75 and recall 0.55) (table 4). In experimental settings B, after expert validation the mapping between CR-IT terms of the minimum data elements for cancer registries (b=AP checklists) and SNOMED v3.5 increases to 20% (precision : 0.60 and specificity 0.59). The mapping between PC-IT terms used to capture structured anatomic pathology diagnostic findings for cancer (b=AP reports) and SNOMED v3.5 increases to xxxx% (precision: xxxx and recall xxx)(table4). 20 64 129 0.76 0.73 23 44 154 36 0.55 0.75 8 65 35 0.89 0.70 27 75 109 0.60 72 280 0.59 Thanks to the validated mapping between SNOMED v3.5 and the interface terminologies b (AP checklists) and b (AP reports), the validated mapping between these two interface terminologies is re-calculated and increases from xxx to xxxx% (table 5). Thanks to the validated mapping between SNOMED v3.5 and the interface terminologies a (Arcadia) and a (Visite); the validated mapping between these two interface terminologies is re-calculated and increases from 10 to 13.1% (table 5). TP+FN/study terms (after SNOMED v3.5 mapping) 8 (+23) / 236 23/236 ( 2(+13)/176 13/176 Taux de réutilisation potentielle de données cliniques: 13.1%
 IT-RC/IT-S. (n=3.739/8.587) % Arcadia/Visite. (n=236/367) % -> 11.0% Arcadia/Visite (SNOMED) % -> 13.1% The semantic interoperability framework provided automatic mapping for 15.7% of the items of the ARCADIA ODM templates ( Arcadia-IT , n=236) with the items of PatientCare-IT. Automatic pre-population was available for 13.1% of the items of the Arcadia eCRF. Thanks to the use of SNOMED v3.5 as a pivot reference terminology the mapping between the two template interface terminologies increased from 11.0 to 13.1%. After expert validation the mapping between Arcadia-IT and PatientCare-IT was of 11%. The automatic mapping between PC-IT and RC-IT if of 17,3% (table 1). 861 forms. 8,587 terms or expressions. 16 specialties. >2,000,000 doc since eCRF. 3,739 terms or expressions. 367 terms or expression. Visite-IT 4,345 instanciated eCRF since 2001 derived from seven Arcadia eCRFs templates. 236 termes. Arcadia-IT Negative. Positive. Study terms CR-IT/PC-IT. Positive/Study terms (%) 648. a/a b/b In experimental settings A, after expert validation the mapping between CR-IT terms of the electronic clinical research form (eCRF)(a=Arcadia) and PC-IT terms used for data capture in the hypertension department (a= Visite) is evaluated to 10%. The precision and recall of the algorithm are respectively of 70 and 100%. In experimental settings B, after expert validation the mapping between CR-IT terms of the minimum data elements for cancer registries (b=AP checklists) and PC-IT terms used to capture structured anatomic pathology diagnostic findings for cancer (b=AP reports) is evaluated to xxxx%. The sensitivity and specificity of the algorithm are respectively of xxx and xxxx%. TP. TP+FN/study terms. FN. Precision. FP. TN. Recall /236 (11%) /135 (11.8%) The automatic mapping between the interface terminologies (a (Arcadia), a (Visite), b (AP checklists) and b (AP reports)) and SNOMED v3.5 are from 25 to 70% (table 3). CR-IT/SNOMED v3.5. PC-IT/SNOMED v3.5. a/SNOMED v , b/SNOMED v , In the experimental setting A, after expert validation the mapping between CR-IT terms of the electronic clinical research form (eCRF)(a=Arcadia) and SNOMED v3.5 increases to 27% (precision : 0.73 and recall 0.76). The mapping between PC-IT terms used for data capture in the hypertension department (a= Visite) and SNOMED v3.5 increases to 17% (precision: 0.75 and recall 0.55) (table 4). In experimental settings B, after expert validation the mapping between CR-IT terms of the minimum data elements for cancer registries (b=AP checklists) and SNOMED v3.5 increases to 20% (precision : 0.60 and specificity 0.59). The mapping between PC-IT terms used to capture structured anatomic pathology diagnostic findings for cancer (b=AP reports) and SNOMED v3.5 increases to xxxx% (precision: xxxx and recall xxx)(table4) Thanks to the validated mapping between SNOMED v3.5 and the interface terminologies b (AP checklists) and b (AP reports), the validated mapping between these two interface terminologies is re-calculated and increases from xxx to xxxx% (table 5). Thanks to the validated mapping between SNOMED v3.5 and the interface terminologies a (Arcadia) and a (Visite); the validated mapping between these two interface terminologies is re-calculated and increases from 10 to 13.1% (table 5). TP+FN/study terms (after SNOMED v3.5 mapping) 8 (+23) / /236 ( 2(+13)/ /176. Taux de réutilisation potentielle de données cliniques: 13.1%")
24
Bibliothèque de variables standardisées HEGP (Recherche clinique/Soin)
Variables « Soin » Variables « Recherche clinique »

25
Interopérabilité sémantique Pourquoi faire?

26
Interopérabilité sémantique Bénéfices attendus
Permet l’extraction et l’utilisation de l’information clinique non seulement par des humains Mais aussi par des machines (Systèmes d’information de Santé) offrant des fonctionnalités avancées pour la coordination des soins, la recherche et formation Grâce à l’intégration de données et de connaissances POURQUOI CODER PUISQUE C’EST DIFFICILE (CODER DE LA MEME FACON : LA TERMINOLOGIE N’EST PAS TOU!)
 offrant des fonctionnalités avancées pour la coordination des soins, la recherche et formation. Grâce à l’intégration de données et de connaissances. POURQUOI CODER PUISQUE C’EST DIFFICILE. (CODER DE LA MEME FACON : LA TERMINOLOGIE N’EST PAS TOU!)")
27
Coordination des soins Capture de données (guidée par une ontologie)
Structured Data Entry File Edit Help FRACTURE SURGERY Reduction Fixation Fixation Open Closed Open Tibia Fibula Ankle More... Radius Ulna Wrist Humerus Femur Femur Left Left Right More... Gt Troch Shaft Neck Neck Réduction d’une fracture du col du fémur gauche

28
Coordination des soins Recherche d’information (vues, navigation)
Vues construites à partir de l’interprétation de données cliniques structurées codées Ce patient présente de nouveaux résultats biologiques en rapport avec sa pathologie hépatique Maladies Hépatobiliaires Tests fonctionnels hépatiques Cholestase et ictère Hépatite test_diagnostique_de Hépatite cytolytique Hépatite cholestatique Rapprocher les inforamtion cliniques se rapportant au même problème. Augmentation des ALAT Bilirubine augmentée Hépatite cholestatique : oui Blb augmentée ALAT augmentées

29
Coordination des soins Aide à la décision, évaluation des pratiques
Coupler les données cliniques aux règles en se basant sur l’interprétation de données cliniques structurées codées E.g Rappels, alarmes, suggestions diagnostiques ou thérapeutiques, détection des interactions, détection de pratiques inappropriées Rapprocher les inforamtion cliniques se rapportant au même problème. : comparer les traitements délivrés pour une même indication

30
Epidémiologie, veille sanitaire
Tableaux de bords construits à partir de l’interprétation (agrégation) de données cliniques structurées codées La résistance des entérobactéries aux fluoroquinolones augmente en Ile de France Entérobactéries Fluoroquinolones Quinolones … Escherichia Klebsiella test_de_susceptibilité Peflacine Oflocet Escherichia coli Klebsie pneumoniaella
 de données cliniques structurées codées. La résistance des entérobactéries aux fluoroquinolones augmente en Ile de France. Entérobactéries. Fluoroquinolones. Quinolones. … Escherichia. Klebsiella. test_de_susceptibilité. Peflacine. Oflocet. Escherichia coli. Klebsie pneumoniaella.")
31
Epidémiologie, veille sanitaire
Détection du signal (pharmacovigilance) à partir de l’interprétation (agrégation) de données cliniques structurées codées 3 cas d’hépatotoxicité liés au Doliprane ? Maladies Hépatobiliaires Tests fonctionnels hépatiques Cholestase et ictère Hépatite test_diagnostique_de Hépatite cytolytique Hépatite cholestatique Augmentation des ALAT Bilirubine augmentée Atteinte hépatique: Hépatite cytolytique Blb augmentée ALAT augmentées Hépatite cholestatique : oui
 à partir de l’interprétation (agrégation) de données cliniques structurées codées. 3 cas d’hépatotoxicité liés au Doliprane Maladies. Hépatobiliaires. Tests. fonctionnels. hépatiques. Cholestase. et ictère. Hépatite. test_diagnostique_de. Hépatite. cytolytique. Hépatite. cholestatique. Augmentation. des ALAT. Bilirubine. augmentée. Atteinte hépatique: Hépatite cytolytique. Blb augmentée. ALAT augmentées. Hépatite cholestatique : oui.")
32
Interopérabilité sémantique Comment?

33
Standards pour l’interopérabilité des SIS Health Level 7 (HL7)
Organisme de développement de standards (ANSI) créé en 1987 Standards d’échange ou partage de données informatisées administratives et cliniques (spécifications messages, documents) 500 organisations membres, inscrits, 15 affiliés internationaux France depuis 2004 Les organismes de standardisation dans le domaine de l’informatique de santé, tels que HL7, le CEN TS 251, ISO TC 215, DICOM assurent dans le cadre de leur mission la production de standards d’interopérabilité de SIS. Les modèles de documents cliniques de réference sont le support de l’intéropérabilité sémantique Les standards fournissent la grammaire (structures de données) et le vocabulaire REFERENTIELS DE CONTENU RIM – HL7 CDA HL7 (Health Level 7) : Standard de données santé le plus implémenté au monde “HL7 is the undisputed leader in the establishment of standards for interoperability among computerized information systems in healthcare.” US. Dept. For Health and Human Services, Public Health Service, Centers For Disease Control and Prevention. Public Health Conceptual Data Model. July 2000.
 créé en Standards d’échange ou partage de données informatisées administratives et cliniques (spécifications messages, documents) 500 organisations membres, 1500 inscrits, 15 affiliés internationaux. France depuis Les organismes de standardisation dans le domaine de l’informatique de santé, tels que HL7, le CEN TS 251, ISO TC 215, DICOM assurent dans le cadre de leur mission la production de standards d’interopérabilité de SIS. Les modèles de documents cliniques de réference sont le support de l’intéropérabilité sémantique. Les standards fournissent la grammaire (structures de données) et le vocabulaire. REFERENTIELS DE CONTENU. RIM – HL7 CDA. HL7 (Health Level 7) : Standard de données santé le plus implémenté au monde. HL7 is the undisputed leader in the establishment of standards for interoperability among computerized information systems in healthcare. US. Dept. For Health and Human Services, Public Health Service, Centers For Disease Control and Prevention. Public Health Conceptual Data Model. July")
34
HL7 Version 3 Modèle de données de réference RIM : Reference Information Model Modèle objet représenté en Unified Modeling Langage (UML) Types de données rigoureusement définis Couplage avec des domaines de vocabulaires contrôlés prédéfinis Modèles de données spécifiques Organisés en 30 domaines d’intérêt (Universal Domains) Ex : laboratoire, médicament, prescription, résultats, etc Conçus en utilisant une méthode formelle de développement de standards (HDF : HL7 Development Framework) Messages e.g prescription médicamenteuse, résultat biologique, etc Document clinique : HL7 Clinical Document architecture (CDA) ISO ISO RIM Genèse 1997 : Première version du RIM (draft 0.80) Août 2001 : 1er ballot v3 Standard ISO (TC 215) le modèle d’information de réference HL7 (RIM) (ISO/HL (2006)) Modèle objet couvrant la totalité des domaines de la santé Définition détaillée et précise des informations à partir desquelles les messages de communication et les architectures de documents HL7 sont construits Données cliniques, administratives, financières, d’assurance Maintenu de façon collaborative Processus de conception consensuelle (Technical Committees & Special Interest Groups) Base d’extensions nationales définies par les affiliés HL7 Méthode formelle de développement de standards (HDF : HL7 Development Framework) Méthode de conception orientée objet Outils de dérivation et test de conformité ISO 34
 Ex : laboratoire, médicament, prescription, résultats, etc. Conçus en utilisant une méthode formelle de développement de standards (HDF : HL7 Development Framework) Messages. e.g prescription médicamenteuse, résultat biologique, etc. Document clinique : HL7 Clinical Document architecture (CDA) ISO. ISO. RIM. Genèse : Première version du RIM (draft 0.80) Août 2001 : 1er ballot v3. Standard ISO (TC 215) le modèle d’information de réference HL7 (RIM) (ISO/HL (2006)) Modèle objet couvrant la totalité des domaines de la santé. Définition détaillée et précise des informations à partir desquelles les messages de communication et les architectures de documents HL7 sont construits. Données cliniques, administratives, financières, d’assurance. Maintenu de façon collaborative. Processus de conception consensuelle (Technical Committees & Special Interest Groups) Base d’extensions nationales définies par les affiliés HL7. Méthode formelle de développement de standards (HDF : HL7 Development Framework) Méthode de conception orientée objet. Outils de dérivation et test de conformité. ISO. 34.")
35
RIM HL7: Diagramme de classes
ISO 110 classes 532 attributs 167 Relations 30 relations Is-a 2 relations d’agrégation 43 types de données (Data types) Couplage à des vocabulaires contrôlés 35
 Couplage à des vocabulaires contrôlés. 35.")
36
Types de données HL7 Booléen String Concept Descriptor
ISO Booléen String Concept Descriptor <code ='8480-6 ' displayName=‘Intravascular systolic' codeSystem=' ' codeSystemName='LOINC'/> Physical Quantity Real Integer

37
Prescription médicamenteuse
HL7 v3 Architetcure de document clinqiue HL7 Clinical Document Architecture (CDA) ISO Valideur Observation Signataire légal Corps non structuré ROI Destinataire Moyen d’observation Auteur Prescription médicamenteuse Opérateur de saisie Procédure Structure de données dérivant du HL7 v3 Reference Information Model (RIM ) Utilisant les types de données HL7 v3 Data Types Constituée Header Informations concernant le patient, lnepersonnel de santé, la visite encounter, and authentication Body Texte libre/ contenu multimedia (level 1) +/- equivalent coded information (levels 2 & 3) (Release 2 (2005) Codée en Extensible Markup Language (XML) Guides d’implémentation ASTM/HL7 Continuity of Care Document (CCD) IHE Patient Care Coordination (PCC) Templates Patient Episode de soin Observation Organiseur Acte Participant Corps structuré 37 Entête
 ISO. Valideur. Observation. Signataire légal. Corps non structuré. ROI. Destinataire. Moyen d’observation. Auteur. Prescription médicamenteuse. Opérateur de saisie. Procédure. Structure de données dérivant du HL7 v3 Reference Information Model (RIM ) Utilisant les types de données HL7 v3 Data Types. Constituée. Header. Informations concernant le patient, lnepersonnel de santé, la visite encounter, and authentication. Body. Texte libre/ contenu multimedia (level 1) +/- equivalent coded information (levels 2 & 3) (Release 2 (2005) Codée en Extensible Markup Language (XML) Guides d’implémentation. ASTM/HL7 Continuity of Care Document (CCD) IHE Patient Care Coordination (PCC) Templates. Patient. Episode de soin. Observation. Organiseur. Acte. Participant. Corps structuré. 37. Entête.")
38
HL7 CDA niveau 3 Document clinique section fournit
ClinicalDocument : en-tête CDA identification, type, gestion du document patient et rencontre (venue en étabt.) participants (prescripteur, signataire, etc) fournit l’essentiel des métadonnées pour l’indexation du document structuredBody : corps structuré section section de second niveau text [ … ] entry observations images & graphes … … Mise en page de l’élément <text> : paragraph table renderMultimedia : graphiques
 participants (prescripteur, signataire, etc) fournit. l’essentiel des métadonnées pour l’indexation du document. structuredBody : corps structuré. section. section de second niveau. text [ … ] entry. observations. images & graphes … … Mise en page de l’élément <text> : paragraph. table. renderMultimedia : graphiques.")
39
HL7 CDA : structure Ex: Pression artérielle systolique
Variable élément <observation> utilisant le modèle Vital Signs Observation template. <observation classCode='OBS' moodCode='EVN'> <templateId root=' '/> <code code='8480-6 ' displayName=‘Intravascular systolic pressure' codeSystem=' ' codeSystemName='LOINC'/> <effectiveTime value=' '/> <value xsi:type='PQ' value=' ' unit=' mm[Hg] '/> </observation> “Organiseur” “Signes vitaux” Element <organizer> <organizer classCode='CLUSTER' moodCode='EVN'> <templateId root=' '/> <code code=' ' displayName='Vital signs' codeSystem=' ' codeSystemName=‘SNOMED CT /> <!-- one or more vital signs observations --> <templateId root=' '/> </observation> </organizer> The vital signs section contains coded measurement results of a patient’s vital signs. The organizer shall have one or more <component> elements that are <observation> elements using the Vital Signs Observation template. <organizer classCode='CLUSTER' moodCode='EVN'> <templateId root=' '/> <templateId root=' '/> <templateId root=' '/> <id root='' extension=''/> <code code=' ' displayName='Vital signs' codeSystem=' ' codeSystemName='SNOMED CT'/> <statusCode code='completed'/> <effectiveTime value=''/> <!-- For HL7 Version 3 Messages <author classCode='AUT'> <assignedEntity1 typeCode='ASSIGNED'> : <assignedEntity1> </author> --> <!-- one or more vital signs observations --> <component typeCode='COMP'> <observation classCode='OBS' moodCode='EVN'> <templateId root=' '/> : </observation> </component></organizer>The organizer shall have one or more <component> elements that are <observation> elements using the Vital Signs Observation template. <observation classCode='OBS' moodCode='EVN'> <templateId root=' '/> <templateId root=' '/> <templateId root=' '/> <id root=' ' extension=' '/> <code code=' ' codeSystem=' ' codeSystemName='LOINC'/> <text><reference value='#xxx'/></text> <statusCode code='completed'/> <effectiveTime value=' '/> <repeatNumber value=' '/> <value xsi:type='PQ' value=' ' unit=' '/> <interpretationCode code=' ' codeSystem=' ' codeSystemName=' '/> <methodCode code=' ' codeSystem=' ' codeSystemName=' '/> <targetSiteCode code=' ' codeSystem=' ' codeSystemName=' '/></observation> 39

40
HL7 CDA : vocabulaire Ex: Variables du groupe «Signes vitaux»
Code de l‘observation (LOINC) Designation de l‘observation Type de donnée de la valeur de l’observation Unité 9279-1 RESPIRATION RATE Numérique /min 8867-4 HEART BEAT 2710-2 OXYGEN SATURATION % 8480-6 INTRAVASCULAR SYSTOLIC PRESSURE mm[Hg] 8462-4 INTRAVASCULAR DIASTOLIC PRESSURE 8310-5 BODY TEMPERATURE Cel or [degF] 8302-2 BODY HEIGHT m, cm,[in_us] or [in_uk] 8306-3 BODY HEIGHT^LYING 8287-5 CIRCUMFRENCE.OCCIPITAL-FRONTAL (TAPE MEASURE) 3141-9 BODY WEIGHT kg, g, [lb_av] or [oz_av] La terminologie exprime des “faits vrais/théories”. Elle ne décrit pas "la structure des informations dans leur contexte" Une terminologie doit être d’usage général et définir seulement les concepts du monde réel Elle fournit une base pour des hypothèses d’aide à la décision Mais la façon dont on structure les données est souvent arbitraire, culturelle et spécifique De manière courante, on n’a presque pas de contrôle sur les données ou leurs requêtes
 Designation de l‘observation. Type de donnée de la valeur de l’observation. Unité RESPIRATION RATE. Numérique. /min HEART BEAT OXYGEN SATURATION. % INTRAVASCULAR SYSTOLIC PRESSURE. mm[Hg] INTRAVASCULAR DIASTOLIC PRESSURE BODY TEMPERATURE. Cel or [degF] BODY HEIGHT. m, cm,[in_us] or [in_uk] BODY HEIGHT^LYING CIRCUMFRENCE.OCCIPITAL-FRONTAL (TAPE MEASURE) BODY WEIGHT. kg, g, [lb_av] or [oz_av] La terminologie exprime des faits vrais/théories . Elle ne décrit pas la structure des informations dans leur contexte Une terminologie doit être d’usage général et définir seulement les concepts du monde réel. Elle fournit une base pour des hypothèses d’aide à la décision. Mais la façon dont on structure les données est souvent arbitraire, culturelle et spécifique. De manière courante, on n’a presque pas de contrôle sur les données ou leurs requêtes.")
41
Standards pour l’interopérabilité des SIS
x.htm 30 domaines CE QUI EST REQUIS Des modèles "d'information dans leur contexte" par discipline, exprimant une structure et des contraintes Une connexion à des terminologies Une capacité à créer des données respectant les règles de ces modèles, en utilisant correctement la terminologie Une capacité à partager les données et les modèles Les modèles doivent être séparés, et relativement indépendants ; ils ne peuvent pas faire partie d'une ontologie massive Les auteurs doivent être les cliniciens, pas les informaticiens !

42
Standards pour l’interopérabilité des SIS CEN TC 251
Organisme de développement de standards Standard de communication entre DPI (EHR) Solution de partage de dossiers ou d’éléments de dossier Entre systèmes hétérogènes au sein d’un réseau EN13606 (EHRcom) en 2006 Modèle de données de référence Modèle de données spécifiques (archétypes) Modèles de messages Organisme de développement de standards depuis xxx Spécifications logicielles (messages, documents) Échange ou partage de données informatisées administratives et cliniques Xxx organisations membres, xxxx inscrits, xx affiliés internationaux (France depuis xxx) Partie 1: Modèle de Référence Modèle générique pour le partage de tout ou partie(s) de DPI Partie 2: Modèle d’archétypes Modèle permettant de décrire des “objets métiers” cliniques et leurs contraintes en s’appuyant sur le Modèle de Référence - adopté d’openEHR Partie 3: Archétypes de référence et terminologies Base d’archétypes Micro-vocabulaires pour le Modèle de référence Partie 4: Sécurité Solutions permettant de gérer le contrôle d’accès et la supervision des communications entre DPI. Partie 5: Modèles d’échange Message et interfaces de services permettant la communication d’archétypes et d’éléments de dossier
 Solution de partage de dossiers ou d’éléments de dossier. Entre systèmes hétérogènes au sein d’un réseau. EN13606 (EHRcom) en Modèle de données de référence. Modèle de données spécifiques (archétypes) Modèles de messages. Organisme de développement de standards depuis xxx. Spécifications logicielles (messages, documents) Échange ou partage de données informatisées administratives et cliniques. Xxx organisations membres, xxxx inscrits, xx affiliés internationaux (France depuis xxx) Partie 1: Modèle de Référence. Modèle générique pour le partage de tout ou partie(s) de DPI. Partie 2: Modèle d’archétypes. Modèle permettant de décrire des objets métiers cliniques et leurs contraintes en s’appuyant sur le Modèle de Référence - adopté d’openEHR. Partie 3: Archétypes de référence et terminologies. Base d’archétypes. Micro-vocabulaires pour le Modèle de référence. Partie 4: Sécurité. Solutions permettant de gérer le contrôle d’accès et la supervision des communications entre DPI. Partie 5: Modèles d’échange. Message et interfaces de services permettant la communication d’archétypes et d’éléments de dossier.")
43
“Standardiser les standards”
CEN TC 251 HL7

44
Standards - Mode d’emploi
Standards - Mode d’emploi ? Rôle de l’initiative “Integrating the Healthcare Enterprise” (IHE) Y-a-t-il un chef d’orchestre ? IHE (Integrating the Healthcare Entreprise) Promotion de l’utilisation de standards existant IT (Internet, ISO, etc) Domaine de la santé (HL7, DICOM) Existe-t-il une partition ? Technical framework IHE – Profils d’intégration Forum de discussion et de spécification Utilisateurs et développeurs Y-a-t-il des répétitions ? Connectathons Environnement de test de la connectivité des produits Editeurs testent la connectivité de leurs produits sous la surveillance d’observateurs neutres QUAND ON CONNAIS UN PEU LA MUSIQUE IL N4EST PAS CERTAIN DE SAVOIR JOUER LA SYMPHONIE DE L4INTEROP RECETTES D’INTEGRATION REPOSANT SUR DES STANDARD POUR DES SITUATIONS CONCRETES Je veux envoyer une prescription méd, bio, je veux envoyer un résultat bio ou d’anapath, je veux partager un document clinique, je veux envoyer des données d’anapath à un registre de cancer, je veux partager un formulaire de recherche clinique avec un DPI Solution aux problèmes non résolus par les organismes de standardisation. Au besoin IHE remonte ces problèmes au niveau de ces organismes. d’un chef de projet oeuvrant sous la responsabilité des utilisateurs sponsorisant IHE
 Y-a-t-il un chef d’orchestre IHE (Integrating the Healthcare Entreprise) Promotion de l’utilisation de standards existant. IT (Internet, ISO, etc) Domaine de la santé (HL7, DICOM) Existe-t-il une partition Technical framework IHE – Profils d’intégration. Forum de discussion et de spécification. Utilisateurs et développeurs. Y-a-t-il des répétitions Connectathons. Environnement de test de la connectivité des produits. Editeurs testent la connectivité de leurs produits sous la surveillance d’observateurs neutres. QUAND ON CONNAIS UN PEU LA MUSIQUE IL N4EST PAS CERTAIN DE SAVOIR JOUER LA SYMPHONIE DE L4INTEROP. RECETTES D’INTEGRATION REPOSANT SUR DES STANDARD POUR DES SITUATIONS CONCRETES. Je veux envoyer une prescription méd, bio, je veux envoyer un résultat bio ou d’anapath, je veux partager un document clinique, je veux envoyer des données d’anapath à un registre de cancer, je veux partager un formulaire de recherche clinique avec un DPI. Solution aux problèmes non résolus par les organismes de standardisation. Au besoin IHE remonte ces problèmes au niveau de ces organismes. d’un chef de projet oeuvrant sous la responsabilité des utilisateurs sponsorisant IHE.")
45
Integrating the Healthcare Enterprise (IHE)
Connectathons

46
Integrating the Healthcare Enterprise (IHE)
")
47
Integrating the Healthcare Enterprise (IHE)
")
48
Standards - Mode d’emploi ? Rôle de l’ASIP Santé
En France, l’ASIP Santé (Agence des Systèmes d’Information Partagés de Santé) est en charge du cadre d’interopérabilité des SI de santé Définir, promouvoir et homologuer des référentiels contribuant à l’interopérabilité, à la sécurité et à l’usage des systèmes d’information de santé et de la télésanté. Référentiels d’identification : Patients (Identifiant National de Santé) , Professionnel de Santé, Etablissement de Santé Réseau d’Annuaires Santé Social (RASS – publication des annuaires RPPS, noyau RMESS) Référentiels de sécurité : Procédure d’agrément des hébergeurs de données de santé Politique Générale de Sécurité des SI de Santé) Référentiel d’authentification (authentification des PS au sein des ES) Référentiel d’imputabilité (signerquoi avec quel certificat) Le cadre d’interopérabilité : Interopérabilité technique (transport et services) Interopérabilité sémantique (modèles de contenus et terminologies) IHE CDA
 est en charge du cadre d’interopérabilité des SI de santé. Définir, promouvoir et homologuer des référentiels contribuant à l’interopérabilité, à la sécurité et à l’usage des systèmes d’information de santé et de la télésanté. Référentiels d’identification : Patients (Identifiant National de Santé) , Professionnel de Santé, Etablissement de Santé. Réseau d’Annuaires Santé Social (RASS – publication des annuaires RPPS, noyau RMESS) Référentiels de sécurité : Procédure d’agrément des hébergeurs de données de santé. Politique Générale de Sécurité des SI de Santé) Référentiel d’authentification (authentification des PS au sein des ES) Référentiel d’imputabilité (signerquoi avec quel certificat) Le cadre d’interopérabilité : Interopérabilité technique (transport et services) Interopérabilité sémantique (modèles de contenus et terminologies) IHE CDA.")
49
ASIP Santé Cadre d’interopérabilité
IHE CDA Standards internationaux dédiés à la santé SNOMED LOINC CIM-10 CDA DICOM Standards internationaux généralistes (de l’internet) Soap http xml SAML … assemblés et contraints dans des profils IHE
 Soap. http. xml. SAML. … assemblés et contraints dans des profils IHE.")
50
Interopérabilité sémantique Comment?
Un exemple : le référentiel “Compte rendu structuré d’anatomie pathologique” La mise en musique sur un exemple…

51
Contexte : Démarches nationales de standardisation des variables…
CR anatomie pathologique Pays-Bas, Allemagne, Australasie CR anatomie pathologique de cancérologie CAP (College of American Pathologists) 67 checklists et protocoles (Octobre 2009) France - SFP (Société Française de Pathologie) – INCa (Institut du Cancer) Items minimaux CR tumeur primitive - 20 localisations Australasie 6 modèles Royaume-Uni Anatomic pathology reports (APR) document the pathologic findings in specimens removed from patients for diagnostic or therapeutic reasons. This information can be used for patient care, clinical research and epidemiology. Standardizing and computerizing APRs is necessary to improve the quality of reporting and the exchange of APR information. As part of joint IHE and HL7 anatomic pathology activities, our objective is to provide a methodology and tools that facilitate the development of consensus-based APR templates and to publish an HL7 “Clinical Document Architecture” (CDA) implementation guide for these templates. Glodsmith08 [Goldsmith, J.D., et al., Reporting guidelines for clinical laboratory reports in surgical pathology. Arch Pathol Lab Med, (10): p ] provides recent recommendations that delineate the required, preferred, and optional elements which should be included in any APR, regardless of report types. Several international initiatives intend to define standard structured templates for specific types of APRs. For example, in the cancer domain, in the United States, the CAP (College of American Pathologists) has published 67 cancer APR templates (cancer checklists and background information) [ In France, the SFP (French society of pathology) has published 23 APR templates (cancer checklists associated to Comptes Rendus Fiches Standardisées, CRFS) that cover the main cancer domains [ Together, the recommendations for generic and specific APR reporting requirements have become clinical guidelines, the use of which may be required by accrediting bodies. In addition to standardizing the cancer APR contents, it is necessary to computerize them. Several studies have focused on defining an appropriate IT standard comprising the structured and encoded clinical documents (e.g. CAP eCC). HL7 CDA is one of the most reliable standards that can support these needs. CDA allows the clinical data to be both machine and human-readable and provides a framework for incremental growth in the granularity of structured, codes-bound clinical information. This document takes into consideration currently very few national initiatives of CDA implementation guides for the APR, one example being developed at the National IT Institute for Healthcare in the Netherlands [ pdf.]. Proposed Workitem: Proposal Editor: Thomas Schrader, CHristel Daniel Editor: Thomas Schrader? Domain: Anatomic Pathology 2. The Problem The transaction related to the reporting worflow (PAT3-Order Results Management) of the IHE Anatomic Pathologyt Technical Framework is mainly dedicated to storage and sharing of free text anatomic pathology reports. There are many initiatives in different countries and/or within standardization bodies (HL7, CEN)aiming at proposing standard structured architecture for anatomic pathology reports. CEN TC 251 WI :2003 : A histology report may be divided into sections describing the: macroscopic appearance, microscopic features and the conclusion of the service provider based on these findings. Each of these sections may consist of free-text, measurements (e.g. size, weight etc.) and code values representing the findings.Different healthcare parties may be responsible for different parts of a report. Furthermore, overall responsibility for reviewing and signing-off the reports may rest with yet another supervisory healthcare party. CAP Cancer Protocoles and checklists (US) INCa (France) Royal College (UK), etc) Generally speaking, according to “evidence-based pathology”, only features that are reproducible and relevant – with a demonstrated diagnostic or prognostic signification – should be reported in description and corresponding evidence available”. The obective of this white paper is to collect, analyze and summarize these different initiative in order to discuss the available technical solution to store and share strucred reports in anatomic pathology and to choose the most appropriate one. Confidentiality issues are out of the scope of this white paper 3. Key Use Case Activity diagrams and strucured reporting will be defined for the use cases already available in the IHE Anatomic Pathology TF 1 USE CASE 1: SURGICAL PATHOLOGY – OPERATIVE SPECIMEN 1.1: Surgical pathology – one specimen per container 1.2: Surgical pathology - more than one specimen per container 1.3: Surgical pathology – two requested procedure per order 2 USE CASE 2: SURGICAL PATHOLOGY – BIOPSIES 2.1: Biopsies – one specimen per container 2.2: Biopsies – more than one specimen per container 3 USE CASE 3: CYTOLOGY 3.1: Cytology – one specimen per container 3.2: Cytology – more than one specimen per container 4 USE CASE 4 : AUTOPSY 5 USE CASE 5: TISSUE MICRO ARRAY (MORE THAN ONE SPECIMEN FROM MORE THAN ONE PATIENT PER CONTAINER) 4. Standards & Systems XDS - CDA cf LAB domain HL7 v3 : Domaines Laboraory, Specimen, Observation 5. Discussion Will be especially considered the following issues and barriers : Medical consensus is not easy to achieve at regional/national/international level about important features that should be reported as well as the vocabulary and/or code system to use. Standard information models (templates) are not available. "International" code systems are mainly available in English and ther content coverage with regards to the content of anatomic pathology reports has not been formally evaluated Structured reports may be built from different sources(APIS, post processing station ("evidence" creation), etc). A crucial issue is to identify a technical solution to handle templates of structured reports including findings and their evidences. It should be possible to link each observation or finding to the specimen source (part(s) (Box ID) for macroscopic findings, tissue item (Slide ID) for microscopic findings)). Moreover it must be possible to link each observation or finding to the image(s) or region of interest of image(s) acquired from the specimen source. Complex diagnostic structured reports include numeric quantitative measurement, images or graphs, image annotation and links between image (and/or evidence) information and textual information. Structured reports may be designed for multple uses : patient care but also "secondary use" (clinical research, cancer registries, cancer multi(disciplinary meetings, etc). We have to carefully analyse these different contexts of producing structured reports (workflow) in order to define both templates and IT solution to support these different uses.
 67 checklists et protocoles (Octobre 2009) France - SFP (Société Française de Pathologie) – INCa (Institut du Cancer) Items minimaux CR tumeur primitive - 20 localisations. Australasie. 6 modèles. Royaume-Uni. Anatomic pathology reports (APR) document the pathologic findings in specimens removed from patients for diagnostic or therapeutic reasons. This information can be used for patient care, clinical research and epidemiology. Standardizing and computerizing APRs is necessary to improve the quality of reporting and the exchange of APR information. As part of joint IHE and HL7 anatomic pathology activities, our objective is to provide a methodology and tools that facilitate the development of consensus-based APR templates and to publish an HL7 Clinical Document Architecture (CDA) implementation guide for these templates. Glodsmith08 [Goldsmith, J.D., et al., Reporting guidelines for clinical laboratory reports in surgical pathology. Arch Pathol Lab Med, (10): p ] provides recent recommendations that delineate the required, preferred, and optional elements which should be included in any APR, regardless of report types. Several international initiatives intend to define standard structured templates for specific types of APRs. For example, in the cancer domain, in the United States, the CAP (College of American Pathologists) has published 67 cancer APR templates (cancer checklists and background information) [ In France, the SFP (French society of pathology) has published 23 APR templates (cancer checklists associated to Comptes Rendus Fiches Standardisées, CRFS) that cover the main cancer domains [ Together, the recommendations for generic and specific APR reporting requirements have become clinical guidelines, the use of which may be required by accrediting bodies. In addition to standardizing the cancer APR contents, it is necessary to computerize them. Several studies have focused on defining an appropriate IT standard comprising the structured and encoded clinical documents (e.g. CAP eCC). HL7 CDA is one of the most reliable standards that can support these needs. CDA allows the clinical data to be both machine and human-readable and provides a framework for incremental growth in the granularity of structured, codes-bound clinical information. This document takes into consideration currently very few national initiatives of CDA implementation guides for the APR, one example being developed at the National IT Institute for Healthcare in the Netherlands [ pdf.]. Proposed Workitem: Proposal Editor: Thomas Schrader, CHristel Daniel. Editor: Thomas Schrader Domain: Anatomic Pathology. 2. The Problem. The transaction related to the reporting worflow (PAT3-Order Results Management) of the IHE Anatomic Pathologyt Technical Framework is mainly dedicated to storage and sharing of free text anatomic pathology reports. There are many initiatives in different countries and/or within standardization bodies (HL7, CEN)aiming at proposing standard structured architecture for anatomic pathology reports. CEN TC 251 WI :2003 : A histology report may be divided into sections describing the: macroscopic appearance, microscopic features and the conclusion of the service provider based on these findings. Each of these sections may consist of free-text, measurements (e.g. size, weight etc.) and code values representing the findings.Different healthcare parties may be responsible for different parts of a report. Furthermore, overall responsibility for reviewing and signing-off the reports may rest with yet another supervisory healthcare party. CAP Cancer Protocoles and checklists (US) INCa (France) Royal College (UK), etc) Generally speaking, according to evidence-based pathology , only features that are reproducible and relevant – with a demonstrated diagnostic or prognostic signification – should be reported in description and corresponding evidence available . The obective of this white paper is to collect, analyze and summarize these different initiative in order to discuss the available technical solution to store and share strucred reports in anatomic pathology and to choose the most appropriate one. Confidentiality issues are out of the scope of this white paper. 3. Key Use Case. Activity diagrams and strucured reporting will be defined for the use cases already available in the IHE Anatomic Pathology TF. 1 USE CASE 1: SURGICAL PATHOLOGY – OPERATIVE SPECIMEN. 1.1: Surgical pathology – one specimen per container. 1.2: Surgical pathology - more than one specimen per container. 1.3: Surgical pathology – two requested procedure per order. 2 USE CASE 2: SURGICAL PATHOLOGY – BIOPSIES. 2.1: Biopsies – one specimen per container. 2.2: Biopsies – more than one specimen per container. 3 USE CASE 3: CYTOLOGY. 3.1: Cytology – one specimen per container. 3.2: Cytology – more than one specimen per container. 4 USE CASE 4 : AUTOPSY. 5 USE CASE 5: TISSUE MICRO ARRAY (MORE THAN ONE SPECIMEN FROM MORE THAN ONE PATIENT PER CONTAINER) 4. Standards & Systems. XDS - CDA. cf LAB domain. HL7 v3 : Domaines Laboraory, Specimen, Observation. 5. Discussion. Will be especially considered the following issues and barriers : Medical consensus is not easy to achieve at regional/national/international level about important features that should be reported as well as the vocabulary and/or code system to use. Standard information models (templates) are not available. International code systems are mainly available in English and ther content coverage with regards to the content of anatomic pathology reports has not been formally evaluated. Structured reports may be built from different sources(APIS, post processing station ( evidence creation), etc). A crucial issue is to identify a technical solution to handle templates of structured reports including findings and their evidences. It should be possible to link each observation or finding to the specimen source (part(s) (Box ID) for macroscopic findings, tissue item (Slide ID) for microscopic findings)). Moreover it must be possible to link each observation or finding to the image(s) or region of interest of image(s) acquired from the specimen source. Complex diagnostic structured reports include numeric quantitative measurement, images or graphs, image annotation and links between image (and/or evidence) information and textual information. Structured reports may be designed for multple uses : patient care but also secondary use (clinical research, cancer registries, cancer multi(disciplinary meetings, etc). We have to carefully analyse these different contexts of producing structured reports (workflow) in order to define both templates and IT solution to support these different uses.")
52
Contexte : Démarches nationales de standardisation des variables…
1er avril 2017

53
Contexte : … et de production de guides d’implémentation
Standards internationaux généralistes XML CAP electronic Cancer Checklist Standards internationaux d’informatique de santé CEN archétypes Australie HL7 CDA Pays-Bas, Allemagne Most reliable standard for clinical document templates International standard (ISO/HL :2009 Data Exchange Standards - HL7 Clinical Document Architecture, Release 2) Clinical data are both human-readable and machine Existing implementation guides for the APSR ? In addition to standardizing the cancer APR contents, it is necessary to computerize them. Several studies have focused on defining an appropriate IT standard comprising the structured and encoded clinical documents (e.g. CAP eCC). HL7 CDA is one of the most reliable standards that can support these needs. CDA allows the clinical data to be both machine and human-readable and provides a framework for incremental growth in the granularity of structured, codes-bound clinical information. This document takes into consideration currently very few national initiatives of CDA implementation guides for the APR, one example being developed at the National IT Institute for Healthcare in the Netherlands [ pdf.].
 Clinical data are both human-readable and machine. Existing implementation guides for the APSR In addition to standardizing the cancer APR contents, it is necessary to computerize them. Several studies have focused on defining an appropriate IT standard comprising the structured and encoded clinical documents (e.g. CAP eCC). HL7 CDA is one of the most reliable standards that can support these needs. CDA allows the clinical data to be both machine and human-readable and provides a framework for incremental growth in the granularity of structured, codes-bound clinical information. This document takes into consideration currently very few national initiatives of CDA implementation guides for the APR, one example being developed at the National IT Institute for Healthcare in the Netherlands [ pdf.].")
54
Objectif: Référentiel “Compte rendu structuré d’anatomie pathologique”
Modèles HL7 CDA de CR anatomie pathologique pour l’échange ou partage dans un contexte de coordination des soins Périmètre 22 modèles de CR Modèle générique Tout type de pathologie (inflammatoire, vasculaire, traumatique, métabolique ou tumorale) Modèles générique de CR de cancer 20 modèles de CR de cancer spécifiques d’organe (85% des cancers incidents) Variables anatomo-pathologiques “traditionnelles” Microscopie optique (y compris immunohistochimie, hybridation in situ, etc) Royal College of pathologists Australasia Describes an anatomic pathology report as an electronic document to be published towards a document sharing resource such as a Personal Health Record (PHR) shared by a community of care providers, using one of the document sharing profiles defined in ITI-TF. Such an electronic document contains the set of observations produced by an anatomic pathology laboratory in fulfillment of an Order or an Order Group The definition of required, preferred and optional elements in APSR is mainly based on [Glodsmith08] and, in the cancer domain, on clinical document models provided by US CAP and French SFP & INCa The report is shared in a human-readable format AND contain anatomic pathology observations as well as links to relevant images in a machine-readable format, to facilitate the integration of these observations in the database of a consumer system. The set of anatomic pathology observations in a machine-readable format, MAY also be used with appropriate content anonymization and patient identification pseudonymization to create shared repositories of anatomic pathology information.
 Modèles générique de CR de cancer. 20 modèles de CR de cancer spécifiques d’organe (85% des cancers incidents) Variables anatomo-pathologiques traditionnelles Microscopie optique (y compris immunohistochimie, hybridation in situ, etc) Royal College of pathologists Australasia. Describes an anatomic pathology report as an electronic document to be published towards a document sharing resource such as a Personal Health Record (PHR) shared by a community of care providers, using one of the document sharing profiles defined in ITI-TF. Such an electronic document contains the set of observations produced by an anatomic pathology laboratory in fulfillment of an Order or an Order Group. The definition of required, preferred and optional elements in APSR is mainly based on [Glodsmith08] and, in the cancer domain, on clinical document models provided by US CAP and French SFP & INCa. The report is shared in a human-readable format AND contain anatomic pathology observations as well as links to relevant images in a machine-readable format, to facilitate the integration of these observations in the database of a consumer system. The set of anatomic pathology observations in a machine-readable format, MAY also be used with appropriate content anonymization and patient identification pseudonymization to create shared repositories of anatomic pathology information.")
55
Méthode de production du référentiel Profil de contenu IHE
Production du référentiel international (profil de contenu IHE « Anatomic Pathology Structured Report ») Initiative conjointe IHE-HL7 anatomic pathology (ADICAP, ASIP Santé, CAP, NAACCR, CDC) Production de l’extension nationale (référentiel ASIP Santé « CR d’Anatomie Pathologique (CR-ACP) ») Following annual cycles Technical frameworks User’s needs “Integration profiles” (real-world situations of the healthcare workflow) Implementation guides for transactions using established industry standards such as DICOM or HL7 “Connectathons” Rigorous neutral testing process
 Initiative conjointe IHE-HL7 anatomic pathology (ADICAP, ASIP Santé, CAP, NAACCR, CDC) Production de l’extension nationale (référentiel ASIP Santé « CR d’Anatomie Pathologique (CR-ACP) ») Following annual cycles. Technical frameworks. User’s needs. Integration profiles (real-world situations of the healthcare workflow) Implementation guides for transactions using established industry standards such as DICOM or HL7. Connectathons Rigorous neutral testing process.")
56
CR d’anatomie pathologique (HL7 CDA) Corps structuré
Organizing observations in sections Information in entry(ies) Grouped by specimen (Specimen Information Organizer) & problem (Problem Organizer) Example : Final diagnosis entry Left breast excision Infiltrating ductal carcinoma DCIS Apical left axillary tissue sampling Micrometasases
 Grouped by specimen (Specimen Information Organizer) & problem (Problem Organizer) Example : Final diagnosis entry. Left breast excision. Infiltrating ductal carcinoma. DCIS. Apical left axillary tissue sampling. Micrometasases.")
57
Variables anatomo-pathologiques (n=80) e
Variables anatomo-pathologiques (n=80) e.g “procédure de collecte du prélèvement”, “taille de la tumeur”, “type histologique” [0..*] <value> (zero to many response) coded (code, coding system, version, display name) [0..*] <qualifier> (post coordinated expression) numeric (integer or real, unit) textual
 e.g procédure de collecte du prélèvement , taille de la tumeur , type histologique [0..*] <value> (zero to many response) coded (code, coding system, version, display name) [0..*] <qualifier> (post coordinated expression) numeric (integer or real, unit) textual.")
58
Jeux de valeurs (“Value Sets”) des variables codées (Coded Descriptor)
Procédure de collecte du prélèvement (CR cancer du sein) Système de codage: PathLex – OID: Jeu de valeurs OID: Exceptions admises: Inconnu, demandé mais inconnu, autre displayName Breast excision without wire-guided localization Breast excision with wire-guided localization Total mastectomy (including nipple and skin)
 Système de codage: PathLex – OID: Jeu de valeurs OID: Exceptions admises: Inconnu, demandé mais inconnu, autre. displayName. Breast excision without wire-guided localization. Breast excision with wire-guided localization. Total mastectomy (including nipple and skin)")
59
Ce que voit le clinicien
CR d’anatomie pathologiques standardisés, interprétables par l’Homme et la machine - HL7 CDA Ce que voit le clinicien Ce que voit la machine

60
Ce que voit le clinicien…
60

61
Ce que voit la machine… Solution d’échange et partage de CR d’anatomie pathologique multimédia au niveau international pour la coordination des soins Utilisation secondaire dans un contexte d’assurance qualité, d’épidémiologie (registres du cancer) et de recherche clinique <ClinicalDocument xmlns='urn:hl7-org:v3'> <typeId extension="POCD_HD000040" root=" "/> <!-- conformance to a generic APSR content module --> <templateId root=' '/> <!-- conformance to a cancer APSR content module --> <templateId root=' '/> <!-- conformance to a breast cancer content module --> <templateId root=' '/> ...remainder of the header not shown ... <component> <structuredBody> <section> <templateId root=' '/> <code code=' ' displayName=’Pathology report relevant history' codeSystem=' ' codeSystemName='LOINC'/> <title>Relevant information provided by the ordering physician</title> <text> Tissue submitted: left breast biopsy and apical axillary tissue </text> <entry> ... </entry> Kussaibi H, Macary F, Kennedy M, Booker D, Brodsky V, Schrader T, Garcia-Rojo M, Daniel C. CDA Implementation Guide for Structured Anatomic Pathology Reports Methodology and Tools. Medinfo. 2010 61
 et de recherche clinique. <ClinicalDocument xmlns= urn:hl7-org:v3 > <typeId extension= POCD_HD root= /> <!-- conformance to a generic APSR content module --> <templateId root= /> <!-- conformance to a cancer APSR content module --> <templateId root= /> <!-- conformance to a breast cancer content module --> <templateId root= /> ...remainder of the header not shown ... <component> <structuredBody> <section> <templateId root= /> <code code= displayName=’Pathology report relevant history codeSystem= codeSystemName= LOINC /> <title>Relevant information provided by the ordering physician</title> <text> Tissue submitted: left breast biopsy and apical axillary tissue </text> <entry> ... </entry> Kussaibi H, Macary F, Kennedy M, Booker D, Brodsky V, Schrader T, Garcia-Rojo M, Daniel C. CDA Implementation Guide for Structured Anatomic Pathology Reports Methodology and Tools. Medinfo")
62
Interopérabilité sémantique Comment?
Les 5 règles d’or de la production de référentiels d’interopérabilité sémantique Respecte-t-on les standards d’interopérabilité sémantique existant? (modèles et terminologies de référence) Ce n’est pas magique! seul garantie de cohérence, préoccupation de l’universalité Le contexte est-il clair? les objectifs et le périmètre bien définis? Le niveau de structuration envisagé est-il adapté? C’est spécifique! Dispose-t-on de ressources d’expertise métier et technique suffisantes? Dispose-t-on de la plateforme collaborative adéquate? C’est pharaonique! Des supports d’opérationalisation sont-ils prévus? Cà peut être pratique mais parfois très technique Existe-t-il un contexte d’acceptation favorable? C’est politique, éthique, etc
 Ce n’est pas magique! seul garantie de cohérence, préoccupation de l’universalité. Le contexte est-il clair les objectifs et le périmètre bien définis Le niveau de structuration envisagé est-il adapté C’est spécifique! Dispose-t-on de ressources d’expertise métier et technique suffisantes Dispose-t-on de la plateforme collaborative adéquate C’est pharaonique! Des supports d’opérationalisation sont-ils prévus Cà peut être pratique mais parfois très technique. Existe-t-il un contexte d’acceptation favorable C’est politique, éthique, etc.")
63
Le respect des standards internationaux (Format & modèles métier)
Pas d’interopérabilité sémantique clinique en dehors de modèles CDA de référence encodant des modèles métier partagés, consensuels et validés L’interopérabilité sémantique ce n’est pas magique! SAVE AS CDA PAS SEULEMENT LE CDA : COQUILLE VIDE ETRE CONFORME A CDA DANS L’ABSOLU CA NE VEUT RIEN DIRE C’EST COMME ETRE CONFORME A DICOM!!! Etre compatible CDA cela ne veut rien dire sur le plan de l’interopérabilité sémantique du contenu de santé. CDA c’est une architecture de document clinique GENERALE. Si l’on veut standardiser des contenu c’est la conformité à des modèles de contenu SPECIFIQUES (eux mêmes conformes à CDA) qu’il faut savoir exiger. 63
 qu’il faut savoir exiger. 63.")
64
Un contexte (objectif et périmètre) bien défini
L’interopérabilité sémantique c’est spécifique! Grande variabilité des modèles métier de documents de santé en fonction du contexte d’utilisation (soin, recherche), des experts, du temps, etc Importance de la validation du modèle métier (consensus d’experts, demande institutionnelle/réglementaire, etc) avant toute production de guide d’implémentation Des modèles "d'information dans leur contexte" par discipline, exprimant une structure et des contraintes Une connexion à des terminologies Une capacité à créer des données respectant les règles de ces modèles, en utilisant correctement la terminologie Une capacité à partager les données et les modèles Les modèles doivent être séparés, et relativement indépendants ; ils ne peuvent pas faire partie d'une ontologie massive Les auteurs doivent être les cliniciens, pas les informaticiens ! 64
, des experts, du temps, etc. Importance de la validation du modèle métier (consensus d’experts, demande institutionnelle/réglementaire, etc) avant toute production de guide d’implémentation. Des modèles d information dans leur contexte par discipline, exprimant une structure et des contraintes. Une connexion à des terminologies. Une capacité à créer des données respectant les règles de ces modèles, en utilisant correctement la terminologie. Une capacité à partager les données et les modèles. Les modèles doivent être séparés, et relativement indépendants ; ils ne peuvent pas faire partie d une ontologie massive. Les auteurs doivent être les cliniciens, pas les informaticiens ! 64.")
65
Des ressources d’expertise métier et technique
L’interopérabilité sémantique c’est pharaonique! TA : 160/95 ANAPATH : 9 mois-homme 65

66
Des ressources d’expertise métier et technique
<observation> elements are using the Vital Signs Observation template. <observation classCode='OBS' moodCode='EVN'> <templateId root=' '/> <code code='8480-6 ' displayName=‘Intravascular systolic pressure' codeSystem=' ' codeSystemName='LOINC'/> <effectiveTime value=' '/> <value xsi:type='PQ' value=' ' unit=' mm[Hg] '/> </observation> <code code='8480-6 ' displayName=‘Intravascular diastolic pressure' codeSystem=' ' codeSystemName='LOINC'/> <organizer classCode=‘cluster' moodCode='EVN'> <templateId root=' '/> <code code=' ' displayName='Vital signs' codeSystem=' ' codeSystemName='SNOMED CT'/> <!-- one or more vital signs observations --> <observation classCode='OBS' moodCode='EVN'> <templateId root=' '/> </observation> </organizer> 1…n Observation 5-10 concepts/h La spécification des documents est longue et technique ANAPATH : 9 mois alors que nous disposions de modèles médicaux éprouvés, validés, consensuels Vital sign section Organiseur 66

67
Un niveau de structuration adapté
L’interopérabilité sémantique ce n’est pas automatique! Le choix d’un niveau 3 de structuration permettent une interopérabilité sémantique doit être pesé. La structuration minimale des documents de santé (CDA niveau 1) permet le partage de documents au sein du DMP interprétables par des humains 67
 permet le partage de documents au sein du DMP interprétables par des humains. 67.")
68
Des conditions d’opérationnalisation
L’interopérabilité sémantique c’est parfois pratique…. Serveur de formulaire Intégration de référentiels d’interopérabilité sémantique dans les SI Intégration aux modèles/terminologies locales Produire des formulaires utilisables Gérer les versions …souvent technique L’opérationnalisation de référentiels d’interopérabilité sémantique basés sur des standards est un enjeu important mais reste encore un défi technique pour les éditeurs de SIS. De nombreux SIS sont des solutions propriétaires, incompatibles entre elles et liées à une plateforme spécifique. L’adoption des standards d’informatique de santé n’est pas encore assez avancée pour intégrer aisément des référentiels d’interopérabilité sémantique au sein des SIS. Dans le domaine de la recherché clinique, l’adoption du standard CDIC ODM a permis la mise en œuvre de solution d’intégration de modèle de document (l’eCRF ou cahier d’observation de recherché clinique électronique). Mais il faut noter que la collecte de données pour un essai clinique est réalisée « en silo » sans véritable préoccupation de cohérence avec d’autres études. Dans le domaine de la coordination des soins, des mécanismes similaires d’intégration de modèles de documents cliniques (basés sur le standard HL7 CDA) au sein de SIS peuvent s’envisager mais dans ce contexte il convient de prévoir la synchronisation des modèles de documents cliniques à intégrer avec ceux déjà utilisés au sein du SIS pour la collecte de données. La levée de ce verrou technologique est nécessaire au partage de données structurées et standardisées entre établissements de santé et a fortiori entre les établissements de santé et les structures de recherche ou les organismes de santé publique (objectif déjà atteint en ce qui concerne le PMSI). Progresser sur les concensus de conceptualisation de problème de santé D’emblée envisager les dimensions d’évaluation des pratiques, d’épidémiologie et de recherche clinique (recherche translationnelle) Pragmatisme : s’appuyer sur les initiatives institutionnelles qui facilitent l’utilisation des standards et leur adoption par les acteurs de terrains qui heureusement convergent Ex : NCI & ASIP Santé+++ La conceptualisation d’un domaine dépend-elle de l’activité? Périmètre et objectif 1ère approche : mettre en commun des modèles et ressources terminonologiques Certainement vrai pour des données de base, pour des réferentiels (identification des PDS, des patients, des organismes+++: du coté des SI) – des médicaments+++ Minimum data set : peuvent être capturés de manière différente en fonction des usages mais on peut converger autour d’un modèle pivot 2ème approche : médiation sémantique (cf article de Menet) : DebugIT Hypothèse : SNOMED CT : réference terminology son utilisation dans les 2 approches+++ Il existe dans le monde une conceptualisation mature d’un problème de santé (périmètre et objectifs) Il existe une méthode pour la partager largement et vite EXEMPLE : CR anapath : collaboration CAP-CDC-NAACCR/ASIP Santé : IHE 68
. Mais il faut noter que la collecte de données pour un essai clinique est réalisée « en silo » sans véritable préoccupation de cohérence avec d’autres études. Dans le domaine de la coordination des soins, des mécanismes similaires d’intégration de modèles de documents cliniques (basés sur le standard HL7 CDA) au sein de SIS peuvent s’envisager mais dans ce contexte il convient de prévoir la synchronisation des modèles de documents cliniques à intégrer avec ceux déjà utilisés au sein du SIS pour la collecte de données. La levée de ce verrou technologique est nécessaire au partage de données structurées et standardisées entre établissements de santé et a fortiori entre les établissements de santé et les structures de recherche ou les organismes de santé publique (objectif déjà atteint en ce qui concerne le PMSI). Progresser sur les concensus de conceptualisation de problème de santé. D’emblée envisager les dimensions d’évaluation des pratiques, d’épidémiologie et de recherche clinique (recherche translationnelle) Pragmatisme : s’appuyer sur les initiatives institutionnelles qui facilitent l’utilisation des standards et leur adoption par les acteurs de terrains qui heureusement convergent. Ex : NCI & ASIP Santé+++ La conceptualisation d’un domaine dépend-elle de l’activité Périmètre et objectif. 1ère approche : mettre en commun des modèles et ressources terminonologiques. Certainement vrai pour des données de base, pour des réferentiels (identification des PDS, des patients, des organismes+++: du coté des SI) – des médicaments+++ Minimum data set : peuvent être capturés de manière différente en fonction des usages mais on peut converger autour d’un modèle pivot. 2ème approche : médiation sémantique (cf article de Menet) : DebugIT. Hypothèse : SNOMED CT : réference terminology son utilisation dans les 2 approches+++ Il existe dans le monde une conceptualisation mature d’un problème de santé (périmètre et objectifs) Il existe une méthode pour la partager largement et vite. EXEMPLE : CR anapath : collaboration CAP-CDC-NAACCR/ASIP Santé : IHE. 68.")
69
Des conditions d’opérationnalisation
Maintenir les référentiels CCAM CIM 10 MeSH LOINC SNOMED Jan Fev Mar Avr Mai Jun Jui Aou Sep Oct Nov Dec Formulaires utilisables CR-ACP 69

70
ASIP Santé - “Info-structure” Plateforme collaborative de production et de distribution de référentiels d’interopérabilité sémantique Services génériques classiques Communication (liste de diffusion, notification, agendas partagés, etc) Accès et de partage de documents et fichiers ayant des formats usuels (word, pdf, excel, etc) édition partagée, la gestion de version, etc
 Accès et de partage de documents et fichiers ayant des formats usuels (word, pdf, excel, etc) édition partagée, la gestion de version, etc.")
71
ASIP Santé - “Info-structure” Plateforme collaborative de production et de distribution de référentiels d’interopérabilité sémantique Services et outils spécifiques issus de la recherche Outils d’ingénierie des modèles: éditeur collaboratif de “templates” CDA (MIF) Open Medical Development Framework (OMDF) (D.Ouagne) Outils d’ingénierie ontologique : éditeurs de terminologies (OWL, SKOS) et de jeux de valeurs, services de terminologie ITM (P-Y Vandenbusche)
 Open Medical Development Framework (OMDF) (D.Ouagne) Outils d’ingénierie ontologique : éditeurs de terminologies (OWL, SKOS) et de jeux de valeurs, services de terminologie. ITM (P-Y Vandenbusche)")
72
6ème règle : Des conditions d’adoption
L’interopérabilité sémantique c’est aussi économique, politique, déontologique, etc ! “May all of your problems being technical”! Nécessaire démarche de standardisation et de structuration des données cliniques selon des principes définis au sein de référentiels Questions légitimes d’ordre économique, éthique, déontologique COMME LE 6ème SENS Nécessaire démarche de standardisation et de structuration de la production de données cliniques (documents cliniques) selon des principes définis au sein de référentiels pose des questions légitimes d’ordre économique, éthique, déontologique qu’il convient de considérer et de traiter dans les cadres appropriés qui ne sont pas celui de la maitrise d’œuvre d’une solution informatique
 selon des principes définis au sein de référentiels pose des questions légitimes d’ordre économique, éthique, déontologique qu’il convient de considérer et de traiter dans les cadres appropriés qui ne sont pas celui de la maitrise d’œuvre d’une solution informatique.")
73
Interopérabilité sémantique & médecine translationnelle
Recherche clinique & épidémiologique

74
Intégration systèmes d’information cliniques/de la recherche “De l’incantation à l’action”
Enquête en ligne auprès des 50 membres du “Clinical Research Forum” sur l’utilisation des SI cliniques en recherche (2005/2007) 19 réponses (37%) L’importance des SIC pour la recherche biomédicale est reconnue mais pas d’intégration opérationnelle Les institutions ne sont pas en capacité de construire et maintenir les solutions répondant aux besoins exprimés Data on the state of information systems infrastructures used in the clinical research enterprise of academic medical centers are limited and mostly anecdotal. What has been published is slowly beginning to make important distinctions, such as clinical trials as a specialized form of clinical research and between "Informatics" in an academic setting from health care information technology. However, this field continues to undergo fundamental changes, accelerated by the National Institutes of Health's creation of Clinical and Translational Science Awards to build a new "home" for biomedical research. METHODS: We surveyed all Clinical Research Forum member institutions regarding their enterprise infrastructure and use of information systems in support of clinical research. The questions in this on-line study expanded on one first done in Of the 52 sites invited, 19 (37%) responded. We analyzed the responses and also made matched comparisons for those organizations that participated in both surveys. RESULTS: Although there continues to be conceptual agreement on information system elements for the clinical research enterprise, no single institution achieved the ideal, a similar result to the 2005 survey. Indeed, little progress was made over the past 2 years at most locations other than in information technology planning, strategy, and governance. CONCLUSIONS: There is increased recognition of the importance of information systems infrastructure and expertise for biomedical research, but the needs are accelerating much faster than institutions can build or pay for. A much greater realization of and innovative solution for this growing chasm is urgently required. DiLaura R, Turisco F, McGrew C, Reel S, Glaser J, Crowley WF Jr. Use of informatics and information technologies in the clinical research enterprise within US academic medical centers: progress and challenges from 2005 to J Investig Med Jun;56(5):770-9.
 19 réponses (37%) L’importance des SIC pour la recherche biomédicale est reconnue mais pas d’intégration opérationnelle. Les institutions ne sont pas en capacité de construire et maintenir les solutions répondant aux besoins exprimés. Data on the state of information systems infrastructures used in the. clinical research enterprise of academic medical centers are limited and mostly. anecdotal. What has been published is slowly beginning to make important. distinctions, such as clinical trials as a specialized form of clinical research. and between Informatics in an academic setting from health care information. technology. However, this field continues to undergo fundamental changes, accelerated by the National Institutes of Health s creation of Clinical and. Translational Science Awards to build a new home for biomedical research. METHODS: We surveyed all Clinical Research Forum member institutions regarding. their enterprise infrastructure and use of information systems in support of. clinical research. The questions in this on-line study expanded on one first done. in Of the 52 sites invited, 19 (37%) responded. We analyzed the responses. and also made matched comparisons for those organizations that participated in. both surveys. RESULTS: Although there continues to be conceptual agreement on. information system elements for the clinical research enterprise, no single. institution achieved the ideal, a similar result to the 2005 survey. Indeed, little progress was made over the past 2 years at most locations other than in. information technology planning, strategy, and governance. CONCLUSIONS: There is. increased recognition of the importance of information systems infrastructure and. expertise for biomedical research, but the needs are accelerating much faster. than institutions can build or pay for. A much greater realization of and. innovative solution for this growing chasm is urgently required. DiLaura R, Turisco F, McGrew C, Reel S, Glaser J, Crowley WF Jr. Use of informatics and information technologies in the clinical research enterprise within US academic medical centers: progress and challenges from 2005 to J Investig Med Jun;56(5):")
75
“De l’incantation à l’action” Centres de recherche translationnelle
Plateformes d’informatique translationnelle First Summit on Clinical Research Informatics (CRI) (AMIA) 2010 “The need for effective information management is critical to the addressing the many challenges facing clinical research, and there has been a corresponding and rapid evolution of the biomedical informatics methods and tools specifically designed to address clinical research information management requirements.” Butte AJ. Translational bioinformatics: coming of age. J Am Med Inform Assoc 2008; 15: Friedman CP. A "fundamental theorem" of biomedical informatics. J Am Med Inform Assoc 2009; 16: Hersh W. A stimulus to define informatics and health information technology. BMC Medical Informatics and Decision Making 2009, 9:24. Kahn MG, Kaplan D, Sokol RJ, DiLaura RP. Configuration challenges: implementing translational research policies in electronic medical records. Acad Med 2007: 82:661-9.
 (AMIA) The need for effective information management is critical to the addressing the many challenges facing clinical research, and there has been a corresponding and rapid evolution of the biomedical informatics methods and tools specifically designed to address clinical research information management requirements. Butte AJ. Translational bioinformatics: coming of age. J Am Med Inform Assoc 2008; 15: Friedman CP. A fundamental theorem of biomedical informatics. J Am Med Inform Assoc 2009; 16: Hersh W. A stimulus to define informatics and health information technology. BMC Medical Informatics and Decision Making 2009, 9:24. Kahn MG, Kaplan D, Sokol RJ, DiLaura RP. Configuration challenges: implementing translational research policies in electronic medical records. Acad Med 2007: 82:")
76
Enjeux de la recherche clinique
NCE : New Chemical Entities

77
Enjeux de la recherche clinique
Augmenter les capacités de développement initial Phase I Phase II Phase III rejection Augmenter le nombre de nouveaux médicaments approuvés Accélérer la mise sur le marché Limiter le coût Eviter les échecs tardifs Ian Ferrier, PhD Recrutement des patients Seulement 7% des patients éligibles sont inclus dans les essais cliniques Dans 86% des essais cliniques les inclusions ne se font pas à temps Les femmes, minorités, enfants sont sous-représentés Capture de données Dossier Patient Informatisé contiennent 30% à 50% des items de recherche clinique Déclaration spontanée d’évènements indésirables

78
Intégrer les Systèmes d’Information cliniques/de recherche clinique
Analyser la faisabilité d’un essai clinique Faciliter la participation des patients Seulement 7% des patients éligibles étaient recrutés Le patients ne sont pas recrutés à temps dans 86% des essais cliniques Les femmes, les minorités, les enfants sont sous représentés Faciliter la collecte des données DPI contiennent 30% to 50% des données collectées lors des essais cliniques Améliorer le signalement d’évènements indésirables d’origine médicamenteuse Seuls 7% des malades éligibles sont inclus dans un essai clinique Seuls 3% des médecins aux participent aux essais cliniques Individual Case Safety Report : EHR-based ICSR DPI : Facilite la déclaration, augmente la qualité des informations demandées, évite la double saisie Il faut aussi augmenter la reconnaissance / la déclaration De nombreux établissements de santé s’orientent vers cette direction (VA, Kaiser (EPIC), Group Health, Partners, Geisinger, etc) Kahn, Michael G. MD, PhD; Kaplan, David MD. Implementing Translational Research Policies in Electronic Medical Records. Academic Medicine. 82(7): , July 2007. Draft version 0.1, March 3, 2006;The eClinical Forum and PhaRMA EDC. The Future Vision of Electronic Health Records as eSource for Clinical Research
, Group Health, Partners, Geisinger, etc) Kahn, Michael G. MD, PhD; Kaplan, David MD. Implementing Translational Research Policies in Electronic Medical Records. Academic Medicine. 82(7): , July Draft version 0.1, March 3, 2006;The eClinical Forum and PhaRMA EDC. The Future Vision of Electronic Health Records as eSource for Clinical Research.")
79
“Standardiser les standards”
CDISC HL7

80
CDISC (Clinical Data Interchange Standards Consortium)
Organisation internationale créée en 1997 liée à l’ISO TC 215 accord avec HL7 depuis 2001 Standards de données de la recherche clinique régulée par les agences règlementaires pour l’acquisition, l’échange, l’archivage, la soumission de données électroniques 80

81
CDISC ODM (Operational data Model)
Structure standard d’acquisition, d’échange et d’archivage de données de recherche clinique au sein de bases de données opérationnelles Quatre niveaux principaux : étude, méta données, données administratives, et données à archiver SubjectData StudyEventData FormData ItemGroupData ItemData StudyEventDef FormDef ItemGroupDef ItemDef CodeListDef Meta données Données 1:N N:M MeasurementUnit RangeCheck Protocol AuditRecord To capture and exchange CRF data with a full audit trail To import from LAB and other data sources during a trial To provide a human readible and system independent data archive Can be a model for an opera-tional database (CDM or EDC)
")
82
eCRF généré automatiquement à partir du fichier CDISC ODM
Visites=Events Groupe d‘items Formulaires Items

83
CDISC ODM : structure Ex: Pression artérielle systolique
Item definition including CDASH normalized data structures <ItemDef DataType="integer" Length="3" Name="PA systolique" OID="ID.PA_SYSTOLIQUE"> <Question> <TranslatedText xml:lang="fr">Pression Artérielle Systolique</TranslatedText> </Question> <MeasurementUnitRef MeasurementUnitOID="MU.MMHG" /> <Alias Context="CDASH" Name=“VS.VSORRES (where VS.VSTEST=systolic blood pressure)" /> </ItemDef> Item group definition & item references <ItemGroupDef Name="Bilan commun" OID="IG.BILAN_COMMUN" Repeating="No"> <Description> <TranslatedText xml:lang="fr">Bilan commun </TranslatedText> </Description> <ItemRef ItemOID="ID.POIDS" Mandatory="Yes" /> <ItemRef ItemOID="ID.TAILLE" Mandatory="Yes" /> <ItemRef ItemOID="ID.PA_SYSTOLIQUE" Mandatory="Yes" /> </ItemGroupDef> Clinical Data Acquisition Standards Harmonization (CDASH) <ItemDef DataType="partialDate" Name="Birthday" OID="ID.BIRTHYEAR"> <Description> <TranslatedText xml:lang="fr"> Annee de naissance </TranslatedText> </Description> <Question> <TranslatedText xml:lang="fr"> Annee de naissance </TranslatedText> </Question> <Alias Context="CDASH" Name="BRTHYR" /> </ItemDef> 83
 /> </ItemDef> Item group definition & item references. <ItemGroupDef Name= Bilan commun OID= IG.BILAN_COMMUN Repeating= No > <Description> <TranslatedText xml:lang= fr >Bilan commun </TranslatedText> </Description> <ItemRef ItemOID= ID.POIDS Mandatory= Yes /> <ItemRef ItemOID= ID.TAILLE Mandatory= Yes /> <ItemRef ItemOID= ID.PA_SYSTOLIQUE Mandatory= Yes /> </ItemGroupDef> Clinical Data Acquisition Standards Harmonization (CDASH) <ItemDef DataType= partialDate Name= Birthday OID= ID.BIRTHYEAR > <Description> <TranslatedText xml:lang= fr > Annee de naissance. </TranslatedText> </Description> <Question> <TranslatedText xml:lang= fr > Annee de naissance </TranslatedText> </Question> <Alias Context= CDASH Name= BRTHYR /> </ItemDef> 83.")
84
CDISC ODM – Vocabulaire Clinical Data Acquisition Standards Harmonization (CDASH)
Conçu pour standardiser les variables dans un certain nombre de domaines transversaux aux études CDASH Domain Variable Name Definition Demography BRTHYR/BRTHMO Year/Month of subject’s birth SEX Medical History MHTERM Medical condition or event. CMTRT Drug name CMSTDTC Date when the medication was first taken. Substance Use SUTRT The type of substance (e.g., TOBACCO, ALCOHOL, CAFFEINE, etc. Or CIGARETTES, CIGARS, COFFEE, etc.). VSORRES Result of the vital signs measurement as originally received or collected. VSORRESU Original units in which the data were collected. Lab Test Results LBDTC Date of sample collection. LBORRES Result of the measurement or finding LBORRESU Units in which the data were collected LBTEST Test or examination used to obtain the measurement or finding. ECG Test Results EGORRES Result of the measurement or finding a EGTEST
. VSORRES. Result of the vital signs measurement as originally received or collected. VSORRESU. Original units in which the data were collected. Lab Test Results. LBDTC. Date of sample collection. LBORRES. Result of the measurement or finding. LBORRESU. Units in which the data were collected. LBTEST. Test or examination used to obtain the measurement or finding. ECG Test Results. EGORRES. Result of the measurement or finding a. EGTEST.")
85
“Standardiser les standards”
CDISC HL7 RCRIM BRIDG model IHE QRPH Quality, Research, and Public Health HL7

86
“Standardiser les standards”
HL7 (UML) CDISC RIM Niveau d’Abstraction Modèles spécifiques ODM Modèles spécifiques HL7 CDA
 CDISC. RIM. Niveau d’Abstraction. Modèles spécifiques. ODM. Modèles spécifiques. HL7 CDA.")
87
“Standardiser les standards”
HL7 (UML) SHARE : bibliothèque de variables SI cliniques/de recheche clinique CDISC RIM Niveau d’Abstraction BRIDG Modèles spécifiques recherche clinique Modèles spécifiques HL7 CDA ODM
 SHARE : bibliothèque de variables SI cliniques/de recheche clinique. CDISC. RIM. Niveau d’Abstraction. BRIDG. Modèles spécifiques recherche clinique. Modèles spécifiques. HL7 CDA. ODM.")
88
Recherche clinique (CDISC)
Réutilisation des données cliniques Approche “Source unique” (RE-USE - A.Elfadly) Soin (HL7) Recherche clinique (CDISC) (1) Recherche de template (meta données) CDISC ODM file Hopital n°1 CRO n°1 (2) Template source Template Consumer Document Repository Document Source We defined the “Cross enterprise Template Sharing” (XTS) integration profile and used existing IHE “Cross enterprise Document Media interchange” (XDM) integration profile in order to implement the “single source” concept for the RE-USE project (figure 2). The XTS integration profile, allows the Clinical Data Management System (CDMS) of the clinical research organization, acting as “Template Source” to distribute the template of an eCRF to EHRs, acting as “Template Consumers” using the transaction “Distribute Template”. This transaction is based on the transaction “Distribute Document Set on Media [ITI-32]” of the IHE XDM integration profile. The media is USB, CD-R or ZIP file sent via a secure message. Clinical research templates were implemented using CDISC ODM standard. The EHR (“Template Consumer”) receives the template. The “DxSync” process relying on the semantic interoperability framework is used to integrate the ODM file of the eCRF in the EHR. For each patient involved in the study, instances of eCRFs are stored in EHR. During the clinical trial, the IHE XDM or XDS integration profiles allow the EHR, acting as a “Document Source” to exchange/share case report documents of clinical trials with the CDMS, acting as a “Document Consumer”. Instances of eCRF were encoded using CDISC ODM standard to be shared or exchanged. “Single source” solution. The template of the eCRF is distributed by the clinical research organization to healthcare facilities to be implemented in EHRs. Data are exchanged/shared using IHE cross enterprise integration profiles (XDM, XDS). (3) Echange/partage de document (meta données + données) CDISC ODM El Fadly N, Lucas N, Lastic P-Y, Verplancke P, Daniel C.The REUSE project: EHR as single datasource for biomedical research. Medinfo
 Soin (HL7) Recherche clinique (CDISC) (1) Recherche de template. (meta données) CDISC ODM file. Hopital n°1. CRO n°1. (2) Template source. Template Consumer. Document Repository. Document Source. We defined the Cross enterprise Template Sharing (XTS) integration profile and used existing IHE Cross enterprise Document Media interchange (XDM) integration profile in order to implement the single source concept for the RE-USE project (figure 2). The XTS integration profile, allows the Clinical Data Management System (CDMS) of the clinical research organization, acting as Template Source to distribute the template of an eCRF to EHRs, acting as Template Consumers using the transaction Distribute Template . This transaction is based on the transaction Distribute Document Set on Media [ITI-32] of the IHE XDM integration profile. The media is USB, CD-R or ZIP file sent via a secure message. Clinical research templates were implemented using CDISC ODM standard. The EHR ( Template Consumer ) receives the template. The DxSync process relying on the semantic interoperability framework is used to integrate the ODM file of the eCRF in the EHR. For each patient involved in the study, instances of eCRFs are stored in EHR. During the clinical trial, the IHE XDM or XDS integration profiles allow the EHR, acting as a Document Source to exchange/share case report documents of clinical trials with the CDMS, acting as a Document Consumer . Instances of eCRF were encoded using CDISC ODM standard to be shared or exchanged. Single source solution. The template of the eCRF is distributed by the clinical research organization to healthcare facilities to be implemented in EHRs. Data are exchanged/shared using IHE cross enterprise integration profiles (XDM, XDS). (3) Echange/partage de document. (meta données + données) CDISC ODM. El Fadly N, Lucas N, Lastic P-Y, Verplancke P, Daniel C.The REUSE project: EHR as single datasource for biomedical research. Medinfo")
89
Processus de synchronisation (DxSync) (cadre d’intéropérabilité sémantique)
Synchronisation des variables (recherche clinique/soin) lors de l’intégration du formulaire
 lors de l’intégration du formulaire.")
90
Capture de données Réutilisation des données du DPI
Le pré-remplissage du formulaire repose sur les mécanismes internes du DPI Visite “Poids actuel” : 78 kg 90

91
Capture de données Réutilisation des données du DPI
Arcadia “Dernier poids connu” : 78 kg Daniel - Le Bozec C, Steichen O, Dart T, Jaulent M-C. The role of local terminologies in electronic health records. The HEGP experience. Stud Health Technol Inform. 2007;129:780-4.

92
Export des données vers la base de données de recherche clinique
La validation des données est réalisée au sein de la base de données de recherche clinique 92

93
Perspective: de RE-USE à EHR4CR (call IMI 2009)
Soin (HL7) Recherche clinique (CDISC) RE-USE Preuve de concept “1 hopital - 1 promotteur” Hospital n°1 CRO n°1 CDMS EHR Hospital n°2 The RE-USE architecture was used to design a single source solution assessed in the real settings of the ARCADIA clinical trial in G.Pompidou hospital (AP-HP) The Cross Enterprise Template Sharing (XTS) a standard-based integration profile was used to integrate in EHR the CDISC-ODM templates corresponding to the seven eCRF of the ARCADIA trial An interoperability framework using SNOMED International v3.5 supports the mapping between EHR proprietary models & CDISC-ODM models Current status Many pilot projects have implemented different types of EHR/CDMS integration solutions Usually institution-specific approaches that do not use standards and thus lack the broad interoperability required for multicenter trials … plateforme utilisable et extensible EHR4CR EHR CRO n°X CDMS Hoppital n°X EHR 93
 Recherche clinique (CDISC) RE-USE. Preuve de concept. 1 hopital - 1 promotteur Hospital n°1. CRO n°1. CDMS. EHR. Hospital n°2. The RE-USE architecture was used to design a single source solution assessed in the real settings of the ARCADIA clinical trial in G.Pompidou hospital (AP-HP) The Cross Enterprise Template Sharing (XTS) a standard-based integration profile was used to integrate in EHR the CDISC-ODM templates corresponding to the seven eCRF of the ARCADIA trial. An interoperability framework using SNOMED International v3.5 supports the mapping between EHR proprietary models & CDISC-ODM models. Current status. Many pilot projects have implemented different types of EHR/CDMS integration solutions. Usually institution-specific approaches that do not use standards and thus lack the broad interoperability required for multicenter trials. … plateforme utilisable et extensible. EHR4CR. EHR. CRO n°X. CDMS. Hoppital n°X. EHR. 93.")
94
L’interopérabilité sémantique pour la médecine translationnelle
Epidémiologie, veille sanitaire

95
Agrégation de données cliniques DebugIT (R. Choquet, D. Ouagne, A
Agrégation de données cliniques DebugIT (R.Choquet, D.Ouagne, A.Assele, N.Douali) DebugIT (Detecting and Eliminating Bacteria UsinG Information Technology)(FP7-ICT « Patient Safety ») Plateforme Européenne d’informatique translationnelle dédiée aux maladies infectieuses Intégrer des données hétérogènes distribuées au sein de Systèmes d’Information Cliniques Surveillance de l’antibiorésistance, fouille de données, alertes, aide à l’antibiothérapie This work has been done in the framework of the DebugIT project. The aim of this European project is to build a translational informatics platform dedicated to infectious diseases and antibioresistance The DebugIT platform integrates data from different European Clinical Data Repositories (CDR) which therefore become accessible for healthcare surveillance, datamining, knowledge discovery and decision support. Schober D, Boeker M, Daniel C, Bullenkamp J. The DebugIT Core Ontology: semantic integration of antibiotics resistance patterns. Medinfo Schulz S, Schober D, Daniel C, Jaulent MC. Bridging the semantics gap between terminologies, ontologies, and information models. Medinfo Choquet R, Qouiyd S, Ouagne D, Pasche E, Daniel C, Boussaid O, Jaulent MC. The Information Quality Triangle: a methodology to assess Clinical Information quality. Medinfo Ouagne D, Nadah N, Schober D, Choquet R, Teodoro D, Colaert D, Schulz S, Jaulent MC, Daniel C. Ensuring HL7-based information model requirements within an ontology framework. Medinfo
 DebugIT (Detecting and Eliminating Bacteria UsinG Information Technology)(FP7-ICT « Patient Safety ») Plateforme Européenne d’informatique translationnelle dédiée aux maladies infectieuses. Intégrer des données hétérogènes distribuées au sein de Systèmes d’Information Cliniques. Surveillance de l’antibiorésistance, fouille de données, alertes, aide à l’antibiothérapie. This work has been done in the framework of the DebugIT project. The aim of this European project is to build a translational informatics platform dedicated to infectious diseases and antibioresistance The DebugIT platform integrates data from different European Clinical Data Repositories (CDR) which therefore become accessible for healthcare surveillance, datamining, knowledge discovery and decision support. Schober D, Boeker M, Daniel C, Bullenkamp J. The DebugIT Core Ontology: semantic integration of antibiotics resistance patterns. Medinfo Schulz S, Schober D, Daniel C, Jaulent MC. Bridging the semantics gap between terminologies, ontologies, and information models. Medinfo Choquet R, Qouiyd S, Ouagne D, Pasche E, Daniel C, Boussaid O, Jaulent MC. The Information Quality Triangle: a methodology to assess Clinical Information quality. Medinfo Ouagne D, Nadah N, Schober D, Choquet R, Teodoro D, Colaert D, Schulz S, Jaulent MC, Daniel C. Ensuring HL7-based information model requirements within an ontology framework. Medinfo")
96
Utiliser les ontologies et les technologies du Web sémantique pour intégrer des données de santé
SPARQL (SPARQL Protocol and RDF Query Language), une technologie du Web sémantique permettant d’interroger des bases de données dont les données sont vues comme des triplets RDF (Resource Description Framework) e.g “Quel était le pourcentage d’isolats d’E.Coli resistants au TMP/SMX en 2008”? In the DebugIT project we use the query language SPARQL (SPARQL Protocol and RDF Query Language), which is a key semantic web technology to express queries across diverse data sources in which the data are not stored as RDF triples but can be viewed as RDF via a middleware Queries performed using the platform are for example related to Resistance of isolates to specific antibiotics e.g “What percentage of E.Coli cases are resistant to TMP/SMX in 2008”? Hypothesis : A formal representation of the operational CDR (“mapping ontology” or “information model ontology”) instantiated by information entities of the CDR and linked in its turn to the more abstract formal representation (DebugIT ontologies) supports and enhances the mapping process To enable the use of SPARQL end-points, the interoperability platform relies on mappings between non-formal CDRs and DebugIT ontologies Integrating information models & ontologies an RDF query language; its name is a recursive acronym that stands for SPARQL Protocol and RDF Query Language. It was standardized by the RDF Data Access Working Group (DAWG) of the World Wide Web Consortium, and is considered a key semantic web technology. On 15 January 2008, SPARQL became an official W3C Recommendation. [2] RDF is a directed, labeled graph data format for representing information in the Web. This specification defines the syntax and semantics of the SPARQL query language for RDF. SPARQL can be used to express queries across diverse data sources, whether the data is stored natively as RDF or viewed as RDF via middleware. SPARQL contains capabilities for querying required and optional graph patterns along with their conjunctions and disjunctions. SPARQL also supports extensible value testing and constraining queries by source RDF graph. The results of SPARQL queries can be results sets or RDF graphs. DebugIT (Detecting and Eliminating Bacteria UsinG Information Technology, FP7 project)) Most rely on local clinical data repositories based on proprietary data models and are facing major semantic interoperability issues Healthcare surveillance systems L'objectif principal du projet DebugIT (Detecting and Eliminating Bacteria UsinG Information Technology, 7ème programme cadre (FP7-ICT « Patient Safety ») est de construire un système d'information de veille sanitaire dans le domaine des maladies infectieuses et particulièrement de l’emergeance des résistances aux antibiotiques en Europe afin d'en aider le contrôle par l'optimisation des prescriptions d'antibiotiques (Lovis, 2008). L'architecture proposée doit permettre le partage de grands volumes de données cliniques hétérogènes et distribuées pour en faciliter l'analyse en utilisant des techniques de fouille de données et finalement permettre l'utilisation de connaissances ainsi caractérisées au sein d'un système décisionnel. Interoperability platform able to share heterogeneous clinical data sets from different European hospitals for the monitoring and the control of infectious diseases and antimicrobial resistances. Le périmètre de cette plateforme d’informatique translationnelle est large puisqu’elle vise a contribuer à l’innovation (génération de nouvelles connaissances sur l’émergence de nouvelles résistances aux antibiotiques par l’application de techniques de fouille de données et d’images sur de grandes quantité de données cliniques multimédia issues de dossiers patients informatisés de différents pays Européens), leur validation (mesure de l’impact de facteurs d’emergence identifiés) et leur adoption (utilisation de ces nouvelles connaissances modifier les politiques locales d’antibiothérapie). La plateforme d’informatique translationnelle Européenne DebugIT comporte un prototype de plateforme d’interopérabilité sémantique basée sur le langage d’interrogation SPARQL opérant sur des « SPARQL endpoints » installés au niveau des systèmes d’informations cliniques distribués permettant l’intégration de données cliniques hétérogènes saisies par les cliniciens dans le domaine de l’antibiorésistance dans les différents hôpitaux Européens partenaires du projet. La plateforme d’interopérabilité DebugIT offre aux épidémiologistes une solution d’interrogation et de fouille de données cliniques multimédia des différents hôpitaux Européens. La plateforme comporte des modules de création de base de connaissances destinés aux experts du domaine et d’aide à la décision en antibiothérapie destinés aux cliniciens. L’ontologie de domaine (DebugIT core ontology) est utilisée à la fois pour l’interrogation de sources de données cliniques distribuées et pour l’élaboration de règles diagnostiques ou thérapeutiques au sein de DPI. Semantic Web technologies are used to aggregate and query heterogeneous distributed clinical data in a unified view via ontologies This can be realized in a direct way by means of a 'mapping ontology', a formal representation of the operational repository matching 1-1, which in its turn is linked to the more abstract formal representation, e.g. the DCO. Another way of mapping is provided via clinical terminology/coding systems by linking e.g. SNOMED CT or ICD-10 codes to the classes an properties in the DebugIT ontologies. Concerning semantic interoperability, to enable the use of SPARQL end-points (see WP5) for direct querying of non-formal CDRs, mappings between the latter and ontologies have to be made. This mapping requires the CDR to contain structured data, not only free text. We have been able to express SPARQL queries onto this CDR that did match with the competencies questions Q5 and Q6: Although we prefer fully formalized resources, also databases can be referenced and just-in-time be queried via a SPARQL end-point, and do not need to be "owl-ized", i.e. transformed into an ontology, using the RDF(S) and OWL ontologies and declared in RDF/XML. Q6: What percentage of E.Coli cases are resistant to fluoroquinolones ? Q5: What percentage of E.Coli cases are resistant to TMP/SMX and TMP ? proprietary information models and domain ontologies. A challenging issue is to ease the querying process between 2http:// 1http:// Indeed, it seems easier, as a first step, to map proprietary information models to “mediator” ontologies that are done in a second step [2] in order to improve the coverage of ontology to an information model ontology has then to be instantiated by information entities. The binding of a domain This paper describes the domain ontology.
, une technologie du Web sémantique permettant d’interroger des bases de données dont les données sont vues comme des triplets RDF (Resource Description Framework) e.g Quel était le pourcentage d’isolats d’E.Coli resistants au TMP/SMX en 2008 In the DebugIT project we use the query language SPARQL (SPARQL Protocol and RDF Query Language), which is a key semantic web technology to express queries across diverse data sources in which the data are not stored as RDF triples but can be viewed as RDF via a middleware. Queries performed using the platform are for example related to Resistance of isolates to specific antibiotics e.g What percentage of E.Coli cases are resistant to TMP/SMX in 2008 Hypothesis : A formal representation of the operational CDR ( mapping ontology or information model ontology ) instantiated by information entities of the CDR and linked in its turn to the more abstract formal representation (DebugIT ontologies) supports and enhances the mapping process. To enable the use of SPARQL end-points, the interoperability platform relies on mappings between non-formal CDRs and DebugIT ontologies. Integrating information models & ontologies. an RDF query language; its name is a recursive acronym that stands for SPARQL Protocol and RDF Query Language. It was standardized by the RDF Data Access Working Group (DAWG) of the World Wide Web Consortium, and is considered a key semantic web technology. On 15 January 2008, SPARQL became an official W3C Recommendation. [2] RDF is a directed, labeled graph data format for representing information in the Web. This specification defines the syntax and semantics of the SPARQL query language for RDF. SPARQL can be used to express queries across diverse data sources, whether the data is stored natively as RDF or viewed as RDF via middleware. SPARQL contains capabilities for querying required and optional graph patterns along with their conjunctions and disjunctions. SPARQL also supports extensible value testing and constraining queries by source RDF graph. The results of SPARQL queries can be results sets or RDF graphs. DebugIT (Detecting and Eliminating Bacteria UsinG Information Technology, FP7 project)) Most rely on local clinical data repositories based on proprietary data models and are facing major semantic interoperability issues. Healthcare surveillance systems. L objectif principal du projet DebugIT (Detecting and Eliminating Bacteria UsinG Information Technology, 7ème programme cadre (FP7-ICT « Patient Safety ») est de construire un système d information de veille sanitaire dans le domaine des maladies infectieuses et particulièrement de l’emergeance des résistances aux antibiotiques en Europe afin d en aider le contrôle par l optimisation des prescriptions d antibiotiques (Lovis, 2008). L architecture proposée doit permettre le partage de grands volumes de données cliniques hétérogènes et distribuées pour en faciliter l analyse en utilisant des techniques de fouille de données et finalement permettre l utilisation de connaissances ainsi caractérisées au sein d un système décisionnel. Interoperability platform able to share heterogeneous clinical data sets from different European hospitals for the monitoring and the control of infectious diseases and antimicrobial resistances. Le périmètre de cette plateforme d’informatique translationnelle est large puisqu’elle vise a contribuer à l’innovation (génération de nouvelles connaissances sur l’émergence de nouvelles résistances aux antibiotiques par l’application de techniques de fouille de données et d’images sur de grandes quantité de données cliniques multimédia issues de dossiers patients informatisés de différents pays Européens), leur validation (mesure de l’impact de facteurs d’emergence identifiés) et leur adoption (utilisation de ces nouvelles connaissances modifier les politiques locales d’antibiothérapie). La plateforme d’informatique translationnelle Européenne DebugIT comporte un prototype de plateforme d’interopérabilité sémantique basée sur le langage d’interrogation SPARQL opérant sur des « SPARQL endpoints » installés au niveau des systèmes d’informations cliniques distribués permettant l’intégration de données cliniques hétérogènes saisies par les cliniciens dans le domaine de l’antibiorésistance dans les différents hôpitaux Européens partenaires du projet. La plateforme d’interopérabilité DebugIT offre aux épidémiologistes une solution d’interrogation et de fouille de données cliniques multimédia des différents hôpitaux Européens. La plateforme comporte des modules de création de base de connaissances destinés aux experts du domaine et d’aide à la décision en antibiothérapie destinés aux cliniciens. L’ontologie de domaine (DebugIT core ontology) est utilisée à la fois pour l’interrogation de sources de données cliniques distribuées et pour l’élaboration de règles diagnostiques ou thérapeutiques au sein de DPI. Semantic Web technologies are used to aggregate and query heterogeneous distributed clinical data in a unified view via ontologies. This can be realized in a direct way by means of a mapping ontology , a formal representation of the operational repository matching 1-1, which in its turn is linked to the more abstract formal representation, e.g. the DCO. Another way of mapping is provided via clinical terminology/coding systems by linking e.g. SNOMED CT or ICD-10 codes to the classes an properties in the DebugIT ontologies. Concerning semantic interoperability, to enable the use of SPARQL end-points (see WP5) for direct querying of non-formal CDRs, mappings between the latter and ontologies have to be made. This mapping requires the CDR to contain structured data, not only free text. We have been able to express SPARQL queries onto this CDR that did match with the competencies questions Q5 and Q6: Although we prefer fully formalized resources, also databases can be referenced and just-in-time be queried via a SPARQL end-point, and do not need to be owl-ized , i.e. transformed into an ontology, using the RDF(S) and OWL ontologies and declared in RDF/XML. Q6: What percentage of E.Coli cases are resistant to fluoroquinolones Q5: What percentage of E.Coli cases are resistant to TMP/SMX and TMP proprietary information models and domain ontologies. A challenging issue is to ease the querying process between. 2http:// 1http:// Indeed, it seems easier, as a first step, to map proprietary. information models to mediator ontologies that are. done in a second step [2] in order to improve the coverage of. ontology to an information model ontology has then to be. instantiated by information entities. The binding of a domain. This paper describes. the domain ontology.")
97
Utiliser les ontologies pour intégrer des données de santé
Pourcentage d’isolats d’E.Coli resistants aux fluoroquinolones en 2008 ? Fluoroquinolones Ontologies de domaine Peflacine Oflocet We applied a 3 steps methodology. First we used OMDF to mine in HL7 v3 models, relevant models with regards to this conceptual scope of the project, to import these models and to merge them and adapt them in order to build the HL7-based DebugIT information model. Then we transformed this IM in an OWL. And then, we are currently working on integrating concepts defining information artifacts in the DebugIT Core Ontology used to express the clinical queries. Ontologie d’objets d’information HL7 CDR

98
Ingénierie des modèles OMDF (D.Ougane)
Méta modèle HL7 (UML) Ontologies (OWL) Ontologie du RIM RIM Niveau d’Abstraction Ontologies spécifiques d’objets d’information Modèles spécifiques (e.g laboratoire, prescription médicamenteuse)
 Ontologies. (OWL) Ontologie du RIM. RIM. Niveau d’Abstraction. Ontologies spécifiques d’objets d’information. Modèles spécifiques (e.g laboratoire, prescription médicamenteuse)")
99
Résultats : Antibioresistance d’E.coli / fluoroquinolones (2008)
here you’ve got the status of resistance of E.coli isolates versus fluoroquinolones in the 4 hospitals involved in the project

100
Conclusion L’intéropérabilité sémantique en santé est un enjeu
Des solutions existent qui ont déjà apporté des résultats Merci pour votre attention ! Cap de Bonne Espérance, Medinfo 2010

101
PathLex Terminologie d’interface multilingue dans le domaine de l’anatomie pathologique “Une étoile filante dans la galaxie SNOMED”

102
PathLex -> SNOMED CT
Grammaire compositionnelle permettant le codage d’expressions complexe E.g : |oophorectomy| |method|= |laser excision – action|, |procedure site|= |structure of right ovary| Shooting / falling star in the SNOMED CT galaxy

103
PathLex : Uniformisation des jeux de valeurs (LexWiki)
UV US FR IT SP

104
CDASH > Présentation
OID Name CDASH Alias Name Codelist Domain CDASH Core SDTM Common_1_ Sponsor SPONSOR Common Optional - Description: A unique identifier for a study sponsor. An individual, company, institution, or organization that takes responsibility for the initiation and management of a clinical trial, although may or may not be the main funding organization. If there is also a secondary sponsor, this entity would be considered the primary sponsor. A corporation or agency whose employees conduct the investigation is considered a sponsor and the employees are considered investigators. Question: Completion instructions: Not applicable Info. for Sponsors: This is typically pre-printed. May be used as an identifier in external data warehouses (e.g. Janus) and in electronic medical records or other partnerships for sharing data. Not an SDTM variable. Common_2_ Protocol/Study STUDYID Highly Recommended Unique identifier for a study. Not applicable. This is typically pre-printed/pre-populated. Common_4_ Subject SUBJID Subject identifier for the study. Record the identifier for the subject. Paper: This is typically recorded in the header of each CRF page. EDC: The subject identifiers may be provided to the site using a pre-populated list in the system.
 and in electronic medical records or other partnerships for sharing data. Not an SDTM variable. Common_2_ Protocol/Study. STUDYID. Highly Recommended. Unique identifier for a study. Not applicable. This is typically pre-printed/pre-populated. Common_4_ Subject. SUBJID. Subject identifier for the study. Record the identifier for the subject. Paper: This is typically recorded in the header of each CRF page. EDC: The subject identifiers may be provided to the site using a pre-populated list in the system.")
105
CDASH > Présentation
ODM ItemDef OID Name CDASH Alias Name Codelist Domain CDASH Core SDTM Common_1_ Sponsor SPONSOR Common Optional - Description: A unique identifier for a study sponsor. An individual, company, institution, or organization that takes responsibility for the initiation and management of a clinical trial, although may or may not be the main funding organization. If there is also a secondary sponsor, this entity would be considered the primary sponsor. A corporation or agency whose employees conduct the investigation is considered a sponsor and the employees are considered investigators. Question: Completion instructions: Not applicable Info. for Sponsors: This is typically pre-printed. May be used as an identifier in external data warehouses (e.g. Janus) and in electronic medical records or other partnerships for sharing data. Not an SDTM variable. Common_2_ Protocol/Study STUDYID Highly Recommended Unique identifier for a study. Not applicable. This is typically pre-printed/pre-populated. Common_4_ Subject SUBJID Subject identifier for the study. Record the identifier for the subject. Paper: This is typically recorded in the header of each CRF page. EDC: The subject identifiers may be provided to the site using a pre-populated list in the system.
 and in electronic medical records or other partnerships for sharing data. Not an SDTM variable. Common_2_ Protocol/Study. STUDYID. Highly Recommended. Unique identifier for a study. Not applicable. This is typically pre-printed/pre-populated. Common_4_ Subject. SUBJID. Subject identifier for the study. Record the identifier for the subject. Paper: This is typically recorded in the header of each CRF page. EDC: The subject identifiers may be provided to the site using a pre-populated list in the system.")
106
CDASH > Présentation
ODM ItemDef CRF / e-CRF OID Name CDASH Alias Name Codelist Domain CDASH Core SDTM Common_1_ Sponsor SPONSOR Common Optional - Description: A unique identifier for a study sponsor. An individual, company, institution, or organization that takes responsibility for the initiation and management of a clinical trial, although may or may not be the main funding organization. If there is also a secondary sponsor, this entity would be considered the primary sponsor. A corporation or agency whose employees conduct the investigation is considered a sponsor and the employees are considered investigators. Question: Completion instructions: Not applicable Info. for Sponsors: This is typically pre-printed. May be used as an identifier in external data warehouses (e.g. Janus) and in electronic medical records or other partnerships for sharing data. Not an SDTM variable. Common_2_ Protocol/Study STUDYID Highly Recommended Unique identifier for a study. Not applicable. This is typically pre-printed/pre-populated. Common_4_ Subject SUBJID Subject identifier for the study. Record the identifier for the subject. Paper: This is typically recorded in the header of each CRF page. EDC: The subject identifiers may be provided to the site using a pre-populated list in the system.
 and in electronic medical records or other partnerships for sharing data. Not an SDTM variable. Common_2_ Protocol/Study. STUDYID. Highly Recommended. Unique identifier for a study. Not applicable. This is typically pre-printed/pre-populated. Common_4_ Subject. SUBJID. Subject identifier for the study. Record the identifier for the subject. Paper: This is typically recorded in the header of each CRF page. EDC: The subject identifiers may be provided to the site using a pre-populated list in the system.")
107
CDISC > CDASH dans le fichier ODM
<ItemDef DataType="partialDate" Name="Birthday" OID="ID.BIRTHYEAR"> <Description> <TranslatedText xml:lang="fr"> Annee de naissance </TranslatedText> </Description> <Question> <TranslatedText xml:lang="fr"> Annee de naissance </TranslatedText> </Question> <Alias Context="CDASH" Name="BRTHYR" /> </ItemDef>

108
CDISC > CDASH dans le fichier ODM
<ItemDef DataType="partialDate" Name="Birthday" OID="ID.BIRTHYEAR"> <Description> <TranslatedText xml:lang="fr"> Annee de naissance </TranslatedText> </Description> <Question> <TranslatedText xml:lang="fr"> Annee de naissance </TranslatedText> </Question> <Alias Context="CDASH" Name="BRTHYR" /> </ItemDef>

109
CDISC > CDASH dans le fichier ODM
<ItemDef DataType="partialDate" Name="Birthday" OID="ID.BIRTHYEAR"> <Description> <TranslatedText xml:lang="fr"> Annee de naissance </TranslatedText> </Description> <Question> <TranslatedText xml:lang="fr"> Annee de naissance </TranslatedText> </Question> <Alias Context="CDASH" Name="BRTHYR" /> </ItemDef> Identifiant de la variable dans le fichier ODM Ne doit pas obligatoirement provenir de CDASH (préfixe ID. par exemple)
")
110
CDASH > Présentation
Niveau de recommandation de la variable dans le CRF CDASH > Présentation OID Name CDASH Alias Name Codelist Domain CDASH Core SDTM Common_1_ Sponsor SPONSOR Common Optional - Description: A unique identifier for a study sponsor. An individual, company, institution, or organization that takes responsibility for the initiation and management of a clinical trial, although may or may not be the main funding organization. If there is also a secondary sponsor, this entity would be considered the primary sponsor. A corporation or agency whose employees conduct the investigation is considered a sponsor and the employees are considered investigators. Question: Completion instructions: Not applicable Info. for Sponsors: This is typically pre-printed. May be used as an identifier in external data warehouses (e.g. Janus) and in electronic medical records or other partnerships for sharing data. Not an SDTM variable. Common_2_ Protocol/Study STUDYID Highly Recommended Unique identifier for a study. Not applicable. This is typically pre-printed/pre-populated. Common_4_ Subject SUBJID Subject identifier for the study. Record the identifier for the subject. Paper: This is typically recorded in the header of each CRF page. EDC: The subject identifiers may be provided to the site using a pre-populated list in the system.
 and in electronic medical records or other partnerships for sharing data. Not an SDTM variable. Common_2_ Protocol/Study. STUDYID. Highly Recommended. Unique identifier for a study. Not applicable. This is typically pre-printed/pre-populated. Common_4_ Subject. SUBJID. Subject identifier for the study. Record the identifier for the subject. Paper: This is typically recorded in the header of each CRF page. EDC: The subject identifiers may be provided to the site using a pre-populated list in the system.")
111
CDASH > Présentation
OID Name CDASH Alias Name Codelist Domain CDASH Core SDTM Common_1_ Sponsor SPONSOR Common Optional - Description: A unique identifier for a study sponsor. An individual, company, institution, or organization that takes responsibility for the initiation and management of a clinical trial, although may or may not be the main funding organization. If there is also a secondary sponsor, this entity would be considered the primary sponsor. A corporation or agency whose employees conduct the investigation is considered a sponsor and the employees are considered investigators. Question: Completion instructions: Not applicable Info. for Sponsors: This is typically pre-printed. May be used as an identifier in external data warehouses (e.g. Janus) and in electronic medical records or other partnerships for sharing data. Not an SDTM variable. Common_2_ Protocol/Study STUDYID Highly Recommended Unique identifier for a study. Not applicable. This is typically pre-printed/pre-populated. Common_4_ Subject SUBJID Subject identifier for the study. Record the identifier for the subject. Paper: This is typically recorded in the header of each CRF page. EDC: The subject identifiers may be provided to the site using a pre-populated list in the system.
 and in electronic medical records or other partnerships for sharing data. Not an SDTM variable. Common_2_ Protocol/Study. STUDYID. Highly Recommended. Unique identifier for a study. Not applicable. This is typically pre-printed/pre-populated. Common_4_ Subject. SUBJID. Subject identifier for the study. Record the identifier for the subject. Paper: This is typically recorded in the header of each CRF page. EDC: The subject identifiers may be provided to the site using a pre-populated list in the system.")
112
CDASH > Présentation
Domaines CDASH OID Name CDASH Alias Name Codelist Domain CDASH Core SDTM Common_1_ Sponsor SPONSOR Common Optional - Description: A unique identifier for a study sponsor. An individual, company, institution, or organization that takes responsibility for the initiation and management of a clinical trial, although may or may not be the main funding organization. If there is also a secondary sponsor, this entity would be considered the primary sponsor. A corporation or agency whose employees conduct the investigation is considered a sponsor and the employees are considered investigators. Question: Completion instructions: Not applicable Info. for Sponsors: This is typically pre-printed. May be used as an identifier in external data warehouses (e.g. Janus) and in electronic medical records or other partnerships for sharing data. Not an SDTM variable. Common_2_ Protocol/Study STUDYID Highly Recommended Unique identifier for a study. Not applicable. This is typically pre-printed/pre-populated. Common_4_ Subject SUBJID Subject identifier for the study. Record the identifier for the subject. Paper: This is typically recorded in the header of each CRF page. EDC: The subject identifiers may be provided to the site using a pre-populated list in the system. Common (Common) Adverse Events (AE) Concomitant Medication (CM) Demographics (DM) Medical History (MH) Vital Signs (VS) Substance Use (SU) ECG (EG) Lab (LB) Subject Characteristic (SC) Inclusion and Exclusion Criteria (IE) Disposition (DS) Drug Accountability (DA) Exposure (EX) Protocol Deviations (DV) Physical Examination (PE)
 and in electronic medical records or other partnerships for sharing data. Not an SDTM variable. Common_2_ Protocol/Study. STUDYID. Highly Recommended. Unique identifier for a study. Not applicable. This is typically pre-printed/pre-populated. Common_4_ Subject. SUBJID. Subject identifier for the study. Record the identifier for the subject. Paper: This is typically recorded in the header of each CRF page. EDC: The subject identifiers may be provided to the site using a pre-populated list in the system. Common (Common) Adverse Events (AE) Concomitant Medication (CM) Demographics (DM) Medical History (MH) Vital Signs (VS) Substance Use (SU) ECG (EG) Lab (LB) Subject Characteristic (SC) Inclusion and Exclusion Criteria (IE) Disposition (DS) Drug Accountability (DA) Exposure (EX) Protocol Deviations (DV) Physical Examination (PE)")
113
CDASH > hiérarchisation
Dans dernière version en développement : MHOCCUR : Medical history occured HBP.MHOCCUR : High blood pressure (Y/N) APPENDECTOMY.MHOCCUR : Appendectomy (Y/N) SUNCF : Substance usage TOBACCO.CIGARETTES.SUNCF : Usage (Never/Current/Former) TOBACCO.CIGARS.SUNCF : Usage (Never/Current/Former) Précision de la variable par un préfixe, quelques cas prévus Probablement à entendre avec d’autres vocabulaires contrôlés
 APPENDECTOMY.MHOCCUR : Appendectomy (Y/N) SUNCF : Substance usage. TOBACCO.CIGARETTES.SUNCF : Usage (Never/Current/Former) TOBACCO.CIGARS.SUNCF : Usage (Never/Current/Former) Précision de la variable par un préfixe, quelques cas prévus. Probablement à entendre avec d’autres vocabulaires contrôlés.")
114
Collaboration HL7 établit des collaboration avec les organismes de standardisation internationaux d’informatique de santé et de recherche clinique (ISO, CEN, OMG, CDISC) Eviter les efforts redondants CDISC (Clinical Data Interchange Standards Consortium) Collaboration depuis 2002 Comité technique RCRIM Développement du modèle BRIDG modèle de domaine “Protocol- driven research and associated regulatory artifacts”
 Eviter les efforts redondants. CDISC (Clinical Data Interchange Standards Consortium) Collaboration depuis Comité technique RCRIM. Développement du modèle BRIDG modèle de domaine Protocol- driven research and associated regulatory artifacts")
115
Affichage de formulaires Serveur de formulaires
Réutilisation des données cliniques Approche 1 : Extraction de données IHE “Retrieve Form for Data Capture (RFD)” - Content profile “Clinical Research data Capture” EHR CDMS Affichage de formulaires Serveur de formulaires Among “source data extraction and verification” solutions, the Integrating the Healthcare Enterprise (IHE) published the Retrieve Form for Data-capture (RFD) "integration profile" An IHE "integration profile" is a real situation describing exchanges of information, called "transactions" of different components of a distributed health information system, called "actors". IHE provides guidelines for implementing these "transactions", using established computer standards such as HL7 or DICOM. .Combined with the Clinical Research Content Profile, this integration profile provides a method of data capture within a used application (e.g. an EHR) that meets the requirements of an external system (e.g. a CDMS). The RFD profile specifies a solution to integrate EHR and CDMS. If an external organization needs to collect clinical data as part of a clinical trial, the RFD profile will allow the EHR user (physician investigator, for example) to access to the electronic Case Report Form (eCRF) of the clinical trial without leaving the EHR, and enter the required information so that they are collected by the external agency. However this solution still constrains the clinician to provide and manage two distinct data sources, duplicating data entry from one to another except for only several items described in the Clinical Research Content Profile. IHE has successfully engaged the biopharmaceutical industry in the use of a content-free integration profile, RFD, to gather research data during an EHR session. Extending the reach of RFD by binding it to a clinical research specific content profile further reinforces the cross-industry alliance between healthcare and bio-pharma. This content profile will enable automatic population of RFD provided forms, resulting in greater data capture efficiencies between clinical trial sponsors, investigators and research sites. Leveraging existing or developing standards available from CDISC (SDTM, CDASH, ODM), the content standard will map the clinical research vocabularies to similar term definitions in the healthcare world. The CDISC community can provide content and resources to do the mapping. In fact, a trial implementation of RFD has begun this work already. Individuals from both the CDASH and Vocabulary projects are willing to contribute to this effort. Form Manager The Form Manager actor provides the store of forms ready for use by a Form Filler. Form Filler The Form Filler actor retrieves forms from a Form Manager as and when required. When requesting a form, the Form Filler actor can optionally provide context information by providing pre-population xml data in the request for use by the Form Manager. The Form Filler may also specify a Form Archiver actor. The Form Archiver actor specified by the Form Filler is in addition to any Form Archiver actors specified by the Form Manager. Transaction Definitions Retrieve Form The Retrieve Form transaction carries the form identifier from a Form Filler to a Form Manager. The transaction also allows a Form Filler to optionally specify a Form Archiver actor as well as optionally containing context information in the form of xml data to be used in the selection and pre-population of the requested form prior to the form being returned to the Form Filler. Form Filler Options CCD Option This option defines that the Form Filler can produce a valid CCD as content for the prepopulation data transaction as defined in RFD. This valid CCD will be further constrained in volume 2 of this profile. ODM/CDASH Option This option defines that the Form Filler can produce a valid CDASH encoded ODM as content for the prepopulation data transaction as defined in RFD. Form Manager Options This option defines that the Form Manager can recieve a valid CCD as content for the prepopulation data transaction as defined in RFD. This valid CCD will be further constrained in volume 2 of this profile. Note the reference implementation that then supports conversion of this CCD into ODM/CDASH. This option defines that the Form Manager can recieve a valid CDASH encoded ODM as content for the prepopulation data transaction as defined in RFD. Note the reference implementation will not apply to this option as no transform is needed. RFD permet de collecter durant une session au sien du DPI des données cliniques d’une étude. L’extension de RFD avec un profil de contenu permet la saisie automatique d’une partie des items de l’eCRF avec des données du DPI. Le profil de contenu fournit des propositions d’alignement entre des variables de recherche clinique (CDASH, ODM) et des variables similaires du DPI Rechercher et pré-remplir un formulaire
 - Content profile Clinical Research data Capture EHR. CDMS. Affichage de formulaires. Serveur de formulaires. Among source data extraction and verification solutions, the Integrating the Healthcare Enterprise (IHE) published the Retrieve Form for Data-capture (RFD) integration profile An IHE integration profile is a real situation describing exchanges of information, called transactions of different components of a distributed health information system, called actors . IHE provides guidelines for implementing these transactions , using established computer standards such as HL7 or DICOM. .Combined with the Clinical Research Content Profile, this integration profile provides a method of data capture within a used application (e.g. an EHR) that meets the requirements of an external system (e.g. a CDMS). The RFD profile specifies a solution to integrate EHR and CDMS. If an external organization needs to collect clinical data as part of a clinical trial, the RFD profile will allow the EHR user (physician investigator, for example) to access to the electronic Case Report Form (eCRF) of the clinical trial without leaving the EHR, and enter the required information so that they are collected by the external agency. However this solution still constrains the clinician to provide and manage two distinct data sources, duplicating data entry from one to another except for only several items described in the Clinical Research Content Profile. IHE has successfully engaged the biopharmaceutical industry in the use of a content-free integration profile, RFD, to gather research data during an EHR session. Extending the reach of RFD by binding it to a clinical research specific content profile further reinforces the cross-industry alliance between healthcare and bio-pharma. This content profile will enable automatic population of RFD provided forms, resulting in greater data capture efficiencies between clinical trial sponsors, investigators and research sites. Leveraging existing or developing standards available from CDISC (SDTM, CDASH, ODM), the content standard will map the clinical research vocabularies to similar term definitions in the healthcare world. The CDISC community can provide content and resources to do the mapping. In fact, a trial implementation of RFD has begun this work already. Individuals from both the CDASH and Vocabulary projects are willing to contribute to this effort. Form Manager. The Form Manager actor provides the store of forms ready for use by a Form Filler. Form Filler. The Form Filler actor retrieves forms from a Form Manager as and when required. When requesting a form, the Form Filler actor can optionally provide context information by providing pre-population xml data in the request for use by the Form Manager. The Form Filler may also specify a Form Archiver actor. The Form Archiver actor specified by the Form Filler is in addition to any Form Archiver actors specified by the Form Manager. Transaction Definitions. Retrieve Form. The Retrieve Form transaction carries the form identifier from a Form Filler to a Form Manager. The transaction also allows a Form Filler to optionally specify a Form Archiver actor as well as optionally containing context information in the form of xml data to be used in the selection and pre-population of the requested form prior to the form being returned to the Form Filler. Form Filler Options. CCD Option. This option defines that the Form Filler can produce a valid CCD as content for the prepopulation data transaction as defined in RFD. This valid CCD will be further constrained in volume 2 of this profile. ODM/CDASH Option. This option defines that the Form Filler can produce a valid CDASH encoded ODM as content for the prepopulation data transaction as defined in RFD. Form Manager Options. This option defines that the Form Manager can recieve a valid CCD as content for the prepopulation data transaction as defined in RFD. This valid CCD will be further constrained in volume 2 of this profile. Note the reference implementation that then supports conversion of this CCD into ODM/CDASH. This option defines that the Form Manager can recieve a valid CDASH encoded ODM as content for the prepopulation data transaction as defined in RFD. Note the reference implementation will not apply to this option as no transform is needed. RFD permet de collecter durant une session au sien du DPI des données cliniques d’une étude. L’extension de RFD avec un profil de contenu permet la saisie automatique d’une partie des items de l’eCRF avec des données du DPI. Le profil de contenu fournit des propositions d’alignement entre des variables de recherche clinique (CDASH, ODM) et des variables similaires du DPI. Rechercher et pré-remplir un formulaire.")
116
Réutilisation des données cliniques Approche 1 : Extraction de données
Pré-remplissage du formulaire de recherche clinique à partir des données cliniques Une fois rempli le formulaire de recherche clinique est stocké sous forme de document (pdf) dans le Dossier Patient Informatisé. Etudes pilotes le plus souvent mono-institutionnelles et ne reposant pas sur des standards bien établis. Trois approches d’intégration “Source data extraction and verification” Extraction de données et vérification par l’investigateur que ces données correspondent aux données requises dans le contexte de l’étude. Profil d’intégration IHE “Retrieve Form for Data Capture (RFD)” + profil de contenu “Clinical Research data Capture” “Single source” Capture des données de l’étude au sein du DPI et export vers la BD de recherche clinique “EHR used as CDMS” Capture des données de l’étude au sein du DPI qui est utilisé également comme BD de recherche clinique
 dans le Dossier Patient Informatisé. Etudes pilotes le plus souvent mono-institutionnelles et ne reposant pas sur des standards bien établis. Trois approches d’intégration. Source data extraction and verification Extraction de données et vérification par l’investigateur que ces données correspondent aux données requises dans le contexte de l’étude. Profil d’intégration IHE Retrieve Form for Data Capture (RFD) + profil de contenu Clinical Research data Capture Single source Capture des données de l’étude au sein du DPI et export vers la BD de recherche clinique. EHR used as CDMS Capture des données de l’étude au sein du DPI qui est utilisé également comme BD de recherche clinique.")
117
Clinical Research Data Capture Data Elements
Content profile “Clinical Research data Capture” Règles d’alignement HL7 CDA r2 <-> CDASH Clinical Research Data Capture Data Elements CDISC CDASH Domains HL7 CCD Reference Demography CCD Header Information Medical History Active Problems, Past Medical History, and Procedures and Interventions Concommitant Medication Current Medications Substance Use Social History Vital Signs Physical Exam Adverse Events Allergies Lab Test Results Coded Results ECG Test Results

118
BRIDG (Biomedical Research Integrated Domain Group)
HL7 s’intéresse aux modèles statiques et dynamiques en relation avec les processus Le protocole de spécification des messages ou documents HL7 exige une correspondance avec les activités des acteurs et les « interactions » définies entre ces acteurs Les modèles doivent avoir une sémantique commune CDISC s’intéresse (actuellement) aux modèles statiques Spécification des messages échangés entre les applications Objectifs de BRIDG Un modèle formel comportant des modèles statiques et dynamiques Une sémantique commune Source: Douglas B. Fridsma, Julie Evans, Charles N. Mead
 aux modèles statiques. Spécification des messages échangés entre les applications. Objectifs de BRIDG. Un modèle formel comportant des modèles statiques et dynamiques. Une sémantique commune. Source: Douglas B. Fridsma, Julie Evans, Charles N. Mead.")
119
Historique de BRIDG Début 2004, CDISC
Modèle d'analyse de domaine pour garantir l'harmonisation des standards de recherche clinique avec les standards HL7 de soin Fin 2004, NCI’s «Cancer Biomedical Informatics Grid (caBIG ™) Représentation structurée des protocoles pour les systèmes de gestion des essais cliniques en cancérologie En 2005, HL7 «Regulated Clinical Research Information Management (RCRIM TC) Adoption du modèle BRIDG afin de produire un modèle d’analyse de domaine En 2007, FDA BRIDG intégré à plusieurs projets du plan d’action à 5 ans Quatre grands flux de développement se sont réunis Représentation structurée des protocoles pour leurs systèmes de gestion des essais cliniques dans le domaine de la recherche sur le cancer. en cancérologie (CTMs), dans le but d’assurer l'interopérabilité entre les essais cliniques En 2005, le modèle GRIDG a été adopté par le comité technique «Regulated Clinical Research Information Management (RCRIM TC) » d’HL7 afin de produire un modèle d’analyse de domaine. En 2007, la FDA inclus BRIDG dans leur plan «5 years PDUFA IV IT» comme une base pour plusieurs projets. CDISC « Notre mission au CDISC est de développer et favoriser, à l'échelle mondiale, des normes de données indépendantes de plate-forme, permettant l'interopérabilité des systèmes d'information entre les sponsors, les partenaires et les fournisseurs, cela afin d'améliorer le processus de recherche clinique » NCI Biomedical Informatics Un réseau virtuel pour interconnecter des données, des personnes et des organisations afin de définir comment : Mener des essais clinique Dispenser des soins Les patients/participants et les entreprises de recherche biomédicale pourront collaborer. RCRIM Tous les messages HL7 développés par RCRIM seront représentés dans BRIDG FDA Plusieurs projets de la FDA, y compris les messages HL7/CDISC, seront basés sur la sémantique de BRIDG. NCI (caBIGTM) : Développement d’application + spécification de message L’application est développée dans un espace distribué, déployée en utilisant des services web assurant une exécution à la fois synchrone et asynchrone sur le réseau. L’application est nécessaire pour assurer l’interopérabilité sémantique calculable (statique et dynamique) Echange des structures statiques sémantiquement cohérentes Coordination des processus dynamiques (services) sémantiquement non ambigus Le NCI a adopté HL7 pour l’espace de travail d’essai clinique et travaille sur le déploiement d'une grande entreprise d’architecture orientée services Source: Douglas B. Fridsma, Julie Evans, Charles N. Mead
 Représentation structurée des protocoles pour les systèmes de gestion des essais cliniques en cancérologie. En 2005, HL7 «Regulated Clinical Research Information Management (RCRIM TC) Adoption du modèle BRIDG afin de produire un modèle d’analyse de domaine. En 2007, FDA. BRIDG intégré à plusieurs projets du plan d’action à 5 ans. Quatre grands flux de développement se sont réunis. Représentation structurée des protocoles pour leurs systèmes de gestion des essais cliniques dans le domaine de la recherche sur le cancer. en cancérologie (CTMs), dans le but d’assurer l interopérabilité entre les essais cliniques. En 2005, le modèle GRIDG a été adopté par le comité technique «Regulated Clinical Research Information Management (RCRIM TC) » d’HL7 afin de produire un modèle d’analyse de domaine. En 2007, la FDA inclus BRIDG dans leur plan «5 years PDUFA IV IT» comme une base pour plusieurs projets. CDISC. « Notre mission au CDISC est de développer et favoriser, à l échelle mondiale, des normes de données indépendantes de plate-forme, permettant l interopérabilité des systèmes d information entre les sponsors, les partenaires et les fournisseurs, cela afin d améliorer le processus de recherche clinique » NCI Biomedical Informatics. Un réseau virtuel pour interconnecter des données, des personnes et des organisations afin de définir comment : Mener des essais clinique. Dispenser des soins. Les patients/participants et les entreprises de recherche biomédicale pourront collaborer. RCRIM. Tous les messages HL7 développés par RCRIM seront représentés dans BRIDG. FDA. Plusieurs projets de la FDA, y compris les messages HL7/CDISC, seront basés sur la sémantique de BRIDG. NCI (caBIGTM) : Développement d’application + spécification de message. L’application est développée dans un espace distribué, déployée en utilisant des services web assurant une exécution à la fois synchrone et asynchrone sur le réseau. L’application est nécessaire pour assurer l’interopérabilité sémantique calculable (statique et dynamique) Echange des structures statiques sémantiquement cohérentes. Coordination des processus dynamiques (services) sémantiquement non ambigus. Le NCI a adopté HL7 pour l’espace de travail d’essai clinique et travaille sur le déploiement d une grande entreprise d’architecture orientée services. Source: Douglas B. Fridsma, Julie Evans, Charles N. Mead.")
120
BRIDG Separating Analysis from Design/Implementation
Modèle de l’espace de problème (HL7 Development Framework) Niveau d’Abstraction RIM / DMIM ODM RMIM / HMD / XSD
 Niveau d’Abstraction. RIM / DMIM. ODM. RMIM / HMD / XSD.")
121
Documentation du modèle BRIDG
BRIDG 3.0 is a restructuring of the semantics already in the BRIDG 2.2 model. The restructuring was done because domain experts found the earlier versions of the model increasingly harder to understand and because technical experts found it difficult to unambiguously map the BRIDG concepts to the HL7 Reference Information Model (RIM). To resolve those problems, BRIDG Release 3.0 introduces three layers: A sub-domain specific layer, allowing domain experts to see their semantics in the 5 user-friendly sub-domain models: Protocol Representation, Study Conduct, Adverse Event, Regulatory, Common; A comprehensive layer that combines all the sub-domains in a single view of the harmonized and shared semantics; A RIM-based layer that represents the BRIDG concepts but uses the RIM classes and HL7 diagrammatic representation for the HL7-savvy technical personnel. BRIDG 3.0 also includes tags on model elements identifying the source model element(s) from which they were derived, a revision to the Study Design portion of the model to make it more flexible, the adoption of a UML style guide, and an updated User's Guide. The BRIDG model consists of multiple layers that address the needs of both domain experts and technologists. In particular, there is an ‘upper layer’ of multiple sub‐domain models (e.g. Protocol Representation, Study Conduct, Adverse Event, and Common) in which each sub‐domain will be much more ‘user friendly,’ and a second, ‘lower’ level which will be a robust model with the appropriate conventions to ensure non‐ambiguous RIM mapping. In addition, a ‘middle layer’ has been added that shows the comprehensive view of the sub‐domain models. One of the components of this middle layer is an OWL representation of BRIDG. OWL (Web Ontology Language) is a knowledge representation language for authoring ontologies. OWL has been used to provide a means of validating the semantics of BRIDG against other ontologies (e.g., the HL7 Reference Information Model (RIM)). In addition, a published OWL version of BRIDG will also be maintained in the near future. Figure 1 below depicts this new Release 3.0+ approach.
. To resolve those problems, BRIDG Release 3.0 introduces three layers: A sub-domain specific layer, allowing domain experts to see their semantics in the 5 user-friendly sub-domain models: Protocol Representation, Study Conduct, Adverse Event, Regulatory, Common; A comprehensive layer that combines all the sub-domains in a single view of the harmonized and shared semantics; A RIM-based layer that represents the BRIDG concepts but uses the RIM classes and HL7 diagrammatic representation for the HL7-savvy technical personnel. BRIDG 3.0 also includes tags on model elements identifying the source model element(s) from which they were derived, a revision to the Study Design portion of the model to make it more flexible, the adoption of a UML style guide, and an updated User s Guide. The BRIDG model consists of multiple layers that address the needs of both domain experts and technologists. In particular, there is an ‘upper layer’ of multiple sub‐domain models (e.g. Protocol Representation, Study Conduct, Adverse Event, and Common) in which each sub‐domain will be much more ‘user friendly,’ and a second, ‘lower’ level which will be a robust model with the appropriate conventions to ensure non‐ambiguous RIM mapping. In addition, a ‘middle layer’ has been added that shows the comprehensive view of the sub‐domain models. One of the components of this middle layer is an OWL representation of BRIDG. OWL (Web Ontology Language) is a knowledge representation language for authoring ontologies. OWL has been used to provide a means of validating the semantics of BRIDG against other ontologies (e.g., the HL7 Reference Information Model (RIM)). In addition, a published OWL version of BRIDG will also be maintained in the near future. Figure 1 below depicts this new Release 3.0+ approach.")
122
Modèle du domaine compréhensible par les experts
Différents niveaux d’abstraction et d’explicitation dans de multiple sous-domaines Explicitaion au sein d’un seul modèle basé sur le RIM (‘Analysis Model’) Aligné sans ambiguité au RIM HL7
 Aligné sans ambiguité au RIM HL7.")
123
BRIDG 3.0 Sub domains Adverse Event Regulatory Common
Protocol Representation Study Conduct

124
AdverseEvent sub domain
Type: public Class {leaf} Extends: PerformedObservationResult. Package: Adverse Event Sub-Domain Any unfavorable and unintended sign, symptom, disease, or other medical occurrence with a temporal association with the use of a medical product, procedure or other therapy, or in conjunction with a research study, regardless of causal relationship. For example, death, back pain, headache, pulmonary embolism, heart attack.

125
AdverseEvent Attributes
Type Notes gradeCode public : CD A coded value specifying the level of injury suffered by the subject for whom the event is reported. For example, the gradeCode could be 3 if the CTCAE coding system is being used. Map:AE = 'AdverseEvent.gradeOrSeverity' Map:CTOM = 'AdverseEvent.ctcGradeCode' Map:CTOM = 'AdverseEvent.ctcGradeCodeSystem' Map:SDTM IG = 'AE.AETOXGR' severityCode A coded value specifying the intensity of the event.For example, moderate could be used to describe acne. Map:SDTM IG = 'AE.AESEV' seriousnessCode A coded value specifying the degree or extent of the consequence suffered by the subject. For example, resulted in death, required hospitalization, was life threatening. Map:AE = 'AdverseEvent.seriousnessCode' Map:CTOM = 'AdverseEvent.seriousReasonCode' Map:SDTM IG = 'AE.AESER' Map:SDTM IG = 'AE.AESHOSP'

126
AdverseEvent Attributes (suite)
Type Notes categoryCode public : CD A coded value specifying a classification of the adverse event.For example, bleeding, hypoglycemia.NOTE: Theoretically speaking, the category should be derivable from the subcategory, however if there may only be a category and not a subcategory, then both attributes must be present in the model. Map:SDTM IG = 'AE.AECAT' subcategoryCode A coded value specifying a subdivision within a larger category of an adverse event.For example, neurologic.NOTE: Theoretically speaking, the category should be derivable from the subcategory, however if there may only be a category and not a subcategory, then both attributes must be present in the model. Map:SDTM IG = 'AE.AESCAT' occurrencePatternCode A coded value specifying the time recurrence by which an adverse event occurs. For example, intermittent. Map:AE = 'AdverseEvent.patternCode' Map:CTOM = 'AdverseEvent.conditionPatternCode' Map:SDTM IG = 'AE.AEPATT'

127
PerformedObservation
Type: public Class {leaf}Extends: PerformedActivity. The completed action of observing, monitoring, measuring or otherwise qualitatively or quantitatively gathering data or information about one or more aspects of a subject's, study subject's or experimental unit's physiologic or psychologic state. For example, lab test, taking vital signs, physical exam, etc.

128
PerformedObservation Attributes
Type Notes methodCode public : DSET<CD> A coded value specifying the technique used to perform the observation.For example, blood pressure measurement method could be arterial puncture or sphygmomanometry.For example, global introspection, algorithm, bayesian to assess AE causality.For example for a clinical result assay method, values could include: Estrogen Receptor Assay, Progesterone Receptor Assay, p53 Assay, etc. Map:AE = 'PerformedProductInvestigation.evaluationMethodCode' Map:AE = 'CausalAssessment.methodCode' Map:CTOM = 'ClinicalResult.meansVitalStatusObtainedCode' Map:CTOM = 'ClinicalResult.assayMethodCode' Map:CTOM = 'ClinicalResult.labTechniqueCode' Map:CTOM = 'LesionDescription.methodCode' bodyPositionCode public : CD A coded value specifying the 3-dimensional spatial orientation of a subject during a particular observation.For example, supine, trendelenburg, standing, etc. AE:Exclude = 'True' Map:CTOM = 'ClinicalResult.bodyPositionCode' Map:PSC = 'VS.VSPOS' Map:SDTM IG = 'EG.EGPOS' targetAnatomicSiteCode A coded value specifying the anatomic location that is the focus of the observation.For example, gastrointestinal, cardiovascular. NOTE: The target site of the result may be different than the target site of the activity (PerformedObservation) that generated it. For example, a chest x-ray (observation) has the target site of chest while the result might show an infiltration in the left lower lobe of the lung (target site of result), or a dermatological exam may check the skin across the whole body (target site of observation) while the result might identify a rash on the right leg (target site of result). Map:AE = 'AdverseEvent.bodyLocation' Map:CTOM = 'Diagnosis.primaryAnatomicSiteCodeSystem' Map:CTOM = 'Imaging.anatomicSiteCodeSystem' Map:CTOM = 'Imaging.anatomicSiteCode' Map:CTOM = 'Diagnosis.primaryAnatomicSiteCode'
 that generated it. For example, a chest x-ray (observation) has the target site of chest while the result might show an infiltration in the left lower lobe of the lung (target site of result), or a dermatological exam may check the skin across the whole body (target site of observation) while the result might identify a rash on the right leg (target site of result). Map:AE = AdverseEvent.bodyLocation Map:CTOM = Diagnosis.primaryAnatomicSiteCodeSystem Map:CTOM = Imaging.anatomicSiteCodeSystem Map:CTOM = Imaging.anatomicSiteCode Map:CTOM = Diagnosis.primaryAnatomicSiteCode")
129
PerformedObservation Attributes (suite)
Type Notes targetAnatomicSiteLateralityCode public : CD A coded value specifying the side of the body (or a paired organ) that is a target site for a procedure. For example, Bilateral, Left, Right. Map:AE = 'AdverseEvent.bodyLocation' Map:CTOM = 'Diagnosis.primaryAnatomicSiteLateralityCode' focalDuration public : PQ.TIME The quantity of time in which the observation result is held to be true.For example, 2 months is the evaluation interval for a question such as "Have you smoked in the last 2 months?".NOTE: The focalDuration can be derived using the focalDateRange. AE:Exclude = 'True' Map:CTOM = 'DiseaseResponse.progressionPeriodUnitOfMeasureCode' Map:CTOM = 'DiseaseResponse.progressionPeriod' Map:SDTM IG = 'QS.QSEVLINT' focalDateRange public : IVL<TS.DATETIME> The time period in which the observation result is held to be true.NOTE: The focalDateRange can be derived from DefinedObservation.focalDateRange alone (i.e., directly from simple date ranges like ) or from evaluating the expression in DefinedObservation.focalDateRange (which references a date that is now known). Map:CTOM = 'DiseaseResponse.progressionDate' Map:CTOM = 'Diagnosis.confirmationDate'
 that is a target site for a procedure. For example, Bilateral, Left, Right. Map:AE = AdverseEvent.bodyLocation Map:CTOM = Diagnosis.primaryAnatomicSiteLateralityCode focalDuration. public : PQ.TIME. The quantity of time in which the observation result is held to be true.For example, 2 months is the evaluation interval for a question such as Have you smoked in the last 2 months .NOTE: The focalDuration can be derived using the focalDateRange. AE:Exclude = True Map:CTOM = DiseaseResponse.progressionPeriodUnitOfMeasureCode Map:CTOM = DiseaseResponse.progressionPeriod Map:SDTM IG = QS.QSEVLINT focalDateRange. public : IVL<TS.DATETIME> The time period in which the observation result is held to be true.NOTE: The focalDateRange can be derived from DefinedObservation.focalDateRange alone (i.e., directly from simple date ranges like ) or from evaluating the expression in DefinedObservation.focalDateRange (which references a date that is now known). Map:CTOM = DiseaseResponse.progressionDate Map:CTOM = Diagnosis.confirmationDate")
130
Représentation OWL de BRIDG
Domaine d’intérêt Conceptualisation visuelle (DAM UML ) Representation ontologique (OWL-DL) Est décrit par Fourni des information pour Formalisation Une définition OWL-DL est préferable à un ensemble de classes UML Un diagramme UML est préferable à une centaine de recommandations dans un documen word
 Representation ontologique. (OWL-DL) Est décrit par. Fourni des information pour. Formalisation. Une définition OWL-DL est préferable à un ensemble de classes UML. Un diagramme UML est préferable à. une centaine de recommandations dans un documen word.")
131
Conclusion BRIDG, un des piliers de l'interopérabilité
Modèle UML de données global pour tous les domaines d'intérêt Base de types de données rigoureusement définis Méthodologie pour interagir avec des domaines de vocabulaires contrôlés prédéfinis Méthode formelle de développement de standards Méthode de conception orientée objet Outils de dérivation et test de conformité

Présentations similaires



















