Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Apprentissage par renforcement dans les SMA situés réactifs
(extension du modèle satisfaction-altruisme) Olivier Simonin LIRMM Université Montpellier II - CNRS 2ème journées PDM et IA, LORIA, 28 juin 2002
 Olivier Simonin. LIRMM Université Montpellier II - CNRS. 2ème journées PDM et IA, LORIA, 28 juin")
2
Des agents situés réactifs …
Résolution collective de problèmes (comm. indirectes ou sans) IAD réactive [Steels&Deneubourg 89] swarm intelligence [Kube 92] éco-résolution [Ferber 89] [Drogoul 93] robotique cellulaires [Beni&Wang 89] Architecture réactive, à base de comportements [Brooks 89],[Mataric 94], [Drogoul 93], [Arkin 92] ... Réactions directes aux perceptions Environnement Action Perception pas de carte de l’environnement Acquisition Actions Agent Environnement Interactions Agent - Environnement Agent - Agent
 IAD réactive [Steels&Deneubourg 89] swarm intelligence [Kube 92] éco-résolution [Ferber 89] [Drogoul 93] robotique cellulaires [Beni&Wang 89] Architecture réactive, à base de comportements. [Brooks 89],[Mataric 94], [Drogoul 93], [Arkin 92] ... Réactions directes aux perceptions. Environnement. Action. Perception. pas de carte de l’environnement. Acquisition. Actions. Agent. Environnement. Interactions. Agent - Environnement. Agent - Agent.")
3
Problématique agents homogènes/hétérogènes buts differents
Environnements dynamiques / mals connus coordination coopération apprentissage intégrer à l’approche intelligence collective / architecture réactive des comportements coopératifs intentionnels pour diminuer le nombre d’agents nécessaire aux résolutions, assurer la « survie » de chaque agent et accélerer les processus de coopération Objectif initial

4
Plan I. Le modèle satisfaction-altruisme
II. Extension : apprentissage par renforcement III. Quelques questions et perspectives Modèle de comportement Expérimentations réelles Simulations

5
L’Architecture satisfaction-altruisme
Processus temps réel Vision interaction Éval. Sat I signaux test d’altruisme Combi. vect. Vision interne Architecture à base de comportements (ou fonctions)
")
6
Satisfaction personnelle
Principe: évaluer continuellement un niveau de satisfaction P(t) fonction de la progression de la tâche courante de l’agent P(t) = P(t-t) + v v |v| s t 0 |P(t)| Pmax Pmax + Evaluation de v : extension des progress estimators de M.J. Mataric[94] m si progression vers le but n si éloignement du but f si agent immobilisé v = avec -s < f < n 0 m < s persistance
 fonction de la progression de la tâche courante de l’agent. P(t) = P(t-t) + v v |v| s. t 0 |P(t)| Pmax Pmax + Evaluation de v : extension des progress estimators de M.J. Mataric[94] m si progression vers le but n si éloignement du but f si agent immobilisé. v = avec -s < f < n 0 m < s. persistance.")
7
Satisfaction interactive, signaux et réaction altruiste
Principe: évaluer les interactions perception gêne, aide (potentielle), indifférence émettre des signaux localement coopération des agents voisins Satisfaction interactive (tâche-voisins) But / Besoin de l’agent partage de ressources, besoin d’aide attirer le voisinage conflit/piège potentiel, gênes repousser le voisinage Emission de signaux de satisfaction interactive I à valeurs dans [-Pmax, Pmax] Intensité variable, fonction des satisfactions I > 0 attraction, I < 0 répulsion Réaction altruiste (approche champs de potentiels)
, indifférence émettre des signaux localement coopération des agents voisins. Satisfaction interactive (tâche-voisins) But / Besoin de l’agent. partage de ressources, besoin d’aide attirer le voisinage. conflit/piège potentiel, gênes repousser le voisinage. Emission de signaux de satisfaction interactive I à valeurs dans [-Pmax, Pmax] Intensité variable, fonction des satisfactions. I > 0 attraction, I < 0 répulsion. Réaction altruiste (approche champs de potentiels)")
8
Propagation des signaux
Coordination et coopération spatiale Test d’altruisme : Si .|Ie(t)| > (1- ).P(t) Vgoal = réaction altruiste (coop. ou non) Zeghal [94] max(signaux) cohérence Combinaison vectorielle : V = g1.Vgoal + g2.Fsli + g3. kj Faltj (déplacement de l’agent) Propagation des signaux
| > (1- ).P(t) Vgoal = réaction altruiste (coop. ou non) Zeghal [94] max(signaux) cohérence. Combinaison vectorielle : V = g1.Vgoal + g2.Fsli + g3. kj Faltj (déplacement de l’agent) Propagation des signaux.")
9
Simulations des robots fourrageurs
« Surface des signaux de satisfactions » (in)satisfactions des agents émission de signaux de satisfaction interactive = influences dynamiques combinées aux perceptions des agents Affichage de -I et de son évolution Le système combine auto-organisation et coopération intentionnelle
satisfactions des agents. émission de signaux de satisfaction interactive. = influences dynamiques combinées aux perceptions des agents. Affichage de -I et de son évolution. Le système combine auto-organisation et coopération intentionnelle.")
10
Principe de résolution :
Traitement des conflits spatiaux Problème: agents situés réactifs situations de blocages, actions incompatibles propagation des signaux d’insatisfactions (répulsions) des agents les plus contraints (insatisfaits) vers les plus libres spatialement. Principe de résolution : Pénalisation d’un blocage: v = N1. + N2.’ ’ < < 0 agents obstacles perçus
 des agents les plus contraints (insatisfaits) vers les plus libres spatialement. Principe de résolution : Pénalisation d’un blocage: v = N1. + N2.’ ’ < < 0. agents obstacles perçus.")
11
Résolution d’un cas extrême: l’impasse
- Preuve de résolution pour ce type d’environnement ( manipuler temps, espace et états de satisfactions) - Simulations
 - Simulations.")
12
Expérimentation réelle
Problème de l’impasse - 2 robots - extrémités fermées les robots doivent se repousser à tour de rôle : oscillation

13
II. Extension : Apprentissage par renforcement
Approche M.J. Mataric [94] - agents situés / robots autonomes - Conditions sur les systèmes situés : évolution en environnement continu et partiellement observable, l’agent n’a pas de modèle a priori du monde, ( + non connaissance des intentions/états des autres agents ) Conséquences : le monde n’est pas décomponsable en un ensemble fini d’états, (le problème du partitionnement en états discrets est très difficile [Kosecka92]) la limitation des perceptions ne garantie pas la distinction entre deux états differents du monde POMDP [Cassandra et al. 94] RL classique est exponentiel dans la taille des entrées problème du calcul de la récompense…
 Conséquences : le monde n’est pas décomponsable en un ensemble fini d’états, (le problème du partitionnement en états discrets est très difficile [Kosecka92]) la limitation des perceptions ne garantie pas la distinction entre deux états differents du monde POMDP [Cassandra et al. 94] RL classique est exponentiel dans la taille des entrées. problème du calcul de la récompense…")
14
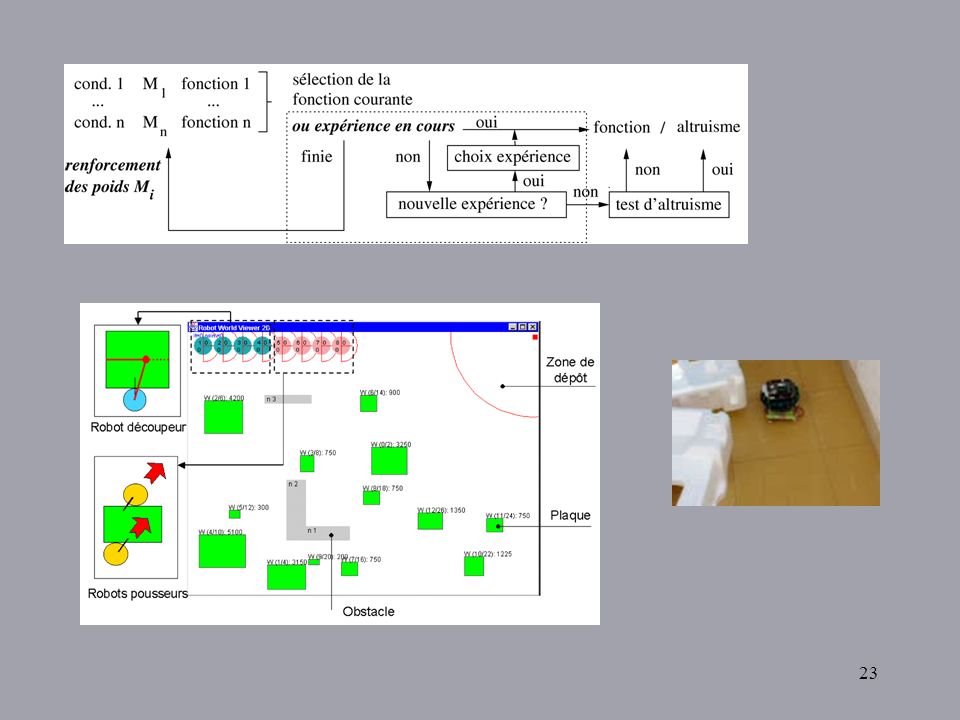
Limiter l’espace des états en considérant les comportements
Apprentissage : ajuster les valeurs de la matrice conditions/comportements: ens. de cond. binaires matrice 2n conditions * B comportements Condition Behavior Recherche Retour base Dispersion Recharger bat. 0000 100 45 40 35 0001 0010 30 A(c,b) = t=1T R(c,t) Résultat pour la politique optimale : Condition Behavior près géneur ? objet saisi ? à la base ? lumière ? Recherche 1 Retour base R(c) fonctions de renforcement hétérogènes, progress estimators …
 = t=1T R(c,t) Résultat pour la politique optimale : Condition. Behavior. près géneur objet saisi à la base lumière Recherche. 1. Retour base. R(c) fonctions de renforcement hétérogènes, progress estimators …")
15
Renforcer suivant les satisfactions du voisinage
Un état de l’agent (condition) est défini par : des perceptions sur les états des agents voisins des perceptions sur les objets à traiter signaux de satisfaction (sat. P) (leur signe représentation compacte) Calcul de la récompense ( Mataric[97], comm. récompense du voisinage): L’agent calcule une moyenne MSat des signaux perçus localement durant la tâche à chaque itération l’agent considère le signal soit le plus négatif sinon le plus positif ne renforcer que les situations positives pour l’ensemble des voisins. est l’écart entre la moyenne MSat et la valeur initiale r = ||. + (1-||). MSat / Pmax Wi = b.Wi + (1-b).r
 est. défini par : des perceptions sur les états des agents voisins. des perceptions sur les objets à traiter. signaux de satisfaction (sat. P) (leur signe représentation compacte) Calcul de la récompense ( Mataric[97], comm. récompense du voisinage): L’agent calcule une moyenne MSat des signaux perçus localement durant la tâche. à chaque itération l’agent considère le signal soit le plus négatif. sinon le plus positif. ne renforcer que les situations positives pour l’ensemble des voisins. est l’écart entre la moyenne MSat et la valeur initiale. r = ||. + (1-||). MSat / Pmax Wi = b.Wi + (1-b).r.")
16
Des robots netoyeurs Système hétérogène de robots pousseurs et découpeurs de plaques 27 Etats action-interactions : robot découpeur Code I1 : signal Découp. I2 : signal Pous. S3 : percep. plaque pas de signal pas de plaque 1 + plaque détectée 2 - plaque saisie

17
Résultats - Simulations
Diminution des situations insatisfaisantes (gênes, actions incompatibles) Apparition ou renforcement des situations-actions collectivement satisfaisantes Ex. situation 022 (rob. découp. tenant une plaque et percevant un pousseur insat.) Agent n1 en sit. 022 avant après marche aléatoire 0.1 0.11 +10% pousser plaque 0.13 Nouv. couper plaque 0.5 0.09 -82% stabiliser plaque 0.15 -70% réaction altruiste 0.6 -83% (après 25 essais en 022) évaluation en cours…
 Apparition ou renforcement des situations-actions collectivement satisfaisantes. Ex. situation 022 (rob. découp. tenant une plaque et percevant un pousseur insat.) Agent n1 en sit avant. après. marche aléatoire % pousser plaque Nouv. couper plaque % stabiliser plaque % réaction altruiste % (après 25 essais en 022) évaluation en cours…")
18
Questions et Perspectives
L’approche par comportements (Mataric) permet de mettre en œuvre un RL efficace pour un SMA réel (bruité) d’utiliser des fn. progress estimators pour évaluer dynamiquement la récompense d’une tâche. Nous introduisons la communication des états de satisfactions pour prendre en compte les états des agents voisins dans l’évaluation de la situation courante de l’agent (pb. états cachés) introduire un apprentissage « collectif » (non centré sur la tâche individuelle courante de l’agent) conserver les atouts du modèle satisfaction-altruisme.
 permet. de mettre en œuvre un RL efficace pour un SMA réel (bruité) d’utiliser des fn. progress estimators pour évaluer dynamiquement la récompense d’une tâche. Nous introduisons la communication des états de satisfactions pour. prendre en compte les états des agents voisins dans l’évaluation de la situation courante de l’agent (pb. états cachés) introduire un apprentissage « collectif » (non centré sur la tâche individuelle courante de l’agent) conserver les atouts du modèle satisfaction-altruisme.")
19
Questions et Perspectives
Le formalisme POMDP peut-il donner un cadre formel à ces travaux ? ens. fini d’états (conditions), ens. d’actions (comportements), politique optimale à découvrir… type MMDP [Boutilier 99] au contraire, notre approche est-elle une alternative à l’approche MDP ? L’approche AMM de [Mataric 00] (Augmented Markov Models) est-elle une solution ? (semi-Markov chains) construction et communication de graphes ! Perspectives : répondre à ces questions ! appliquer/évaluer notre modèle sur de véritable robots, étendre le modèle : communications, def. des états, etc.
, ens. d’actions (comportements), politique optimale à découvrir… type MMDP [Boutilier 99] au contraire, notre approche est-elle une alternative à l’approche MDP L’approche AMM de [Mataric 00] (Augmented Markov Models) est-elle une solution (semi-Markov chains) construction et communication de graphes ! Perspectives : répondre à ces questions ! appliquer/évaluer notre modèle sur de véritable robots, étendre le modèle : communications, def. des états, etc.")
20
Perspectives à court et moyen terme:
Expérimentations avec plus de robots (en cours), hétérogénéité, Appliquer la méthode de résolution des conflits à des problèmes réels, Etendre le modèle apprenant (enrichir les communications) à plus long terme: Exploiter ces mesures/modèles de satisfactions pour analyser/concevoir divers types de SMAs Etudier les signaux d’attractions dans l’éco-résolution (et les éco-robots), Etudier les états particuliers des processus de résolutions par les outils de la théorie des systèmes dynamiques.
, hétérogénéité, Appliquer la méthode de résolution des conflits à des problèmes réels, Etendre le modèle apprenant (enrichir les communications) à plus long terme: Exploiter ces mesures/modèles de satisfactions pour analyser/concevoir divers types de SMAs. Etudier les signaux d’attractions dans l’éco-résolution (et les éco-robots), Etudier les états particuliers des processus de résolutions par les outils de la théorie des systèmes dynamiques.")
21
Publications Modèle de comportement - résolution de problèmes :
La thèse : Modèle de comportement - résolution de problèmes : JFIADSMA' eme journées Francophones d'Intelligence Artificielle Distribuée et Systèmes Multi-Agents "Modélisation des satisfactions personnelle et interactive d'agents situés coopératifs" Olivier Simonin et Jacques Ferber nov Montreal (Best paper) SAB'2000 The Sixth International Conference on the Simulation of Adaptative Behavior FROM ANIMALS TO ANIMATS 6 (Paris, France) "Modeling Self Satisfaction and Altruism to handle Action Selection and Reactive Cooperation" Olivier Simonin and Jacques Ferber DARS'2000 5th International Symposium on Distributed Autonomous Robotic Systems Knoxville, TN, USA "An Architecture for Reactive Cooperation of Mobile Distributed Robots" Olivier Simonin, Alain Liégeois and Philippe Rongier ECAI' th European Conf. on Artificial Intelligence «How situated agents can learn to cooperate by monitoring their neighbors’ satisfaction" Jérôme Chapelle, Olivier Simonin and Jacques Ferber (à paraître) Implémentation et validation en robotique : ICRA'2002 IEEE Int. Conf. on Robotics and Automation "Implementation and Evaluation of a Satisfaction/Altruism Based Architecture for Multi-Robot Systems" (à paraître) Philippe Lucidarme, Olivier Simonin and Alain Liégeois
 SAB 2000 The Sixth International Conference on the Simulation of Adaptative Behavior FROM ANIMALS TO ANIMATS 6 (Paris, France) Modeling Self Satisfaction and Altruism to handle Action Selection and Reactive Cooperation Olivier Simonin and Jacques Ferber. DARS th International Symposium on Distributed Autonomous Robotic Systems Knoxville, TN, USA An Architecture for Reactive Cooperation of Mobile Distributed Robots Olivier Simonin, Alain Liégeois and Philippe Rongier. ECAI th European Conf. on Artificial Intelligence «How situated agents can learn to cooperate by monitoring their neighbors’ satisfaction Jérôme Chapelle, Olivier Simonin and Jacques Ferber (à paraître) Implémentation et validation en robotique : ICRA 2002 IEEE Int. Conf. on Robotics and Automation Implementation and Evaluation of a Satisfaction/Altruism Based Architecture for Multi-Robot Systems (à paraître) Philippe Lucidarme, Olivier Simonin and Alain Liégeois.")
24
la notion d’Embodiment R. Brooks [91]
Introduction aux agents situés réactifs Acquisition Actions communications Traiter des tâches Coopérer Comportement cohérent et autonome ? Agent Environnement Interactions Agent - Environnement Agent - Agent la notion d’Embodiment R. Brooks [91] (robotique) Traitements des tâches par processus collectifs (éthologie) Steels et Deneubourg [89] (informatique)
![la notion d’Embodiment R. Brooks [91]](http://slideplayer.fr/slide/497572/2/images/24/la+notion+d%E2%80%99Embodiment+R.+Brooks+%5B91%5D.jpg "Introduction aux agents situés réactifs. Acquisition. Actions. communications. Traiter des tâches. Coopérer. Comportement cohérent et autonome. Agent. Environnement. Interactions. Agent - Environnement. Agent - Agent. la notion d’Embodiment R. Brooks [91] (robotique) Traitements des tâches par processus collectifs (éthologie) Steels et Deneubourg [89] (informatique)")
Présentations similaires
















>")



