Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
LA GÉNÉTIQUE MOLECULAIRE
L’ADN et les gènes

2
Chromosomes, ADN et gènes
Cellule Chromosome Noyau

3
La chromatine est la forme (amas) sous laquelle se présente l‘ADN dans le noyau. correspond à l'association de l'ADN et de protéines.

4
Les chromosomes sont les éléments porteurs de l'information génétique (contiennent les gènes). sont formés d'une longue molécule d'ADN. leur nombre est constant chez chaque espèce animale. sont souvent illustrés sous leur forme condensée et dupliquée. L'ensemble des chromosomes est représenté sur un caryotype (carte de chromosomes). Les chromosomes sont habituellement représentés par paires, en parallèle avec leur homologue. Les anomalies soit du nombre, soit de la structure des chromosomes sont appelées aberrations chromosomiques.
. Les chromosomes sont habituellement représentés par paires, en parallèle avec leur homologue. Les anomalies soit du nombre, soit de la structure des chromosomes sont appelées aberrations chromosomiques.")
5
Les chromosomes (suite)
La mitose transmet la totalité des chromosomes aux cellules filles. la division cellulaire où chaque « cellule-fille » reçoit une copie complète du génome de l'organisme « cellule-mère ». La méiose ne transmet que la moitié du patrimoine génétique aux cellules filles. la division cellulaire qui aboutit à la production de cellules sexuelles (gamètes).
.")
7
Le gène est une succession précise de bases azotés (fragments d’ADN). (comme des lettres qui forment des mots) fournit les instructions pour la fabrication de protéines. Le génome est l'ensemble du matériel génétique (gènes) d'un individu codé dans son ADN. Le chercheur français Christian Vélot[1] compare le génome à une encyclopédie dont les différents volumes seraient les chromosomes. Les gènes seraient les phrases contenues dans ces volumes et ces phrases seraient écrites dans un langage génétique représenté par quatre bases (adénine, guanine, cytosine et thymine) abrégées en AGCT. Génomique: Le séquençage de l'ADN consiste à déterminer l'ordre d'enchaînement des nucléotides d’un fragment d’ADN donné.
 d un individu codé dans son ADN. Le chercheur français Christian Vélot[1] compare le génome à une encyclopédie dont les différents volumes seraient les chromosomes. Les gènes seraient les phrases contenues dans ces volumes et ces phrases seraient écrites dans un langage génétique représenté par quatre bases (adénine, guanine, cytosine et thymine) abrégées en AGCT. Génomique: Le séquençage de l ADN consiste à déterminer l ordre d enchaînement des nucléotides d’un fragment d’ADN donné.")
8
1. Le manuel d’instructions des processus de la vie : l’ADN
A) Des scientifiques découvrent la structure de l'ADN, le fondement matériel de l'hérédité (1953) L'équipe de Watson et Crick propose un modèle de l'ADN à partir des travaux de Rosalind Franklin. Crick Watson
 Des scientifiques découvrent la structure de l ADN, le fondement matériel de l hérédité (1953) L équipe de Watson et Crick propose un modèle de l ADN à partir des travaux de Rosalind Franklin. Crick. Watson.")
9
L’ADN hérité de nos parents est notre génome
Génome de l’humain Contenu ADN de nos 46 chromosomes C) La capacité de l’ADN à se répliquer est le processus fondamental à la base de la perpétuation de la vie. Les enfants ressemblent à leurs parents, parce que l'ADN de ces derniers se réplique (se double) d'une manière précise avant d'être transmis d'une génération à l'autre. D) L’ADN dicte nos caractéristiques physiques (biochimiques, anatomiques, physiologiques) via nos protéines.
 La capacité de l’ADN à se répliquer est le processus fondamental à la base de la perpétuation de la vie. Les enfants ressemblent à leurs parents, parce que l ADN de ces derniers se réplique (se double) d une manière précise avant d être transmis d une génération à l autre. D) L’ADN dicte nos caractéristiques physiques (biochimiques, anatomiques, physiologiques) via nos protéines.")
10
2. Des expériences majeures mènent les chercheurs à reconnaître que l’ADN est le matériel héréditaire À partir des recherches de Morgan (1910) sur les chromosomes géants de drosophiles (une mouche), on savait que le matériel génétique devait être composé d'ADN, d'ARN ou de protéines mais on penchait pour les protéines. L'ADN semblait trop uniforme dans sa structure pour pouvoir expliquer la grande diversité démontrée par le vivant.
 sur les chromosomes géants de drosophiles (une mouche), on savait que le matériel génétique devait être composé d ADN, d ARN ou de protéines mais on penchait pour les protéines. L ADN semblait trop uniforme dans sa structure pour pouvoir expliquer la grande diversité démontrée par le vivant.")
11
A) L'expérience de Griffith (1928)
La transformation des bactéries par l'ADN d’autres bactéries Matériel Deux souches bactériennes : pathogène et non pathogène Des souris La souche L (lisse) est pathogène parce que sa capsule la protège du système immunitaire de ses victimes. La souche R (rugueuse) est non pathogène car elle est dépourvue de capsule. Le système immunitaire la reconnaît et la détruit.
 est pathogène parce que sa capsule la protège du système immunitaire de ses victimes. La souche R (rugueuse) est non pathogène car elle est dépourvue de capsule. Le système immunitaire la reconnaît et la détruit.")
12
Bactéries pathogènes «tuées par la chaleur»
Expérience Un mélange de bactéries, pathogènes «mortes» et non pathogènes «vivantes», injecté à une souris la fait mourir. Bactérie non pathogène «vivante» Bactéries pathogènes «vivantes»

13
Conclusion; Les bactéries vivantes, non pathogènes, ont capté une substance provenant des bactéries pathogènes et se sont transformées en bactéries pathogènes ce qui a fait mourir l’animal. L'agent de transformation est héréditaire puisque les bactéries transformées en pathogènes se reproduisent en d'autres bactéries pathogènes. L'agent de transformation n'est probablement pas constitué de protéines car les protéines sont dénaturées par la chaleur. Ors, Griffith a utilisé la chaleur pour tuer les bactéries. On peut penser que l'agent de transformation est l’ADN.

14
B) Les travaux de l’équipe Avery (1944)
Déterminent que l'agent de transformation dans l’expérience de Griffith est véritablement l'ADN. Cherchent pendant 14 ans l'identité du matériel ayant transformé les bactéries de Griffith.

15
C) L’analyse de l’ADN par Erwin Chargaff (1947)
Preuve indirecte que l’ADN est le matériel génétique «héréditaire» puisque chaque espèce a sa propre composition en ADN Erwin Chargaff a analysé la proportion des bases dans l'ADN de plusieurs organismes différents et a tiré deux conclusions : : Chaque espèce a sa propre composition d'ADN Dans l'ADN, il y a : autant d'adénine que de thymine (A = T) autant de guanine que de cytosine (G = C) Ce sont les règles de Chargaff !
 autant de guanine que de cytosine (G = C) Ce sont les règles de Chargaff !")
16
D) L'expérience d'Hershey et Chase (1952)
Une preuve de la programmation de cellules par l'ADN viral Matériel: Deux groupes de virus (des phages) Groupe de virus ayant de l’ADN marqué au phosphore radioactif 32 (32P) Groupe de virus ayant des protéines marquées au soufre radioactif 35 (35S). Des bactéries ADN marqué Protéines marquées (Capsule virale, essentiellement)
 Groupe de virus ayant de l’ADN marqué au phosphore radioactif 32 (32P) Groupe de virus ayant des protéines marquées au soufre radioactif 35 (35S). Des bactéries. ADN marqué. Protéines marquées. (Capsule virale, essentiellement)")
17
Expérience: Capsule marquée ADN marqué Les bactéries infectées par des virus aux protéines marquées (32P) ne deviennent pas radioactives mais celles infectées par des virus à l’ADN marqué (35S ) le devienne. 32P Conclusion: 35S Le matériel héréditaire injecté par les virus aux bactéries est l'ADN.
 ne deviennent pas radioactives mais celles infectées par des virus à l’ADN marqué (35S ) le devienne. 32P. Conclusion: 35S. Le matériel héréditaire injecté par les virus aux bactéries est l ADN.")
18
Les chercheurs sont convaincus que le support génétique est de l'ADN.
3. Les chercheurs se lancent à la recherche de la structure de l’ADN A)Au début des années 1950 Les chercheurs sont convaincus que le support génétique est de l'ADN. Ils se lancent dans la course afin de découvrir sa structure tridimensionnelle : Pauling en Californie et l’équipe Wilkins / Franklin à Londres. À cette époque on connaît les constituants de l'ADN et la disposition de ses liaisons.
Au début des années Les chercheurs sont convaincus que le support génétique est de l ADN. Ils se lancent dans la course afin de découvrir sa structure tridimensionnelle : Pauling en Californie et l’équipe Wilkins / Franklin à Londres. À cette époque on connaît les constituants de l ADN et la disposition de ses liaisons.")
19
B) Historique des connaissances sur l’ADN
1869 Friedrich MIESCHER isole la nucléine (ADN) pour la première fois — à partir de sperme de poisson et de cellules trouvées dans le pus des plaies ouvertes. 1871 Premières publications décrivant la nucléine par Friedrich MIESCHER, Felix HOPPE-SEYLER, et P. PLÓSZ. 1889 Richard ALTMANN rebaptise «nucléine» en «acide nucléique». 1929 Phoebus LEVENE identifie les éléments constitutifs de l'ADN, y compris les quatre bases azotées (A, T, G et C). 1949–1950 Erwin CHARGAFF publie ses travaux montrant que : le rapport A+T/C+G est variable selon les espèces mais constant entre les membres d'une même espèce peu importe l’espèce, les rapports A/T et G/C sont toujours égaux à 1 (autant de A que de T et autant de G que de C).
 pour la première fois — à partir de sperme de poisson et de cellules trouvées dans le pus des plaies ouvertes Premières publications décrivant la nucléine par Friedrich MIESCHER, Felix HOPPE-SEYLER, et P. PLÓSZ Richard ALTMANN rebaptise «nucléine» en «acide nucléique» Phoebus LEVENE identifie les éléments constitutifs de l ADN, y compris les quatre bases azotées (A, T, G et C). 1949–1950 Erwin CHARGAFF publie ses travaux montrant que : le rapport A+T/C+G est variable selon les espèces mais constant entre les membres d une même espèce. peu importe l’espèce, les rapports A/T et G/C sont toujours égaux à 1 (autant de A que de T et autant de G que de C).")
20
C) Watson et Crick élaborent un modèle de l’ADN à partir des travaux de Franklin (1953)
1953 Rosalind FRANKLIN démontre que l'ADN possède une structure hélicoïdale grâce à sa radiographie par diffraction de rayons X. Elle en conclue que les squelettes désoxyribose-phosphate sont à l'extérieur de la double hélice. Rosalind Franklin Morte à 38 ans d'un cancer Son équipe a reçu le prix Nobel en Radiographie de l'ADN par diffraction de rayons X

21
James WATSON et Francis CRICK proposent un modèle selon les conclusions de Franklin.
Watson plaça les bases azotées à l'intérieur d’une double hélice dans laquelle on retrouve toujours les paires A avec T et G avec C. Crick Watson Le modèle : Explique les règles de Chargaff Laisse entrevoir comment l'ADN peut se répliquer. Publication dans la revue Nature en 1953 Prix Nobel (ainsi que Wilkins, collaborateur de Franklin) en 1962
 en")
22
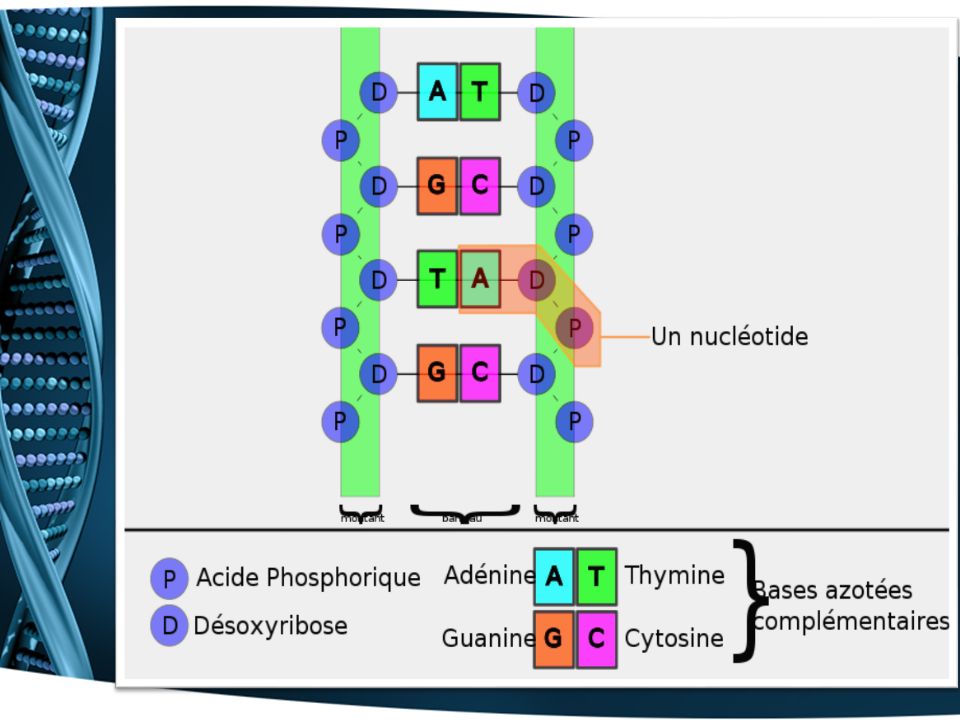
La structure de l’ADN a la forme d’une échelle enroulée (double hélice). est composée de séquences de nucléotides. chaque nucléotide est constitué de trois éléments liés entre eux: un groupe phosphate un sucre, le désoxyribose une base azotée (adénine (A), thymine (T), guanine (G), cytosine (C) ). Bases azotées complémentaires: A-T, G-C
, thymine (T), guanine (G), cytosine (C) ). Bases azotées complémentaires: A-T, G-C.")
23
Les molécules L’ADN définition longue molécule d’acide désoxyribonucléique contenant l’information génétique de la cellule et de l’organisme chaque cellule d’un individu contient les mêmes molécules d’ADN (sauf en cas de maladie, mutations…) en se divisant, la cellule transmet son patrimoine génétique (son ADN) aux cellules filles
 en se divisant, la cellule transmet son patrimoine génétique (son ADN) aux cellules filles.")
24
l’unité de base de l’ADN est le nucléotide
Une base azotée (il y en a 4 sortes possibles) Un sucre, le désoxyribose Un groupement phosphate (H3PO4 ) b. structure l’unité de base de l’ADN est le nucléotide il est composé de 3 éléments : - Une base azotée - Un sucre, le désoxyribose - Un groupement phosphate (H3PO4 ) il existe 4 bases différentes : 2 bases puriques : l’adénine (A) la guanine (G) 2 bases pyrimidiques : la thymine (T) la cytosine (C) Une base azotée (il y en a 4 sortes possibles) Un sucre, le désoxyribose Un groupement phosphate (H3PO4 )
 Un sucre, le désoxyribose Un groupement phosphate (H3PO4 ) b. structure. l’unité de base de l’ADN est le nucléotide. il est composé de 3 éléments : - Une base azotée - Un sucre, le désoxyribose - Un groupement phosphate (H3PO4 ) il existe 4 bases différentes : 2 bases puriques : l’adénine (A) la guanine (G) 2 bases pyrimidiques : la thymine (T) la cytosine (C) Une base azotée (il y en a 4 sortes possibles) Un sucre, le désoxyribose Un groupement phosphate (H3PO4 )")
25
Les nucléotides peuvent se lier les uns aux autres par l'intermédiaire de leur groupe phosphate et de leur sucre. Ils peuvent donc former de longues chaînes polynucléotidiques:

26
L’ADN est constitué de deux chaînes polynucléotidiques enroulées l’une autour de l’autre : double hélice (structure bicaténaire) Les 2 chaînes de l’hélice sont reliées l’une à l ’autre: il se forme des liaisons faibles entre les nucléotides A et T et entre les C et G

27
Les 2 chaînes sont donc complémentaires par leurs nucléotides
L’ordre précis dans lequel les nucléotides sont ordonnés le long de la chaîne d’ADN donne le code spécifique des protéines Une fois déroulée, la molécule d’ADN peut atteindre 7 cm de long L’ADN est contenu dans le noyau et ne peut pas en sortir

28
L’ADN est le support de l’information génétique de la cellule
La fonction L’ADN est le support de l’information génétique de la cellule les gènes sont des facteurs héréditaires qui sont responsables des caractères phénotypiques de l'individu (à un caractère peut être associés plusieurs gènes) les gènes (fragments d'ADN) s’organisent en une succession d’unités de bases: les codons (triplet de nucléotides) les gènes contiennent les instructions permettant aux cellules de polymériser les acides aminés dans un ordre bien précis et de synthétiser ainsi des protéines spécifiques Riz gènes le génome humain a été séquencé en 2001, on considère qu’il est constitué d’environ gènes
 les gènes (fragments d ADN) s’organisent en une succession d’unités de bases: les codons (triplet de nucléotides) les gènes contiennent les instructions permettant aux cellules de polymériser les acides aminés dans un ordre bien précis et de synthétiser ainsi des protéines spécifiques. Riz gènes. le génome humain a été séquencé en 2001, on considère qu’il est constitué d’environ gènes.")
30
4. Réplication de l’ADN Dédoublement de tout l'ADN avant la division cellulaire dans le but de transmettre les gènes, de génération en génération A)Le monomère de la réplication est le nucléoside triphosphate d’ADN Le nucléoside tri-P est chimiquement actif à cause des charges négatives des 3 groupes phosphate. Il se lie à l’ADN en formation en perdant deux groupes P (pyrophosphate). L’hydrolyse du pyrophosphate (en deux molécules de phosphate inorganique) dégage l'énergie nécessaire à la liaison du nucléotide à la chaîne d'ADN . Nucléoside tri-P i P Pyrophosphate Phosphates inorganiques P i P i
Le monomère de la réplication est le nucléoside triphosphate d’ADN. Le nucléoside tri-P est chimiquement actif à cause des charges négatives des 3 groupes phosphate. Il se lie à l’ADN en formation en perdant deux groupes P (pyrophosphate). L’hydrolyse du pyrophosphate (en deux molécules de phosphate inorganique) dégage l énergie nécessaire à la liaison du nucléotide à la chaîne d ADN . Nucléoside tri-P. i. P. Pyrophosphate. Phosphates inorganiques. P. i. P. i.")
31
B) La réplication (concept de base)
Chaque molécule d'ADN se déroule et se sépare en deux brins qui vont servir de matrice pour la synthèse d'ADN (par bris des liens hydrogène). Des nucléosides triphosphates d'ADN, déjà synthétisés et présents dans le noyau, s'approchent des extrémités 3' des deux brins d'ADN en formation. Les nucléosides s'apparient aux bases de l'ADN par des liens hydrogène et selon les règles de complémentarité. L'ADN polymérase (un enzyme) libère le pyrophosphate de chaque nucléoside qui s'ajoute et utilise l'énergie dégagée par la réaction pour unir (polymériser) les nucléotides entre eux par des liens phosphodiester. Les deux nouvelles molécules d'ADN s’enroulent en une double hélice. Il y a maintenant deux nouvelles molécules d'ADN, là où il n'y en avait qu'une seule.
. Des nucléosides triphosphates d ADN, déjà synthétisés et présents dans le noyau, s approchent des extrémités 3 des deux brins d ADN en formation. Les nucléosides s apparient aux bases de l ADN par des liens hydrogène et selon les règles de complémentarité. L ADN polymérase (un enzyme) libère le pyrophosphate de chaque nucléoside qui s ajoute et utilise l énergie dégagée par la réaction pour unir (polymériser) les nucléotides entre eux par des liens phosphodiester. Les deux nouvelles molécules d ADN s’enroulent en une double hélice. Il y a maintenant deux nouvelles molécules d ADN, là où il n y en avait qu une seule.")
32
Lien phosphodiester Carbone 3’ du sucre ADN polymérase
Nouveau brin Brin matrice Lien phosphodiester Carbone 3’ du sucre ADN polymérase Nucléoside tri-P

33
L’ARN définition L’ARN est l’acide ribonucléique il est synthétisé à partir de l’ADN L'ARN, possède un rôle essentiel de messager de l'information génétique, c’est un intermédiaire entre l'ADN et les structures cellulaires, chargées de lire la séquence d'information copiée de l'ADN en vue de la production des protéines. Il existe différents types d'ARN (ARN messager, ARN de transfert, ARN ribosomal)
")
34
La structure l’unité de base est comme pour l’ADN le nucléotide Les différences avec l’ADN : Le sucre est le ribose (désoxyribose pour l’ADN) La base Thymine (T) n’existe pas et est remplacée par la base Uracile (U) L’ARN est une molécule simple brin
 La base Thymine (T) n’existe pas et est remplacée par la base Uracile (U) L’ARN est une molécule simple brin.")
35
Fonction L’ARN est l’intermédiaire entre l’ADN et les protéines, il est synthétisé dans le noyau à partir de l’ADN lors de la transcription Les différents ARNs (ARNm, ARNr, ARNt) ont tous un rôle particulier dans le processus complexe de synthèse des protéines. l'ARNr : (ARN ribosomal) forme avec des protéines les ribosomes. L'ARNr est de loin le type d'ARN le plus abondant dans la cellule. l'ARNm : (ARN messager) véhicule l'information génétique de l'ADN au site de fixation se trouvant sur les ribosomes où il est traduit en chaîne polypeptidique. l'ARNt : (ARN de transfert) porte à son extrémité un acide aminé qui sera complémentaire du codon porté par l'ARNm qui lui est associé de par les règles de la génétique.
 ont tous un rôle particulier dans le processus complexe de synthèse des protéines. l ARNr : (ARN ribosomal) forme avec des protéines les ribosomes. L ARNr est de loin le type d ARN le plus abondant dans la cellule. l ARNm : (ARN messager) véhicule l information génétique de l ADN au site de fixation se trouvant sur les ribosomes où il est traduit en chaîne polypeptidique. l ARNt : (ARN de transfert) porte à son extrémité un acide aminé qui sera complémentaire du codon porté par l ARNm qui lui est associé de par les règles de la génétique.")
36
La synthèse des protéines
LA GÉNÉTIQUE La synthèse des protéines

37
Partie 2 : Du gène à la protéine
Les gènes (l’ADN) dictent les caractères physiques de l’individu via les protéines À la découverte du lien entre les gènes et les protéines Principes généraux de l’expression des gènes L’information génétique est codée : le code génétique Étude de la transcription : synthèse de l’ARN à partir de l’ADN (via l’ARN polymérase) Étude de la traduction : synthèse d’un polypeptide à partir de l’ARNm (via les ARN du ribosome) Précisions quant à la synthèse protéique Mutations et mutagènes
 dictent les caractères physiques de l’individu via les protéines. À la découverte du lien entre les gènes et les protéines. Principes généraux de l’expression des gènes. L’information génétique est codée : le code génétique. Étude de la transcription : synthèse de l’ARN à partir de l’ADN (via l’ARN polymérase) Étude de la traduction : synthèse d’un polypeptide à partir de l’ARNm (via les ARN du ribosome) Précisions quant à la synthèse protéique. Mutations et mutagènes.")
38
Comment les gènes dictent-ils l’aspect physique d’un organisme ?
7. Les gènes (l’ADN) dictent les caractères physiques de l’individu via les protéines Comment les gènes dictent-ils l’aspect physique d’un organisme ? C’est en dictant la synthèse des protéines de l’organisme. Les protéines sont de niveau moléculaire mais elle s’expriment physiquement dans notre apparence (elles deviennent visibles «en quelque sorte»). Ainsi, elles déterminent des caractères comme la couleur des cheveux, le groupe sanguin et la longueur de la tige des pois. Les protéines représentent donc le lien entre le génotype (les gènes) et le phénotype (les caractères apparents). «Nous sommes le reflet de nos protéines et nos protéines sont codées dans nos gènes !»
 dictent les caractères physiques de l’individu via les protéines. Comment les gènes dictent-ils l’aspect physique d’un organisme C’est en dictant la synthèse des protéines de l’organisme. Les protéines sont de niveau moléculaire mais elle s’expriment physiquement dans notre apparence (elles deviennent visibles «en quelque sorte»). Ainsi, elles déterminent des caractères comme la couleur des cheveux, le groupe sanguin et la longueur de la tige des pois. Les protéines représentent donc le lien entre le génotype (les gènes) et le phénotype (les caractères apparents). «Nous sommes le reflet de nos protéines et nos protéines sont codées dans nos gènes !»")
39
B) Archibald GARROD établit, pour la première fois, une corrélation «un gène — enzyme» grâce à l’observation d’une maladie génétique : l’alcaptonurie ( ) GARROD, quasi 50 ans avant que l'ADN ne soit reconnu comme étant le matériel héréditaire, comprend qu’il y a un lien entre les gènes et les enzymes (des protéines catalytiques). Source En 1902, au St Bartholomew's Hospital (Londres), il observe un jeune garçon atteint d'alcaptonurie , une maladie dans laquelle l'urine du malade vire au noir en présence d'air. Dans la même famille, un autre enfant naît avec la même maladie. Il étudie d'autres cas et conclut qu'un malade devait avoir reçu deux gènes de la maladie. Il suggère que la déficience enzymatique soit due à une anomalie du gène responsable de la synthèse de cette enzyme. Il publie ses observations en 1909 dans «Les erreurs innées du métabolisme», où il avance une explication similaire pour plusieurs maladies génétiques : albinisme, cystinurie et pentosurie.
. Source. En 1902, au St Bartholomew s Hospital (Londres), il observe un jeune garçon atteint d alcaptonurie , une maladie dans laquelle l urine du malade vire au noir en présence d air. Dans la même famille, un autre enfant naît avec la même maladie. Il étudie d autres cas et conclut qu un malade devait avoir reçu deux gènes de la maladie. Il suggère que la déficience enzymatique soit due à une anomalie du gène responsable de la synthèse de cette enzyme. Il publie ses observations en 1909 dans «Les erreurs innées du métabolisme», où il avance une explication similaire pour plusieurs maladies génétiques : albinisme, cystinurie et pentosurie.")
40
Le champignon se reproduit de deux façons :
C) BEADLE et TATUM généralisent l'hypothèse de GARROD grâce aux mutants métaboliques de Neurospora crassa (1941—1946) Travail de plusieurs années ! Edward Lawrie Tatum ( ) Matériel : La moisissure rouge du pain, un champignon filamenteux, très ramifié (Neurospora crassa) sexuée par ascospore asexuée par conidie George Wells Beadle ( ) Le champignon se reproduit de deux façons :
 BEADLE et TATUM généralisent l hypothèse de GARROD grâce aux mutants métaboliques de Neurospora crassa (1941—1946) Travail de plusieurs années ! Edward Lawrie Tatum ( ) Matériel : La moisissure rouge du pain, un champignon filamenteux, très ramifié (Neurospora crassa) sexuée par ascospore. asexuée par conidie. George Wells Beadle ( ) Le champignon se reproduit de deux façons :")
41
On devrait plutôt dire : un gène —une molécule d'ARN.
Conclusions Des mutations peuvent conduire à la modification d'enzymes qui ne fonctionnent plus correctement. Un gène a pour fonction de commander la production d'une enzyme spécifique (une protéine). L'hypothèse de Beadle et Tatum, un gène-un enzyme, n'est plus tout à fait vraie car : les gènes déterminent les protéines en général, pas juste les enzymes certaines protéines sont faites de plusieurs chaînes polypeptidiques qui se regroupent alors que d’autres sont issues d’une chaîne qui se fragmente plusieurs gènes codent pour des molécules d'ARN qui ne sont pas traduites en protéines On devrait plutôt dire : un gène —une molécule d'ARN.
. L hypothèse de Beadle et Tatum, un gène-un enzyme, n est plus tout à fait vraie car : les gènes déterminent les protéines en général, pas juste les enzymes. certaines protéines sont faites de plusieurs chaînes polypeptidiques qui se regroupent alors que d’autres sont issues d’une chaîne qui se fragmente. plusieurs gènes codent pour des molécules d ARN qui ne sont pas traduites en protéines. On devrait plutôt dire : un gène —une molécule d ARN.")
42
Synthèse d'ARN messager (ARNm) sous la direction de l'ADN.
9. Principes généraux de l’expression des gènes A)Les étapes L’expression génique se fait en 2 étapes : la transcription et la traduction Transcription Synthèse d'ARN messager (ARNm) sous la direction de l'ADN. On passe du langage ADN au langage ARN (langage semblable de «nucléotides») La transcription produit aussi d’autres types d’ARN (de transfert, ribosomique, petit ARN nucléaire…) ayant divers rôles. Traduction Synthèse d'un polypeptide à partir d’un ARN messager. On passe du langage ARN au langage des protéines : les acides aminés.
Les étapes. L’expression génique se fait en 2 étapes : la transcription et la traduction. Transcription. Synthèse d ARN messager (ARNm) sous la direction de l ADN. On passe du langage ADN au langage ARN (langage semblable de «nucléotides») La transcription produit aussi d’autres types d’ARN (de transfert, ribosomique, petit ARN nucléaire…) ayant divers rôles. Traduction. Synthèse d un polypeptide à partir d’un ARN messager. On passe du langage ARN au langage des protéines : les acides aminés.")
43
B) Différences générales de la transcription et de la traduction chez les cellules Procaryotes et Eucaryotes Bactérie (cellule procaryote) La transcription et la traduction se produisent quasi simultanément dans le compartiment de la zone nucléoïde. La transcription produit un ARNm mature, traduit immédiatement en chaîne polypeptidique «dans les ribosomes de la zone nucléoïde». Processus très très rapide. Cellule eucaryote La transcription et la traduction se produisent l'une après l'autre dans le compartiment du noyau puis dans le compartiment du cytoplasme. La transcription produit un ARNm immature « transcrit primaire — ARNpm » qui doit subir des transformations pour devenir un ARNm. L’ARNm passe ensuite du compartiment du noyau vers le compartiment du cytoplasme afin d’être traduit en chaîne polypeptidique «dans les ribosomes». Tous les types d'ARN sont d’abord des «transcrits primaires». Processus beaucoup plus long.
 La transcription et la traduction se produisent quasi simultanément dans le compartiment de la zone nucléoïde. La transcription produit un ARNm mature, traduit immédiatement en chaîne polypeptidique «dans les ribosomes de la zone nucléoïde». Processus très très rapide. Cellule eucaryote. La transcription et la traduction se produisent l une après l autre dans le compartiment du noyau puis dans le compartiment du cytoplasme. La transcription produit un ARNm immature « transcrit primaire — ARNpm » qui doit subir des transformations pour devenir un ARNm. L’ARNm passe ensuite du compartiment du noyau vers le compartiment du cytoplasme afin d’être traduit en chaîne polypeptidique «dans les ribosomes». Tous les types d ARN sont d’abord des «transcrits primaires». Processus beaucoup plus long.")
44
Bactérie Cellule eucaryote ADN ADN Transcription ARNpm Transcription
Noyau Transcription Transcription ARNpm ARNm Traduction Maturation ARNm Traduction Ribosome Cytoplasme Chaîne polypeptidique Ribosome Chaîne polypeptidique

45
10. L’information génétique est codée dans le code dit «génétique»
A)Le code génétique, un code à triplets, est qualifié de code car il doit être décrypté en acides aminés Le code Est formé de triplets de nucléotides ADN : les génons. Le décryptage Les génons sont déchiffrés en triplets de nucléotides d’ARNm : les codons. Les codons sont déchiffrés en triplets de nucléotides d’ARNt (ARN de transfert) : les anticodons. 3) Les anticodons sont déchiffrés en «acides aminés». Au cours de la transcription, un seul des deux brins d'ADN est transcrit en ARN — dit « brin codant». L’autre brin est dit «non codant». Un brin codant pour un gène donné peut servir de brin non codant pour un autre gène.
Le code génétique, un code à triplets, est qualifié de code car il doit être décrypté en acides aminés. Le code. Est formé de triplets de nucléotides ADN : les génons. Le décryptage. Les génons sont déchiffrés en triplets de nucléotides d’ARNm : les codons. Les codons sont déchiffrés en triplets de nucléotides d’ARNt (ARN de transfert) : les anticodons. 3) Les anticodons sont déchiffrés en «acides aminés». Au cours de la transcription, un seul des deux brins d ADN est transcrit en ARN — dit « brin codant». L’autre brin est dit «non codant». Un brin codant pour un gène donné peut servir de brin non codant pour un autre gène.")
46
Brin codant de l’ADN GÉNON Brin ARNpm ou ARNm CODON Brins ARNt
A G T Brin ARNpm ou ARNm U C A CODON Brins ARNt A G U ANTICODON Ser Polypeptide Acide aminé

47
61 codons codent un acide aminé
Par convention, le terme «code génétique» est restreint à la liste des codons (ARNm) et des acides aminés qu’ils déterminent. Le seul qui doive être appelé code génétique. Tous autres correspondances , bases ADN avec bases ARN ou bases ADN et acides aminés, ne doivent pas être appelées ainsi. C) Soixante quatre (64) codons d'ARNm ont été identifiés par les chercheurs ( ) 61 codons codent un acide aminé un codon signale le début de la traduction (codon de départ) mais aussi code pour l'acide aminé «méthionine» — ainsi, toutes les chaînes polypeptidiques commencent par la méthionine trois codons indiquent la fin de la traduction (codons d'arrêt) — aucun acide aminé peut être ajouté lors de la lecture de ces codons
 et des acides aminés qu’ils déterminent. Le seul qui doive être appelé code génétique. Tous autres correspondances , bases ADN avec bases ARN ou bases ADN et acides aminés, ne doivent pas être appelées ainsi. C) Soixante quatre (64) codons d ARNm ont été identifiés par les chercheurs ( ) 61 codons codent un acide aminé. un codon signale le début de la traduction (codon de départ) mais aussi code pour l acide aminé «méthionine» — ainsi, toutes les chaînes polypeptidiques commencent par la méthionine. trois codons indiquent la fin de la traduction (codons d arrêt) — aucun acide aminé peut être ajouté lors de la lecture de ces codons.")
48
61 codons codent un acide aminé
D)Le dictionnaire du code génétique (64 codons et leurs acides aminés) 61 codons codent un acide aminé 3 codons ne codent pas d’acides aminés et servent de codons d’arrêt 1 codon code la méthionine et sert de codon de départ
Le dictionnaire du code génétique (64 codons et leurs acides aminés) 61 codons codent un acide aminé. 3 codons ne codent pas d’acides aminés et servent de codons d’arrêt. 1 codon code la méthionine et sert de codon de départ.")
49
E) Le code génétique est redondant (code dégénéré)
Plusieurs codons codent le même acide aminé bien qu’un seul «à la fois» soit nécessaire pour la mise en place de l’acide aminé dans la protéine. Rôle de la redondance Minimise les effets néfastes des mutations ! Si un changement dans l’ADN (mutation) entraîne la mise en place d’un autre codon mais que ce dernier code pour le même acide aminé que le codon d’origine, alors, la mutation ne s’exprime pas «silencieuse».
 entraîne la mise en place d’un autre codon mais que ce dernier code pour le même acide aminé que le codon d’origine, alors, la mutation ne s’exprime pas «silencieuse».")
50
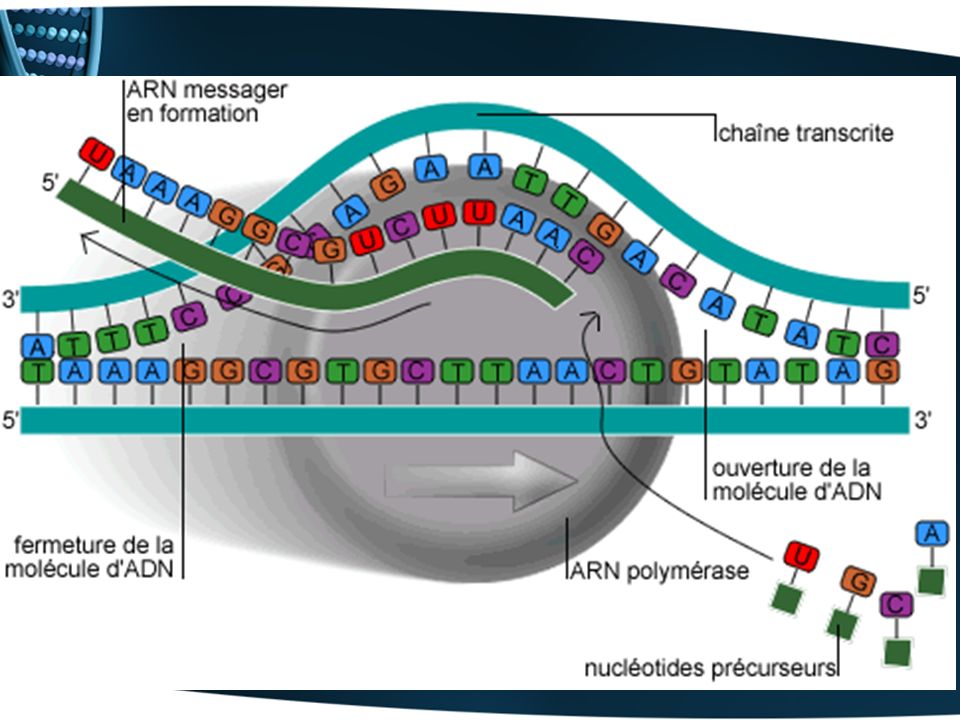
Le gène à transcrire ou l’unité de transcription (3 parties) :
11. Étude de la transcription : synthèse de l’ARN à partir de l’ADN (via l’ARN polymérase) A) Les composants moléculaires de la transcription Le gène à transcrire ou l’unité de transcription (3 parties) : Le promoteur (plusieurs douzaines de nucléotides en amont du gène). Sert de point d’ancrage pour l’enzyme de transcription, spécifie le début de la transcription (ajout du premier nucléotide). Une partie codante ; plus précisément le brin codant ADN. Matrice pour la synthèse de l’ARN La région terminale (plusieurs douzaines de nucléotides en aval du gène). Libère l’ARN synthétisé et l’ARN polymérase. L’enzyme de transcription : l'ARN polymérase Les nucléosides triphosphate d’ARN ATP (adénosine triphosphate), UTP (UridineTP), GTP (GuanosineTP) et CTP (CytidineTP).
 A) Les composants moléculaires de la transcription. Le gène à transcrire ou l’unité de transcription (3 parties) : Le promoteur (plusieurs douzaines de nucléotides en amont du gène). Sert de point d’ancrage pour l’enzyme de transcription, spécifie le début de la transcription (ajout du premier nucléotide). Une partie codante ; plus précisément le brin codant ADN. Matrice pour la synthèse de l’ARN. La région terminale (plusieurs douzaines de nucléotides en aval du gène). Libère l’ARN synthétisé et l’ARN polymérase. L’enzyme de transcription : l ARN polymérase. Les nucléosides triphosphate d’ARN ATP (adénosine triphosphate), UTP (UridineTP), GTP (GuanosineTP) et CTP (CytidineTP).")
51
Amont Aval Promoteur Région terminale
B) La transcription du gène produit un transcrit d’ARN (un fidèle reflet de l’unité de transcription) UNITÉ DE TRANSCRIPTION (ADN) 5’ 3’ Promoteur Brin non codant du gène Brin codant du gène Région terminale 3’ 5’ GD GA Génons DÉPART DE LA TRANSCRIPTION LE TRANSCRIT (ARN) 5’ 5’UTR 3’UTR 3’ Copie d’une partie du promoteur Copie de la région terminale CD CA Codons Copie du brin codant (portion de l’ARN qui sera traduite en polypeptide) GD : génon de départ GA : génon d’arrêt CD : codon de départ CA : codon d’arrêt UTR = UnTranslated Region = région non traduite
 La transcription du gène produit un transcrit d’ARN (un fidèle reflet de l’unité de transcription) UNITÉ DE TRANSCRIPTION (ADN) 5’ 3’ Promoteur. Brin non codant du gène. Brin codant du gène. Région terminale. 3’ 5’ GD. GA. Génons. DÉPART DE LA TRANSCRIPTION. LE TRANSCRIT (ARN) 5’ 5’UTR. 3’UTR. 3’ Copie d’une partie du promoteur. Copie de la région terminale. CD. CA. Codons. Copie du brin codant (portion de l’ARN qui sera traduite. en polypeptide) GD : génon de départ GA : génon d’arrêt. CD : codon de départ CA : codon d’arrêt. UTR = UnTranslated Region. = région non traduite.")
52
De manière antiparallèle par rapport à l’ADN copié
C) Le processus de la transcription Initiation L’ARN polymérase se lie au promoteur du gène. Les deux brins d'ADN se déroulent à cet endroit (bris des liens hydrogène) et la transcription commence. Élongation Dans le sens 5’-3’ De manière antiparallèle par rapport à l’ADN copié De façon complémentaire La polymérase déroule le brin codant et expose 10 à 20 bases à la fois. Des nucléosides tri-P d'ARN (synthétisés dans le cytoplasme puis entrés dans le noyau) s'apparient aux bases (A U et G C). Une fois appariés, les nucléosides sont polymérisés par des liens phosphodiester. Derrière la vague de synthèse, l'ARN se détache et l'ADN se réenroule. Terminaison La transcription se poursuit jusqu'à la fin de la région terminale. Le transcrit d’ARN et la polymérase sont libérés.
 Le processus de la transcription. Initiation L’ARN polymérase se lie au promoteur du gène. Les deux brins d ADN se déroulent à cet endroit (bris des liens hydrogène) et la transcription commence. Élongation. Dans le sens 5’-3’ De manière antiparallèle par rapport à l’ADN copié. De façon complémentaire. La polymérase déroule le brin codant et expose 10 à 20 bases à la fois. Des nucléosides tri-P d ARN (synthétisés dans le cytoplasme puis entrés dans le noyau) s apparient aux bases (A U et G C). Une fois appariés, les nucléosides sont polymérisés par des liens phosphodiester. Derrière la vague de synthèse, l ARN se détache et l ADN se réenroule. Terminaison La transcription se poursuit jusqu à la fin de la région terminale. Le transcrit d’ARN et la polymérase sont libérés.")
54
Notez bien La transcription se produit seulement quand la cellule a besoin d’une protéine particulière ou d’un ARN particulier, autre que l’ARNm. Spécification quant à l’enzyme de transcription : ARN polymérase chez les Procaryotes et ARN polymérase II chez les Eucaryotes (les Eucaryotes ont aussi de l’ARN polymérase I et III) . Fixation de l’enzyme au promoteur : directement chez les Procaryotes et par l’intermédiaire de facteurs de transcription chez les Eucaryotes Détachement de la polymérase : en même temps que l’ARNm des Procaryotes mais après la libération de l’ARNpm des Eucaryotes (l’enzyme continue sur une centaine de nucléotides, environ la zone qu’il couvre). Pas de correction d'épreuve par l’ARN polymérase comme le fait l’ADN polymérase. Vitesse de transcription des Eucaryotes = ± 60 nucléotides /sec. L’ARNm est une petite molécule (copie d’une petite portion d’ADN). L’ARNm est constitué d’une chaîne de nucléotides car il est fabriqué par copie d’un seul brin : le codant. Taux des erreurs de transcription environ 1 base /100 bases Un gène peut être transcrit simultanément par plusieurs polymérases.
 . Fixation de l’enzyme au promoteur : directement chez les Procaryotes et par l’intermédiaire de facteurs de transcription chez les Eucaryotes. Détachement de la polymérase : en même temps que l’ARNm des Procaryotes mais après la libération de l’ARNpm des Eucaryotes (l’enzyme continue sur une centaine de nucléotides, environ la zone qu’il couvre). Pas de correction d épreuve par l’ARN polymérase comme le fait l’ADN polymérase. Vitesse de transcription des Eucaryotes = ± 60 nucléotides /sec. L’ARNm est une petite molécule (copie d’une petite portion d’ADN). L’ARNm est constitué d’une chaîne de nucléotides car il est fabriqué par copie d’un seul brin : le codant. Taux des erreurs de transcription environ 1 base /100 bases. Un gène peut être transcrit simultanément par plusieurs polymérases.")
55
Rôles des extrémités modifiées
D)Maturation du transcrit des Eucaryotes Le transcrit primaire des Eucaryotes subit des transformations avant sa traduction : ajout d’une coiffe, ajout d’une queue et coupures. Modification des extrémités du transcrit Rôles des extrémités modifiées Ajout d’une coiffe de guanosine (— CH3) à l’extrémité 5’ . Mise en place rapide, avant même la fin de la transcription. Aident la fixation de l’ARNm à un ribosome dans le cytoplasme. Facilitent le transport de l'ARNm mature vers l’extérieur du noyau. Semblent contribuer à protéger l'ARNm de la dégradation enzymatique. Ajout d’une queue poly-A à l’extrémité 3’ (de 50 à 250 nucléotides d’adénine). Dès la fin de la transcription, avant même que l’ARN ne quitte le noyau.
Maturation du transcrit des Eucaryotes. Le transcrit primaire des Eucaryotes subit des transformations avant sa traduction : ajout d’une coiffe, ajout d’une queue et coupures. Modification des extrémités du transcrit. Rôles des extrémités modifiées. Ajout d’une coiffe de guanosine. (— CH3) à l’extrémité 5’ . Mise en place rapide, avant même la. fin de la transcription. Aident la fixation de l’ARNm à un ribosome dans le cytoplasme. Facilitent le transport de l ARNm mature vers l’extérieur du noyau. Semblent contribuer à protéger l ARNm de la dégradation enzymatique. Ajout d’une queue poly-A à l’extrémité. 3’ (de 50 à 250 nucléotides d’adénine). Dès la fin de la transcription, avant même que l’ARN. ne quitte le noyau.")
56
Gène à transcrire (brin codant de l’ADN)
Résumé I Intron 5’ UTR E Exon 3’ UTR CA CD AUG AAAAAAAAAAA Gène à transcrire (brin codant de l’ADN) ARNpm Transcription Maturation de l’ARN Ajout coiffe 5’ et queue 3’ Traduction Épissage ATT ACT ATC UAA UGA UAG Polypeptide (Chaîne d’acides aminés) ARN m «mature» NOYAU CYTOPLASME 3’ Promoteur Région terminale 5’ GA GD TAC Coiffe (guanine) Queue poly-A @ Féry ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| M7•G I = Intron Région non codante E = Exon Dans ce schéma nous avons (6) codons dans l’ARNm mais (5) acides aminés dans le polypeptide. Le codon d’arrêt marque la fin de la traduction.
 ARNpm. Transcription. Maturation de l’ARN. Ajout coiffe 5’ et queue 3’ Traduction. Épissage. ATT. ACT. ATC. UAA. UGA. UAG. Polypeptide. (Chaîne d’acides aminés) ARN m «mature» NOYAU. CYTOPLASME. 3’ Promoteur. Région terminale 5’ GA. GD. TAC. Coiffe (guanine) Queue Féry. ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| ||| M7•G. I = Intron. Région. non. codante. E = Exon. Dans ce schéma nous avons (6) codons dans l’ARNm mais (5) acides aminés dans le polypeptide. Le codon d’arrêt marque la fin de la traduction.")
57
Coupure des introns du transcrit «épissage»
Le transcrit contient des sections non codantes (les introns) et des sections codantes (les exons). L'épissage consiste à enlever les introns puis à recoller les exons. Les introns restent à l'intérieur du noyau puis sont dégradés. La longueur moyenne du transcrit est d’environ 8000 nucléotides. Après l’épissage, il mesure environ 1200 nucléotides ce qui suffira à coder une protéine de taille moyenne de 400 acides aminés. Rôle de l’épissage Permet à un gène de coder pour plusieurs polypeptides. En effet, le regroupement des exons selon diverses combinaisons produit divers ARN aboutissant à des chaînes polypeptidiques différentes. L'épissage différentiel explique pourquoi il y a beaucoup plus de sortes de protéines que de gènes (± pour ± gènes humain).
 et des sections codantes (les exons). L épissage consiste à enlever les introns puis à recoller les exons. Les introns restent à l intérieur du noyau puis sont dégradés. La longueur moyenne du transcrit est d’environ 8000 nucléotides. Après l’épissage, il mesure environ 1200 nucléotides ce qui suffira à coder une protéine de taille moyenne de 400 acides aminés. Rôle de l’épissage. Permet à un gène de coder pour plusieurs polypeptides. En effet, le regroupement des exons selon diverses combinaisons produit divers ARN aboutissant à des chaînes polypeptidiques différentes. L épissage différentiel explique pourquoi il y a beaucoup plus de sortes de protéines que de gènes (± pour ± gènes humain).")
58
Segment codant pour la protéine M7-Gppp
Un groupement méthyle «CH3» est ajouté en position —7 de la guanine Brin de l’ARNm ou plus précisément de l’ARNpm. Coiffe 5’ Segment codant pour la protéine Queue poly-A M7-Gppp 5’UTR 3’UTR Codon de départ Codon d’arrêt Notez bien. Les groupes phosphate de la coiffe font partie intégrante du transcrit primaire. Ils sont cependant inclus dans les modifications complexes qui mènent à la coiffe.

59
12. Étude de la traduction : synthèse d’un polypeptide à partir de l’ARNm (via les ARN du ribosome)
A) Les composants moléculaires de la traduction Le brin d'ARN messager (mâture). Contient les codons qui déterminent la liste des acides aminés de la chaîne polypeptidique. Des acides aminés. De nombreux exemplaires des 20 types d'acides aminés (a.a.) sont présents dans le cytosol. La plupart proviennent des voies anaboliques mais huit d’entre eux doivent absolument être absorbés dans la nourriture car le corps ne peut les fabriquer. Des ARN de transfert (ARNt). Acheminent les acides aminés du cytosol vers le ribosome. Un ribosome. Contient l’ARNr (ribosomique) et les protéines enzymatiques nécessaires à la polymérisation (ou union) d’acides aminés en polypeptide.
 Les composants moléculaires de la traduction. Le brin d ARN messager (mâture). Contient les codons qui déterminent la liste des acides aminés de la chaîne polypeptidique. Des acides aminés. De nombreux exemplaires des 20 types d acides aminés (a.a.) sont présents dans le cytosol. La plupart proviennent des voies anaboliques mais huit d’entre eux doivent absolument être absorbés dans la nourriture car le corps ne peut les fabriquer. Des ARN de transfert (ARNt). Acheminent les acides aminés du cytosol vers le ribosome. Un ribosome. Contient l’ARNr (ribosomique) et les protéines enzymatiques nécessaires à la polymérisation (ou union) d’acides aminés en polypeptide.")
60
Signal de fin de traduction
B) La traduction de l’ARN messager produit un polypeptide. Le polypeptide reflète ainsi l’ARNm ! (L’ARNm reflète, quant à lui, le brin codant de l’ADN.) ARNm «ARN mature» 5’UTR CD Codons CA 3’UTR M7•G AAA… AUGCUUCAGAGGCUGUAA Quelle est la séquence de ce polypeptide ? (Servez-vous du dictionnaire du code génétique) Signal de fin de traduction Met— Leu— Gln— Arg— Leu Notez qu’il y a au moins deux codons de terminaison et même plus !
 La traduction de l’ARN messager produit un polypeptide. Le polypeptide reflète ainsi l’ARNm ! (L’ARNm reflète, quant à lui, le brin codant de l’ADN.) ARNm «ARN mature» 5’UTR. CD. Codons. CA. 3’UTR. M7•G. AAA… AUGCUUCAGAGGCUGUAA. Quelle est la séquence de ce polypeptide (Servez-vous du dictionnaire du code génétique) Signal de fin de traduction. Met— Leu— Gln— Arg— Leu. Notez qu’il y a au moins deux codons de terminaison et même plus !")
61
La molécule d'ARN messager se fixe à un ribosome.
C)Résumé de la traduction (concept de base) La molécule d'ARN messager se fixe à un ribosome. Le Ribosome traverse l’ARNm , codon par codon. Chaque fois qu'un codon est lu par le ribosome, une molécule d'ARN de transfert spécifique (ARNt) apporte un acide aminé spécifique — via son anticodon(1) et via des liaisons H — en respectant les règles de complémentarité A/U et G/C Pour déterminer l’acide aminé apporté par un ARNt, il faut utiliser le dictionnaire du code génétique. Ainsi, l'ARNt ayant l'anticodon AAA porte la phénylalanine car le dictionnaire nous dit que le codon appariable avec cet anticodon « UUU» code pour cet acide aminé. Chaque dépôt d'acide aminé dans le ribosome est suivi de son union avec la chaîne polypeptidique en formation, via une liaison peptidique. Quand tous les codons ARNm ont été lus, la chaîne est terminée. (1) Anticodon : triplet de nucléotides ARNt complémentaire à un codon ARNm
Résumé de la traduction (concept de base) La molécule d ARN messager se fixe à un ribosome. Le Ribosome traverse l’ARNm , codon par codon. Chaque fois qu un codon est lu par le ribosome, une molécule d ARN de transfert spécifique (ARNt) apporte un acide aminé spécifique — via son anticodon(1) et via des liaisons H — en respectant les règles de complémentarité A/U et G/C Pour déterminer l’acide aminé apporté par un ARNt, il faut utiliser le dictionnaire du code génétique. Ainsi, l ARNt ayant l anticodon AAA porte la phénylalanine car le dictionnaire nous dit que le codon appariable avec cet anticodon « UUU» code pour cet acide aminé. Chaque dépôt d acide aminé dans le ribosome est suivi de son union avec la chaîne polypeptidique en formation, via une liaison peptidique. Quand tous les codons ARNm ont été lus, la chaîne est terminée. (1) Anticodon : triplet de nucléotides ARNt complémentaire à un codon ARNm.")
62
Polypeptide en formation
Acides aminés ARNt LP Ribosome 3’ Anticodon 5’ ARNm 5’ 3’ Codon LP : Lien peptidique

63
D) L’ARN de transfert, un des composants moléculaires de la traduction
Origine de l'ARN de transfert (ARNt) Produit par transcription de l'ADN. Le brin d'ARN (environ 80 nucléotides de long) quitte le noyau et va dans le cytosol chez les cellules eucaryotes. Une navette à acide aminé Se lie à l'acide aminé qui lui est spécifique puis l’apporte au ribosome. Redevenu libre, il retourne se lier à un autre acide aminé et le rapporte encore. Recommence plusieurs fois avant d'être dégradé. Repliement de la molécule et forme Le brin se replie à cause d'appariement entre certaines bases complémentaires via des liaisons hydrogène. Cela lui confère une forme tridimentionnelle : un «L» inversé.
 Produit par transcription de l ADN. Le brin d ARN (environ 80 nucléotides de long) quitte le noyau et va dans le cytosol chez les cellules eucaryotes. Une navette à acide aminé. Se lie à l acide aminé qui lui est spécifique puis l’apporte au ribosome. Redevenu libre, il retourne se lier à un autre acide aminé et le rapporte encore. Recommence plusieurs fois avant d être dégradé. Repliement de la molécule et forme. Le brin se replie à cause d appariement entre certaines bases complémentaires via des liaisons hydrogène. Cela lui confère une forme tridimentionnelle : un «L» inversé.")
64
Site de liaison pour un acide aminé «spécifique»
La molécule possède trois boucles jouant chacune un rôle. En écrasant l’ARNt, la molécule prend la forme d’un trèfle. Les trois feuilles du trèfle (trois boucles) jouent des rôles importants. Site de liaison pour un acide aminé «spécifique» Boucle pour l’enzyme aidant la liaison de l’ARNt à son acide aminé A C C Des bases inhabituelles empêchent les appariements en créant des boucles. Boucle qui se fixe au ribosome Boucle contenant l’anticodon. Partie spécifique à chaque type d’ARNt, le reste de la molécule étant identique pour tous ARNt. 3’ — AAG — 5’
 jouent des rôles importants. Site de liaison pour un acide aminé «spécifique» Boucle pour l’enzyme aidant la liaison de l’ARNt à son acide aminé. A C C. Des bases inhabituelles empêchent les appariements en créant des boucles. Boucle qui se fixe au ribosome. Boucle contenant l’anticodon. Partie spécifique à chaque type d’ARNt, le reste de la molécule étant identique pour tous ARNt. 3’ — AAG — 5’")
65
a.a. Deux rôles de l’ARNt ENZYME Se lier à son acide aminé spécifique (à son anticodon) Avec l’aide de l'enzyme : aminoacyl- ARNt synthétase et l'énergie de l'ATP. Comme il existe 20 types d’acides aminés différents, il faut autant d'enzymes différents dans la cellule, soit un par acide aminé. Porter cet acide aminé dans le ribosome Via l'association de l'anticodon au codon approprié de l'ARNm. Acide aminé «activé» ARNt Libération du reste de l’ATP : de l’AMP ARNt lié à son acide aminé spécifique
 Avec l’aide de l enzyme : aminoacyl- ARNt synthétase et l énergie de l ATP. Comme il existe 20 types d’acides aminés différents, il faut autant d enzymes différents dans la cellule, soit un par acide aminé. Porter cet acide aminé dans le ribosome Via l association de l anticodon au codon approprié de l ARNm. Acide aminé «activé» ARNt. Libération du reste de l’ATP : de l’AMP. ARNt lié à son acide aminé spécifique.")
66
Relâchement des règles d’appariement : Environ 45 sortes d’ARNt différents dans la cellule suffisent à reconnaître les 61 codons codants d’ARNm. À cause du relâchement des règles d’appariement. A G La base U peut s’apparier avec A ou G en troisième position. L’inosine (une base azotée inhabituelle) peut s’apparier avec A, U ou C en troisième position. A U C
 peut s’apparier avec A, U ou C en troisième position. A. U. C.")
67
E)Le ribosome, l’organite où se produit la traduction
Structure du ribosome Formé de deux sous-unités — chacune contient des protéines et de l'ARN ribosomique (ARNr). Le deux tiers du ribosome est constitué d'ARNr. Modèle informatisé d’un ribosome bactérien 3 filaments ARNr Polypeptide en voie de synthèse ARNm Petite sous-unité Grosse sous-unité Ribosome procaryote 70S Plus petit Grosse sous-unité 50S : 2 filaments ARNr et 31 protéines Petite sous-unité 30S : 1 filament ARNr et 21 protéines Ribosome eucaryote 80S Plus gros Grosse sous-unité 60S : 3 filaments ARNr et 50 protéines Petite sous-unité 40S : 1 filament ARNr et 33 protéines S est une constante de sédimentation : elle reflète la masse des ARN r
. Le deux tiers du ribosome est constitué d ARNr. Modèle informatisé d’un ribosome bactérien. 3 filaments ARNr. Polypeptide en voie de synthèse. ARNm. Petite sous-unité. Grosse sous-unité. Ribosome procaryote. 70S. Plus petit. Grosse sous-unité 50S : 2 filaments ARNr et 31 protéines. Petite sous-unité 30S : 1 filament ARNr et 21 protéines. Ribosome eucaryote. 80S. Plus gros. Grosse sous-unité 60S : 3 filaments ARNr et 50 protéines. Petite sous-unité 40S : 1 filament ARNr et 33 protéines. S est une constante de sédimentation : elle reflète la masse des ARN r.")
68
Origine des ARN ribosomiques (ARNr)
Produits par transcription de certains gènes de l'ADN (ADN de la chromatine mais aussi, ADN dans le nucléole). Les transcrits subissent de la maturation. Production des sous-unités des ribosomes et exportation vers le cytosol L'assemblage des petits ARNr et des protéines (venues du cytosol) en sous-unités ribosomiques est fait par le nucléole. Les sous-unités sont exportées, individuellement, vers le cytosol. Se regroupent en ribosome fonctionnel lorsqu'ils se fixent à une molécule d'ARN messager.
. Les transcrits subissent de la maturation. Production des sous-unités des ribosomes et exportation vers le cytosol. L assemblage des petits ARNr et des protéines (venues du cytosol) en sous-unités ribosomiques est fait par le nucléole. Les sous-unités sont exportées, individuellement, vers le cytosol. Se regroupent en ribosome fonctionnel lorsqu ils se fixent à une molécule d ARN messager.")
69
Le ribosome contient quatre sites de liaisons :
La structure du ribosome reflète sa fonction qui est de rapprocher l’ARNm et les ARNt porteurs d'acides aminés Le ribosome contient quatre sites de liaisons : Grosse sous-unité Site P (site peptidyl-ARNt) — retenue de l'ARNt lié au polypeptide Site A (site aminoacyl-ARNt) — ajout de l'ARNt chargé d’un a. aminé Site E (site de sortie) — sortie de l'ARNt « vidé» de sa charge Petite sous-unité Site pour l’ARNm ou « site M » — agrippe l'ARNm au tout début de la traduction Site M : Utilisé pour faciliter l’étude mais n’est pas utilisé dans le volume !
 — retenue de l ARNt lié au polypeptide. Site A (site aminoacyl-ARNt) — ajout de l ARNt chargé d’un a. aminé. Site E (site de sortie) — sortie de l ARNt « vidé» de sa charge. Petite sous-unité. Site pour l’ARNm ou « site M » — agrippe l ARNm au. tout début de la traduction. Site M : Utilisé pour faciliter l’étude mais. n’est pas utilisé dans le volume !")
70
E P A M Lien peptidique Polypeptide en formation Site P
Retient l’ARNt lié au polypeptide en voie de synthèse. Acide aminé E P A M Site A Retient l’ARNt qui s’ajoute. Site E Permet la sortie de l’ARNt ayant fini «son job». Site M Agrippe l’ARNm au tout début de la traduction

71
Rapproche l'ARNm et les ARNt.
Les rôles du ribosome Rapproche l'ARNm et les ARNt. Place le nouvel acide aminé «dans le bon sens» : le groupement amine près du carboxyle du polypeptide. Catalyse la liaison peptidique entre les acides aminés qui s'ajoutent les uns à la suite des autres. H H | | HN — C — RX | C = O O H H | | H N — C — RX | C = O O H H | | N —C — RX | C = O O H RX H RX H H H H I I I I I I I I H— N— C— C— N— C— C— N— C — C — N— C— C I II I II I II I II H O H O RX O RX O Acide aminé 3’ 3’ 3’ 5’ 3’ 5’ Site P Site A AGC Site E CCC UUU AAA AGC UCG 3’ 5’

72
F)Les trois étapes de la traduction
Transformation des codons de l’ARNm en une chaîne polypeptidique. Requiert de nombreux facteurs protéiques. Consomme l’énergie de la GTP (guanosine triphosphate) Requiert l’activité enzymatique des ARN ribosomiques. Initiation Étape la plus longue et la plus complexe. Élongation Chaque cycle d’élongation lit un codon et ajoute un acide aminé à la chaîne polypeptidique. Terminaison Libère tous les «acteurs moléculaires de la traduction ainsi que le produit final «le polypeptide».
 Requiert l’activité enzymatique des ARN ribosomiques. Initiation. Étape la plus longue et la plus complexe. Élongation. Chaque cycle d’élongation lit un codon et ajoute un acide aminé à la chaîne polypeptidique. Terminaison. Libère tous les «acteurs moléculaires de la traduction ainsi que le produit final «le polypeptide».")
73
La grosse sous-unité se fixe ensuite (grâce à l’énergie de la GTP).
Grosso modo : L’ARNt d’initiation porteur de la méthionine «modifié par un groupement formyl» s’installe dans la petite sous-unité. La petite sous-unité branche l’ARN m dans son site «M» puis se déplace vers le «CD». L’ARNt d’initiation se lie au codon de départ via son anticodon. Il est au site «P». La grosse sous-unité se fixe ensuite (grâce à l’énergie de la GTP). INITIATION Groupe formyl Méthionine O H O I C — NH — C — C H R O F• Met— ARNt 3’ Au site P ARNt d’initiation Anticodon GTP GDP Site «M» E A CD Ribosome
. INITIATION. Groupe formyl. Méthionine. O H O. I. C — NH — C — C. H R O. F• Met— ARNt. 3’ Au site P. ARNt d’initiation. Anticodon. GTP. GDP. Site «M» E. A. CD. Ribosome.")
74
Reconnaissance d’un codon Un aa•ARNt s’ajoute au site A.
1 ÉLONGATION Durée : ± 0,1 sec Le ribosome et l’ARNm bougent ds le sens contraire. Début d’un nouveau cycle E A 3’ 5’ Lien peptidique P Translocation La chaîne•ARNt du site A passe au site P. Le site A est maintenant libre. L’ARNt du site P, ayant fini son «job», passe au site E puis se libère. 2 GTP 2 GDP ARNm Ribosome E A Le nouvel acide aminé est dans la chaîne. E P A P 3 Liaison peptidique Le lien se forme entre l’a.a. qui s’ajoute et la chaîne en formation. Transfert de la chaîne sur l’ARNt du site A. Catalyse par l’ARNr. 2 GDP GTP E A P

75
Les sous-unités du ribosome et l’ARNm sont libérés.
TERMINAISON Facteur de terminaison E P A A P Codon d’arrêt UAG, UAA ou UGA Les sous-unités du ribosome et l’ARNm sont libérés. 3 Le ribosome lit le codon d’arrêt. Une protéine de terminaison se lie au site A. Le facteur de terminaison hydrolyse le lien qui relie le polypeptide à l’ARNt. Le polypeptide se détache ainsi que le dernier ARNt. 2 1

76
13. Précisions quant à la synthèse protéique
Les 3 types d’ARN sont des outils qui servent plusieurs fois avant d'être dégradés. Les ARNt et les ribosomes sont semblables chez tous les eucaryotes. Les ARNm diffèrent entre les espèces car ils sont issus de gènes différents. Ils permettent la production des protéines spécifiques à chaque espèce. Une molécule d'ARNm se fait généralement traduire par plusieurs ribosomes simultanément. Le brin d’ARNm lu par plusieurs ribosomes prend le nom de «polyribosome» ou «polysome».

77
Un polyribosome Ribosomes ARNm MET d’un polyribosome La présence de polysomes dans une cellule signe une intense activité. De nombreuses copies d’un même type de polypeptide apparaît rapidement.

78
En présence d’une séquence «signal»
La synthèse de tout polypeptide débute dans un ribosome libre du cytosol mais la fin du processus dépend de la présence ou de l’absence d’une séquence «signal». En présence d’une séquence «signal» La synthèse s'interrompt. Le ribosome va se lier aux membranes externes du REG ou du noyau. La synthèse reprend. En absence d’une séquence «signal» la synthèse se produit entièrement dans le cytosol.

79
Protéines fabriquées par les ribosomes libres
Les protéines sécrétées par les deux populations de ribosomes ont une destinée différente. Protéines fabriquées par les ribosomes libres Fabriquent des protéines qui se dissolvent dans le cytosol où elles remplissent leurs fonctions ou se dirigent vers les organites qui ne font pas partie du réseau intracellulaire de membranes : peroxysomes, chloroplastes et mitochondries. Protéines fabriquées par les ribosomes «liés» Synthétisent les protéines du réseau intracellulaire de membranes : enveloppe nucléaire, RE, AG, lysosomes, vacuoles et membrane plasmique ainsi que celles qui doivent être sécrétées en dehors de la cellule.

80
Entrée du polypeptide dans la chaperonine.
Les modifications post-traductionnelles Les polypeptides «frais» doivent subir des transformations pour devenir véritablement fonctionnels. Les polypeptides se replient «spontanément» et adoptent leur conformation native. Ils ont tout de même besoin d’un chaperon moléculaire pour bien prendre forme. Entrée du polypeptide dans la chaperonine. Sortie du polypeptide avec la forme convenable

81
REG sucre les protéines «reçues» grâce aux enzymes de ses citernes.
2) Les polypeptides sont modifiés via divers enzymes. Beaucoup de ces modifications ont lieu dans le RER et l’AG. REG sucre les protéines «reçues» grâce aux enzymes de ses citernes. Entrée d’un polypeptide, dans la citerne du RER Vésicules de transition RER (CITERNE) GOLGI (SACCULES) MEMBRANE PLASMIQUE AG modifie les protéines qu'il reçoit grâce aux enzymes de ses saccules. Ces modifications sont fonction de la destinée du polypeptide. Exemples de modifications : Ajouts : sulfate, phosphate, glucides, lipides … Retraits : phosphates, sucres … Coupures : enlèvement d’acides aminés aux extrémités amine et ou carboxyle. Fragmentations : une chaîne est découpée en plusieurs protéines. Regroupements : plusieurs polypeptides synthétisés séparément s’unissent.
 Les polypeptides sont modifiés via divers enzymes. Beaucoup de ces modifications ont lieu dans le RER et l’AG. REG sucre les protéines «reçues» grâce aux enzymes de ses citernes. Entrée d’un polypeptide, dans la citerne du RER. Vésicules de transition. RER. (CITERNE) GOLGI. (SACCULES) MEMBRANE PLASMIQUE. AG modifie les protéines qu il reçoit grâce aux enzymes de ses saccules. Ces modifications sont fonction de la destinée du polypeptide. Exemples de modifications : Ajouts : sulfate, phosphate, glucides, lipides … Retraits : phosphates, sucres … Coupures : enlèvement d’acides aminés aux extrémités amine et ou carboxyle. Fragmentations : une chaîne est découpée en plusieurs protéines. Regroupements : plusieurs polypeptides synthétisés séparément s’unissent.")
82
MERCI

Présentations similaires