Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

2
Toutes les variables étaient mesurées au niveau intervalle et sans erreur Toutes les variables étaient mesurées au niveau intervalle et sans erreur -> Problème d'erreur de mesure La moyenne du terme d'erreur est zéro pour chaque ensemble de valeurs pour les k variables indépendantes La moyenne du terme d'erreur est zéro pour chaque ensemble de valeurs pour les k variables indépendantes La variance est constante pour chaque ensemble de valeurs pour les k variables indépendantes La variance est constante pour chaque ensemble de valeurs pour les k variables indépendantes -> Problème de hétérocédasticité Pour chaque paire d'ensembles de valeurs pour les k variables indépendantes les termes d'erreur ne sont pas corrélés, COV(ei, ei)= 0. => il n'y a pas d'auto-corrélation Pour chaque paire d'ensembles de valeurs pour les k variables indépendantes les termes d'erreur ne sont pas corrélés, COV(ei, ei)= 0. => il n'y a pas d'auto-corrélation Pour chaque variable indépendante la COV(Xi, e) = 0. C-à-d, les variables indépendantes ne sont pas corrélées avec le terme d'erreur Pour chaque variable indépendante la COV(Xi, e) = 0. C-à-d, les variables indépendantes ne sont pas corrélées avec le terme d'erreur -> Problème de spécification du modèle Il n'y a pas colinéarité parfaite. C-à-d, il n'y a pas une variable indépendante qui soit parfaitement linéairement liée à une ou plusieurs autres variables indépendantes Il n'y a pas colinéarité parfaite. C-à-d, il n'y a pas une variable indépendante qui soit parfaitement linéairement liée à une ou plusieurs autres variables indépendantes -> Problème de multicolinéarité Pour chaque ensemble de valeurs pour les k variables indépendantes, ei est distribuée normalement Pour chaque ensemble de valeurs pour les k variables indépendantes, ei est distribuée normalement
= 0. => il n y a pas d auto-corrélation Pour chaque variable indépendante la COV(Xi, e) = 0. C-à-d, les variables indépendantes ne sont pas corrélées avec le terme d erreur Pour chaque variable indépendante la COV(Xi, e) = 0. C-à-d, les variables indépendantes ne sont pas corrélées avec le terme d erreur -> Problème de spécification du modèle Il n y a pas colinéarité parfaite. C-à-d, il n y a pas une variable indépendante qui soit parfaitement linéairement liée à une ou plusieurs autres variables indépendantes Il n y a pas colinéarité parfaite. C-à-d, il n y a pas une variable indépendante qui soit parfaitement linéairement liée à une ou plusieurs autres variables indépendantes -> Problème de multicolinéarité Pour chaque ensemble de valeurs pour les k variables indépendantes, ei est distribuée normalement Pour chaque ensemble de valeurs pour les k variables indépendantes, ei est distribuée normalement.")
3
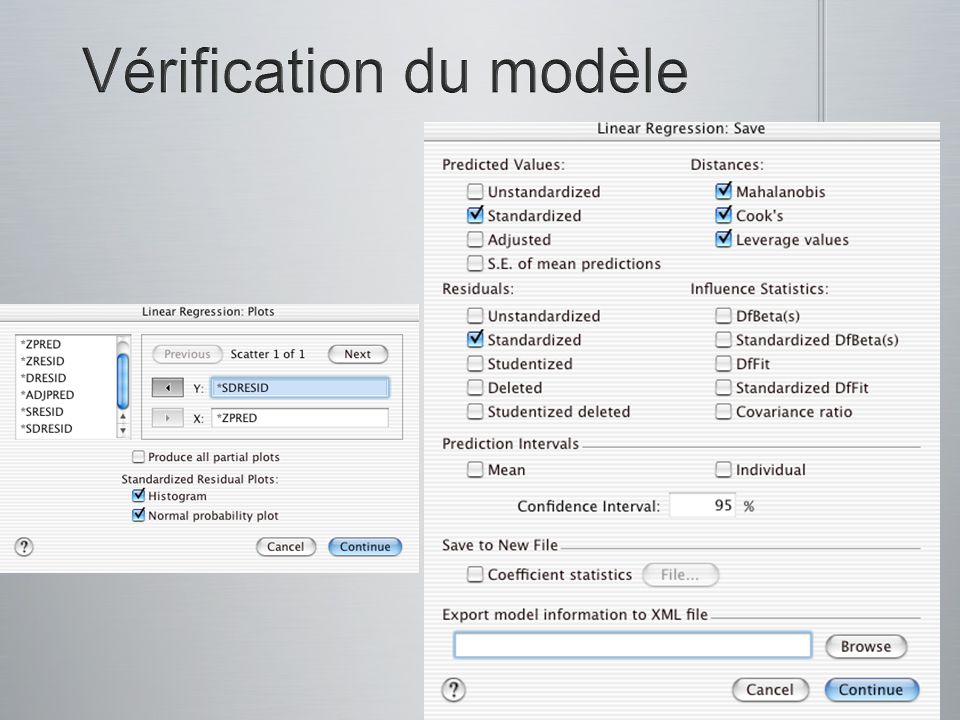
Vérifier les statistiques descriptives univariées Vérifier les statistiques descriptives univariées Valeurs impossibles (ex: valeur de 2 pour une variable 0-1) Valeurs impossibles (ex: valeur de 2 pour une variable 0-1) moyennes et écart-types improbables (ex: moyenne de moyennes et écart-types improbables (ex: moyenne de -900 pour une échelle de 1-7) outliers univariés outliers univariés Pourcentage des valeurs manquantes Pourcentage des valeurs manquantes Vérifier la linéarité Vérifier la linéarité Évaluer les outliers multivariés Évaluer les outliers multivariés Évaluer la multicolinéarité Évaluer la multicolinéarité
 Valeurs impossibles (ex: valeur de 2 pour une variable 0-1) moyennes et écart-types improbables (ex: moyenne de moyennes et écart-types improbables (ex: moyenne de -900 pour une échelle de 1-7) outliers univariés outliers univariés Pourcentage des valeurs manquantes Pourcentage des valeurs manquantes Vérifier la linéarité Vérifier la linéarité Évaluer les outliers multivariés Évaluer les outliers multivariés Évaluer la multicolinéarité Évaluer la multicolinéarité")
10
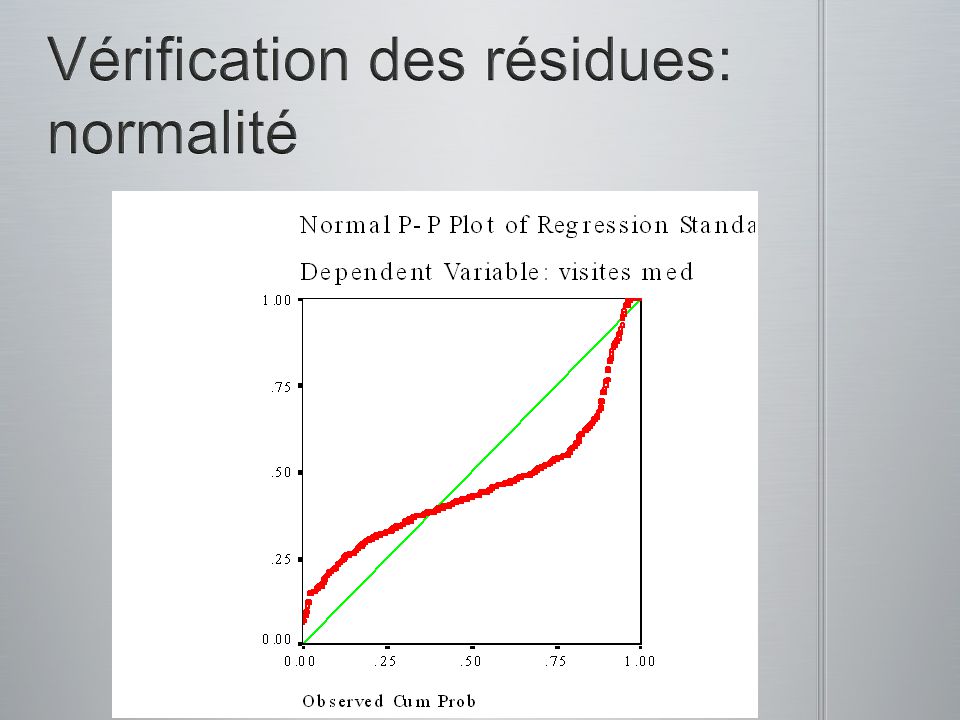
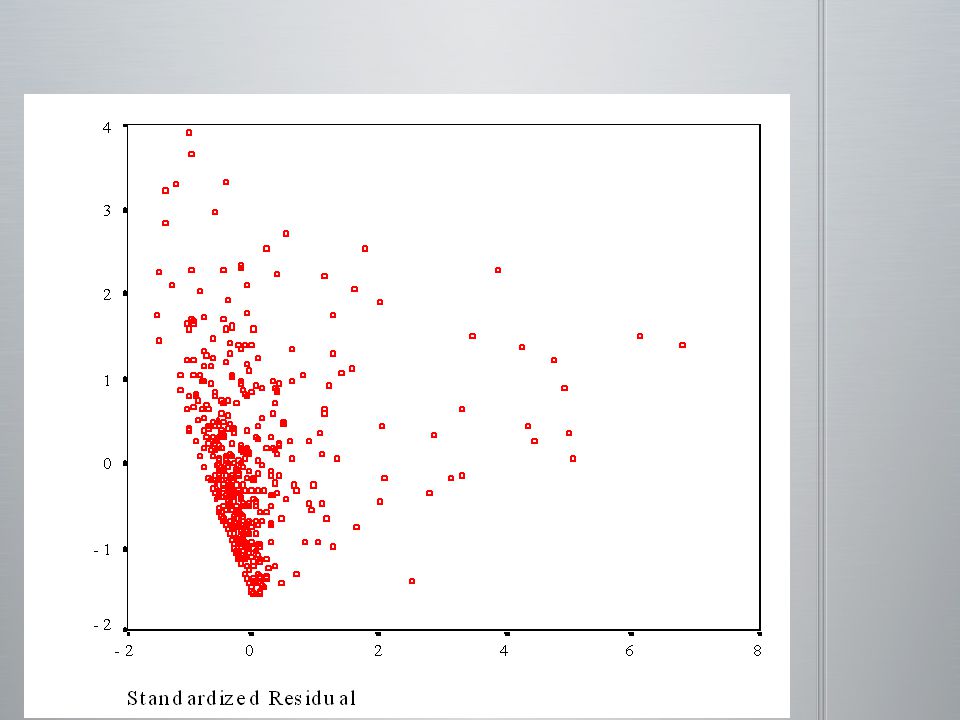
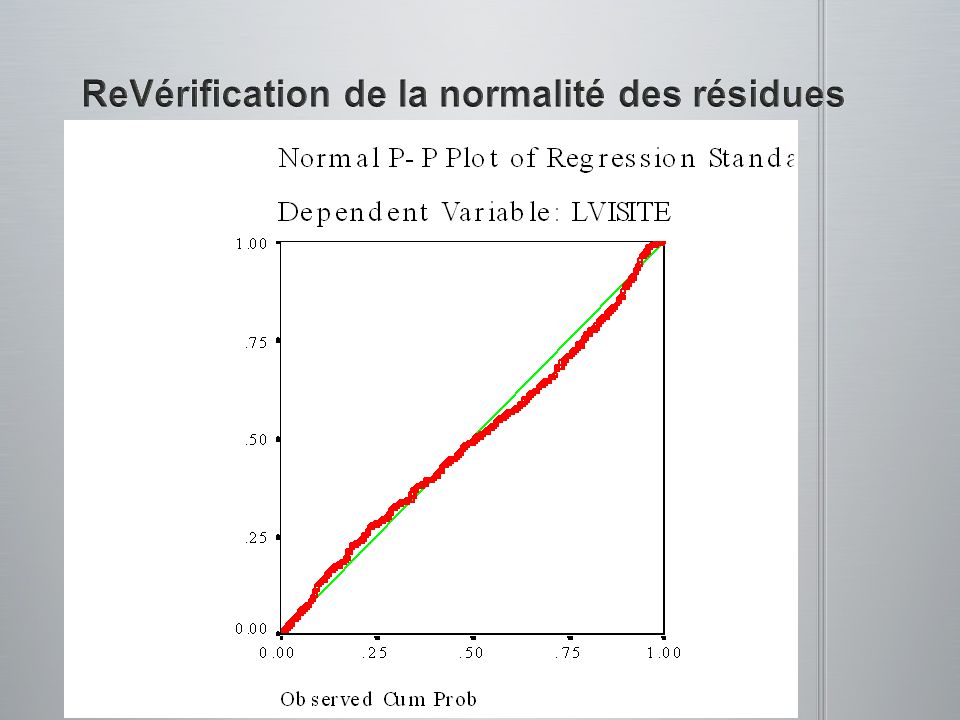
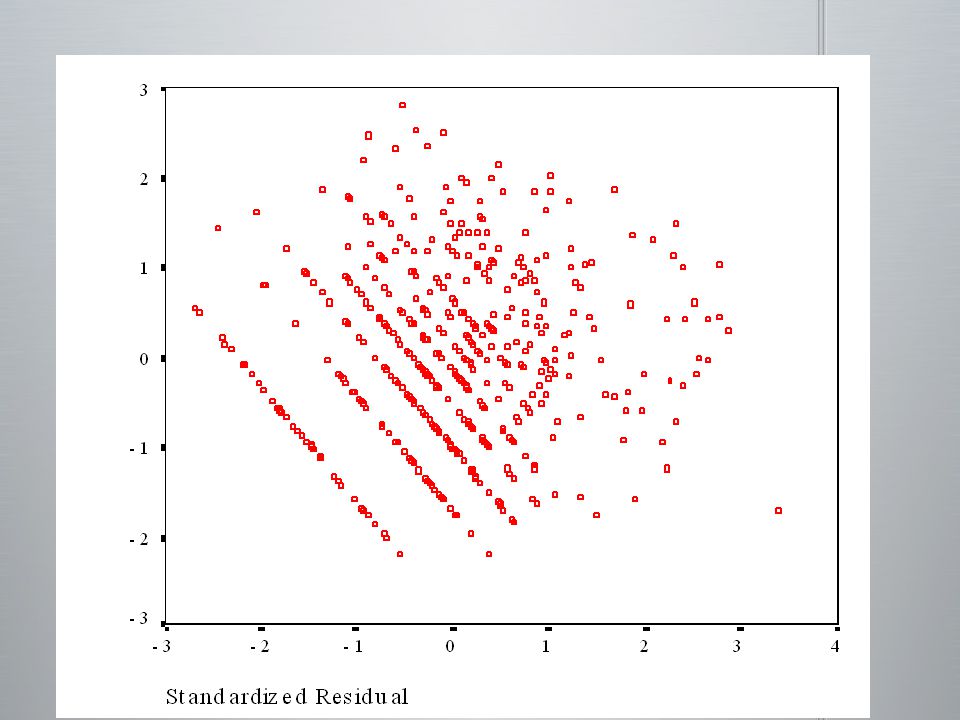
(a) postulats de base remplis (b) problème de non normalité (c) problème de non linéarité (d) problème de hétérocédasticité
 postulats de base remplis (b) problème de non normalité (c) problème de non linéarité (d) problème de hétérocédasticité")
11
compute lvisite = lg10(v2+1).
.")
12
compute sqstress = sqrt(v5).
.")
16
Valeur critique X 2 avec k df = 7.82

17
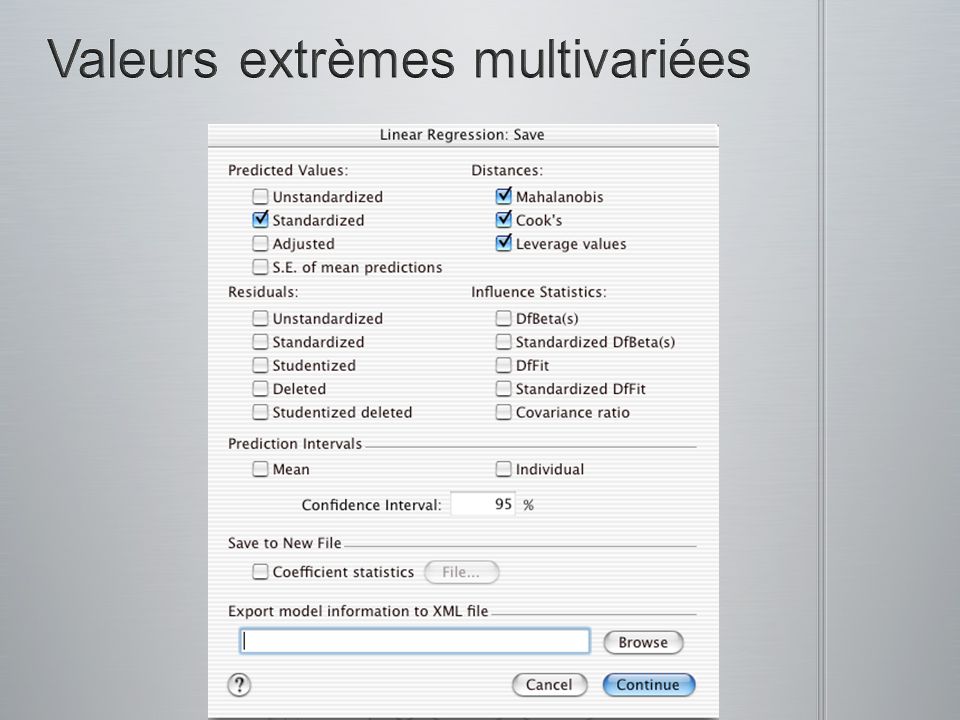
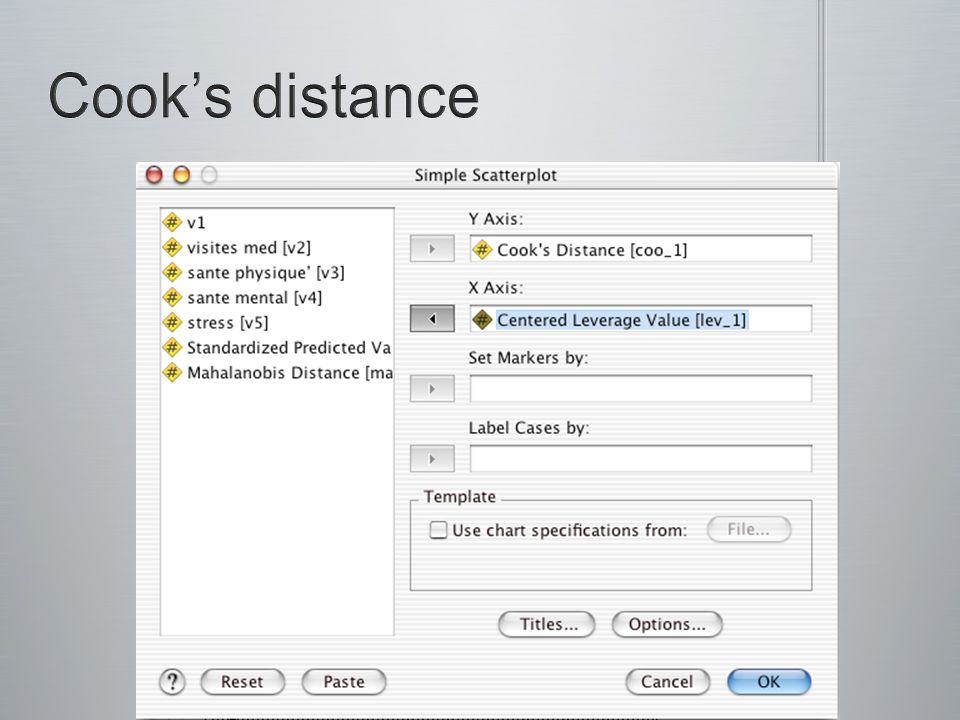
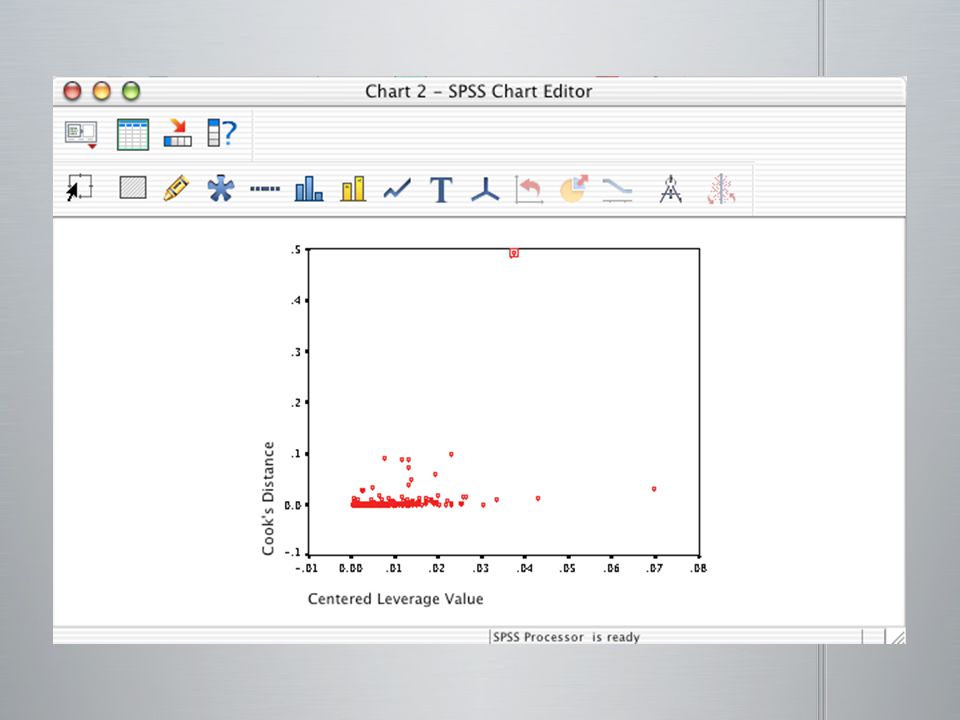
Valeurs extrêmes et données influentes

22
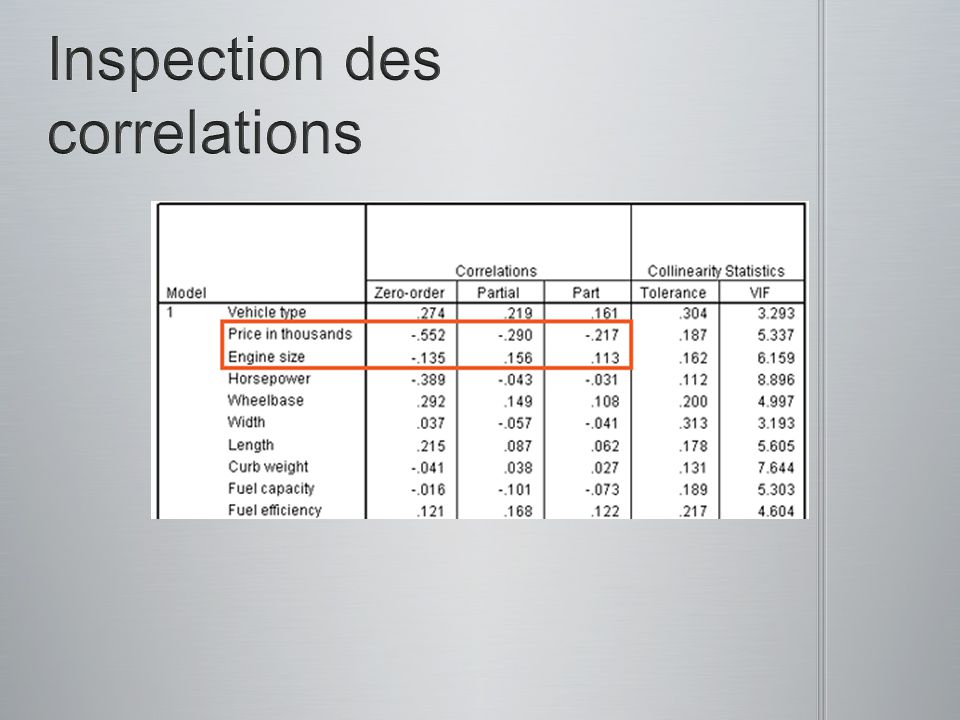
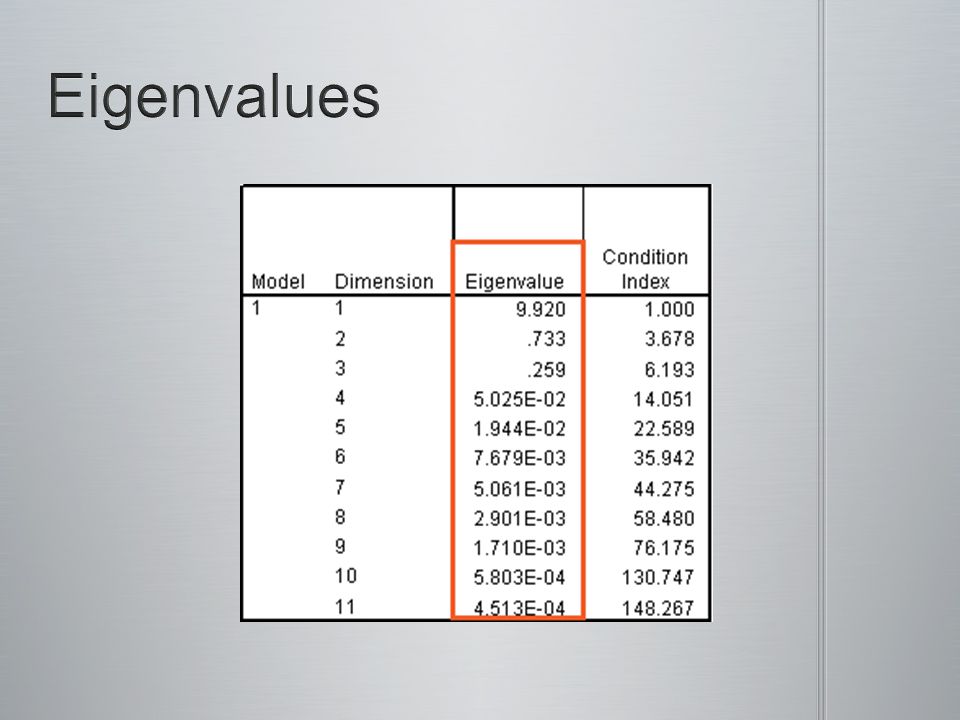
Le pourcentage de la variance qui est unique à un prédicteur

23
Valeur problématique: 2

25
Valeur problématique: 30

26
modèle de mesure: X j = X tj + u j modèle de mesure: X j = X tj + u j Xj - la variable observée Xj - la variable observée Xtj - la vrai valeur (true score) Xtj - la vrai valeur (true score) uj - lerreur; u a une moyenne de zéro et nest pas corrélé ni avec X ni avec le terme derreur uj - lerreur; u a une moyenne de zéro et nest pas corrélé ni avec X ni avec le terme derreur Fiabilité dune mesure Fiabilité dune mesure r xx = s 2 x /(s 2 x + s 2 u ) r xx = s 2 x /(s 2 x + s 2 u ) Erreur de mesure pour la VD lefficacité souffre car nous estimons: Y*+u = a + b 1 X 1 + b 2 X 2 + e ou Y* = a + b 1 X 1 + b 2 X 2 + (e+u) à la place de à la place de Y = a + b 1 X 1 + b 2 X 2 + e Erreur de mesure pour la VI lestimé de est biaisé; dans le cas dun modèle avec deux VI lestimé de devient: E(b) = r xx, b est donc atténué en fonction de la fiabilité de la VI
 Xtj - la vrai valeur (true score) uj - lerreur; u a une moyenne de zéro et nest pas corrélé ni avec X ni avec le terme derreur uj - lerreur; u a une moyenne de zéro et nest pas corrélé ni avec X ni avec le terme derreur Fiabilité dune mesure Fiabilité dune mesure r xx = s 2 x /(s 2 x + s 2 u ) r xx = s 2 x /(s 2 x + s 2 u ) Erreur de mesure pour la VD lefficacité souffre car nous estimons: Y*+u = a + b 1 X 1 + b 2 X 2 + e ou Y* = a + b 1 X 1 + b 2 X 2 + (e+u) à la place de à la place de Y = a + b 1 X 1 + b 2 X 2 + e Erreur de mesure pour la VI lestimé de est biaisé; dans le cas dun modèle avec deux VI lestimé de devient: E(b) = r xx, b est donc atténué en fonction de la fiabilité de la VI")
27
Inclusion dune variable de trop vrai modèle : Y = a + b 1 X 1 + e modèle estimé : Y = a + b 1 X 1 + b 2 X 2 + e lestimation des b est non-biaisée: E(b 2 ) = 0 et E(b 1 )= 1, mais dans le cas où X 1 et X 2 sont corrélés lefficacité souffre car: Exclusion dune variable vrai modèle: Y = a + b 1 X 1 + b 2 X 2 + e modèle estimé: Y = a + b 1 X 1 + e lestimation de 1 est biaisée dans le cas où 1 et 2 sont corrélés car: E(b 1 ) = 1 + 2 b 21 avec b 21 - la régression de X 1 sur X 2 lefficacité ne souffre pas
 = 0 et E(b 1 )= 1, mais dans le cas où X 1 et X 2 sont corrélés lefficacité souffre car: Exclusion dune variable vrai modèle: Y = a + b 1 X 1 + b 2 X 2 + e modèle estimé: Y = a + b 1 X 1 + e lestimation de 1 est biaisée dans le cas où 1 et 2 sont corrélés car: E(b 1 ) = b 21 avec b 21 - la régression de X 1 sur X 2 lefficacité ne souffre pas")
28
Auto-corrélation Pour chaque paire d'ensemble de valeurs pour les k variables indépendantes les termes d'erreur ne sont pas corrélés Si COV(e i,e j ) > 0 lestimation des reste non-biaisée est efficace. Pourtant lestimé de est biaisé tel que E(a) = + E(e) Hétérocédacité La variance est constante pour chaque ensemble de valeurs pour les k variables indépendantes e Y
 = + E(e) Hétérocédacité La variance est constante pour chaque ensemble de valeurs pour les k variables indépendantes e Y.")
29
Il faut que les données soient organisés selon le # de sujet! Il faut que la valeur Durbin-Watson soit autour de 2.00

30
Nonlinéarité Y = + 1 X 1 + 2 X 2 + Y = + 1 X 1 + 2 X 2 + Ex: Y = + 1 X 1 + 2 X 2 + 3 (X 1 X 2 ) + Y = + 1 X 1 + 2 X 2 + 3 (X 1 X 2 ) + e Y
 + Y = + 1 X X (X 1 X 2 ) + e Y")
31
Considérations générales Considérations générales Rapport entre le nombre de cas et le nombre de VI Rapport entre le nombre de cas et le nombre de VI Normalité, linéarité, homocédasticité des résidues Normalité, linéarité, homocédasticité des résidues Cas extrêmes Cas extrêmes Multicolinéarité Multicolinéarité Analyses principales Analyses principales R multiple, valeur F R multiple, valeur F R 2 ajusté (pourcentage de variance expliquée) R 2 ajusté (pourcentage de variance expliquée) Signification des coefficients de régression Signification des coefficients de régression Carré des corrélations semi-partielles (sr j 2 ) Carré des corrélations semi-partielles (sr j 2 ) Analyses supplémentaires Analyses supplémentaires Valeurs B, intervalles de confiance Valeurs B, intervalles de confiance Valeurs ß Valeurs ß Équation Équation
 R 2 ajusté (pourcentage de variance expliquée) Signification des coefficients de régression Signification des coefficients de régression Carré des corrélations semi-partielles (sr j 2 ) Carré des corrélations semi-partielles (sr j 2 ) Analyses supplémentaires Analyses supplémentaires Valeurs B, intervalles de confiance Valeurs B, intervalles de confiance Valeurs ß Valeurs ß Équation Équation")
35
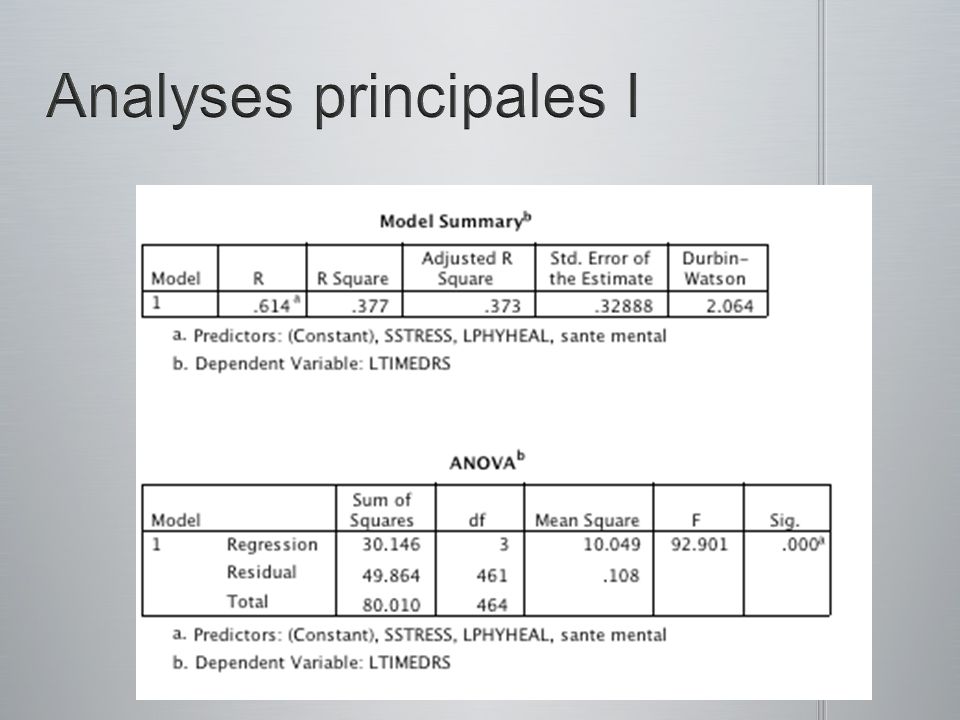
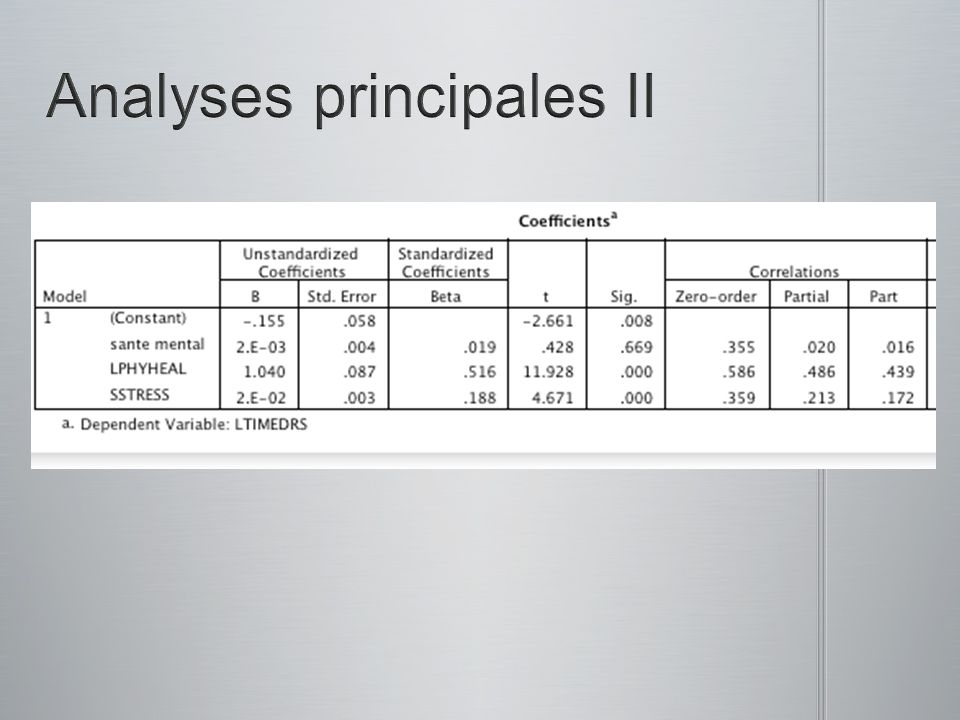
Une régression multiple standard fut conduite entre le nombre de visites chez le médecin comme étant la variable dépendante et la santé physique, la santé psychologique et le niveau de stress comme étant les variables indépendantes. Pour réduire la non normalité (skewness), le nombre de cas extrêmes, en plus daméliorer la normalité, la linéarité et lhomoscédasticité des résiduels, une transformation racine carré fut faite sur la variable stress et une transformation logarithmique fut faite sur le nombre de visites chez le médecin et sur la santé physique. La variable de santé mentale était positivement biaisé sans transformation et négativement biaisé avec transformation. Conséquemment, cette variable ne fut pas transformée. Le Tableau 5.18 présente les corrélations entre les variables, les coefficients de régression non-standardisés (B), lorigine, les coefficients de régression standardisés (ß), les corrélations semi- partielles (sr 2 ), R 2, and R 2 ajusté. Le R multiple était significativement différent de 0, F(3, 461) = 92.90, p <.001. Pour les deux coefficients de régression qui différaient significativement de zéro, les intervalles de confiance de 95% furent calculés. Lintervalle de confiance pour (la racine carré) le stress était 0.0091 à 0.0223, et celle pour (log de) la santé physique était de 0.8686 à 1.2113. Seulement deux des VIs ont contribuées significativement à la prédiction du (log de) nombre de visites chez le médecin : les (log de) scores de santé physique (sr 2 =.19) et les (racine carré de) scores de stress aigus (sr 2 =.03). Les trois Vis en combinaison contribuaient un autre.15 de variabilités communes. Dans lensemble, 38% (37% ajusté) de la variance du nombre de visite chez le médecin fut prédite par les scores de ces trois VIs. Une régression multiple standard fut conduite entre le nombre de visites chez le médecin comme étant la variable dépendante et la santé physique, la santé psychologique et le niveau de stress comme étant les variables indépendantes. Pour réduire la non normalité (skewness), le nombre de cas extrêmes, en plus daméliorer la normalité, la linéarité et lhomoscédasticité des résiduels, une transformation racine carré fut faite sur la variable stress et une transformation logarithmique fut faite sur le nombre de visites chez le médecin et sur la santé physique. La variable de santé mentale était positivement biaisé sans transformation et négativement biaisé avec transformation. Conséquemment, cette variable ne fut pas transformée. Le Tableau 5.18 présente les corrélations entre les variables, les coefficients de régression non-standardisés (B), lorigine, les coefficients de régression standardisés (ß), les corrélations semi- partielles (sr 2 ), R 2, and R 2 ajusté. Le R multiple était significativement différent de 0, F(3, 461) = 92.90, p <.001. Pour les deux coefficients de régression qui différaient significativement de zéro, les intervalles de confiance de 95% furent calculés. Lintervalle de confiance pour (la racine carré) le stress était 0.0091 à 0.0223, et celle pour (log de) la santé physique était de 0.8686 à 1.2113. Seulement deux des VIs ont contribuées significativement à la prédiction du (log de) nombre de visites chez le médecin : les (log de) scores de santé physique (sr 2 =.19) et les (racine carré de) scores de stress aigus (sr 2 =.03). Les trois Vis en combinaison contribuaient un autre.15 de variabilités communes. Dans lensemble, 38% (37% ajusté) de la variance du nombre de visite chez le médecin fut prédite par les scores de ces trois VIs. Malgré que la corrélation entre le (log de) nombre de visite chez le médecin et la santé mentale était de.36, la santé mentale ne contribuait pas significativement à la régression. Des évaluations post hocs de cette corrélation ont révélées quelle était significativement différente de zéro, F(3, 461) = 22.16, p <.01. Cela amène à lhypothèse que la relation entre le nombre de visite chez le médecin et la santé mentale est médié par la relation entre la santé mentale, le stress, et les visites chez le médecin. Malgré que la corrélation entre le (log de) nombre de visite chez le médecin et la santé mentale était de.36, la santé mentale ne contribuait pas significativement à la régression. Des évaluations post hocs de cette corrélation ont révélées quelle était significativement différente de zéro, F(3, 461) = 22.16, p <.01. Cela amène à lhypothèse que la relation entre le nombre de visite chez le médecin et la santé mentale est médié par la relation entre la santé mentale, le stress, et les visites chez le médecin.
, le nombre de cas extrêmes, en plus daméliorer la normalité, la linéarité et lhomoscédasticité des résiduels, une transformation racine carré fut faite sur la variable stress et une transformation logarithmique fut faite sur le nombre de visites chez le médecin et sur la santé physique. La variable de santé mentale était positivement biaisé sans transformation et négativement biaisé avec transformation. Conséquemment, cette variable ne fut pas transformée. Le Tableau 5.18 présente les corrélations entre les variables, les coefficients de régression non-standardisés (B), lorigine, les coefficients de régression standardisés (ß), les corrélations semi- partielles (sr 2 ), R 2, and R 2 ajusté. Le R multiple était significativement différent de 0, F(3, 461) = 92.90, p <.001. Pour les deux coefficients de régression qui différaient significativement de zéro, les intervalles de confiance de 95% furent calculés. Lintervalle de confiance pour (la racine carré) le stress était à , et celle pour (log de) la santé physique était de à Seulement deux des VIs ont contribuées significativement à la prédiction du (log de) nombre de visites chez le médecin : les (log de) scores de santé physique (sr 2 =.19) et les (racine carré de) scores de stress aigus (sr 2 =.03). Les trois Vis en combinaison contribuaient un autre.15 de variabilités communes. Dans lensemble, 38% (37% ajusté) de la variance du nombre de visite chez le médecin fut prédite par les scores de ces trois VIs. Une régression multiple standard fut conduite entre le nombre de visites chez le médecin comme étant la variable dépendante et la santé physique, la santé psychologique et le niveau de stress comme étant les variables indépendantes. Pour réduire la non normalité (skewness), le nombre de cas extrêmes, en plus daméliorer la normalité, la linéarité et lhomoscédasticité des résiduels, une transformation racine carré fut faite sur la variable stress et une transformation logarithmique fut faite sur le nombre de visites chez le médecin et sur la santé physique. La variable de santé mentale était positivement biaisé sans transformation et négativement biaisé avec transformation. Conséquemment, cette variable ne fut pas transformée. Le Tableau 5.18 présente les corrélations entre les variables, les coefficients de régression non-standardisés (B), lorigine, les coefficients de régression standardisés (ß), les corrélations semi- partielles (sr 2 ), R 2, and R 2 ajusté. Le R multiple était significativement différent de 0, F(3, 461) = 92.90, p <.001. Pour les deux coefficients de régression qui différaient significativement de zéro, les intervalles de confiance de 95% furent calculés. Lintervalle de confiance pour (la racine carré) le stress était à , et celle pour (log de) la santé physique était de à Seulement deux des VIs ont contribuées significativement à la prédiction du (log de) nombre de visites chez le médecin : les (log de) scores de santé physique (sr 2 =.19) et les (racine carré de) scores de stress aigus (sr 2 =.03). Les trois Vis en combinaison contribuaient un autre.15 de variabilités communes. Dans lensemble, 38% (37% ajusté) de la variance du nombre de visite chez le médecin fut prédite par les scores de ces trois VIs. Malgré que la corrélation entre le (log de) nombre de visite chez le médecin et la santé mentale était de.36, la santé mentale ne contribuait pas significativement à la régression. Des évaluations post hocs de cette corrélation ont révélées quelle était significativement différente de zéro, F(3, 461) = 22.16, p <.01. Cela amène à lhypothèse que la relation entre le nombre de visite chez le médecin et la santé mentale est médié par la relation entre la santé mentale, le stress, et les visites chez le médecin. Malgré que la corrélation entre le (log de) nombre de visite chez le médecin et la santé mentale était de.36, la santé mentale ne contribuait pas significativement à la régression. Des évaluations post hocs de cette corrélation ont révélées quelle était significativement différente de zéro, F(3, 461) = 22.16, p <.01. Cela amène à lhypothèse que la relation entre le nombre de visite chez le médecin et la santé mentale est médié par la relation entre la santé mentale, le stress, et les visites chez le médecin..")
36
La RM peut mettre en évidence de liens corrélationnels mais non pas des liens causaux (ceci est aussi le cas pour les analyses des chemins causaux) La RM peut mettre en évidence de liens corrélationnels mais non pas des liens causaux (ceci est aussi le cas pour les analyses des chemins causaux) Il est très important de choisir les variables indépendantes soigneusement car la solution est fortement influencée par la combinaison des variables inclus Il est très important de choisir les variables indépendantes soigneusement car la solution est fortement influencée par la combinaison des variables inclus Il est bon de choisir des VIs avec une forte corrélation avec la VD mais des faibles corrélations entre elles Il est bon de choisir des VIs avec une forte corrélation avec la VD mais des faibles corrélations entre elles Il est important dinclure toutes les variables qui influencent la VD, car dans le cas où certaines variables mesurées sont corrélées avec des variables non mesurées, lexistence de ces dernières introduit un biais dans lestimation des betas. Il est important dinclure toutes les variables qui influencent la VD, car dans le cas où certaines variables mesurées sont corrélées avec des variables non mesurées, lexistence de ces dernières introduit un biais dans lestimation des betas. Car la RM présuppose des variables mesurées sans erreur (ce qui généralement impossible) il faut se servir des variables qui sont aussi fiables que possible Car la RM présuppose des variables mesurées sans erreur (ce qui généralement impossible) il faut se servir des variables qui sont aussi fiables que possible
 il faut se servir des variables qui sont aussi fiables que possible Car la RM présuppose des variables mesurées sans erreur (ce qui généralement impossible) il faut se servir des variables qui sont aussi fiables que possible.")
Présentations similaires



 r =>")


















>")