Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Initiation à la recherche clinique et épidémiologique
(Les différents types d’enquête) Initiation à l’analyse de données (Comment présenter les données ?) (Pourquoi a-t-on besoin des tests ?) Dr Benoît Lepage Dr Vanina Bongard Département d’Epidémiologie, Economie de la Santé et Santé Publique Université Toulouse III – Paul Sabatier Master de Santé Publique, Toulouse III
 Initiation à l’analyse de données. (Comment présenter les données ) (Pourquoi a-t-on besoin des tests ) Dr Benoît Lepage Dr Vanina Bongard Département d’Epidémiologie, Economie de la Santé et Santé Publique. Université Toulouse III – Paul Sabatier. Master de Santé Publique, Toulouse III.")
2
Les outils statistiques
Description de données Sondages, échantillons, inférence Estimations Tests Les principaux types d’enquêtes Essais cliniques transversales Cohortes Cas témoins

3
I. Outils statistiques Comment présenter les données ?
Unités statistiques : éléments faisant l’objet de l’étude : personnes, temps de mesures, département, … Variables statistiques : Paramètre pouvant prendre différentes valeurs d’une unité statistique à l’autre variable qualitative = variable catégorielle variable qualitative nominale (sans relation d’ordre) variable qualitative ordonnée (relation d’ordre) Variable quantitative variable quantitative discontinue = discrète variable quantitative continue
 variable qualitative ordonnée (relation d’ordre) Variable quantitative. variable quantitative discontinue = discrète. variable quantitative continue.")
4
a. Représentation synthétique d’une variable qualitative
Tableaux de fréquence Fréquence absolue : nombre de cas Fréquence relative : pourcentage Variable booléenne, dichotomique, binaire, à 2 modalités N = 150 Sexe, n (%) hommes femmes Tabagisme, n (%) non fumeurs anciens fumeurs fumeurs 80 (53,3 %) 70 (46,7 %) 77 (51,3 %) 28 (18,7 %) 45 (30,0 %)
 hommes. femmes. Tabagisme, n (%) non fumeurs. anciens fumeurs. fumeurs. 80 (53,3 %) 70 (46,7 %) 77 (51,3 %) 28 (18,7 %) 45 (30,0 %)")
6
Diagrammes en secteurs
Graphiques => faire ressortir une vision synthétique (mais souvent moins précise que les tableaux) Diagrammes en secteurs
 Diagrammes en secteurs.")
7
Diagrammes en barres

8
b. De la variable qualitative à la variable quantitative
Histogrammes (variables discrètes)
")
9
Histogrammes 70 80 90 100 110 120 130 140 150 160 170 180 190

10
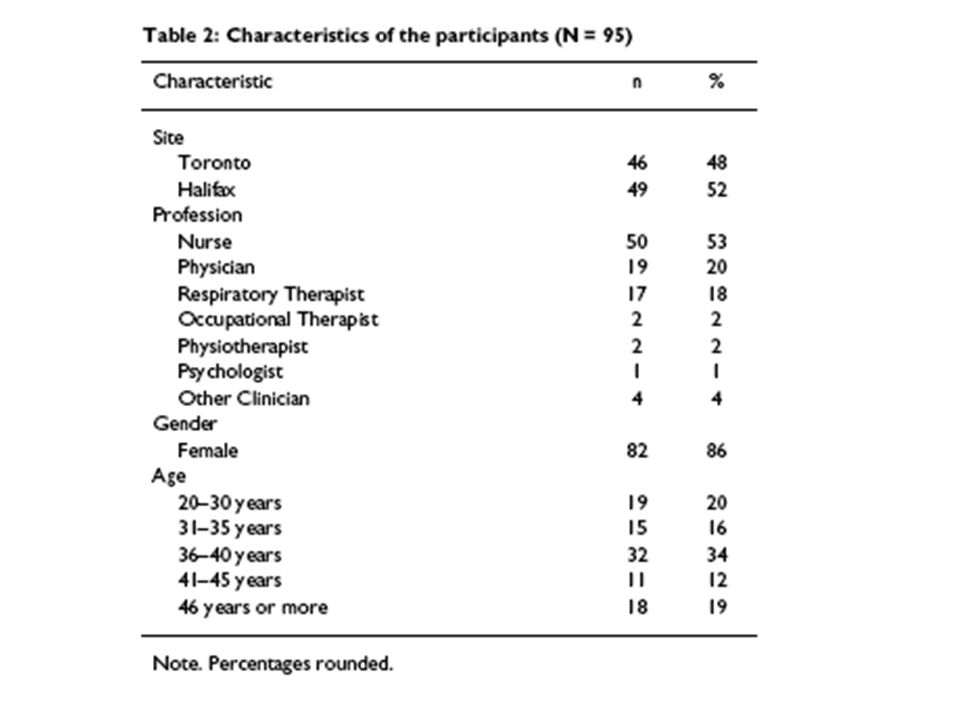
Courbes de distribution
40 30 20 10 70 90 110 130 140 160
11
c. Représentation synthétique d’une variable quantitative
1. Paramètres de position ou de tendance centrale moyenne arithmétique et géométrique médiane mode 2. Paramètres de dispersion variance écart type, erreur standard quantiles intervalle interquartile Extrêmes, étendue DISPERSION POSITION

12
Moyenne arithmétique 1. Paramètres de position
Nb de cas Nb de cas Distribution gaussienne: Distribution non gaussienne: La moyenne correspond aux valeurs les plus fréquentes La moyenne ne correspond pas aux valeurs les plus fréquentes bon indicateur de tendance centrale mauvais indicateur de tendance centrale

13
Médiane : plus adaptée si distribution asymétrique
1. Paramètres de position Médiane : plus adaptée si distribution asymétrique Valeur centrale séparant l’échantillon en deux moitiés 50 % des valeurs sont au dessus 50 % des valeurs sont en dessous rang de la médiane : (n + 1) / 2 si n est pair n/2 si n est impair Mode Valeur la plus représentée (variables quantitatives discrètes +)
 / 2 si n est pair. n/2 si n est impair. Mode. Valeur la plus représentée (variables quantitatives discrètes +)")
14
Exemple médiane (1) Poids en Kg d’une série de 80 sujets (après classement par ordre croissant) Moyenne de la 40ème et 41ème valeur Médiane = (73+74)/2 = 73,5 kg (ne nécessite pas de connaître toutes les valeurs)
/2 = 73,5 kg. (ne nécessite pas de connaître toutes les valeurs)")
15
Exemple médiane (2) Une série de 7 sujets :
Ici, n est impair, la médiane est la valeur de rang (n+1)/2 = la valeur de rang 4 La médiane est 58
/2. = la valeur de rang 4. La médiane est 58.")
16
Dispersion

17
1 2 = (X i - ) n = 2 Variance
La variance est la moyenne des carrés des écarts des valeurs par rapport à la moyenne. L’unité de la variance est l’unité de la variable étudiée au carré. Ecart Type, déviation standard, SD L’unité de l’écart type est identique à l’unité de la variable étudiée. = 2

18
Si une variable suit une distribution normale :
- 2DS - 1DS + 1DS + 2DS 68% 95% Moy ± 1ET contient 68% des observations Moy ± 2ET contient 95% des observations Moy ± 3ET contient 99% des observations

19
Quantiles (k – 1) valeurs séparant l’échantillon en k zones comportant le même nombre d’observations k = 3 : tertiles k = 4 : quartiles k = 10 : déciles k = 100 : centiles ou percentiles Un intervalle entre deux quantiles correspond à un intervalle interquantile

20
Exemple : quartiles Poids en Kg d’une série de 80 sujets (après classement par ordre croissant) 1er quartile = (¼,¾) = 69 kg 2ème quartile = Médiane = 73,5 kg 3ème quartile = (¾,¼) = 77 kg
 = 69 kg. 2ème quartile = Médiane = 73,5 kg. 3ème quartile = (¾,¼) = 77 kg.")
21
Notion d’inférence = tirer une conclusion au niveau d’une population inaccessible
à partir d’observations faites sur un échantillon Population cible : ensemble des individus auxquels on s’intéresse Population source : ensemble des individus à partir desquels on effectue le tirage au sort Echantillon : ensemble des individus effectivement étudiés

22
Population source représentative de la population cible
Un sondage est un procédé qui consiste à n’observer qu’une partie de la population étudiée (échantillon) et à tirer de cette observation des informations sur la population entière. Population source représentative de la population cible N sujets Echantillon n sujets n < N
 et à tirer de cette observation des informations sur la population entière. Population source représentative de la population cible. N sujets. Echantillon. n sujets n < N.")
23
Fluctuations d’échantillonnage
Malade Non malade

24
AVANTAGES d’un sondage :
Le sondage est plus rapide, moins cher et plus facilement réalisable qu’une enquête exhaustive sur la population cible. INCONVENIENT d’un sondage : Incertitude de l’extrapolation à la population cible des observations faites sur l’échantillon. CONTRAINTES d’un sondage : L’échantillon doit être représentatif de la population cible. L’échantillon doit être composé d’unités statistiques en nombre suffisant.

25
distinguer un biais des fluctuations normales d’échantillonnage
Il faut bien distinguer un biais des fluctuations normales d’échantillonnage erreur systématique erreur aléatoire Estimation biaisée Conduit à définir un intervalle de confiance du paramètre à estimer

26
erreur systématique allant toujours dans le même sens (biais)
Biais et erreurs aléatoires Déformation des faits due au hasard de l’échantillonnage : erreur non systématique due au hasard (fluctuations d’échantillonnage ) Estimation précise et non biaisée Estimation peu précise mais non biaisée Déformation des faits due à un biais : erreur systématique allant toujours dans le même sens (biais) Estimation précise mais biaisée Estimation peu précise et biaisée
 Estimation précise et non biaisée. Estimation peu précise mais non biaisée. Déformation des faits due à un biais : erreur systématique allant toujours dans le même sens (biais) Estimation précise mais biaisée. Estimation peu précise et biaisée.")
27
Estimation : Définition (1)
Tenter de définir les paramètres d’une population à partir des paramètres observés sur un échantillon

28
Estimation : Définition (1)
Tenter de définir les paramètres d’une population à partir des paramètres observés sur un échantillon Valeur observée valeur inconnue de la population

29
Estimation : Définition (1)
Tenter de définir les paramètres d’une population à partir des paramètres observés sur un échantillon Valeur observée valeur inconnue de la population Valeur observée proche de la valeur inconnue si échantillon représentatif

30
Estimation : Définition (1)
Tenter de définir les paramètres d’une population à partir des paramètres observés sur un échantillon Valeur observée valeur inconnue de la population Valeur observée proche de la valeur inconnue si échantillon représentatif En répétant l’échantillonnage, autres valeurs proches les unes des autres

31
Estimation : Définition (2)
Valeur observée (échantillon) Valeur exacte (population générale) Incapable de connaître la vraie valeur !!! Objectif de l’estimation en statistique => calculer des bornes où se trouve la valeur inconnue du paramètre (avec une confiance suffisamment grande) = Intervalle de confiance +++
 Valeur exacte (population générale) Incapable de connaître la vraie valeur !!! Objectif de l’estimation en statistique => calculer des bornes où se trouve la valeur inconnue du paramètre (avec une confiance suffisamment grande) = Intervalle de confiance +++")
32
Estimation d’une moyenne inconnue (1)
On sait calculer la moyenne observée d’une variable quantitative sur un échantillon Problème: Estimer la moyenne inconnue de la population d’où est extrait l’échantillon

33
Estimation d’une moyenne inconnue (2)
Utiliser un échantillon représentatif de la population (obtenu par tirage aléatoire) Estimation de à partir de l ’échantillon 1 : est estimée par m1 = (xi) / n1 où xi = {x1, x2, … , xn1} les n1 valeurs de X dans l ’échantillon 1 m1 observée inconnue Mais à quelle distance, de quel côté de ?
 Estimation de à partir de l ’échantillon 1 : est estimée par m1 = (xi) / n1. où xi = {x1, x2, … , xn1} les n1 valeurs de X dans l ’échantillon 1. m1 observée inconnue. Mais à quelle distance, de quel côté de ")
34
Estimation d’une moyenne inconnue (2)
Échantillon représentatif de la population (obtenu par tirage aléatoire) m1 observée inconnue Mais à quelle distance, de quel côté de ? 2ème échantillon (par tirage aléatoire) m2 proche de m1 m2 observée inconnue
 m1 observée inconnue. Mais à quelle distance, de quel côté de 2ème échantillon (par tirage aléatoire) m2 proche de m1. m2 observée inconnue.")
35
Estimation d’une moyenne inconnue (2)
Échantillon représentatif de la population (obtenu par tirage aléatoire) m1 observée inconnue Mais à quelle distance, de quel côté de ? 2ème échantillon (par tirage aléatoire) m2 proche de m1 m2 observée inconnue 3ème échantillon : idem...
 m1 observée inconnue. Mais à quelle distance, de quel côté de 2ème échantillon (par tirage aléatoire) m2 proche de m1. m2 observée inconnue. 3ème échantillon : idem...")
36
Estimation d’une moyenne inconnue (3)
Si on dispose de la totalité des échantillons possibles tirés de la population générale

37
Estimation d’une moyenne inconnue (3)
Si on dispose de la totalité des échantillons possibles tirés de la population générale On obtiendrait une moyenne m pour chaque échantillon

38
Estimation d’une moyenne inconnue (3)
Si on dispose de la totalité des échantillons possibles tirés de la population générale On obtiendrait une moyenne m pour chaque échantillon Fluctuations d’échantillonnage de la moyenne

39
Estimation d’une moyenne inconnue (3)
L’estimation m de la moyenne inconnue est une variable aléatoire puisqu’elle varie d’un échantillon à l’autre Fluctuations d’échantillonnage de l’estimation de la moyenne Distribution de la variable X dans la population Distribution des moyennes de X dans chaque échantillon

40
Estimation d’une moyenne inconnue (3)
L’estimation m de la moyenne inconnue est une variable aléatoire puisqu’elle varie d’un échantillon à l’autre On peut estimer la moyenne de l’estimation de la moyenne Et la variance de l’estimation de la moyenne Distribution de la variable X dans la population

41
Estimation d’une moyenne inconnue (4)
Dans un échantillon, on sait calculer un intervalle de confiance à 95% m1 m2 m3 m4 m5 m6 m7 m8 m9 … mk Si on calcule l’intervalle de confiance auprès d’un très grand nombre d’échantillons, la vraie moyenne de la population est comprise dans 95 % des intervalles de confiance Moyenne de la population

42
Intérêt des tests Les tests servent à extrapoler les résultats observés sur des échantillons à l’ensemble des populations dont ils sont issus +++ Échantillon : image ponctuelle Intérêt majeur des tests : Économie de moyens +++ En permettant de déceler des différences sur un nombre réduit d’observations

43
Principe des tests de comparaison
Principe général : Regarder si la différence qu’on observe dans un échantillon est due au hasard ou si au contraire cette différence est telle qu’il est fort peu probable de l’observer par hasard 2 hypothèses sont posées : Hypothèse nulle = « il n’y a pas de différence » Hypothèse alternative = « il y a une différence » (dans la population à laquelle on veut généraliser le résultat)
")
44
Principe des tests de comparaison
Illustration : vous pariez à pile ou face avec un ami, il vous tend une pièce. Hypothèse nulle H0 : la pièce n’est pas faussée, et j’ai une chance sur deux de gagner P(joueur 1 gagne) = P(joueur 2 gagne) Hypothèse alternative H1 : la pièce est faussée, un des joueurs à une probabilité plus élevée de gagner que l’autre joueur : P(joueur 1 gagne) P(joueur 2 gagne)
 = P(joueur 2 gagne) Hypothèse alternative H1 : la pièce est faussée, un des joueurs à une probabilité plus élevée de gagner que l’autre joueur : P(joueur 1 gagne) P(joueur 2 gagne)")
45
Principe des tests de comparaison
Illustration : vous pariez à pile ou face avec un ami, il vous tend une pièce. Au premier essai, vous perdez Vous pensez que vous n’avez pas eu de chance cette fois ci, vous ne remettez pas en cause l’hypothèse nulle selon laquelle la pièce n’est pas faussée, et vous acceptez de refaire une partie en espérant rattraper la mise.

46
Principe des tests de comparaison
Illustration : vous pariez à pile ou face avec un ami, il vous tend une pièce. Au premier essai, vous perdez Vous pensez que vous n’avez pas eu de chance cette fois ci, vous ne remettez pas en cause l’hypothèse nulle selon laquelle la pièce n’est pas faussée, et vous acceptez de refaire une partie en espérant rattraper la mise. Au deuxième essai, vous perdez à nouveau Vous pensez que vous n’avez vraiment pas de chance, vous ne remettez pas en cause l’hypothèse nulle selon laquelle la pièce n’est pas faussée, et vous acceptez de refaire une partie en espérant rattraper la mise.

47
Principe des tests de comparaison
Illustration : vous pariez à pile ou face avec un ami, il vous tend une pièce. Au premier essai, vous perdez Vous pensez que vous n’avez pas eu de chance cette fois ci, vous ne remettez pas en cause l’hypothèse nulle selon laquelle la pièce n’est pas faussée, et vous acceptez de refaire une partie en espérant rattraper la mise. Au deuxième essai, vous perdez à nouveau Vous pensez que vous n’avez vraiment pas de chance, vous ne remettez pas en cause l’hypothèse nulle selon laquelle la pièce n’est pas faussée, et vous acceptez de refaire une partie en espérant rattraper la mise. Vous continuez à jouer, vous perdez 5 fois de suite. Vous commencez à avoir de sérieux doute et à remettre en cause la validité de l’hypothèse nulle selon laquelle la pièce n’est pas faussée

48
Principe des tests de comparaison
Illustration : vous pariez à pile ou face avec un ami, il vous tend une pièce. Au bout du 10ème essai, vous avez perdu 10 fois de suite, vous décider d’arrêter de jouer, la probabilité que la pièce ne soit pas faussée (que l’hypothèse nulle soit vraie) est trop faible : vous rejetez cette hypothèse et acceptez l’hypothèse alternative H1 (la pièce est faussée) vous prenez le risque de vous fâcher avec votre ami (le risque de se fâcher alors que la pièce était en réalité normale est devenu beaucoup trop faible). Il y a un seuil à partir duquel, on décide de rejeter l’hypothèse nulle Si on calcule le risque de se facher pour rien au bout du 10ème échec de suite, ce risque est inférieur à 1 / (Il était déjà inférieur à 5/100 au bout du 5ème essai).
 est trop faible : vous rejetez cette hypothèse et acceptez l’hypothèse alternative H1 (la pièce est faussée) vous prenez le risque de vous fâcher avec votre ami (le risque de se fâcher alors que la pièce était en réalité normale est devenu beaucoup trop faible). Il y a un seuil à partir duquel, on décide de rejeter l’hypothèse nulle. Si on calcule le risque de se facher pour rien au bout du 10ème échec de suite, ce risque est inférieur à 1 / (Il était déjà inférieur à 5/100 au bout du 5ème essai).")
49
Exemple d’utilisation d’un test
Principe général des tests de comparaison : Regarder si la différence qu’on observe dans un échantillon est due au hasard ou si au contraire cette différence est telle qu’il est fort peu probable de l’observer par hasard 2éme Exemple : La prévalence du diabète est-elle supérieure chez les sujets en surcharge pondérale par rapport aux sujets de poids normal ? Sondage dans la population cible pour obtenir un échantillon représentatif.

50
Hypothèse nulle H0 : La prévalence du diabète dans la population cible est identique parmi les sujets de poids normal et parmi les sujets en surcharge pondérale. P1 = P0 ou D = P1 – P0 = 0 Hypothèse alternative H1 : La prévalence du diabète dans la population cible est différente parmi les sujets de poids normal et parmi les sujets en surcharge pondérale. P1 P0 ou D = P1 – P0 0

51
Si l’échantillon est de taille suffisante et représentatif :
- sous H0 : d = p1 – p0 devrait être petite - sous H1 : d = p1 – p0 devrait être grande On réalise un test statistique pour savoir si d peut être considérée comme grande (significativement différente de 0). Autrement dit on réalise un test statistique pour savoir s’il est vraisemblable de rejeter l’hypothèse nulle.
. Autrement dit on réalise un test statistique pour savoir s’il est vraisemblable de rejeter l’hypothèse nulle.")
52
existence d’une différence
Population cible absence de différence D = 0 existence d’une différence D 0 d petite Conclusion vraie Conclusion fausse échantillon d grande Conclusion fausse Conclusion vraie Il y a toujours un risque de se tromper dans notre conclusion => risque d’erreur

53
Risque de première espèce ( seuil de significative p) :
Probabilité de rejeter à tort l’hypothèse nulle (probabilité de conclure à tord à l’existence d’une différence entre les groupes). Risque de seconde espèce : Probabilité de conserver à tort l’hypothèse nulle (probabilité de conclure à tord à l’absence de différence entre les groupes). Puissance du test : Probabilité de mettre en évidence une différence qui existe vraiment entre les groupes : Puissance = 1 -
. Risque de seconde espèce : Probabilité de conserver à tort l’hypothèse nulle (probabilité de conclure à tord à l’absence de différence entre les groupes). Puissance du test : Probabilité de mettre en évidence une différence qui existe vraiment entre les groupes : Puissance = 1 - ")
54
existence d’une différence
Le classement en « d petite » ou « d grande » se fait à partir de la p-value (degré de signification) du test : Si p < , on considère que d est petite Population cible absence de différence D = 0 existence d’une différence D 0 d petite test non significatif Conclusion vraie 1 - Conclusion fausse échantillon d grande test significatif Conclusion fausse Conclusion vraie 1 - Un test significatif permet de conclure à l’existence d’une différence. Un test non significatif ne permet pas d’exclure l’existence d’une différence.
 du test : Si p < , on considère que d est petite. Population cible. absence de différence. D = 0. existence d’une différence. D 0. d petite. test non significatif. Conclusion vraie. 1 - Conclusion fausse. échantillon. d grande. test significatif. Conclusion fausse. Conclusion vraie. 1 - Un test significatif permet de conclure à l’existence d’une différence. Un test non significatif ne permet pas d’exclure l’existence d’une différence.")
55
II. Principaux types d’enquêtes
Une enquête est une opération qui consiste à recueillir de l’information, puis à l’analyser en vue de résoudre une ou plusieurs questions spécifiée(s) à l’avance. Enquêtes exhaustives (sur l’ensemble de la population) Enquête sur échantillon (obtenu par sondage)
 à l’avance. Enquêtes exhaustives (sur l’ensemble de la population) Enquête sur échantillon (obtenu par sondage)")
56
Principaux types d’enquêtes
descriptives enquêtes transversales cohortes non comparatives L’exposition n’est pas contrôlée par l’investigateur Enquêtes d’observation analytiques enquêtes transversales enquêtes cas - témoins enquêtes de cohorte (« exposés - non exposés » ou « longitudinale ») randomisées essais cliniques phase III L’exposition est contrôlée par l’investigateur Enquêtes expérimentales non randomisées essais cliniques phase I et II enquêtes avant - après
 randomisées. essais cliniques phase III. L’exposition est contrôlée par l’investigateur. Enquêtes expérimentales. non randomisées. essais cliniques phase I et II. enquêtes avant - après.")
57
Principaux types d’enquêtes
Essais cliniques La vie du médicament découverte d’une molécule études pré-cliniques (animal) phase I (volontaires sain) phase II (volontaires malades) phase III (volontaires malades : essais comparatifs) Autorisation de Mise sur le Marché (A.M.M.) Phase IV (pharmacovigilance, pharmaco-épidémiologie, pharmaco-économie) 8 – 12 ans pharmacologie clinique
 phase I (volontaires sain) phase II (volontaires malades) phase III (volontaires malades : essais comparatifs) Autorisation de Mise sur le Marché (A.M.M.) Phase IV. (pharmacovigilance, pharmaco-épidémiologie, pharmaco-économie) 8 – 12 ans. pharmacologie clinique.")
58
Principaux types d’enquêtes
Essais cliniques Essais non randomisés : Phase I : étude de la première administration chez l’homme volontaires sains, évaluation des effets indésirables => sécurité et effets pharmacodynamiques Phase II : étude de l’efficacité pharmacologique volontaires malades pharmacologie (posologie efficace, dose-effet) pharmacocinétique
 pharmacocinétique.")
59
Principaux types d’enquêtes
Principes méthodologiques des essais de phase III Objectif : évaluer l’efficacité thérapeutique d’une intervention principe de comparaison par rapport à un placebo ou par rapport à un médicament de référence indispensable pour distinguer l’efficacité du médicament de l’évolution naturelle de la maladie

60
Principaux types d’enquêtes
Principes méthodologiques des essais de phase III principe du tirage au sort (randomisation) La répartition des sujets dans chaque groupe se fait par tirage au sort. indispensable pour assurer la comparabilité des deux groupes les groupes sont comparables en tout point, sauf pour l’attribution du traitement
 La répartition des sujets dans chaque groupe se fait par tirage au sort. indispensable pour assurer la comparabilité des deux groupes. les groupes sont comparables en tout point, sauf pour l’attribution du traitement.")
61
Principaux types d’enquêtes
Principes méthodologiques des essais de phase III principe du double aveugle Le patient ne sait pas s’il prend le placebo ou le traitement testé. Le médecin ne le sait pas non plus. indispensable pour maintenir la comparabilité des groupes au cours de l’étude

62
Principaux types d’enquêtes
Enquête d’observation transversale Souvent : un échantillon représentatif d’une population et n’est pas sélectionné en fonction de l’exposition ou de la maladie Exposition ? temps Maladie ? Au moment de l’enquête, on recueille au même moment les informations sur la présence d’une exposition et la présence d’une maladie

63
Principaux types d’enquêtes
Enquête d’observation transversale Estimation de la prévalence d’une maladie Proportion de sujets atteints d’une maladie dans une population à un instant donné t. M P = M + N P : prévalence de la maladie dans la population à l’instant t M : nombre de malades dans la population à l’instant t N : nombre de non malades dans la population à l’instant t effectif total de la population à l’instant t

64
Principaux types d’enquêtes
Enquête d’observation longitudinale = Enquête de cohorte Les sujets sont suivis dans le temps (on connaît les dates des évènements mesurés) Exposition ? temps Maladie ? Début d’étude : Recueil prospectif Début d’étude : Recueil rétrospectif (cohorte « historique »)
 Exposition temps. Maladie Début d’étude : Recueil prospectif. Début d’étude : Recueil rétrospectif (cohorte « historique »)")
65
Principaux types d’enquêtes
Enquête d’observation longitudinale = Enquête de cohorte Parfois l’inclusion des sujets au départ se fait en fonction d’une exposition dichotomique : enquête « exposé – non exposé » Exposition ? temps Maladie ? Début d’étude : Recueil prospectif Début d’étude : Recueil rétrospectif (cohorte « historique »)
")
66
Principaux types d’enquêtes
Enquête d’observation longitudinale = Enquête de cohorte On peut estimer l’incidence d’une maladie Vitesse moyenne de production de nouveaux cas d’une maladie dans une population pendant un intervalle de temps [t; t+t]. TI = nombre de nouveaux cas sur [t; t+ t] effectif moyen des sujets à risque sur [t; t+ t] TI : taux d’incidence de la maladie dans la population pendant [t; t+ t] Effectif moyen des sujets à risque sur [t; t+ t] : 2 Nt + Nt+ t

67
Principaux types d’enquêtes
Enquête d’observation longitudinale = Enquête de cohorte On peut calculer le risque relatif (RR) : comparer les taux d’incidence entre différentes expositions Le risque relatif d’une exposition (par rapport à l’absence d’exposition) :
 : comparer les taux d’incidence entre différentes expositions. Le risque relatif d’une exposition (par rapport à l’absence d’exposition) :")
68
Principaux types d’enquêtes
Enquête d’observation longitudinale = Enquête de cohorte On peut calculer le risque relatif (RR) : comparer les taux d’incidence entre différentes expositions Si RR > 1 : le risque de maladie est augmenté chez les sujets exposés Si RR < 1 : le risque de maladie est diminué chez les sujets exposés Si RR=1 : le risque de maladie est le même chez les sujets exposés et non-exposés
 : comparer les taux d’incidence entre différentes expositions. Si RR > 1 : le risque de maladie est augmenté chez les sujets exposés. Si RR < 1 : le risque de maladie est diminué chez les sujets exposés. Si RR=1 : le risque de maladie est le même chez les sujets exposés et non-exposés.")
69
Principaux types d’enquêtes étude exposés - non exposés
Exemple dans une enquête exposés – non exposés, avec la même durée de suivi pour tout le monde : exposés % de malades ? étude exposés - non exposés non exposés % de malades ?

70
Principaux types d’enquêtes
Exemple dans une enquête exposés – non exposés, avec la même durée de suivi pour tout le monde : Estimation d’un risque relatif de maladie malades non malades a b exposés n1 c d non exposés n0 m1 m0 RR = Re / Rne = Ie / Ine = (a/n1) / (c/n0)
 / (c/n0)")
71
Principaux types d’enquêtes
Enquête cas - témoins On va comparer la fréquence de l’exposition antérieure chez des malades (cas) et des non-malades (témoins) Début d’étude : Sélection des malades et témoins Recueil rétrospectif de la présence d’une exposition antérieure Exposition ? temps Maladie ?
 et des non-malades (témoins) Début d’étude : Sélection des malades et témoins. Recueil rétrospectif de la présence d’une exposition antérieure. Exposition temps. Maladie")
72
Principaux types d’enquêtes
Enquête cas - témoins cas = malades % d’exposés ? étude cas - témoins témoins = sains % d’exposés ?

73
Principaux types d’enquêtes
Enquête cas - témoins Dans une enquête de cohorte ou une enquête transversale, la sélection ne dépend pas de la présence de la maladie : Les exposés et non-exposés dans l’échantillon sont représentatifs des exposés et non-exposés de la population on peut estimer le risque d’être malade chez les exposés et non exposés et calculer un risque relatif Dans une enquête cas témoins le pourcentage de malades est choisi arbitrairement par l’investigateur : on ne peut pas estimer le risque dans la population ni le risque relatif, il faut calculer un odds ratio (OR) = rapport de cote
 = rapport de cote.")
74
Principaux types d’enquêtes
Enquête cas - témoins Estimation d’un odds ratio de maladie OR = [e1/(1-e1)] / [e0/(1-e0)] = ad / bc avec e1 et e0 fréquences de l’exposition chez les malades et les non malades : a b c d exposés non exposés malades non malades m1 m0 n1 n0 OR = [Re/(1-Re)] / [Rne/(1-Rne)]
] / [e0/(1-e0)] = ad / bc. avec e1 et e0 fréquences de l’exposition chez les malades et les non malades : a. b. c. d. exposés. non exposés. malades. non malades. m1. m0. n1. n0. OR = [Re/(1-Re)] / [Rne/(1-Rne)]")
75
Indispensable ++++ Avant la mise en place d’une étude : quelque soit le schéma Toujours commencer par l’écriture du protocole d’étude : Contexte hypothèses à évaluer l’objectif précis les méthodes à mettre en œuvre : population (critères d’inclusion, d’exclusion) critères de jugement variables d’exposition autres variables à prendre en compte méthodes de mesures des différentes variables calcul de l’effectif nécessaire pour répondre à l’objectif méthodes statistiques envisagées
 critères de jugement. variables d’exposition. autres variables à prendre en compte. méthodes de mesures des différentes variables. calcul de l’effectif nécessaire pour répondre à l’objectif. méthodes statistiques envisagées.")
76
Prendre en compte la variabilité +++
Dernier point important pour les sciences de la vie : la notion de variabilité Prendre en compte la variabilité +++ Variabilité biologique (entre-sujet et intra-sujet) Variabilité instrumentale (expérimentale, liée à l’instrument lui-même) variabilité biologique inter-sujet + variabilité biologique intra-sujet + variabilité instrumentale + variabilité inter- et intra-examinateur …_____________________________ = Variabilité totale Une variable aléatoire est variable : qu’est ce que la variabilité ?
 Variabilité instrumentale (expérimentale, liée à l’instrument lui-même) variabilité biologique inter-sujet. + variabilité biologique intra-sujet. + variabilité instrumentale. + variabilité inter- et intra-examinateur. …_____________________________. = Variabilité totale. Une variable aléatoire est variable : qu’est ce que la variabilité")
77
Variabilité : exemples
Variabilité biologique inter-individuelle Durée de la gestation, taille à l’âge adulte, poids de naissance Variabilité biologique intra-individuelle Cortisol, glycémie, urée, tension artérielle Variabilité liée à la méthode de mesure TA chez l’obèse, mesure sur une échographie (liée à l’appareil et au clinicien) Variabilité liée à l’expérimentation Effet centre, effet placebo, environnement Effet cage : fait référence
 Variabilité liée à l’expérimentation. Effet centre, effet placebo, environnement. Effet cage : fait référence.")
78
Variabilité : conséquences
Rechercher une différence : Facile de montrer une différence entre les deux moyennes Difficile de montrer une différence entre les deux moyennes

79
Rechercher une corrélation :
Facile de montrer une corrélation entre les deux variables Difficile de montrer une corrélation entre les deux variables

Présentations similaires