Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Alignement de séquences biologiques Laurent Duret Pôle Bioinformatique Lyonnais htt://pbil.univ-lyon1.fr/alignment.html

2
Objectifs poursuivis Les alignements permettent de comparer des séquences biologiques. Cette comparaison est nécessaire dans différents types d’études : Identification de gènes homologues Recherche de contraintes fonctionnelles communes à un ensemble de gènes ou de protéines. Prédiction de fonction Prédiction de structure (ARN, protéine) (Cf Deléage, Gaspin) Reconstitution des relations évolutives entre séquences (phylogénie) (Cf Gouy). Choix d'amorces PCR ...
 (Cf Deléage, Gaspin) Reconstitution des relations évolutives entre séquences (phylogénie) (Cf Gouy). Choix d amorces PCR. ...")
3
Alignement: représentation
Les résidus (nucléotides, acides-aminés) sont superposés de façon à maximiser la similarité entre les séquences. G T T A A G G C G – G G A A A G T T – – – G C G A G G A C A * * * * * * * * * * Mutations : Substitution (mismatch) Insertion Délétion Insertions ou délétions : indels (gap).
 sont superposés de façon à maximiser la similarité entre les séquences. G T T A A G G C G – G G A A A. G T T – – – G C G A G G A C A. * * * * * * * * * * Mutations : Substitution (mismatch) Insertion. Délétion. Insertions ou délétions : indels (gap).")
4
Quel est le bon alignement ?
G T T A C G A G T T A C G A G T T - G G A G T T G - G A * * * * * * * * * * OU G T T A C - G A G T T - - G G A * * * * * Pour le biologiste, généralement, le bon alignement est celui qui représente le scénario évolutif le plus probable

5
Fonction de score de similarité
G T T A A G G C G – G G A A A G T T – – – G C G A G G A C A * * * * * * * * * * Score = Exemple: identité = 1 mismatch = 0 gap = -1 Score = = 6

6
Modèle d'évolution (ADN)
Transition: A <-> G T <-> C Transversions : autres substitutions p(transition) > p(transversion) G T T A C G A G T T A C G A G T T - G G A G T T G - G A * * * * * * * * . * *
 > p(transversion) G T T A C G A G T T A C G A. G T T - G G A G T T G - G A. * * * * * * * * . * *")
7
Modèle d'évolution (protéines)
Code génétique Asp (GAC, GAU) Tyr (UAC, UAU) : 1 mutation Asp (GAC, GAU) Cys (UGC, UGU) : 2 mutations Asp (GAC, GAU) Trp (UGG) : 3 mutations Propriétés physico-chimiques des acides-aminés (acidité, hydrophobicité, encombrement stérique, etc.) Matrices de Dayhoff (PAM), BLOSUM: mesures des fréquences de substitutions dans des alignements de protéines homologues PAM 60, PAM 120, PAM 250 (extrapolations à partir de PAM 15) BLOSUM 80, BLOSUM 62, BLOSUM 40 (basé sur des alignements de blocs) Substitutions conservatrices
 Tyr (UAC, UAU) : 1 mutation. Asp (GAC, GAU) Cys (UGC, UGU) : 2 mutations. Asp (GAC, GAU) Trp (UGG) : 3 mutations. Propriétés physico-chimiques des acides-aminés (acidité, hydrophobicité, encombrement stérique, etc.) Matrices de Dayhoff (PAM), BLOSUM: mesures des fréquences de substitutions dans des alignements de protéines homologues. PAM 60, PAM 120, PAM 250 (extrapolations à partir de PAM 15) BLOSUM 80, BLOSUM 62, BLOSUM 40 (basé sur des alignements de blocs) Substitutions conservatrices.")
8
Pondération des gaps TGATATCGCCA TGATATCGCCA TGAT---TCCA TGAT-T--CCA
**** *** **** * *** Gap de longueur k: Pénalités linéaires: w = do + de k do : pénalité pour l'ouverture d'un gap de : pénalité pour l'extension d'un gap

9
Pondération des gaps (plus réaliste)
Estimation des paramètres sur des alignements "vrais" (par exemple basés sur l'alignement de structures connues) Gap de longueur k: Pénalités logarithmiques: w = do + de log(k) w = f(log(k), log(PAM), résidus, structure) PAM: la probabilité d'un gap augmente avec la distance évolutive Résidus, structure: la probabilité d'un gap est plus forte dans une boucle (hydrophile) que dans le cœur hydrophobe des protéines
 Gap de longueur k: Pénalités logarithmiques: w = do + de log(k) w = f(log(k), log(PAM), résidus, structure) PAM: la probabilité d un gap augmente avec la distance évolutive. Résidus, structure: la probabilité d un gap est plus forte dans une boucle (hydrophile) que dans le cœur hydrophobe des protéines.")
10
Similarité globale, locale

11
Similarité, homologie Deux séquences sont homologues ssi elles dérivent d'un ancêtre commun 30% d'identité entre deux protéines => homologie, sauf si Fragment similaire court (< 100 aa) Biais compositionnel (régions de faible complexité, par exemple riche en Pro, Ala)
 Biais compositionnel (régions de faible complexité, par exemple riche en Pro, Ala)")
12
Algorithmes d'alignement de deux séquences
Algorithme de programmation dynamique : Alignement global: Needleman & Wunsh Alignement local: Smith & Waterman Heuristiques : FASTA BLAST

13
Alignement multiple: programmation dynamique
La généralisation de l’algorithme N&W au traitement simultané de plus de deux séquences est théoriquement possible mais inexploitable en pratique. Pour un alignement de n séquences le nombre de chemins possibles pour chaque case est de 2n – 1. On a une croissance exponentielle du temps de calcul et de l'espace mémoire requis en fonction du nombre de séquences. Utilisation de méthodes heuristiques.

14
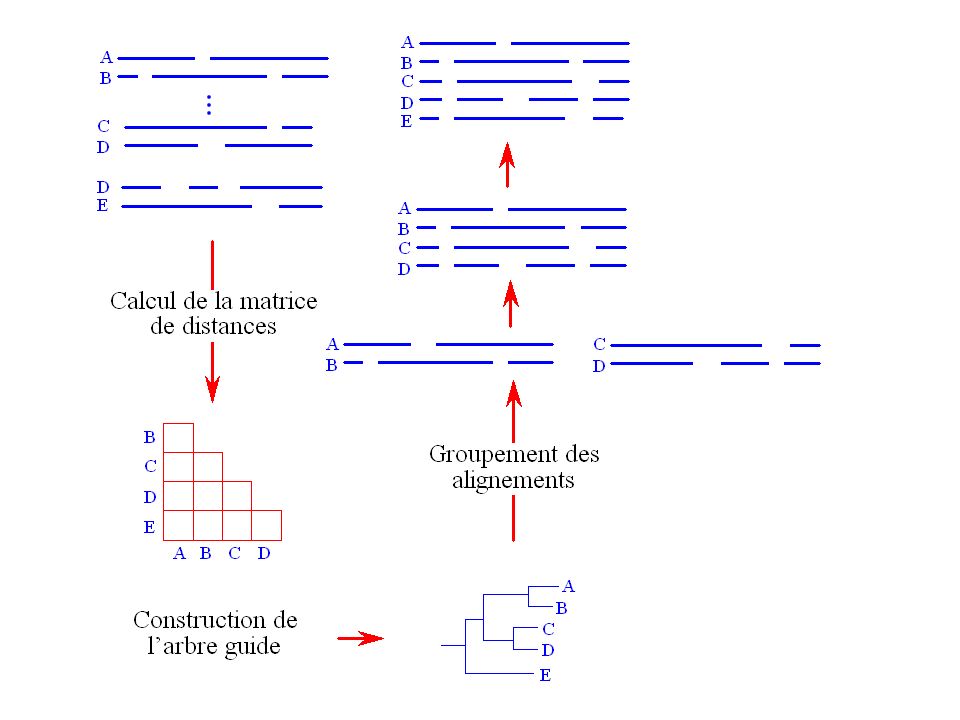
Alignement progressif
Approche consistant à construire itérativement l’alignement multiple en groupant des alignements de paires de séquences. Ce genre de méthodes comporte trois étapes : L’alignement des paires de séquences. Le groupement des séquences. Le groupement des alignements (alignement progressif). CLUSTAL (Higgins, Sharp 1988, Thompson et al., 1994), le programme d’alignements multiples le plus utilisé à l’heure actuelle utilise cette approche. MULTALIN, PILEUP, T-Coffee
. CLUSTAL (Higgins, Sharp 1988, Thompson et al., 1994), le programme d’alignements multiples le plus utilisé à l’heure actuelle utilise cette approche. MULTALIN, PILEUP, T-Coffee.")
16
Pénalités en fonction de la position
CLUSTAL introduit des pondérations qui sont dépendantes de la position des gaps. Diminution de la pénalité à l’emplacement de gaps préexistants. Augmentation de la pénalité au voisinage (8 résidus) de gaps préexistants. Réduction de la pénalité au niveau de régions contenant des suites d’acides aminés hydrophiles (≥ 5 résidus). Modification spécifiques en fonction des acides aminés présents (e.g., la pénalité est plus faible avec Gly, Asn, Pro). Ces pondérations sont prises en compte au moment du groupement des alignements.
 de gaps préexistants. Réduction de la pénalité au niveau de régions contenant des suites d’acides aminés hydrophiles (≥ 5 résidus). Modification spécifiques en fonction des acides aminés présents (e.g., la pénalité est plus faible avec Gly, Asn, Pro). Ces pondérations sont prises en compte au moment du groupement des alignements.")
17
Alignement progressif: pas toujours optimal
Un seul des ces trois alignements est optimal

18
T-Coffee Notredame, Higgins, Heringa (2000) JMB 302:205
 JMB 302:205")
19
T-Coffee Notredame, Higgins, Heringa (2000) JMB 302:205 http://igs-server.cnrs-mrs.fr/~cnotred/
Alignement progressif Lors des alignements intermédiaire, prise en compte de tous les alignements deux à deux (globaux et locaux) Possibilité d'incorporer d'autres informations (structure, etc.)
 Possibilité d incorporer d autres informations (structure, etc.)")
20
Alignements globaux, alignements par bloc

21
Dialign Morgenstern et al. 1996 PNAS 93:12098
Recherche de blocs similaires (≠ exact) sans gap entre les séquences Sélection de la meilleure combinaison possible de blocs similaires (uniformes ou non) consistents : heuristique (Abdeddaim 1997) Alignement ancré sur les blocs Plus lent que alignement progressif, mais meilleur alignement quand les séquences contiennent de grands indels; ne cherche pas à aligner des régions non-alignables
 sans gap entre les séquences. Sélection de la meilleure combinaison possible de blocs similaires (uniformes ou non) consistents : heuristique (Abdeddaim 1997) Alignement ancré sur les blocs. Plus lent que alignement progressif, mais meilleur alignement quand les séquences contiennent de grands indels; ne cherche pas à aligner des régions non-alignables.")
22
Alignements locaux MEME MATCH-BOX PIMA

23
Bilan ClustalW Dialign T-coffee MEME

24
Éditeur d ’alignement multiple

25
Cas particuliers Alignement de séquences ADN codantes
L F L F CTT TTC CTT TTC CTC CTC L L alignement des séquences protéiques traduction-inverse de l'alignement protéique en alignement nucléique Alignement cDNA / génomique: SIM4 Alignement protéine / génomique: WISE2

26
Limitation des comparaisons deux à deux (BLAST, FASTA, ...)
Seq A CGRRLILFMLATCGECDTDSSE … HICCIKQCDVQDIIRVCC :: : ::: :: : : Insuline CGSHLVEALYLVCGERGFFYTP … EQCCTSICSLYQLENYCN ::: : : : :: : : Seq B YQSHLLIVLLAITLECFFSDRK … KRQWISIFDLQTLRPMTA Comparaisons 2 à 2: Insuline / Seq A : 25% d'identité Insuline / Seq B : 25% d'identité

27
Alignement de séquences de la famille des insulines
B-chain A-chain INSL4 Q ELRGCGPRFGKHLLSYCPMPEKTFTTTPGG...[x] SGRHRFDPFCCEVICDDGTSVKLCT INSL3 P REKLCGHHFVRALVRVCGGPRWSTEA [x] AAATNPARYCCLSGCTQQDLLTLCPY RLN1 P VIKLCGRELVRAQIAICGMSTWS [x] PYVALFEKCCLIGCTKRSLAKYC BBXA P VHTYCGRHLARTLADLCWEAGVD [x] GIVDECCLRPCSVDVLLSYC BBXB P ARTYCGRHLADTLADLCF--GVE [x] GVVDECCFRPCTLDVLLSYCG BBXC P SQFYCGDFLARTMSILCWPDMP [x] GIVDECCYRPCTTDVLKLYCDKQI BBXD P GHIYCGRYLAYKMADLCWRAGFE [x] GIADECCLQPCTNDVLLSYC LIRP P VARYCGEKLSNALKLVCRGNYNTMF [x] GVFDECCRKSCSISELQTYCGRR MIP I P RRGVCGSALADLVDFACSSSNQPAMV [x] QGTTNIVCECCMKPCTLSELRQYCP MIP II P PRGICGSNLAGFRAFICSNQNSPSMV [x] QRTTNLVCECCFNYCTPDVVRKYCY MIP III P PRGLCGSTLANMVQWLCSTYTTSSKV [x] ESRPSIVCECCFNQCTVQELLAYC MIP V P PRGICGSDLADLRAFICSRRNQPAMV [x] QRTTNLVCECCYNVCTVDVFYEYCY MIP VII P PRGLCGNRLARAHANLCFLLRNTYPDIFPR...[x]86 ..EVMAEPSLVCDCCYNECSVRKLATYC ILP P AEYLCGSTLADVLSFVCGNRGYNSQP [x] GLVEECCYNVCDYSQLESYCNPYS INS P NQHLCGSHLVEALYLVCGERGFFYTPKT.....[x] GIVEQCCTSICSLYQLENYCN IGF1 P PETLCGAELVDALQFVCGDRGFYF [x] GIVDECCFRSCDLRRLEMYCAPLK IGF2 P SETLCGGELVDTLQFVCGDRGFYF [x] GIVEECCFRSCDLALLETYCATPA * * ** * *

28
Représentation d ’un motif par une matrice de fréquences (exemple)
Site donneur d ’épissage (vertébrés) Matrice de fréquence (pourcentage): Base Position A C G T Cons. M A G G T R A G T
 Matrice de fréquence (pourcentage): Base Position A C G T Cons. M A G G T R A G T.")
29
PSI-BLAST Position-Specific Iterated BLAST 1-recherche BLAST classique
2-construction d'une matrice de pondération (profil) avec les séquences similaires détectées 3-recherche BLAST à partir de ce nouveau profil 4-itération des étapes 2-3 jusqu'à convergence plus sensible que Smith-Waterman 40 fois plus rapide
 avec les séquences similaires détectées. 3-recherche BLAST à partir de ce nouveau profil. 4-itération des étapes 2-3 jusqu à convergence. plus sensible que Smith-Waterman. 40 fois plus rapide.")
Présentations similaires







>")











