Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Evaluation des performances des tests diagnostiques en absence de Gold Standard Christophe Combescure Laboratoire de Biostatistique, IURC

2
Problématique Indicateurs classiques des performances: –Sensibilité( )=Prob[T> |D=1] –Spécificité( )=Prob[T< |D=0] L’information malade/non malade est donnée par le Gold Standard (GS), supposé parfait. Mais en pratique le GS est aussi un test diagnostique Conséquences: –La sensibilité et la spécificité représentent la capacité du test diag. à reproduire les résultats du GS. –Il est impossible de montrer qu’un test diagnostique est meilleur que le GS. Le GS peut ne pas exister (psychiatrie), ou ne peut pas être mis en œuvre (coût,…). Malade ouiNon Test évalué +AB -CD
![Problématique Indicateurs classiques des performances: –Sensibilité( )=Prob[T> |D=1] –Spécificité( )=Prob[T< |D=0] L’information malade/non malade est donnée par le Gold Standard (GS), supposé parfait.](http://images.slideplayer.fr/17/5416865/slides/slide_2.jpg "Mais en pratique le GS est aussi un test diagnostique Conséquences: –La sensibilité et la spécificité représentent la capacité du test diag. à reproduire les résultats du GS. –Il est impossible de montrer qu’un test diagnostique est meilleur que le GS. Le GS peut ne pas exister (psychiatrie), ou ne peut pas être mis en œuvre (coût,…). Malade ouiNon Test évalué +AB -CD.")
3
K tests diagnostiques binaires Contexte: GS absent. Soient K tests binaires et R le vecteur aléatoire de leurs résultats et D la variable « malade/non malade ». Alors: Et la log vraisemblance des données observées s’écrit: D est la classe latente. En complétant les données observées par la variable D, alors les données observées se décomposent en deux effectifs latents: où Xr (resp. Yr) est l’effectif des non malades (resp. malades) ayant le résultat aux tests R
 est l’effectif des non malades (resp. malades) ayant le résultat aux tests R.")
4
La log vraisemblance des données complètes s’écrit: Cette log vraisemblance se maximise facilement: D’où l’utilisation de l’algorithme EM.

5
Généralités sur l’algorithme EM La log vraisemblance des données observées est notée: On suppose que les données Y sont complétées par Z de telle manière que l’estimation des paramètres en maximisant la vraisemblance des données complètes est possible. On note: Etape E: calcul de (revient dans les fait à estimer les effectifs latents par leur espérance conditionnelle) Etape M:
 Etape M:.")
6
Remarque: –Convergence mais vers des points stationnaires Variance des estimateurs (T. Louis, 1982) On note H(q|q (k) ) l’espérance du log de la vraisemblance de la variable Z conditionnellement à la variable Y : Les variances des paramètres estimés peuvent se déduire en utilisant la matrice d’information de Fisher. La matrice d’information de Fisher se décompose en deux termes :
 On note H(q|q (k) ) l’espérance du log de la vraisemblance de la variable Z conditionnellement à la variable Y : Les variances des paramètres estimés peuvent se déduire en utilisant la matrice d’information de Fisher. La matrice d’information de Fisher se décompose en deux termes :.")
7
Retour aux K tests binaires Nécessité de poser des hypothèses sur les probabilités conjointes des scores sinon il y a surparamétrisation Hypothèse d’indépendance conditionnelle entre les tests: hypothèse la plus simplificatrice Le nombre de paramètres devient 2K+1, le nombre de ddl est 2 K -1. Nécessité que K>2 Etape E: estimation des effectifs latents

8
Etape M:

9
Application: - lecture de clichés IRM avant et après injection d’un produit de contraste - 2 lecteurs - Gold Standard: biopsie EtudePaysNombre de patients Nombre de centres Pathologies 1Allemagne182Breast France22Breast Grande Bretagne91Breast 2Allemagne271Ent Belgique152Ent France394Ent 3France304Lung 4Allemagne242Pelvis Pays Bas111Pelvis Suisse162Pelvis 5Belgique91Ent France212Ent 6Allemagne61Rectal Italie142Rectal

10
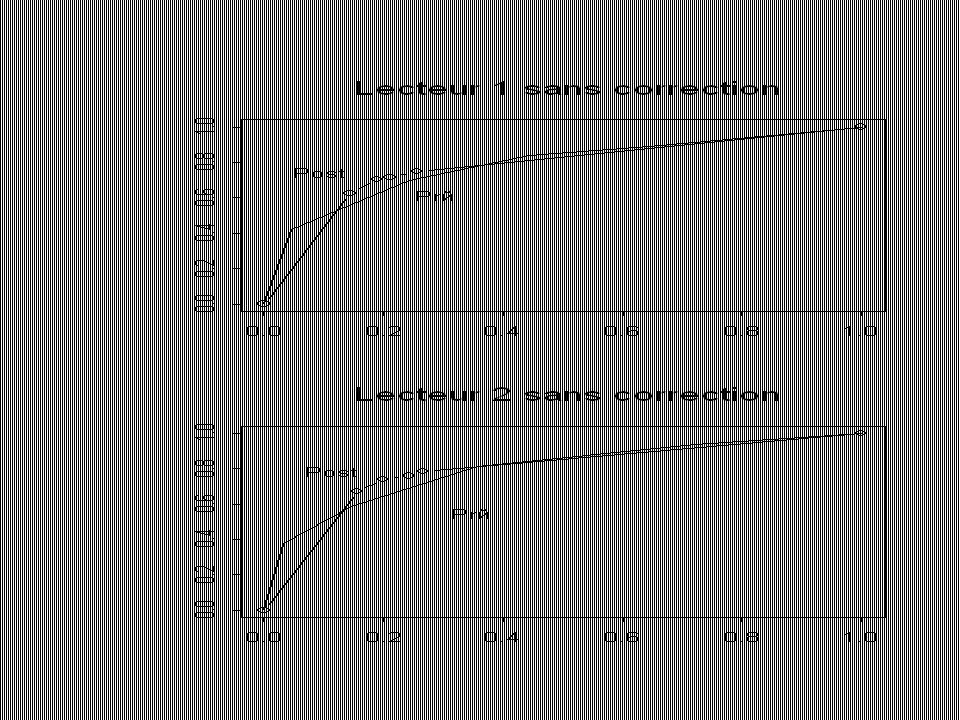
Données poolées Prévalence0.407 (0.042) Sensibilités Lecteur 1 Test 10.919 (0.042) Lecteur 1 Test 20.901 (0.035) Lecteur 2 Test 10.802 (0.050) Lecteur 2 Test 21.000 (0.042) Gold standard0.938 (0.028) Spécificités Lecteur 1 Test 10.796 (0.045) Lecteur 1 Test 20.817 (0.042) Lecteur 2 Test 10.891 (0.031) Lecteur 2 Test 20.844 (0.038) Gold standard0.709 (0.048)
 Sensibilités Lecteur 1 Test (0.042) Lecteur 1 Test (0.035) Lecteur 2 Test (0.050) Lecteur 2 Test (0.042) Gold standard0.938 (0.028) Spécificités Lecteur 1 Test (0.045) Lecteur 1 Test (0.042) Lecteur 2 Test (0.031) Lecteur 2 Test (0.038) Gold standard0.709 (0.048)")
11
Estimation pour les différents niveaux de lecture considérés séparément Lecteur 1 Test 1 Lecteur 1 Test 2 Lecteur 2 Test 1 Lecteur 2 Test 2 Prévalences Etude 10.270 (0.128)0.463 (0.138)0.210 (0.118)0.368 (0.132) Etude 20.658 (0.097)0.741 (0.089)0.646 (0.095)0.692 (0.091) Etude 30.470 (0.143)0.498 (0.145)0.228 (0.126)0.350 (0.135) Etude 40.125 (0.077)0.332 (0.111)0.220 (0.094)0.226 ( 0.092) Etude 50.899 (0.087)0.933 (0.070)0.881 (0.099)0.896 (0.085) Etude 60.227 (0.182)0.411 (0.208)0.136 (0.162)0.146 (0.168) TestSe0.864 (0.597)0.725 (0.182)0.741 (0.175)0.859 (0.342) Spé0.833 (0.243)0.891 (0.320)0.897 (0.103)0.870 (0.355) Gold standard Se0.895 (0.475)0.903 (0.077)0.936 (0.051)0.916 (0.215) Spé0.748 (0.320)0.957 (0.133)0.760 (0.189)0.818 (0.463)
0.463 (0.138)0.210 (0.118)0.368 (0.132) Etude (0.097)0.741 (0.089)0.646 (0.095)0.692 (0.091) Etude (0.143)0.498 (0.145)0.228 (0.126)0.350 (0.135) Etude (0.077)0.332 (0.111)0.220 (0.094)0.226 ( 0.092) Etude (0.087)0.933 (0.070)0.881 (0.099)0.896 (0.085) Etude (0.182)0.411 (0.208)0.136 (0.162)0.146 (0.168) TestSe0.864 (0.597)0.725 (0.182)0.741 (0.175)0.859 (0.342) Spé0.833 (0.243)0.891 (0.320)0.897 (0.103)0.870 (0.355) Gold standard Se0.895 (0.475)0.903 (0.077)0.936 (0.051)0.916 (0.215) Spé0.748 (0.320)0.957 (0.133)0.760 (0.189)0.818 (0.463)")
12
Estimation pour les différents niveaux de lecture considérés appariés Lecteur 1 Test 1 Lecteur 1 Test 2 Lecteur 2 Test 1 Lecteur 2 Test 2 Prévalences Etude 10.247 (0.122) Etude 20.537 (0.082) Etude 30.294 (0.135) Etude 40.167 (0.077) Etude 50.742 (0.079) Etude 60.227 (0.193) TestSe0.950 (0.040)0.894 (0.047)0.819 (0.068)0.984 (0.028) Spé0.809 (0.037)0.804 (0.040)0.895 (0.028)0.823 (0.036) Gold standard Se0.937 (0.032) Spé0.701 (0.043)
 Etude (0.082) Etude (0.135) Etude (0.077) Etude (0.079) Etude (0.193) TestSe0.950 (0.040)0.894 (0.047)0.819 (0.068)0.984 (0.028) Spé0.809 (0.037)0.804 (0.040)0.895 (0.028)0.823 (0.036) Gold standard Se0.937 (0.032) Spé0.701 (0.043)")
13
Introduction de la dépendance conditionnelle Les paramètres de dépendance chez les malades (i.e. d=1) sont notés k et ceux chez les non malades k. Ils sont définis par :
 sont notés k et ceux chez les non malades k. Ils sont définis par :.")
14
Lecteur 1Lecteur 2 Prévalences Etude 10.338 (0.113)0.254 (0.112) Etude 20.674 (0.087)0.617 (0.086) Etude 30.486 (0.118)0.268 (0.118) Etude 40.206 (0.087)0.190 (0.081) Etude 50.917 (0.094)0.812 (0.114) Etude 60.620 (0.161)0.204 (0.141) Test 1Sensibilité0.789 (0.067)0.754 (0.076) Spécificité0.882 (0.056)0.890 (0.040) Test 2Sensibilité0.814 (0.064)0.879 (0.068) Spécificité0.892 (0.060)0.800 (0.051) Covariance entre les tests 1et 2 Non malades0.100 (0.072)0.121 (0.136) Malades-0.026 (0.070)0.038 (0.048) Gold StandardSensibilité0.853 (0.053)0.946 (0.049) Spécificité0.774 (0.065)0.775 (0.063)
0.254 (0.112) Etude (0.087)0.617 (0.086) Etude (0.118)0.268 (0.118) Etude (0.087)0.190 (0.081) Etude (0.094)0.812 (0.114) Etude (0.161)0.204 (0.141) Test 1Sensibilité0.789 (0.067)0.754 (0.076) Spécificité0.882 (0.056)0.890 (0.040) Test 2Sensibilité0.814 (0.064)0.879 (0.068) Spécificité0.892 (0.060)0.800 (0.051) Covariance entre les tests 1et 2 Non malades0.100 (0.072)0.121 (0.136) Malades (0.070)0.038 (0.048) Gold StandardSensibilité0.853 (0.053)0.946 (0.049) Spécificité0.774 (0.065)0.775 (0.063)")
15
2 tests ordinaux Notations : : la prévalence de la maladie dans l’étude. i +, i=1,…,R : probabilité d’avoir un score i au test 1 dans le groupe des patients réellement malades (i.e. dans la classe latente D=1). i -, i=1,…,R : probabilité d’avoir un score i au test 1 dans le groupe des patients réellement non malades (i.e. dans la classe latente D=0). j +, j=1,…,R : probabilité d’avoir un score j au test 2 dans le groupe des patients réellement malades (i.e. dans la classe latente D=1). j -, j=1,…,R : probabilité d’avoir un score j au test 2 dans le groupe des patients réellement non malades (i.e. dans la classe latente D=0). N ij le nombre de patients qui ont un score i au test 1, un score j au test 2. N ij se décompose de la manière suivante: N ij =X ij +Y ij
. i -, i=1,…,R : probabilité d’avoir un score i au test 1 dans le groupe des patients réellement non malades (i.e. dans la classe latente D=0). j +, j=1,…,R : probabilité d’avoir un score j au test 2 dans le groupe des patients réellement malades (i.e. dans la classe latente D=1). j -, j=1,…,R : probabilité d’avoir un score j au test 2 dans le groupe des patients réellement non malades (i.e. dans la classe latente D=0). N ij le nombre de patients qui ont un score i au test 1, un score j au test 2. N ij se décompose de la manière suivante: N ij =X ij +Y ij.")
16
la vraisemblance s’écrit en fonction des paramètres de la manière suivante: Dans l’étape E de l’algorithme EM, les effectifs latents sont estimés par leur espérance conditionnelle : ou encore:

17
Dans l’étape M de l’algorithme EM, les paramètres sont estimés en maximisant l’espérance conditionnelle de la log-vraisemblance des données latentes :

18
ScoreLecteur 1Lecteur 2 Test 1Test 2Test 1Test 2 Malade Test 10.00 (0.05) 0.02 (0.05) 20.02 (0.04)0.05 (0.02)0.05 (0.05)0.01 (0.02) 30.08 (0.04)0.01 (0.01)0.20 (0.04)0.00 (0.03) 40.34 (0.05)0.09 (0.02)0.27 (0.03)0.09 (0.02) 50.560.850.480.88 GS+0.92 (0.05)0.91 (0.05) Non malade Test 10.38 (0.02)0.82 (0.10)0.29 (0.15)0.79 (0.03) 20.19 (0.02)0.03 (0.02)0.38 (0.03)0.04 (0.02) 30.24 (0.03)0.02 (0.01)0.23 (0.05)0.05 (0.03) 40.17 (0.05)0.04 (0.03)0.08 (0.06)0.03 (0.03) 50.020.080.010.08 GS-0.72 (0.04)0.74 (0.04)
 0.02 (0.05) (0.04)0.05 (0.02)0.05 (0.05)0.01 (0.02) (0.04)0.01 (0.01)0.20 (0.04)0.00 (0.03) (0.05)0.09 (0.02)0.27 (0.03)0.09 (0.02) GS+0.92 (0.05)0.91 (0.05) Non malade Test (0.02)0.82 (0.10)0.29 (0.15)0.79 (0.03) (0.02)0.03 (0.02)0.38 (0.03)0.04 (0.02) (0.03)0.02 (0.01)0.23 (0.05)0.05 (0.03) (0.05)0.04 (0.03)0.08 (0.06)0.03 (0.03) GS-0.72 (0.04)0.74 (0.04)")
19
Modélisation selon Agresti Pour des données ordinales, Agresti propose un modèle avec une association de type « linear-by-linear » : où u 1 <…<u r sont les scores attribués à chaque réponse. Ce modèle a un seul paramètre en plus que le modèle sous indépendance, et log odds ratio locaux sont :

20
Introduction dans les modèles à classes latentes (Agresti A. and Lang J.B., 1993) : où D la variable latente, u i et u j les scores observés aux tests 1 et 2 respectivement, et u d la classe latente Etape E: en fonction des paramètres, on estime la probabilité d’être malade sachant les scores et les effectifs latents Etape M: à partir des effectifs latents estimés dans l’étape E, on estime par maximum de vraisemblance le modèle de régression
 : où D la variable latente, u i et u j les scores observés aux tests 1 et 2 respectivement, et u d la classe latente Etape E: en fonction des paramètres, on estime la probabilité d’être malade sachant les scores et les effectifs latents Etape M: à partir des effectifs latents estimés dans l’étape E, on estime par maximum de vraisemblance le modèle de régression.")
22
Questions/Perspectives Variantes de EM plus adaptées à cette problématique ou adaptées à de petits effectifs ? Mesure de l’adéquation des modèles Simulation de données ordinales appariées pour valider les algorithmes Modèles de régression ordinale pour données appariées (prise en compte de la covariance entre 2 tests) Gold standard imparfait sur un seul test diagnostique Etude du nombre nécessaire de patients
 Gold standard imparfait sur un seul test diagnostique Etude du nombre nécessaire de patients.")
Présentations similaires

>")











>")





