Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Etat de l’art, évaluation des outils existants
Découverte des sites de liaison dans des séquences ADN des eucaryotes pluricellulaires Etat de l’art, évaluation des outils existants Maximilian Haeusser Groupe Symbiose IRISA Rennes Oct 2003

2
Plan La situation biologique Principales approches en Bioinfo
Découverte des motifs Enumération Gibbs Sampler Réduire le bruit La Pratique: Evaluation des outils Extraction des séquences Comparaison Découverte Conclusion

3
La situation biologique
"The difference between man and monkey is gene regulation." (Leroy Hood, 2001)
")
4
Les facteurs de transcriptions (FT) s’attachent à leurs fragments de l’ADN
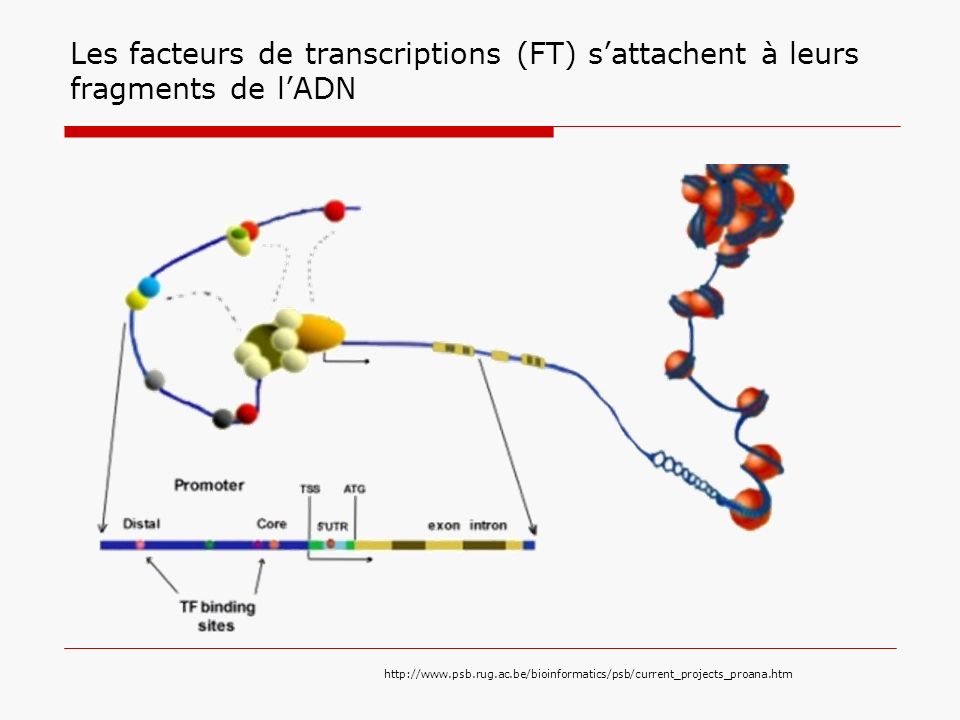
5
Les FT forment des modules
La distance et l’ordre peuvent etre important Il y a des FT, qui ne peuvent pas se lier seul. Il leur faut un autre FT. des FT qui empêchent d’autres FT à se lier Des modules de plusieurs FT qui sont empechés par d’autres modules de se lier Toute une logique permettant de n’initier la transcription que sous certaines conditions Les sites ont une structure spécifique Tutorial Regulatory Sequences, T. Werner, ISMB 2000

6
Les modules sont nombreux
Une impression du nombre et de la structure des motifs pour quelques gènes de la drosophilie

7
Le cas de bactéries est plus facile
Les bactériens n’ont qu’une cellule, donc, moins de conditions pour la régulation Elles ont moins de place sur le génome pour les éléments régulateurs, il est donc plus facile de trouver les sites Ils n’ont pas d’introns Presque tous les logiciels pour trouver les sites de liaison s’appliquent qu’aux bactéries

8
D’autres circonstances sur la transcription
Chromatine, la flexibilité, méthylation, etc. S/MARs, LCRs, etc… => Etre présent ne veut pas dire qu’on trouve vraiment un effet Felsenfeld et al, Nature 421, (23 January 2003);
;")
9
Pas d’expériences haut-débit
In vitro: Essais gel shift / ADNase / ChiP Longue a mettre au point In vivo: Mutations systématiques Beaucoup plus longue, difficile pour les mammifères Donc: Trop de boulot, puisqu’il y a des milliers des FTs

10
Réduire le nombre des mutations nécessaires:
Il y a des gènes qui ont des sites de liaison en commun On cherche les fragments que plusieurs genes ont en commun Comment trouver des tels gènes? Expression (Mme Lagarrigue) Réseau génétique (Mme Theret) fonction ou tissu identiques (GO)
 Réseau génétique (Mme Theret) fonction ou tissu identiques (GO)")
11
« The twilight zone of pattern discovery » (Pevzner2002)
L’évolution change l’ADN: Des mutations qui empêchent le FT de se fixer a l’ADN ne sont pas viables Des mutations qui font le motif trop semblable aux d’autres motifs ne sont pas viables Des mutations qui préservent juste la capacité d’attirer le FT et sont assez uniques dans le génome restent Les motifs sont bien cachés mais ils devraient rester trouvables

12
Principales approches pour la découverte de motifs
Petite etude bibliographique

13
Découverte des motifs Plutôt informatique: Enumerisation
Arbre des suffix Plutôt statistiques: Gibbs Sampler Expectation maximization Dictionary based

14
Enumerisation -approche naïve-
Le modèle du motif est une chaîne de lettres. On fait une liste de toutes les combinaisons des letters ATCG d’un certain longueur On compte combien de fois ces fragments apparaissent dans les séquences On compte aussi les fragments qui sont similaire (p.ex. « ACCCT » est presque « ACTCT », comme ça, on augmente les compteurs des deux fragments) Les meilleurs fragments sont retournés Petite amélioration: Au lieu de 1., on prend juste tous les fragments qu’on trouve dans les séquences
 Les meilleurs fragments sont retournés. Petite amélioration: Au lieu de 1., on prend juste tous les fragments qu’on trouve dans les séquences.")
15
Arbre des suffixes Un peu la même chose que l’enumérisation mais plus rapide et il prend moins de mémoire

16
Les motifs consensus sont à eviter
Dire que la boite TATA a un consensus de TATAAT donne une mauvaise impression de la réalité Seulement 14 de 291 sites correspondent à ce modèle Et si on compte les positions où il y a des desappariements, on ne sait pas où ils se trouvent TATAAT ?

17
Matrice pondérée Le modèle du motif est une liste des probabilités
Chaque position donne pour chaque acide nucléide une probabilité En plus, l’information content mesure la répartition des probabilités: Plus une base est bruitée, plus il est bas => Le logo ameliore la recherche des motifs connus

18
Gibbs Sampler Piqué de: Denis Thiery, ESIL Marseille

19
Réduire le bruit Des bases conservées: Des données d’expression
Les motifs sont mieux conservés que le reste de la région non codante (pression sélective) Un motif qui est mieux conservé qu’un autre est plutôt un vrai motifs => Moins qu’un motif est bruité, plus son score est haut Des données d’expression Idée: Forte expression <=> Forte probabilité qu’un FT se lie a ce fragment <=> motif bien conserve ou plusieurs motifs dans la seq (Et le contraire: Faible expression <=> motif dégénéré) => Des motifs qui correspondent a ce modèle ont un haut score
 Un motif qui est mieux conservé qu’un autre est plutôt un vrai motifs. => Moins qu’un motif est bruité, plus son score est haut. Des données d’expression. Idée: Forte expression. <=> Forte probabilité qu’un FT se lie a ce fragment. <=> motif bien conserve ou plusieurs motifs dans la seq. (Et le contraire: Faible expression <=> motif dégénéré) => Des motifs qui correspondent a ce modèle ont un haut score.")
20
Un essai concret Les genes LXR, SREBF1, ABCA1 et FASN qui ont tous
au moins le motif LXRE en commun -> Est-ce qu’on va le trouver?

21
Les problèmes Extraction en masse des régions promotrices d’un génome
(Trouver des régions conservées) Trouver des motifs communs 4. Trouver les combinaisons communes
 Trouver des motifs communs. 4. Trouver les combinaisons communes.")
22
1 - Extraction de la region “promotrices”
Debut de translation Initiation de transcription La région en amont de la région codante n’est pas, pour les eucaryotes, la région promotrices. L’exon 1 est souvent pas codant. Il y a de longues introns (quelques milliers des bases) Source: Genomatix Tutorial
 Source: Genomatix Tutorial")
23
Extraction des régions en amont d’un gène
Problème: Pas de TSS annoté + séquences RefSeq pas assez longues => Sites d’initiation souvent incorrects (DBTSS: 30%) => la recherche pour la région en amont d’un gène prend beaucoup de temps et est diffcile à trouver sans expériences pour quelques gènes
 => la recherche pour la région en amont d’un gène prend beaucoup de temps et est diffcile à trouver sans expériences pour quelques gènes.")
24
Outils d’extraction des « promoteurs »
On aligne quelques séquences ARNm sur le génome et prend la région devant. Le nombre des séquences varie selon l’outil RSA-Tools 1999, PEG 2001, FIE 2002, Upstreamer 2002, Ensmart 2002, Promoser 2003 On essaie de trouver la région promotrices en exploitant sa composition PromoterInspector 2001, McPromoter 2001, Dragon Promoter Finger 2002, PromH 2003… (autour de 70% de sensitivité?)
")
25
L’Alignment des EST TSS?
UCSC Browser BLAT result view, prediction TSS de Promoser contre FIE, humain, gène SREBF1

26
Exemple: Le vrai TSS pour LXR
Différence: ~1200 bp (Toucan utilise l’annotation d’Ensembl, ou lxre est donc introuvable) NR1H3 humain Vu par DBTSS
 NR1H3 humain. Vu par DBTSS.")
27
Problème: On trouve trop de sites
Même si on connaît le motif, on trouve trop d’instances: ~1300 …et si on filtre et prend seulement des motifs qui apparaissent dans toutes les quatre séquences: ~370 FASN, ABCA1, CYP7A1, SREBF1 de la souris en Genomatix Matinspector

28
Avec un modèle Markov (Toucan)
Le modèle Markov est un modèle de bruit Tous les Gibbs Sampler actuels l’ont A quel prix? Klaus May: Exercice statistique sans valeur, on perd aussi les vrais, faibles motifs (en général?), qui se fixent en modules Gert Thijs et al: Très utile, on trouve mieux les motifs déjà décrits (exemple: Les procaryotes) => Les motifs déjà décrits, sont-ils aussi les motifs les mieux conservés? MotifScanner avec «epd mouse 3rdorder» et Transfac public vertebrate
, qui se fixent en modules. Gert Thijs et al: Très utile, on trouve mieux les motifs déjà décrits (exemple: Les procaryotes) => Les motifs déjà décrits, sont-ils aussi les motifs les mieux conservés MotifScanner avec «epd mouse 3rdorder» et Transfac public vertebrate.")
29
Quelques Algos pour la découverte des motifs
MEME 1994 MACAW CoResearch 1996 R’MES 1997 AlignACE 1998 Yebis CONSENSUS 1999 Et les resultats furent autour de 1998*… * Motifs: Spellman et al 1998, Mol Biol Cell 9, , Réseaux: Tavazoie et al. 1999, Nat Genetics, 22:

30
48 Algos pour la découverte des motifs

31
48 49 Algos pour la découverte des motifs

32
Comment choisir? Comparaisons nécessaires Compétition de M. Tompa
Pas d’exemple commun Pas d’exemple reconnu (comme l’EPD pour la prédiction des promoteurs) On choisit un exemple qui donne le meilleure résultat pour l’article Un bon résultat dans l’article n’en dit pas beaucoup Compétition de M. Tompa Données artificielles Pas encore prêtes
 On choisit un exemple qui donne le meilleure résultat pour l’article. Un bon résultat dans l’article n’en dit pas beaucoup. Compétition de M. Tompa. Données artificielles. Pas encore prêtes.")
33
MotifSampler Motifsampler: Gibbs Sampler avec modèle Markov
Repeatmasker Une belle interface Sans exemple négatif: 15 fragments, dont 3 corrects, 1 non trouvé Le reste? 12 ? Décrit? Nouveau?

34
MotifSampler sans Repeatmasker
MotifSampler devient plutôt un détecteur des répétitions: En bleu, rempli = les motifs trouvé par MotifSampler En noir = les vrais motifs LXRE En jaune et bleu = les régions répétées Parameters MotifSampler-: 50 runs, 2 executions, filtrer les sites communs Repeatmasker: rodent, sensitive - LXRE d’apres la litterature

35
La structure 3D de l’ADN n’est pas négligeable
Information Content SREBF1c-Motif from Genomatix Matrix Database, ACC V$SREBP.03 Srebf1 from NCBI, viewed in Cn3D, ACC mmid:7919

36
Idée, d’après Moses et al:
On peut distinguer les vrais motifs des artéfacts des algorithmes: On compare les changements des fragments de ce motifs qu’on observe dans les mêmes régions des plusieurs espèces assez proches avec les changements des fragments de ce motif dans les séquences analysées S’ils sont corrélés, il s’agit plutôt d’un vrai motif Cela nécessite quelques séquences d’autres espèces « proches » =>Début de la sequenciation des « chimpanzees » en janvier 03, premières contigs pour les macaques déjà sur NCBI

37
Penser en modules “A TF binding site becomes only biologically relevant in its context” (Klaus May, Genomatix) Trouver un site de liaison ne dit rien, ce sont les autres sites qui rendent le motif fonctionnel Les combinaisons des motifs peuvent être plus faibles, car ils ont plus de points de contact Les motifs plus faibles sont plus importants Il va falloir se concentrer sur la composition des modules, à la manière des protéines Classification & Clustering pour élucider les combinaisons des sites de liaisons Arbre de décision? (déjà fait, pas d’implementation) Réseau de bayes? Chaval? (à faire) Classification avec l’inférence grammaticale? (à faire)
 Réseau de bayes Chaval (à faire) Classification avec l’inférence grammaticale (à faire)")
38
Il faut d’abord des données “propres”
Sont ils vraiement corregulés directement? Comment trouver un exemple d’entrainement A-t-on la vraie région 5’ ???? Exist-il une séquence assez proche? Quel algo pour les alignements? Qu’est ce que une bonne base de motifs… … et un bon algo pour la découverte? A la fin: Pas trop d’erreurs accumulés?

39
Résume: La découverte de motifs nécessite une gamme d’autres outils en bioinformatique Il parait improbable que les motifs dans les eucaryotes soient assez bien conservés qu’on puisse utiliser la découverte de motifs seul pour les élucider Mais au moyen terme la comparaison entre espèces va aider beaucoup et il va indiquer les vrais motifs Pour trouver les modules, on pourrait déjà essayer d’appliquer la classification, si on avait des bons exemples (ou quelqu’un qui faisait toutes ces expériences…)
")
41
Annexe: le chemin long d’un FT

42
On peut les grouper selon leur structure
Helix-turn-Helix Homeobox Zinc Finger Alberts et al, Molecular Biology of the Cell, 3rd Ed., Chapitre 9

43
Gibbs sampler On prend un fragment d’un longeur w par hasard. On le prend comme “matrice”. On la compare avec tous les fragments du longeur w dans nos séquences S’il y en a un qui lui ressemble assez, on le prend comme fragment de ce motif et on met a jour la matrice avec lui Amélioration contesté: Pour avoir une idee de « se ressembler » on prend une chaine Markov pour le bruit “background”.

44
Pas toujours, mais il réduit le nombre des possibilités
UCSC Browser, souris, gène Abca1, BLAT des deux meilleurs prédictions de Promoser

45
Celui qui cherche va trouver
Séquences tout a fait “random” Mais: MotifSampler trouve plein de motifs… Avec un score plus bas que pour les vrais séquences Mais seulement pour les quatre meilleurs motifs!

46
La structure 3D, II Rate of evolution IC in bits
Moses et al., BMC evol Biol 3:19, 28/08/2003

47
Outils de comparaison ClustalW AVID Dalign Dynalign Idées?
Pattern Explorer!

Présentations similaires




…+…-… …-3(2x+5) …-(5x-7) …- 2+6x-3 …?>")



>")











