Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Bookbinders book club case
Audrey Hamel Anne-Marie Nadeau 21 février 2007

2
Mise en Contexte L’industrie du livre Vente de livres
nouveaux titres par année au USA Rapporte 20 M de dollars annuellement 10 % des livres sont vendus par envoi postal Vente de livres 1970 apparition des grandes chaînes de librairies 1980 vente de livres dans les grands magasins à rayon 2000 vente de livre en ligne

3
Mise en Contexte Les clubs de livre
Historiquement proposaient des contrats d’achat de livres aux consommateurs Un lecteur accepte d’acheter quelques livres et de recevoir chaque mois 1 ou 2 livres supplémentaires Face à l’augmentation de la concurrence Utilise des bases de données pour retenir de l’information sur leur consommateurs Recherche des modèles qui vont les aider à mieux cerner les préférences de leur client

4
Bookbinders Book Club Fondé en 1986
Spécialiste dans la vente de livres spécialisés Rejoint ses clients à l’aide de marketing direct Possède une base de données avec de l’information sur lecteurs Problématique: La compagnie se demande si l’utilisation d’un modèle de prédiction serait utile pour cerner les consommateurs à cibler lors de l’envoi postal

5
Bookbinders Book Club Cas:
consommateurs ont été sélectionnés à partir d’une base de données Une offre spéciale pour un livre d’art de Florence a été envoyée par la poste 9,03% des consommateurs ont acheté le livre

6
Description des modèles de prédiction
Régression linéaire multiple On cherche à voir le degré d’influence des différentes variables sur la décision d’achat ou non du livre d’art. Multinomial logit analysis Méthode qui permet d’identifier les variables qui influencent le choix des consommateurs Neural network model Permet de comprendre la relation entre les variables dépendantes et indépendantes en essayant de comprendre le processus de traitement de l’information dans le cerveau des individus dans le but de développer des représentations sur ordinateur du mécanisme.

7
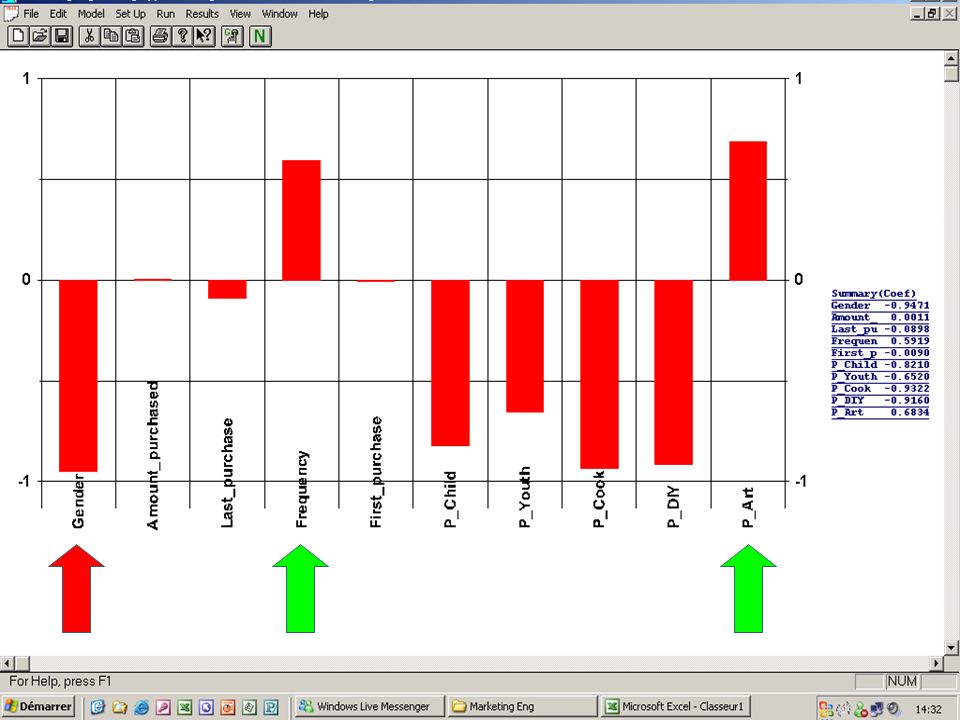
Régression linéaire multiple

8
Statistiques de la régression
Coefficient de détermination multiple 0, Coefficient de détermination R^2 0, 0, Erreur-type 0, Observations 1600

9
Statistiques de la régression
Coefficients Erreur-type Statistique t Constante 0, 0, 11, Gender -0, 0, -6, Amt_purchased 0, 0, 2, Last_purchase -0, 0, -4, First_purchase 0, 0, 7, Frequency -0, 0, -1, P_Child -0, 0, -7, P_Youth -0, 0, -4, P_Cook -0, 0, -8, P_DIY -0, 0, -6, P_Art 0, 0, 6,

10
Équation… Y choix = x gender x Amt_purch. – x last_purch x First_purch. – x freq – 0.13 x p_child – x p_youth – 0.14 x p_cook – 0.14 p_DIY x p_art

11
Neural net forcasting

12
+

13
Model fit : 17,61 % Test fit : 18,54 % Overall fit: 17,79 % Nom t-stat
Amt_purch 2,8123 First_purch 3,6694 Frequency -16,69 Last_purch 11,53 Gender -8,2594 P_Art 19,13 P_Child -7,9469 P_Cook -10,65 P_DIY -8,5867 P_Youth -3,3114 Model fit : 17,61 % Test fit : 18,54 % Overall fit: 17,79 %

14
Choice P_Art

15
Choice Frequency

16
Multinomial logit analysis

18
Diagnostic 1 Nous indique la variable qui influence le plus la réponse à l’envoi postal Gender Amt_purch Last_purch First_purch Frequency P_Child P_Youth P_Cook P_DIY P_Art 0.6587 2.0e+002 3.1988 0.7394 0.3375 0.7600 0.3913 0.4250

19
Diagnostic 2 Cote-t Nom t-stat Amt_purch 1,7283 First_purch -0,7318
Frequency 6,3647 Last_purch -6,2699 Gender -7,4511 P_Art 5,3532 P_Child -7,0268 P_Cook -7,797 P_DIY -6,3718 P_Youth -4,5357

20
Diagnostic 3 Hit rate & Choice Share Number of hits = 1289
Number of observations = 1600 The hit rate of the model = Choice Share (Market Share) Forecasts: Response Dummy % %
 Forecasts: Response Dummy % %")
21
Résumé Facteurs (+) (-) Régression linéaire multiple P_Art
First_ Purch P_DIY P_Cook Neural net forecasting Last_Purch Frequency Multinomial logit analysis Gender

22
Conclusions La variable « nombre de livre d’art acheté » influence significativement et positivement le choix selon les 3 modèles; L’entreprise devrait inévitablement cibler ces consommateurs; La variable « nombre de livre de recettes acheté » influence négativement le choix selon les 3 modèles; L’entreprise ne devrait donc pas cibler ces consommateurs;

23
Conclusions (suite) Le modèle le plus fiable semble être le « Multinomial logit analysis »; Selon ce modèle, en plus des consommateurs ayant achetés des livres d’art, l’entreprise devrait également miser sur ceux qui on fait beaucoup d’achats (frequency) dans la période donnée; Aussi, en plus des consommateurs ayant acheté des livres de recettes, l’entreprise ne devrait pas cibler en fonction du sexe (gender).
 dans la période donnée; Aussi, en plus des consommateurs ayant acheté des livres de recettes, l’entreprise ne devrait pas cibler en fonction du sexe (gender).")
24
Avantages et limites Régression linéaire multiple
On ne peut pas utiliser de variables binaires Neural network model (17,79 %) Avantages On peut faire des prédictions sans connaître le type de relation entre les variables Offre des fits et des prédictions plus robustes que la régression linéaire multiple lorsqu’il y a des données manquantes N’explique pas en détail les prédictions Nouvelle méthode donc peu d’information est disponible sur le modèle et son fonctionnement La performance dépend de plusieurs facteurs Multinomial logit analysis ( 80,56 %) Offre beaucoup plus d’informations
 Avantages. On peut faire des prédictions sans connaître le type de relation entre les variables. Offre des fits et des prédictions plus robustes que la régression linéaire multiple lorsqu’il y a des données manquantes. N’explique pas en détail les prédictions. Nouvelle méthode donc peu d’information est disponible sur le modèle et son fonctionnement. La performance dépend de plusieurs facteurs. Multinomial logit analysis ( 80,56 %) Offre beaucoup plus d’informations.")
25
Questions ? ?

Présentations similaires









.>")









 Section 3 Tests dhypothèses et lhypothèse linéaire générale Version: 26 janvier 2007.>")