Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Introduction au datamining
Système d’information décisionnel DESS ACSI et SID Anne Boyer Année universitaire

2
Plan Introduction 1.Généralités 2. Le processus de datamining
3. Les modèles du datamining 4. Exemples 5. Critères pour le choix d’un logiciel Conclusion et perspectives

3
Environnement de l'entreprise
Accroissement de la concurrence Individualisation des consommateurs Brièveté du cycle de vie des produits Anticiper le marché et pas seulement réagir Cibler au mieux la clientèle pour répondre à ses attentes Connaissance du métier, des schémas de comportement des clients et des fournisseurs

4
Un constat La grande distribution a besoin d'apprendre à connaître se clients Créer des relations privilégiées sur le modèle du commerce de quartier Idéal du "1 à 1" Apprendre à évaluer un client dans la durée Déterminer lequel fidéliser par des attentions particulières et lequel laisser partir à la concurrence Déplacement des centres d'intérêt des segments de marché vers les individus Petit commerce : Observe un client, se souvient de ses préférences Apprend des contacts passés comment améliorer le service futur Introduction

5
Objectif Faire la même chose avec une entreprise de grande taille
le client peut ne jamais entrer en contact avec un employé le client voit chaque fois un employé différent Exploiter les nombreuses traces enregistrées lors de l'observation du client (enregistrements transactionnels) Introduction
 Introduction.")
6
Un potentiel Une solution : le datamining
A disposition une masse importante de données Explorer ses réservoirs de connaissances Extraction de connaissances Données provenant de nombreuses sources À rassembler et à organiser selon un plan cohérent et exploitable À analyser, comprendre et transformer en informations exploitables Une solution : le datamining

7
Extrapoler le passé pour prédire l’avenir
Intérêt du DM "Trop de données tue l’information" seuls 15% des données stockées sont analysées + 150% d’info disponibles chaque année Objectif : favoriser la prise de décision en exploitant les tonnes d’information disponibles modéliser pour prédire faciliter la décision mais ne prend pas de décision améliorer la réactivité d’une entreprise / marché Défi : améliorer la productivité / volume exponentiel de données Extrapoler le passé pour prédire l’avenir Introduction

8
Découverte de connaissances dans les bases de données
Intérêt scientifique Processus d’aide à la décision où les utilisateurs cherchent des modèles d’interprétation dans les données Extraction d’informations auparavant inconnues et potentiellement utiles à partir des données disponibles Intérêt économique Amélioration de la qualité des produits et des services Passage d’un marketing de masse à un marketing individualisé Fidélisation des clients Favoriser la différentiation stratégique de l’entreprise Introduction

9
Datamining Ensemble des outils permettant d'accéder et d'analyser les données de l'entreprise moyens destinés à détecter les associations entre des données contenues dans d’importantes bases de données Outil qui facilite la mise en évidence de modèles ou de règles à partir de l’observation des données Démarche ayant pour objet de découvrir des relations et des faits à la fois nouveaux et significatifs sur de grands ensembles de données Un élément de la transformation de données en connaissances Introduction

10
Datamining Restriction aux outils permettant de générer des infos riches, de découvrir des modèles implicites à partir de données historiques Pertinence et intérêt conditionnées par les enjeux de l'entreprise Idées et techniques provenant des statistiques, de la RO, de l'IA, de l'administration de bases de données, du marketing

11
Connaissance versus donnée
Données Connaissances Donnée : description d’un exemple ou d’un événement spécifique dont l’exactitude peut être vérifiée par rapport au monde réel ex : les achats d’un client sur son ticket de caisse Connaissance : ensemble de relations entre les données Règles, Tendances, Associations, Exceptions, … Décrit une catégorie abstraite pouvant couvrir plusieurs exemples Ex : les bons et les mauvais clients Connaissances synthèse des informations (DM) Introduction
 Introduction.")
12
DM versus autres solutions
Outils relationnels et OLAP Initiative à l'utilisateur DM Initiative au système Pas nécessaire de poser d'hypothèses Interprétation par un expert Nécessité d'un outil ergonomique rendant transparentes les techniques utilisées

13
Datamining et Décisionnel : une solution
Archivage de données crée la mémoire d'entreprise Datamining crée l'intelligence de l'entreprise Analyse prédictive de comportement Généralisation prédictive : communauté Automatisation de certaines phases de l’analyse Rendre les utilisateurs moins dépendants des spécialistes de l’analyse de données Intégrer les résultats du DM dans l’informatique ou les procédures de l’entreprise Introduction

14
Etat des lieux Les algorithmes existent (depuis des années voire des décennies) Les données sont produites Nécessité de grands volumes pour l'apprentissage Les données sont archivées La puissance de calcul nécessaire est disponible et financièrement abordable Le contexte est ultra concurrentiels Motivation commerciale Des produits commerciaux pour le DM existent Introduction

15
Contexte ultra concurrentiel
Renforcement du rôle des informations dans la concurrence Économie de plus en plus tournée vers les services Vente de voitures ou de solutions de transports ? Compagnies aériennes en concurrence par les services offerts Apparition de la personnalisation massive Levi-Strauss et ses jeans personnalisés Peugeot et la voiture à la demande Individual et la revue de presse qui s'améliore avec le temps Importance croissante de l'information comme produit Courtiers en information IMS Journal de l'IOWA Introduction

16
Domaines d'application
Grande distribution, vente par correspondance ou commerce électronique Banques, assurance Transports et voyagistes Télécommunications, eau et énergie Aéronautiques, automobiles, industrie Laboratoires pharmaceutiques Retours sur investissement Introduction

17
Exemples La police américaine
Poseur de bombe d'Oklahoma City (par ex) DM pour filtrer les milliers de rapports soumis par les agents du FBI Le département du Trésor américain pour traquer les formes suspectes dans les transferts de fonds internationaux Les impôts américains (acheteurs d'outils de DM) Les supermarchés Collecte d'infos par le biais de la carte de fidélité Utilisation de la carte pour payer ou obtenir des "points" déterminer l'agencement des rayons, … Vente aux marques pour les bons de réduction à adresser à 1 client Introduction
 DM pour filtrer les milliers de rapports soumis par les agents du FBI. Le département du Trésor américain pour traquer les formes suspectes dans les transferts de fonds internationaux. Les impôts américains (acheteurs d outils de DM) Les supermarchés. Collecte d infos par le biais de la carte de fidélité. Utilisation de la carte pour payer ou obtenir des points déterminer l agencement des rayons, … Vente aux marques pour les bons de réduction à adresser à 1 client. Introduction.")
18
Exemples La banque (les premiers) La vente croisée
les cartes de crédit Aux USA, prédire les changements de cille (et de banque ?) La vente croisée Assurance USAA Compagnie d'investissement Fidelity Marketing direct guidé par l'analyse de comportement Portrait robot du client fidèle Routage des réclamations en période de garantie Fabricant de moteurs diesel Fidélisation des bons clients Compagnie du gaz de Californie du sud à la fin du monopole Eliminer les mauvais clients Introduction
 La vente croisée. Assurance USAA. Compagnie d investissement Fidelity. Marketing direct guidé par l analyse de comportement. Portrait robot du client fidèle. Routage des réclamations en période de garantie. Fabricant de moteurs diesel. Fidélisation des bons clients. Compagnie du gaz de Californie du sud à la fin du monopole. Eliminer les mauvais clients. Introduction.")
19
Plan Introduction 1.Généralités 2. Le processus de datamining
3. Les modèles du datamining 4. Exemples 5. Critères pour le choix d’un logiciel Conclusion et perspectives

20
Exemple d'une grande banque
Constat : Perte de clients supérieure aux nouveaux clients Nouveaux clients rapportent moins que les clients partis les meilleurs clients s'en vont Objectif : augmenter la rentabilité globale Garder les parts de marché Trouver de nouveaux clients (à faible coût)
")
21
Solutions Relever les taux d'épargne, diminuer les taux d'emprunt, …
Inutile pour les clients fidèles Attraction des clients volages solution chère Suppression de services non rentables Mais si ce sont ceux qui fidélisent la clientèle ? Comprendre les clients et appliquer le modèle trouvé Utiliser les données disponibles Les transformer en informations exploitables

22
Le problème Départ de clients rentables affecte le résultat financier
Comment identifier les clients pouvant partir ? Enquête auprès d'anciens clients Échantillon représentatif ? Coopératif ? Réponses honnêtes ? Une ou plusieurs raisons ? Analyse des infos sur les anciens clients et comparaison avec les clients restants Détermination de clusters Transformation des résultats de l'analyse en action Mesure des résultats

23
Les grandes étapes Identifier l'opportunité commerciale
Ex : planification d'actions marketing, établissement de prix de produits ou de services, définition des cibles marketing, explication de pertes de clientèles,… La longueur d'attente aux caisses est elle une raison probable de la perte de clients ? Transformer les données concrètes en informations permettant des actions collectes Utilisation des techniques du DM Agir Mesurer les résultats

24
Les tâches du DM Classification (affectation à une classe prédéfinie)
Estimation Prédiction Groupement par similitudes Analyse des clusters (détermination de classes) Description
 Description.")
25
Classification “La classification consiste à examiner des caractéristiques d’un élément nouvellement présenté afin de l’affecter à une classe d’un ensemble prédéfini. ” [BERRY97] Objectif : affecter des individus à des classes classes discrètes : homme / femme, oui / non, ... exemple de techniques appropriées : Ä les arbres de décision

26
Estimation permet intérêt exemple de techniques appropriées :
obtenir une variable continue en combinant les données en entrée procéder aux classifications grâce à un "barème" Exemple : estimer le revenu d’un ménage selon divers critères ensuite possible de définir des tranches de revenus pour classifier les individus intérêt pouvoir ordonner les résultats pour ne retenir si on le désire que les n meilleures valeurs facile de mesurer la position d’un élément estimé dans sa classe particulièrement important pour les cas limitrophes exemple de techniques appropriées : les réseaux de neurones

27
Prédiction ressemble à la classification et à l’estimation mais dans une échelle temporelle différente s’appuie sur le passé et le présent mais son résultat se situe dans un futur généralement précisé meilleure méthode pour mesurer la qualité de la prédiction : attendre ! exemple de techniques appropriées : L’analyse du panier de la ménagère Les arbres de décision les réseaux de neurones

28
Regroupement par similitudes
consiste à grouper les éléments qui vont naturellement ensembles exemple de techniques appropriées : L’analyse du panier de la ménagère

29
Clusterisation segmenter une population hétérogène en sous-populations homogènes Contrairement à la classification, les sous populations ne sont pas préétablies exemple de techniques appropriées : Les K means

30
Description décrire les données d’une base complexe
engendre souvent une exploitation supplémentaire en vue de fournir des explications exemple de techniques appropriées : L’analyse du panier de la ménagère

31
La classification Déterminer le grade en fonction du sexe, de l'âge, l'ancienneté, le salaire et les affectations Déterminer le sexe en fonction de l'âge, l'ancienneté, le salaire et les affectations L’estimation se fait sur des variables continues Estimer l'âge en fonction du grade, sexe, ancienneté et affectations le salaire en fonction de l'âge, sexe, ancienneté et affectations La prédiction quelle sera la prochaine affectation d'un militaire

32
Le regroupement par similitudes
déterminer des règles de type : le militaire qui est sergent entre 25 et 30 ans sera lieutenant colonel entre 45 et 50 ans (fiabilité de n %) La segmentation segmenter les militaires en fonction de leurs suivi de la carrière et affectations La description indicateurs statistiques traditionnels : âge moyen, %femmes, salaire moyen
 La segmentation. segmenter les militaires en fonction de leurs suivi de la carrière et affectations. La description. indicateurs statistiques traditionnels : âge moyen, %femmes, salaire moyen.")
33
Deux démarches Test d'hypothèses La découverte de connaissances
Générer une idée Déterminer les données permettant de la tester Localiser les données Préparer les données pour l'analyse Construire les modèles informatiques sur la base de données Évaluer les modèles informatiques La découverte de connaissances Dirigée (expliquer une relation) ou non (reconnaître une relation)
 ou non (reconnaître une relation)")
34
Plan Introduction 1.Généralités 2. Le processus de datamining
3. Les modèles du datamining 4. Exemples 5. Critères pour le choix d’un logiciel Conclusion et perspectives

35
Gestion des connaissances
Statistiques et datamining ? Compréhension du domaine Utilisation de la connaissance Identification de relations Enrichissement des variables Qualification des données Sélection des données Données sources cibles validées transformées Information découverte Information exploitée Introduction

36
Les étapes du processus Knowledge Discovery
Phase 1 : Poser le problème Phase 2 : La recherche des données Phase 3 : La sélection des données pertinentes Phase 4 : Le nettoyage des données Phase 5 : Les actions sur les variables Phase 6 : La recherche du modèle Phase 7 : L’évaluation du résultat Phase 8 : L’intégration de la connaissance extraite Le processus de datamining

37
(1) Poser le problème Quel est le problème ?
Formulation du problème Recherche des objectifs et recueil de la connaissance existante Typologie du problème : recherche des objectifs Explication d’un phénomène précis ? ou approche exploratoire ? Influence sur les modèles ou techniques à utiliser Résultat attendu et moyens mis en œuvre pour le mesurer Exploitation des résultats (impacts sur l’organisation) Individus concernés Le processus de datamining
 Individus concernés. Le processus de datamining.")
38
(2) Recherche des données
Quelles données extraire ? Identifier les variables Rendre le processus de découverte performant et efficace Réduction des dimensions Trop de variables nuit à la capacité de généralisation Ratio : Nombres d’exemplaires / Nombre de variables - Nbre d’exemples + - Nbre de variables + multiplication des apprentissages zone optimale temps de calcul long trop peu d’exemples Le processus de datamining

39
(2) Recherche des données
Sélection des variables Fournies par les experts (explication d’un phénomène précis) Recherche des facteurs déterminants par des techniques d’analyse (méthode de régression, réseaux neuronaux...) DM à l’intérieur du DM Mise en évidence : des associations triviales entre les données de la sémantique, des regroupements de valeurs des valeurs de seuil des valeurs aberrantes Eliminer les résultats triviaux et améliorer la prédiction Le processus de datamining
 Recherche des facteurs déterminants par des techniques d’analyse (méthode de régression, réseaux neuronaux...) DM à l’intérieur du DM. Mise en évidence : des associations triviales entre les données. de la sémantique, des regroupements de valeurs. des valeurs de seuil. des valeurs aberrantes. Eliminer les résultats triviaux et améliorer la prédiction. Le processus de datamining.")
40
(3) Sélection des données pertinentes
Comment extraire ces données ? Réaliser un plan d’extraction des données Constituer un fichier à plat Identifier les applications ou systèmes concernés Phase importante + ou - facilitée par l’existence d’entrepôts de données Certaines études nécessitent un plan de collecte (étude qualitative, interception de données transitoires) Avenir : flux continu de données depuis les systèmes transactionnels et traitement immédiat du processus de DM Le processus de datamining
 Avenir : flux continu de données depuis les systèmes transactionnels et traitement immédiat du processus de DM. Le processus de datamining.")
41
(3) Sélection des données pertinentes
Exhaustivité ou non des données ? Echantillon ? Dépend des modèles utilisés Fonction des objectifs de l’étude (Phase 1) Equilibre entre les différentes classes d’individus à appréhender Stratification si une faible population a des enjeux forts Pondérations des individus Le processus de datamining
 Equilibre entre les différentes classes d’individus à appréhender. Stratification si une faible population a des enjeux forts. Pondérations des individus. Le processus de datamining.")
42
(4) Nettoyage des données
La qualité des données extraites ? Identifier les valeurs aberrantes (histogramme, ctrl de cohérence à la saisie des données, outils de visualisation graphique) Quantifier les valeurs manquantes (exclusion des enregistrements incomplets, remplacement par une valeur) les valeurs nulles Le processus de datamining
 Quantifier. les valeurs manquantes (exclusion des enregistrements incomplets, remplacement par une valeur) les valeurs nulles. Le processus de datamining.")
43
(4) Nettoyage des données
Prévenir de la non-qualité des données Intégration de bruit : équilibrer la proportion des données erronées par rapport à l’ensemble extrait Utiliser les modèles adaptés en fonction du diagnostic : processus d’apprentissage «flous», introduction de probabilité Revoir le processus d'extraction ou la saisie des données dans les systèmes initiaux Le processus de datamining

44
(5) Actions sur les variables
Quelles transformations opérées sur les données ? Transformer les données en fonction de la nature des données extraites et des modèles qui seront utilisés Exemple de transformation mono-variable : Modification de l’unité de mesure (normalisation, log()) cas de données numériques Transformation des dates en durée Modification des données géographiques (géocodage) Création de taxonomie de concepts Le processus de datamining
) cas de données numériques. Transformation des dates en durée. Modification des données géographiques (géocodage) Création de taxonomie de concepts. Le processus de datamining.")
45
(5) Actions sur les variables
Exemple de transformation multi-variables Construction d’agrégats de variables Ratios (degré d’implication) Fréquences (mesurer la répétitivité) Tendances (évolution des échanges dans le temps - équations linéaires ou non) Combinaisons linéaires (construction d’indicateurs) Combinaisons non linéaires Le processus de datamining
 Fréquences (mesurer la répétitivité) Tendances (évolution des échanges dans le temps - équations linéaires ou non) Combinaisons linéaires (construction d’indicateurs) Combinaisons non linéaires. Le processus de datamining.")
46
(6) Recherche du modèle Quel modèle découvrir ?
Quel type de techniques ? Supervisé (interactivité, connaissance des algorithmes) Non supervisé (automatisé) Fonction des phases précédentes (qualité des données, objectif,…) Algorithme de calcul pouvoir prédictif du modèle Utilisation des méthodes statistiques + nouveaux outils de type inductif, Bayésiens, neuronaux Le processus de datamining
 Non supervisé (automatisé) Fonction des phases précédentes (qualité des données, objectif,…) Algorithme de calcul pouvoir prédictif du modèle. Utilisation des méthodes statistiques + nouveaux outils de type inductif, Bayésiens, neuronaux. Le processus de datamining.")
47
(6) Recherche du modèle Pour la recherche du modèle :
2 bases de travail base d’apprentissage (80% de la population) pour la découverte d’un modèle base de test (20% de la population) pour évaluer le modèle découvert Le processus de datamining
 pour la découverte d’un modèle. base de test (20% de la population) pour évaluer le modèle découvert. Le processus de datamining.")
48
(7) Évaluation du résultat
Évaluation qualitative Restitution de la connaissance sous forme graphique ou sous une forme interprétable Évaluation quantitative Notion d’intervalle de confiance (indicateurs pour la pertinence des règles, seuil de confiance et intervalle de confiance fonction de la taille de l’échantillon) Validation par le test (base de test) matrice de confusion / éclairage métier Le processus de datamining
 Validation par le test (base de test) matrice de confusion / éclairage métier. Le processus de datamining.")
49
(7) Évaluation du résultat
Évaluation quantitative - Matrice de confusion Achats constatés Oui Non Total Oui 270 160 430 Achats Prédits Non 30 540 570 Total 300 700 1000 Qualité globale du modèle : / 1000 (81%) Forte capacité des non-acheteurs : 540 / 570 (94%) Acheteurs : 270/430 (63%) 160 prospects à contacter Le processus de datamining
 Forte capacité des non-acheteurs : 540 / 570 (94%) Acheteurs : 270/430 (63%) 160 prospects à contacter. Le processus de datamining.")
50
(8) Intégration de la connaissance
Conversion de la connaissance découverte en décision & action Implanter le modèle ou ses résultats dans les systèmes informatiques ou dans le processus de l’entreprise Bilan des étapes précédentes : faible qualité des données collectées Þ revoir le processus d’alimentation du data warehouse détection d’une donnée de fort pouvoir prédictif Þ modification de la BD agrégats construits constituant des dimension intéressantes Þ extension des tableaux de bord connaissance extraite en contradiction avec la connaissance existante Þ mesure de communication Le processus de datamining

51
Processus d’extraction - Conclusion
Rôle primordial des utilisateurs et des experts Sémantique donnée aux données (méta-données) Orientation du processus d’extraction Valider ou infirmer les conclusions Logiciels de DM orientés recherche de modèle Une partie du processus Tendance : intégration de fonctions d’aide à tous les stades du processus Après le processus : la diffusion et l’intégration de la connaissance Le processus de datamining
 Orientation du processus d’extraction. Valider ou infirmer les conclusions. Logiciels de DM orientés recherche de modèle. Une partie du processus. Tendance : intégration de fonctions d’aide à tous les stades du processus. Après le processus : la diffusion et l’intégration de la connaissance. Le processus de datamining.")
52
Plan Introduction 1.Généralités 2. Le processus de datamining
3. Les modèles du datamining 4. Exemples 5. Critères pour le choix d’un logiciel Conclusion et perspectives

53
Data Mining : Cocktail de techniques
Évolution des techniques de statistique + apports des SGBD, de l’IA et de l’apprentissage automatique Mélange de plusieurs disciplines degré de transformation des données implication de l’utilisateur dans le processus performance et lisibilité du modèle ML SGBD Représentation de la Connaissance Les modèles du datamining

54
Data Mining : Utilisateur ou Statisticien
Logiciel Presse-Bouton (apprentissage automatique non supervisé) Interaction avec l’utilisateur au niveau de l’apprentissage (paramètre) ou pendant la recherche du modèle Logiciel basé sur des techniques statistiques : experts requis Þ les outils de DM intègrent des tests statistiques et des algorithmes de choix des meilleures techniques de modélisation en fonction des caractéristiques du cas Les modèles du datamining
 Interaction avec l’utilisateur au niveau de l’apprentissage (paramètre) ou pendant la recherche du modèle. Logiciel basé sur des techniques statistiques : experts requis. Þ les outils de DM intègrent des tests statistiques et des algorithmes de choix des meilleures techniques de modélisation en fonction des caractéristiques du cas. Les modèles du datamining.")
55
Data Mining : Lisibilité ou Puissance
Compromis entre clarté du modèle et pouvoir prédictif Lisibilités des résultats + Pouvoir de prédiction - réseaux neuronaux algorithmes génétiques réseaux bayésiens scores régression cluster arbres de décision analyse d’association RBC Compétences Les modèles du datamining

56
Quelques techniques Associations Raisonnement à partir de cas K means
Arbres de décision Réseaux neuronaux Algorithmes génétiques Réseaux Bayésiens Les modèles du datamining

57
Recherche d'associations ou analyse du panier de la ménagère
processus de découverte de connaissances non dirigée étudier quels articles ont tendance à être achetés ensemble issue du secteur de la distribution applicable dès que plusieurs actions faites par un même individu utilisée pour découvrir des règles d'association but principal descriptif prédictive car résultats éventuellement situés dans le temps souvent départ d'une analyse règles claires et explicites pour l'utilisateur métier ensuite mise en œuvre d'un processus de test d'hypothèses ou de découverte dirigée

58
Les Associations Exemples de règles :
Construire un modèle basé sur des règles conditionnelles à partir d’un fichier de données Le modèle : Règles de la forme : Si prédicat(x) et prédicat(y)… alors prédicat(z) Pondération par une probabilité ou par une métrique de confiance Éventuellement situées dans le temps : "Si action1 ou condition à l'instant t1 alors action2 à l'instant t2" Exemples de règles : Si achat de riz et de vin blanc, alors achat de poisson (84%) Si achat de téléviseur alors achat de magnétoscope dans les 5 ans (45%) Si présence et travail alors réussite à l'examen (99,9%) Les modèles du datamining
 et prédicat(y)… alors prédicat(z) Pondération par une probabilité ou par une métrique de confiance. Éventuellement situées dans le temps : Si action1 ou condition à l instant t1 alors action2 à l instant t2 Exemples de règles : Si achat de riz et de vin blanc, alors achat de poisson (84%) Si achat de téléviseur alors achat de magnétoscope dans les 5 ans (45%) Si présence et travail alors réussite à l examen (99,9%) Les modèles du datamining.")
59
Les Associations Les domaines : Les enjeux :
Analyse des tickets de caisse (mise en relation entre n produits, relation de comportement de produits) Analyse des séquences d’achats détection d’association de ventes pour un même client Þ dimension temporelle et notion d’antériorité Les enjeux : optimisation des stocks, merchandising, ventes croisées (bon de réduction, promotion) Les modèles du datamining
 Analyse des séquences d’achats. détection d’association de ventes pour un même client. Þ dimension temporelle et notion d’antériorité. Les enjeux : optimisation des stocks, merchandising, ventes croisées (bon de réduction, promotion) Les modèles du datamining.")
60
Les Associations Principes de construction d’une association
transaction Û ticket de caisse une transaction T contient le détail des articles ou de leur famille chaque article est une variable binaire une association est une implication de la forme X ® Y avec : X et Y Î T et X ÇY = Æ deux indicateurs pour apprécier une association : niveau de confiance : Card(X ® Y) / Card(X) niveau de support : Card(X ® Y) / Card(X ou Y) extraire les associations pertinentes Les modèles du datamining
 / Card(X) niveau de support : Card(X ® Y) / Card(X ou Y) extraire les associations pertinentes. Les modèles du datamining.")
61
Les Associations Les modèles du datamining

62
Les Associations Les modèles du datamining

63
Les Associations Domaines d’application Limites de l’approche
Analyse d’achats dans la grande distribution Analyse des mouvements bancaires, des incidents dans les assurances Limites de l’approche article = code à barres & une famille = 100 références volume de données ( réf. élémentaires) Þ hiérarchie de concepts niveau élémentaire pour confirmer l’impact de marque X sur les ventes de Y Þ vérifier les associations sur des concepts de haut niveau Les modèles du datamining
 Þ hiérarchie de concepts. niveau élémentaire pour confirmer l’impact de marque X sur les ventes de Y. Þ vérifier les associations sur des concepts de haut niveau. Les modèles du datamining.")
64
Mise en oeuvre LA TAXINOMIE
Un supermarché gère environ 100 000 références différentes analyse sur tous les articles : tableau de 10 milliards de cellules pour des associations de deux articles ! des espaces disques importants (en téra‑octets) des temps de traitements en conséquence aujourd'hui pas très raisonnable Solution : la taxinomie regrouper les articles, les généraliser sous un même terme générique, une même rubrique Exemple : le terme chocolat regroupe les chocolats noirs, au lait, de différentes marques, aux noisettes, allégés, …
 des temps de traitements en conséquence. aujourd hui pas très raisonnable. Solution : la taxinomie. regrouper les articles, les généraliser sous un même terme générique, une même rubrique. Exemple : le terme chocolat regroupe les chocolats noirs, au lait, de différentes marques, aux noisettes, allégés, …")
65
Mise en oeuvre LES ARTICLES VIRTUELS
fréquent de rajouter des articles virtuels pour améliorer la performance du système pour représenter des informations transversales pour regrouper les articles d'une autre manière que la taxinomie Exemple : produits allégés, marque que l'on trouve dans plusieurs rubriques pour donner des indications supplémentaires sur la transaction donnée temporelle (jour de la semaine, heure, mois, saison, …), mode de paiement, météo, … si possible des données sur le client (satisfaction, type d'habitat, catégorie socioprofessionnelle, âge, statut matrimonial, …) pour fournir des règles du type : "si printemps et jardin alors achat de gants de jardinage"
, mode de paiement, météo, … si possible des données sur le client (satisfaction, type d habitat, catégorie socioprofessionnelle, âge, statut matrimonial, …) pour fournir des règles du type : si printemps et jardin alors achat de gants de jardinage")
66
Mise en oeuvre LES REGLES DE DISSOCIATION
analogue à une règle d'association mais fait apparaître la notion de "non" dans une entreprise, 5 produits (A,B,C,D,E) Si un client prend les produits A,B et D, alors il générera la transaction {A,B,non C,D et non E} Ce procédé génère des règles comme : "si achat du produit A et du produit C alors non achat du produit E". inconvénient majeur : fournit des règles où tout est nié "si non A et non B alors non C" connaissances générées peu exploitables
 Si un client prend les produits A,B et D, alors il générera la transaction {A,B,non C,D et non E} Ce procédé génère des règles comme : si achat du produit A et du produit C alors non achat du produit E . inconvénient majeur : fournit des règles où tout est nié. si non A et non B alors non C connaissances générées peu exploitables.")
67
Mise en oeuvre Le LES SERIES TEMPORELLES
L'analyse du panier de la ménagère Objectif : faire de la description et non de la prévision outil non optimal pour étudier les séries temporelles contrainte : avoir une information de temps et une clé d'identification de l'objet (principalement le client) difficulté : transformer les données en transactions Plusieurs possibilités offertes : Ajouter à chaque article la notion de temps : avant, après, en même temps Créer des fenêtres temporelles : regrouper toutes les transactions effectuées dans un même intervalle de temps par un même individu permet de dégager des profils, surtout associée à des articles virtuels
 difficulté : transformer les données en transactions. Plusieurs possibilités offertes : Ajouter à chaque article la notion de temps : avant, après, en même temps. Créer des fenêtres temporelles : regrouper toutes les transactions effectuées dans un même intervalle de temps par un même individu. permet de dégager des profils, surtout associée à des articles virtuels.")
68
Mise en oeuvre plusieurs indicateurs complémentaires pour évaluer
La fréquence règle vraie pour deux clients sur cinq : fréquence 40% Le niveau (ou taux) de confiance mesure de la probabilité dans la sous population concernée par la condition de la règle (fréquence sur une sous population) Ex : règle "si achat de jus d'orange, alors achat d'eau minérale" la population ayant acheté du jus d'orange (ex : 4 individus) le nombre de fois où la règle est respectée (ex : 2) La proportion obtenue (ici 2 sur 4, soit 50 %) : niveau de confiance permet de mesurer la force de l'association Prudence : n'intègre pas la notion d'effectif Ex : Si achat de lait, alors achat de nettoyant vitres effectif 1 individu : très relatif malgré un très bon taux de confiance !
 de confiance. mesure de la probabilité dans la sous population concernée par la condition de la règle (fréquence sur une sous population) Ex : règle si achat de jus d orange, alors achat d eau minérale la population ayant acheté du jus d orange (ex : 4 individus) le nombre de fois où la règle est respectée (ex : 2) La proportion obtenue (ici 2 sur 4, soit 50 %) : niveau de confiance. permet de mesurer la force de l association. Prudence : n intègre pas la notion d effectif Ex : Si achat de lait, alors achat de nettoyant vitres effectif 1 individu : très relatif malgré un très bon taux de confiance !")
69
Le taux d'amélioration LE NIVEAU DE SUPPORT
nombre de fois où l'association est respectée, ramenée au nombre de fois où l'un des articles est présent permet de mesurer la fréquence de l'association. Le taux d'amélioration permet de mesurer la pertinence de l'association Que vaut une règle si son taux de confiance est inférieur à la fréquence du résultat sans condition ? ex règle : "si achat d'eau minérale, alors achat de jus d'orange" règle vraie pour 2 clients sur 3 qui ont acheté de l'eau taux de confiance pour l'achat du jus d'orange dans ces conditions : de 2/3 Or 4 clients sur 5 achètent du jus d'orange, soit 80% ! règle inintéressante à exploiter car ajout de condition pour un taux moins bon Pour mesurer l'amélioration apportée par la règle, on divise le taux de confiance par la fréquence de l'événement ici : 0.66 / 0.80 = 83 % Si le résultat est supérieur à 1, la règle apporte une amélioration sur le résultat sinon renoncer à l'exploiter

70
Conclusion points forts de l'analyse du panier de la ménagère :
résultats clairs et explicites adaptée à l'exploitation non dirigée des données traite des données de taille variable La technique et les calculs simples à comprendre points faibles de l'analyse du panier de la ménagère : Le volume de calculs croît au carré ou au cube du volume de données prend mal en compte les articles rares difficile de déterminer le bon nombre d'articles les attributs des articles (détails et quantités) souvent ignorés
 souvent ignorés.")
71
Conclusion technique s'appliquant aux problèmes
d'exploitation des données non dirigée contenant des articles bien définis, qui se regroupent entre eux de manière intéressante souvent analyse préalable car elle génère des règles susceptibles de soulever des interrogations ou des idées débouchera sur d'autres analyses plus fines : test d'hypothèse ou découverte de connaissance dirigée pour expliquer un phénomène révélé

72
Le raisonnement à partir de cas
technique de découverte de connaissances dirigée utilisée dans un but de classification et de prédiction bien adapté aux bases de données relationnelles mise en œuvre simple équivalence de l'expérience chez l'homme processus : identification des cas similaires puis application de l'information provenant de ces cas au problème actuel principe : on présente un nouvel enregistrement, il trouve les voisins les plus proches et positionne ce nouvel élément s'applique à tous les types de données. pour estimer des éléments manquants, détecter des fraudes, prédire l'intérêt d'un client pour une offre, classifier les réponses en texte libre

73
Véhicule Age Enfants Clio 25 27 1 Espace 32 4 Megane 30 2 28 Laguna 39 Safrane 55 50 24 35 33 40 3 38 22 34 52 54 5 ventes de voitures Renault ventilées en fonction de l'âge et du nombre d'enfants de l'acheteur

75
La consultation du graphique
des zones bien nettes permettant de déterminer, pour un nouveau client dont on connaît l'âge et le nombre d'enfants, le modèle susceptible de l'intéresser. trois nouveaux clients La notion de distance est la distance métrique conseil au client 1 une Espace, au 2 une Clio, au 3 une Safrane 1 3 2

76
Fonction de distance Pour les données numériques
La valeur absolue de la différence : |A-B| Le carré de la différence : (A-B)² La valeur absolue normalisée : |A-B| / (différence maximale) avantage : se trouve toujours entre 0 et 1, supprime les problèmes d'échelles libre de créer sa propre fonction. Pour les autres types de données à l'utilisateur de définir sa propre fonction de distance Exemple : pour comparer le sexe d'un individu, valeur 1 s'ils sont de sexe différent ou la valeur 0 s'ils sont identiques pour des communes, pourquoi ne pas prendre la distance entre elles ou affecter une codification en fonction du type (urbaine, périurbaine, rurale) ou de la région toujours préférable d'avoir le résultat entre 0 et 1
². La valeur absolue normalisée : |A-B| / (différence maximale) avantage : se trouve toujours entre 0 et 1, supprime les problèmes d échelles. libre de créer sa propre fonction. Pour les autres types de données. à l utilisateur de définir sa propre fonction de distance. Exemple : pour comparer le sexe d un individu, valeur 1 s ils sont de sexe différent ou la valeur 0 s ils sont identiques. pour des communes, pourquoi ne pas prendre la distance entre elles ou affecter une codification en fonction du type (urbaine, périurbaine, rurale) ou de la région. toujours préférable d avoir le résultat entre 0 et 1.")
77
Fonction de combinaison
consiste à combiner les n voisins les plus proches pour obtenir le résultat de la prédiction souhaitée exemple : soit une liste de clients ayant déjà répondu à une offre commerciale (par oui ou non) l'utilisateur métier estime que les critères les plus déterminants sont le sexe, l'âge et le salaire net du dernier semestre
 l utilisateur métier estime que les critères les plus déterminants sont le sexe, l âge et le salaire net du dernier semestre.")
78
Numéro Age Sexe Salaire Acheteur A 27 F 19000 Non B 51 M 66000 Oui C 52 105000 D 33 55000 E 45 45000

79
cette cliente sera-t-elle intéressée par l'offre ?
soit un nouveau client : une femme de 45 ans ayant un revenu de Francs cette cliente sera-t-elle intéressée par l'offre ? La fonction de distance est définie ainsi : il s'agit d'une femme, donc la distance par rapport aux clients connus sera de 1 avec les hommes et de 0 avec les femmes A ce chiffre, on ajoute la distance normalisée du salaire et de l'âge Tableau des distances : Les voisins les plus proches sont dans l'ordre : D C B E A Client Age Sexe Salaire Distance totale A 0.720 0.942 1.662 B 0.240 1 0.395 1.635 C 0.280 0.058 1.338 D 0.480 0.523 1.003 E 0.000 0.640 1.640

80
Utilisons maintenant la fonction de combinaison
nombre de voisins retenus ? Nombre de voisins retenus 1 2 3 4 5 Numéro des voisins D DC DCB DCBE DCBEA Réponses des voisins O O,N O,N,O O,N,O,O O,N,O,O,N Décompte des réponses Oui 1 Non 0 Non 1 Oui 2 Oui 3 Non 2 Valeur retenue Oui ? Evaluation 100 % 50 % 66 % 75 % 60 % Si 3 voisins, réponse favorable avec une probabilité (plutôt espérance) de 66% possible également de donner un poids à chaque contribution Ex: 1er voisin a un poids de 3, 2ème poids de 2, 3ème un poids de 1 Possible de pondérer chaque variable utilisée dans la fonction de distance
 de 66% possible également de donner un poids à chaque contribution. Ex: 1er voisin a un poids de 3, 2ème poids de 2, 3ème un poids de 1. Possible de pondérer chaque variable utilisée dans la fonction de distance.")
81
Quelques remarques Complexité en fonction de la taille de la base de cas Technique d'optimisation ajout d'expertise pour guider la recherche vers les critères les plus pertinents Exemple : utilisation d'un arbre de décision D'où principe : Collecte des données Nombre d'exemples lié au nombre de variables et de valeurs par variable Recherche des facteurs pertinents Par mots clés (mc) dist(x,y)=1-(nombre_mc_commun(x,y)/ nombre_mc(x ou y) Hiérarchisation de concepts Indexation des données (plus proche voisin)
 dist(x,y)=1-(nombre_mc_commun(x,y)/ nombre_mc(x ou y) Hiérarchisation de concepts. Indexation des données (plus proche voisin)")
82
Conclusion Les points forts : Les points faibles :
produit des résultats explicites s'applique à tout type de données capable de travailler sur de nombreux champs facile à mettre en œuvre et à comprendre Les points faibles : nécessite un grand volume de données pour être performant très dépendant des fonctions de distance et de combinaison

83
Détection automatique de clusters
méthode de découverte de connaissances non dirigée (ou apprentissage sans supervision) ne nécessite aucun apprentissage principe : regrouper les éléments par similarités successives deux grandes catégories : la méthode des K-moyennes et les méthodes par agglomération. objectif : procéder à une classification du type regroupement par similitude un groupe appelé cluster utilisation classique : clusteriser une population puis étude prévoir une fonction de distance qui mesure l'écart entre deux enregistrements
 ne nécessite aucun apprentissage. principe : regrouper les éléments par similarités successives. deux grandes catégories : la méthode des K-moyennes et les méthodes par agglomération. objectif : procéder à une classification du type regroupement par similitude. un groupe appelé cluster. utilisation classique : clusteriser une population puis étude. prévoir une fonction de distance qui mesure l écart entre deux enregistrements.")
84
K means permet de découper une population en K clusters
K défini par l'utilisateur principe de fonctionnement : on positionne les K premiers points (ou noyaux) au hasard Chaque enregistrement est affecté au noyau le plus proche A la fin de la première affectation, calcul de la valeur moyenne de chaque cluster Le noyau prend cette nouvelle valeur répététition jusqu'à stabilisation des clusters
 au hasard. Chaque enregistrement est affecté au noyau le plus proche. A la fin de la première affectation, calcul de la valeur moyenne de chaque cluster. Le noyau prend cette nouvelle valeur. répététition jusqu à stabilisation des clusters.")
85
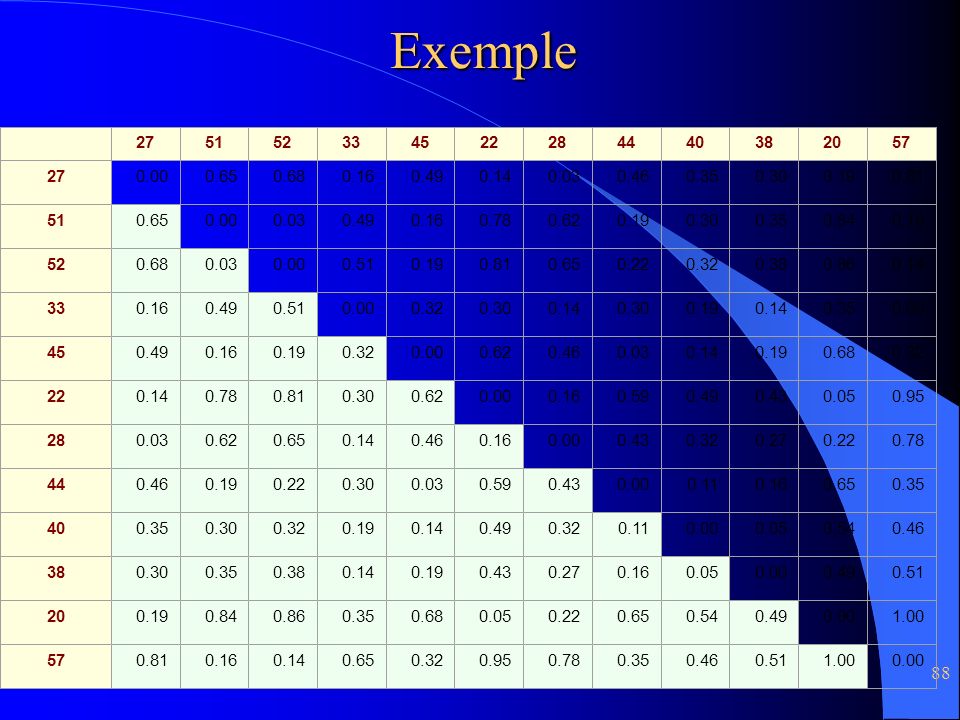
Exemple Personnes d'âge Ex : K=3 Les 3 noyaux : les trois premières valeurs distance = différence / (amplitude maximum) = différence / 37) 27 51 52 33 45 22 28 44 40 38 20 57 Noyau 27 0.00 0.65 0.68 0.16 0.49 0.14 0.03 0.46 0.35 0.30 0.19 0.81 Noyau 51 0.78 0.62 0.84 Noyau 52 0.51 0.22 0.32 0.38 0.86 Minimum 0.3 Affectation 1 2 3 noyau 1 (27) : noyau 2 (51) : noyau 3 (52) :
 = différence / 37) Noyau Noyau Noyau Minimum Affectation noyau 1 (27) : noyau 2 (51) : noyau 3 (52) :")
86
calcul des centroïdes : moyenne arithmétique du cluster
soit 28 pour noyau 1, 45 pour noyau 2 et 54.5 pour noyau 3 Ces valeurs = positions des nouvelles noyaux Recommençons le processus par rapport à ces valeurs 27 51 52 33 45 22 28 44 40 38 20 57 Noyau 28 0.03 0.62 0.65 0.14 0.46 0.16 0.43 0.32 0.27 0.22 0.78 Noyau 45 0.49 0.19 0.68 Noyau 54.5 0.74 0.09 0.07 0.58 0.26 0.88 0.72 0.28 0.39 0.45 0.93 Minimum Affectation 1 3 2 L'affectation donne la répartition suivante : noyau 1 (28) : Moyenne = 26 noyau 2 (45) : Moyenne = 41.75 noyau 3 (54.5) : Moyenne = 53.33 En réitérant le processus, aucune modification des affectations Les clusters sont finalisés : Cluster 1: Jeunes majeurs - Centroïde = 26 Cluster 2: Quadragénaires - Centroïde = 41.75 Cluster 3: Quinquagénaires - Centroïde = 53.33
 : Moyenne = 26. noyau 2 (45) : Moyenne = noyau 3 (54.5) : Moyenne = En réitérant le processus, aucune modification des affectations. Les clusters sont finalisés : Cluster 1: Jeunes majeurs - Centroïde = 26. Cluster 2: Quadragénaires - Centroïde = Cluster 3: Quinquagénaires - Centroïde =")
87
Classification hiérarchique ascendante
Calcul des distances 2à 2 Agglomération des plus proches vosins (inférieurs à un seuil Calcul des centroïdes On itère ..

88
Exemple 27 51 52 33 45 22 28 44 40 38 20 57 0.00 0.65 0.68 0.16 0.49 0.14 0.03 0.46 0.35 0.30 0.19 0.81 0.78 0.62 0.84 0.51 0.22 0.32 0.38 0.86 0.59 0.43 0.05 0.95 0.27 0.11 0.54 1.00
89
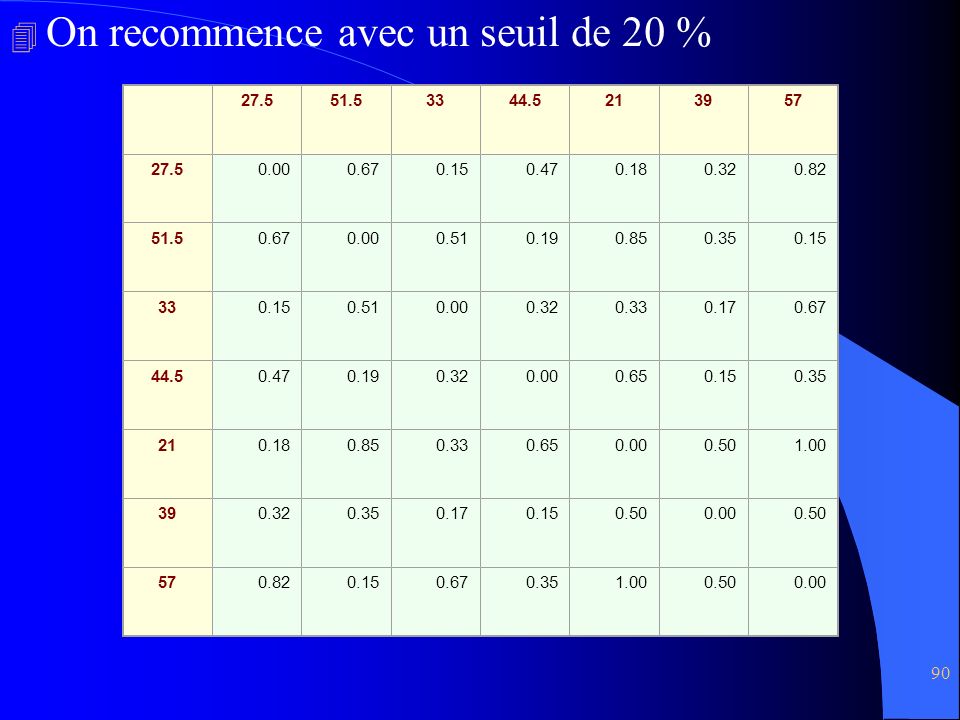
seuil = 10% (0.1) à chaque itération
fixé aléatoirement en fonction du niveau de regroupement souhaité par l'utilisateur. ensemble des valeurs ordonné en ordre croissant valeurs ayant un seuil inférieur à 10%, soit : 0.03 (52-51), 0.03 (27-28), 0.03 (44-45), 0.05 (38-40), 0.05 (20-22) 51 52 27 28 44 45 38 40 20 22 33 57 Chaque cluster est représenté par son centroïde (ici moyenne)
, 0.03 (27-28), 0.03 (44-45), 0.05 (38-40), 0.05 (20-22) Chaque cluster est représenté par son centroïde (ici moyenne)")
90
On recommence avec un seuil de 20 %
27.5 51.5 33 44.5 21 39 57 0.00 0.67 0.15 0.47 0.18 0.32 0.82 0.51 0.19 0.85 0.35 0.33 0.17 0.65 0.50 1.00
91
Conclusion Les points forts : Les points faibles :
Les résultats sont clairs plutôt facile à mettre en œuvre Pas grosse consommatrice de ressources application facile. Les points faibles : difficile de trouver une bonne fonction de distance Certains clusters résultants peuvent être difficiles à expliquer

92
Les arbres de décision objectif : classification et prédiction
fonctionnement basé sur un enchaînement hiérarchique de règles en langage courant composé : D’un nœud racine De questions De réponses qui conditionnent la question suivante De nœuds feuilles correspondant à un classement jeu de questions réponses itératif jusqu’à ce arrivé à un nœud feuille pour déterminer quelle variable affecter à chaque nœud, application d'un algorithme sur chaque paramètre et conservation du plus représentatif pour un découpage

93
Les Arbres de décisions
Le modèle Utiliser la valeur des attributs pour subdiviser l’ensemble d’exemples en sous-ensembles de plus en plus fins Réitérer la démarche jusqu’à obtenir une classe avec un nombre majoritaire de n-uplets appartenant à la même classe Arbre : nœud racine = S exemples Découpage successif par une séquence de décisions Résultat : un ensemble de règles Règle : si X=a et Y=b et… alors Classe 1 Parcours de l’arbre (liste d’attributs dont la valeur détermine une classe d’appartenance) Les modèles du datamining
 Les modèles du datamining.")
94
Les Arbres de décisions
Algorithme - Quinlan 1979 Fabrication d’un arbre minimal en recherchant à chaque niveau le paramètre le plus discriminant pour classifier un exemple Þ chemin optimal pour une classification correcte 1. Sélection de l’attribut le + déterminant à chaque nœud Développement des branches pour chacune des valeurs de l’attribut 2. si tout élément d’une branche appartient à la même classe alors la feuille est étiquetée avec la classe sinon retour en 2. 3. si toutes les feuilles sont étiquetées ou plus d’attributs alors fin sinon retour en 1. Les modèles du datamining

95
Amélioration C4.5 Utilisation de la notion d’entropie pour le choix de l’attribut à chaque étape Limiter le développement de l’arbre (« élagage ») Force => Fréq. Classe / Fréq. Totale > seuil Statistiques pour mesurer l’indépendance d’un attribut /classe (Chi 2)
")
96
Les Arbres de décisions
Traitements des infos bruitées ou corrompues 2 classes mais plus d’attributs pour subdiviser : étiquetage par la classe majoritaire ou probabilité test statistique : pour mesurer l’indépendance entre attribut et classe Traitements des valeurs manquantes Valeur majoritaire (renforce l’entropie) Ignorer l’exemple Probabilité sur chacune des branches Les modèles du datamining
 Ignorer l’exemple. Probabilité sur chacune des branches. Les modèles du datamining.")
97
Les Arbres de décisions
Principes de calculs Algorithme de détermination de variable significative Diminution du désordre apparent dans les données Cas de descripteur qualitatif Probabilité d’appartenance ex : grand-moyen-petit - sur 100 observations 20 ont la valeur « grand » - 20% Mesure de l’incertitude (désordre) : théorème de Shannon = - S Pi log2(Pi) avec Pi : % d’appartenance à la catégorie Algorithme issus du Chi 2 qui permet de vérifier la conformité d’un phénomène aléatoire à une loi de probabilité posée en hypothèse (algorithme de CHAID) Les modèles du datamining
 : théorème de Shannon. = - S Pi log2(Pi) avec Pi : % d’appartenance à la catégorie. Algorithme issus du Chi 2 qui permet de vérifier la conformité d’un phénomène aléatoire à une loi de probabilité posée en hypothèse (algorithme de CHAID) Les modèles du datamining.")
98
Les Arbres de décisions
Principes de calculs Cas des attributs à valeur (oui, non) métrique de Hamming Hd = Nbre de non coïncidences entre deux attributs pseudo-métrique de Hamming (facteur de la mesure du désordre) Pm = Min ((nbre ex - Hd), Hd) Les modèles du datamining
 métrique de Hamming. Hd = Nbre de non coïncidences entre deux attributs. pseudo-métrique de Hamming. (facteur de la mesure du désordre) Pm = Min ((nbre ex - Hd), Hd) Les modèles du datamining.")
99
Les Arbres de décisions
Exemple d’application de la distance de Hamming verse la taxe à l’école A eu un stagiaire RDV accepté RDV refusé Oui Non Oui Non Arbre obtenu après 2 itérations Les modèles du datamining

100
Les Arbres de décisions
Principes de calculs Cas de descripteur quantitatif Méthode de grappe : partition sur la médiane pour deux classes, en déciles pour plusieurs classes pas de garantie pour obtenir un seuil optimal de découpage mais la méthode est rapide Méthode exhaustive : méthode qui détermine le seuil optimal de découpage de la variable parcours de toutes les valeurs numériques prises par l’attribut calcul du pouvoir discriminant pour chaque valeur, la valeur ayant le plus grand pouvoir discriminant devient seuil Les modèles du datamining

101
Les Arbres de décisions
Enjeux La détection de variables importantes (structuration du phénomène étudié et mise en place de solutions correctrices) La construction d’un S.I. (repérage des variables déterminantes, amélioration des règles d’alimentation d’un Data Warehouse, affinement d’un processus d’historisation) Data Mining de masse (formalisme très simple) Les modèles du datamining
 La construction d’un S.I. (repérage des variables déterminantes, amélioration des règles d’alimentation d’un Data Warehouse, affinement d’un processus d’historisation) Data Mining de masse (formalisme très simple) Les modèles du datamining.")
102
Les Arbres de décisions
Résoudre 2 types de problèmes : Segmentation d’une population Affectation d’une classe à un individu Domaines d’application Etude de marketing (critères prépondérants dans l’achat) Marketing direct (isoler les meilleurs critères explicatifs) Ventes (analyse des performances) SAV (détecter les causes de réclamation, les défauts) Contrôle de qualité (identifier les éléments du processus) Domaine médical... Les modèles du datamining
 Marketing direct (isoler les meilleurs critères explicatifs) Ventes (analyse des performances) SAV (détecter les causes de réclamation, les défauts) Contrôle de qualité (identifier les éléments du processus) Domaine médical... Les modèles du datamining.")
103
Les Arbres de décisions
Avantages et limites Simplicité d’utilisation Lisibilité du modèle : règle Si ... alors ... sinon Pas adapté à un apprentissage incrémental (base de test) Taille de l’arbre : un arbre « touffu » perd son pouvoir de généralisation et de prédiction importance de l’utilisateur métier Perspectives : intégrer ce type d’outil à des tableurs ou EIS Les modèles du datamining
 Taille de l’arbre : un arbre « touffu » perd son pouvoir de généralisation et de prédiction. importance de l’utilisateur métier. Perspectives : intégrer ce type d’outil à des tableurs ou EIS. Les modèles du datamining.")
104
Les Algorithmes Génétiques
Définition Travaux récent 1975 (J. Holland) Système artificiel qui s’appuie sur le principe de sélection de Darwin et les méthodes de combinaison de gènes de Mendel Description de l’évolution d’une population d’individus en réponse à leur environnement Sélection : survie du plus adapté Reproduction Mutation Les modèles du datamining
 Système artificiel qui s’appuie sur le principe de sélection de Darwin et les méthodes de combinaison de gènes de Mendel. Description de l’évolution d’une population d’individus en réponse à leur environnement. Sélection : survie du plus adapté. Reproduction. Mutation. Les modèles du datamining.")
105
Principe Individus codés comme un ensemble de chromosomes
Chaque chromosome a sa vie propre Travail sur une population nombreuse de solutions potentielles toutes différentes Élimination des plus faibles pour reproduire les mieux adaptés Individus les + adaptés ont une + forte chance d'être sélectionnés et d’exister à la génération suivante Reproduction par hybridation génétique des plus forts Donne des individus encore plus forts La mutation d’un gène permet de conserver une certaine diversité dans la population

106
Remarque La population initiale cherche à peupler l'espace des solutions Succès dans les problèmes d’optimisation (proche des techniques de recherche opérationnelle) L’application successive du processus de sélection + mutation permet d’atteindre une solution optimale Les modèles du datamining
 L’application successive du processus de sélection + mutation permet d’atteindre une solution optimale. Les modèles du datamining.")
107
Codage Codage sous forme de 0 et 1 (codage du chromosome)
ex : [1]Ancienneté de la cde : 1 si < 6 mois et 0 sinon [2]CA Annuel : 1 si < 1000 $ et 0 sinon variable numérique transformée en entier puis en binaire

108
Fonction d'évaluation Dépendante du problème
Ex : taux d'impayés constatés Permet de sélectionner le taux de reproduction à la génération suivante Taille de la population constante Tirage au hasard des candidats à la survie Biaisé : ceux qui ont une fonction d'évaluation importante

109
Manipulation génétique
Hybridation échange entre 2 chromosomes d'un "morceau" mutation changement de parité inversion inversion de 2 caractères successifs

110
Les Algorithmes Génétiques
Principes Population Initiale Non Tri des solutions sur la fonction d’évaluation Oui Solution acceptable ? Solution retenue Sélection des individus à conserver Hybridation Mutation Nouvelle génération Les modèles du datamining

111
Exemple : voyageur de commerce
Lille Reims Dijon Lyon Aix Pau Nantes Rouen 000 001 010 011 110 111 Codage : 8 villes donc 3 bits Ordre donne la succession des villes traversées Fonction d'évaluation Ville non visitée : pénalité de 1000 Km distance entre 2 villes successives

112
Lille Reims Dijon Lyon Aix Pau Nantes Rouen 000 001 010 111 011 100
101 3 chromosomes : F(1) = 5400 F(2) = 4700 F(3) = 2700 Reproduction de 2 (1 fois) et de 3 (3 fois)
 = F(2) = F(3) = Reproduction de 2 (1 fois) et de 3 (3 fois)")
113
Lille Reims Dijon Lyon Aix Pau Nantes Rouen 000 010 001 011 100 101
111 Hybridation entre les chromosomes 3 et 4 échange d'une portion de chaîne

114
Lille Reims Dijon Lyon Aix Pau Nantes Rouen 000 010 001 011 100 101
111 F(1) =2700 F(2) = 4700 F(3) = 3600 F(4) = 3200
 =2700. F(2) = F(3) = F(4) =")
115
Lille Reims Dijon Lyon Aix Pau Nantes Rouen 000 010 001 011 100 101
Mutation du 1 : changement de parité au hasard Lille Reims Dijon Lyon Aix Pau Nantes Rouen 000 010 001 011 100 101 111 110 F(0) = 2200 On conserve 0, 1,4
 = On conserve 0, 1,4.")
116
Lille Reims Dijon Lyon Aix Pau Nantes Rouen 000 010 001 011 100 111 101

117
Les Algorithmes Génétiques
Domaines d’application Domaine industriel problème d’optimisation ou de contrôle de processus complexes (ex : optimisation de la T° d’un four, de la pression d’un cylindre) Domaine spatial et géomarketing (ex : optimisation de l’emplacement d’automates bancaires, optimisation d’une campagne d’affichage) Utiliser d’autres techniques en complément (RN modifier le poids des liaisons, arbre de décision en isolant les variables qui expliquent un comportement) Les modèles du datamining
 Domaine spatial et géomarketing. (ex : optimisation de l’emplacement d’automates bancaires, optimisation d’une campagne d’affichage) Utiliser d’autres techniques en complément. (RN modifier le poids des liaisons, arbre de décision en isolant les variables qui expliquent un comportement) Les modèles du datamining.")
118
Les Algorithmes Génétiques
Avantages et limites Capacité à découvrir l’espace : N Þ N3 Limite du codage (formé de 0 et 1) complexe à mettre en place pb pour représenter la proximité de valeurs numériques Dosage des mutations : pb des sous-optimums locaux réglage subtil entre le mouvement et la stabilité taux d’hybridation Þ recombinaison des chaînes mais risque de détruire de bonnes solutions taux de mutation Þ espace de solutions avec des risques d’altération Les modèles du datamining
 complexe à mettre en place. pb pour représenter la proximité de valeurs numériques. Dosage des mutations : pb des sous-optimums locaux. réglage subtil entre le mouvement et la stabilité. taux d’hybridation Þ recombinaison des chaînes mais risque de détruire de bonnes solutions. taux de mutation Þ espace de solutions avec des risques d’altération. Les modèles du datamining.")
119
Les Réseaux Neuronaux Définition
1943 McCulloch et Pitts - Perceptron Connexionisme Analogie avec le fonctionnement du cerveau 2 catégories : supervisé : réponse connue (apprentissage à partir d'exemples) non supervisé : le réseau ne connaît pas le type de résultat Découvrir la structure sous-jacente des données par une recherche des corrélations des entrées pour les organiser en catégories Réseau non supervisé » techniques statistiques (analyse de données) Les modèles du datamining
 non supervisé : le réseau ne connaît pas le type de résultat. Découvrir la structure sous-jacente des données par une recherche des corrélations des entrées pour les organiser en catégories. Réseau non supervisé » techniques statistiques (analyse de données) Les modèles du datamining.")
120
Structure Les composants : Le neurone formel Une règle d’activation
Une organisation en couches Une règle d’apprentissage

121
Neurone formel calcule la somme pondérée par son poids de chaque entrée transmise par le reste du réseau (Xi * Wi) X1 X2 X3 X4 W1 W2 W3 W4 Variables en entrée Poids associés sur chaque connexion Les modèles du datamining
 X1. X2. X3. X4. W1. W2. W3. W4. Variables en entrée. Poids associés sur. chaque connexion. Les modèles du datamining.")
122
Règle d'activation Associée à chaque neurone formel Définie avec
une fréquence T une fonction généralement sigmoïde, dont le résultat est d’activer ou non le neurone de sortie X1 X2 X3 X4 W1 W2 W3 W4 Fonction Sortie

123
Les Réseaux Neuronaux Définition X1 X2 X3 X4 X5 W1 W15 U1
Organisation en couches pour résoudre des problèmes de toute complexité La couche d’entrée transmet ses résultats à la couche supérieure qui, ayant de nouvelles données et de nouveaux poids retransmet ses données résultantes à la couche suivante et ainsi de suite jusqu’à la couche de sortie qui fournit le neurone de sortie couches intermédiaires = couches cachées. Matrice des poids pour chaque couche Activation du nœud en sortie X1 X2 X3 X4 X5 W1 W15 U1 Les modèles du datamining

124
Les Réseaux Neuronaux Auto-apprentissage
Capacité du réseau à changer son comportement en fonction de son expérience passée Þ variation des poids de connexion Règle d’apprentissage : minimiser l’erreur entre la donnée fournie par le réseau et la donnée réelle Renforcement des connexions les plus actives (règle de Hebb) Þ convergence rapide du réseau Possibilité d’intégrer des relations complexes entre les données Les modèles du datamining
 Þ convergence rapide du réseau. Possibilité d’intégrer des relations complexes entre les données. Les modèles du datamining.")
125
Les Réseaux Neuronaux Construction d’un réseau de neurones
Phase 1 : préparation des données Données en entrée / sortie Constitution de la base d’exemples Représentativité de toutes les classes en sortie => Augmentation du pouvoir de prédiction ex : si 3% refus, proportion (50% refus et 50% accepté) Codage des entrées Variable discrète = un neurone par type de valeur Certaines variables continues traitées comme des variables discrètes Optimisation du jeu de données Les modèles du datamining
 Codage des entrées. Variable discrète = un neurone par type de valeur. Certaines variables continues traitées comme des variables discrètes. Optimisation du jeu de données. Les modèles du datamining.")
126
Les Réseaux Neuronaux Construction d’un réseau de neurones
Phase 2 : création des fichiers Base d’exemples (80 %) et base de test (20%) Dispatching aléatoire : brassage du fichier Phase 3 : paramètres du réseau Matrice : poids entre les connexions Les logiciels : modes par défaut (mode novice ou expert) Nombreux paramètres : architecture, fonction de sommation, fonction de transformation (fonction sigmoïde), normalisation de la sortie, transmission de la sortie (sorties actives, rétro-propagation), calcul de l’erreur (erreur quadratique, absolue, moyenne…) Les modèles du datamining
 et base de test (20%) Dispatching aléatoire : brassage du fichier. Phase 3 : paramètres du réseau. Matrice : poids entre les connexions. Les logiciels : modes par défaut (mode novice ou expert) Nombreux paramètres : architecture, fonction de sommation, fonction de transformation (fonction sigmoïde), normalisation de la sortie, transmission de la sortie (sorties actives, rétro-propagation), calcul de l’erreur (erreur quadratique, absolue, moyenne…) Les modèles du datamining.")
127
Les Réseaux Neuronaux Phase 5 : performance du réseau
Construction d’un réseau de neurones Phase 4 : apprentissage (mise à jour itérative des poids) calcul de la rétro-propagation 1. Initialisation de la matrice des poids au hasard 2. Choix d’un exemple en entrée 3. Propagation du calcul de cette entrée dans le réseau 4. Calcul de la sortie de cette entrée 5. Mesure de l’erreur de prédiction (¹ sortie réelle et sortie prévue) 6. Calcul de la sensibilité d’un neurone (contribution à l’erreur) 7. Détermination du gradient 8. Correction des poids des neurones 9. Retour à l’étape 2 Phase 5 : performance du réseau Matrice de confusion Les modèles du datamining
 calcul de la rétro-propagation. 1. Initialisation de la matrice des poids au hasard. 2. Choix d’un exemple en entrée. 3. Propagation du calcul de cette entrée dans le réseau. 4. Calcul de la sortie de cette entrée. 5. Mesure de l’erreur de prédiction (¹ sortie réelle et sortie prévue) 6. Calcul de la sensibilité d’un neurone (contribution à l’erreur) 7. Détermination du gradient. 8. Correction des poids des neurones. 9. Retour à l’étape 2. Phase 5 : performance du réseau. Matrice de confusion. Les modèles du datamining.")
128
Les Réseaux Neuronaux Domaines d’application
RN sont largement diffusés Reconnaissance des formes Traitement du signal domaine médical, risque cardiovasculaire domaine bancaire, risque de défaillance ou d’utilisation frauduleuse Classification marketing (identification de segments de clients) industrie (détection de défauts et de pannes) Prévision prévision de valeurs boursières, des ventes en marketing… Contrôle adaptatif (robotique) Les modèles du datamining
 industrie (détection de défauts et de pannes) Prévision. prévision de valeurs boursières, des ventes en marketing… Contrôle adaptatif (robotique) Les modèles du datamining.")
129
Les Réseaux Neuronaux Avantages et limites Auto-apprentissage
Technologie éprouvée (des réponses aux limites) Faux mythe de la boite noire Risque de trop apprendre Taille de la base d ’exemple ex : 256 entrées, une couche intermédiaire à 10 neurones et 3 neurones en sortie = 2590 connexions soit exemples Risque de non optimalité présence de minima locaux apprentissage sur plusieurs réseaux à partir de plusieurs matrices de poids ou variation du delta au cours de la construction du réseau Temps de calcul Les modèles du datamining
 Faux mythe de la boite noire. Risque de trop apprendre. Taille de la base d ’exemple. ex : 256 entrées, une couche intermédiaire à 10 neurones et 3 neurones en sortie = 2590 connexions soit exemples. Risque de non optimalité. présence de minima locaux. apprentissage sur plusieurs réseaux à partir de plusieurs matrices de poids ou variation du delta au cours de la construction du réseau. Temps de calcul. Les modèles du datamining.")
130
Les réseaux Bayésiens Définition
Modèle graphique qui encode les probabilités entre les variables plus pertinentes Associer une probabilité d’apparition d’un événement étant donné la connaissance d’autres événements Comprendre certaines relations causales (notion d’antériorité ou d’impact) conjonction de certaines variables pour déclencher une action Les modèles du datamining
 conjonction de certaines variables pour déclencher une action. Les modèles du datamining.")
131
Les réseaux Bayésiens Conception des réseaux bayésiens
Graphe orienté : Probabilité d’apparition d’un événement : Force des dépendances entre variable = probabilité conditionnelle Objet Prêt Contentieux Sain Montant Durée P(Sain|Objet, Durée, Montant) = P(Objet) x P(Montant|Objet) x P(Durée|Montant, Objet) x P(Sain|Montant, Durée) Les modèles du datamining
 = P(Objet) x P(Montant|Objet) x P(Durée|Montant, Objet) x P(Sain|Montant, Durée) Les modèles du datamining.")
132
Les réseaux Bayésiens Conception des réseaux bayésiens
Complexité du réseau Variables discontinues autant de nœuds que de valeurs Variables continues modélisées par la techniques de grappe Limiter le nombre de nœuds et de connexions Ex : 10 objets de prêt, 10 tranches de montant, 10 tranches de durée, résultats en sortie = 32 nœuds Elagage du réseau Regroupement des valeurs Limitations des liens : recherche de la couverture minimale Les modèles du datamining

133
Les réseaux Bayésiens Domaines d’application Avantages et limites
Peu d’applications opérationnelles - technique jeune (modélisation de processus d’alertes, prédiction de risques d’impayés pour télécommunications) Peu de logiciels Avantages et limites Bon compromis entre puissance et compréhension Bonne résistance au bruit Limite de la puissance de calcul Ex : 3 var. de 10 modalités et 2 parents = 90 lectures Les modèles du datamining
 Peu de logiciels. Avantages et limites. Bon compromis entre puissance et compréhension. Bonne résistance au bruit. Limite de la puissance de calcul. Ex : 3 var. de 10 modalités et 2 parents = 90 lectures. Les modèles du datamining.")
134
Plan Introduction 1.Généralités 2. Le processus de datamining
3. Les modèles du datamining 4. Exemples 5. Critères pour le choix d’un logiciel Conclusion et perspectives

135
exemple : Étude de cas

136
Exemple Cas très simplifié
Identification de profils clients et organisation d’une campagne de marketing direct Voyagiste qui organise des circuits touristiques et propose 5 types de prestations (A, B, C, D, E) Politique de fidélisation des clients
 Politique de fidélisation des clients.")
137
Exemple : 1. Poser le problème
Affiner le problème : fidéliser le client Þ vendre aux clients existants de nouvelles prestations Þ transformer les mono-détenteurs en multi-détenteurs 1. Problème de structuration Distinguer les mono-détenteurs, qui sont mes clients ? 2. Problème d’affectation Construire des cibles prioritaires pour la vente croisée de produits, quels sont les clients à contacter ?

138
Exemple : 2. Recherche des données
Infos disponibles « comportement d’un client » informations Client : Age, Sexe, Situation familiale, Nombre d’enfants, Catégorie socioprofessionnelle, Nombre d’années dans l’emploi informations sur les Produits achetés : Produit A + date du 1er achat du produit A Produit B + date du 1er achat du produit B ... Produit E + date du 1er achat du produit E

139
Exemple : 2. Recherche des données
Infos disponibles « comportement d’un client » informations comptables Montant des achats, Date du dernier achat, Type de paiement, Statut financier informations collectées par questionnaire Centres d’intérêts informations géographiques Code commune, taille de la commune, type habitat origine des variables de trois sources : systèmes gestion client, gestion produits et achats, enquêtes et Insee Traitements sur les données « dédoublonnage » des fichiers et traitement des adresses

140
Exemple : 3. Sélection des données
Données des centres d’intérêts données saisies manuellement + données issues de mégabases (Calyx ou ConsoData) 1 client sur 2 répond aux enquêtes + 10% issus des mégabases Þ 55% taux de renseignement Þ extraction sur toute la population (biais) Étude sur le thème (Récence-Fréquence-Monétaire) pas d’achats sur les 5 dernières années pour 30% clients 10% clients = 40% du C.A. Þ suppression des 30% d’inactifs et sur-pondération des 10% des clients à fort C.A.
 1 client sur 2 répond aux enquêtes + 10% issus des mégabases Þ 55% taux de renseignement. Þ extraction sur toute la population (biais) Étude sur le thème (Récence-Fréquence-Monétaire) pas d’achats sur les 5 dernières années pour 30% clients. 10% clients = 40% du C.A. Þ suppression des 30% d’inactifs et sur-pondération des 10% des clients à fort C.A.")
141
Exemple : 3. Sélection des données
Modification du plan d’extraction : Þ clients à fort C.A. : 80% des questionnaires remplis Þ 80% clients intermédiaires : 60% de réponses Procédures d’extraction si dernier achat de + de 5 ans : ne pas extraire si achat > 25000F : tirage aléatoire 1 sur 3 (30%) sinon tirage aléatoire : un enregistrement sur 10 (10%) Échantillon non représentatif de la population mais plus représentatif des enjeux de marketing (accroître le C.A.)
 sinon tirage aléatoire : un enregistrement sur 10 (10%) Échantillon non représentatif de la population mais plus représentatif des enjeux de marketing. (accroître le C.A.)")
142
Exemple : 4. Nettoyage des données
Taille du fichier Extraction fichiers de 1500 clients avec qualification de 1410 adresses Þ fichier de 1410 enregistrements Enrichissement des centres d’intérêts : taux de pertinence 94% Valeurs aberrantes analyse valeurs minimales et maximales ex : exclusion des clients avec C.A.> 35000F Þ erreur de codification clients particuliers et entreprises analyse de la distribution (homogénéité) ex : distribution des âges, crête forte sur des valeurs rondes 20, 25, 30 contrôle de cohérence des infos ex : code CSP inexistant classé 99, absence de personnes mariées, dates incohérentes => pb extraction ou suppression des enregistrements
 ex : distribution des âges, crête forte sur des valeurs rondes 20, 25, 30. contrôle de cohérence des infos. ex : code CSP inexistant classé 99, absence de personnes mariées, dates incohérentes. => pb extraction ou suppression des enregistrements.")
143
Exemple : 4. Nettoyage des données
Valeurs manquantes nombre d’enfants : valeur NR ou moyenne nationale Valeurs nulles discrétisation de la valeur ex : Nb enfants NR = Null, 0 = 0, 1 = 1, 2 = 2, 3 à N = 3 Transformation des variables pour introduire des dimensions particulières âge du client au 1er achat (âge et date au 1er achat) durée de vie du client (âge au 1er et au dernier achat) détention des produits (nbre de produits détenus) type habitat et taille de la commune
 durée de vie du client (âge au 1er et au dernier achat) détention des produits (nbre de produits détenus) type habitat et taille de la commune.")
144
Exemple : 6. Recherche du modèle
1. Caractériser la population en sous-groupes homogènes: typologie des clients Analyse factorielle met en évidence 3 facteurs principaux nombre de produits achetés ancienneté des achats données sur l’âge du client ancienneté dans l’emploi C.A. Techniques des nuées dynamiques

145
Exemple : 6. Recherche du modèle
1. Caractériser la population en sous-groupes âgés avec gros C.A. 4 % C.A. élevé jeunes clients avec gros C.A. 3% âge moyen avec C.A. important 5% S4 S1 S6 âge moyen avec C.A. moyen 6 % âgés avec C.A. moyen 21 % jeunes avec C.A. moyen 20 % S5 S3 S2 Âgés Jeunes S9 jeunes avec petit C.A. 21% S8 âgés avec petit C.A. 7 % âge moyen avec petit C.A. 7 % S7 C.A. faible multidétenteur monodétenteur

146
Exemple : 6. Recherche du modèle
2. Ventes croisées (modèle de prédiction) Qu’est ce qui caractérise les gros C.A. parmi les jeunes clients, les middle-aged et les âgés ? Étude sur les jeunes clients Approche neuronale : distinction des facteurs pertinents 3 segments : multiacheteurs avec fort C.A. 3%, multiacheteur avec C.A. moyen 20%, monoacheteurs 21% Modèle pour permettre de vendre plus (2 classes : monodétenteur et multidétenteur)
 Qu’est ce qui caractérise les gros C.A. parmi les jeunes clients, les middle-aged et les âgés Étude sur les jeunes clients. Approche neuronale : distinction des facteurs pertinents. 3 segments : multiacheteurs avec fort C.A. 3%, multiacheteur avec C.A. moyen 20%, monoacheteurs 21% Modèle pour permettre de vendre plus. (2 classes : monodétenteur et multidétenteur)")
147
Exemple : 6. Recherche du modèle
Premiers résultats (représentation équilibrée à 50% des deux classes) facteurs pertinents : CSP, nb d’années dans l’emploi, statut familial, nb enfants diminution des variables en entrée du réseau Réseau final modèle appliqué à l’ensemble de la base probabilité d’appartenance des classes ajoutée dans la BD résultat : modèle à 75% Mono prédit Multi prédit prospects Mono observé 30% 15% Multi observé 10% 45% erreurs
 facteurs pertinents : CSP, nb d’années dans l’emploi, statut familial, nb enfants. diminution des variables en entrée du réseau. Réseau final. modèle appliqué à l’ensemble de la base. probabilité d’appartenance des classes ajoutée dans la BD. résultat : modèle à 75% Mono prédit. Multi prédit. prospects. Mono observé. 30% 15% Multi observé. 10% 45% erreurs.")
148
Exemple : 6. Recherche du modèle
Arbre de décision : isoler les monodétenteurs des multidétenteurs mise en évidence de l’âge comme premier facteur explicatif de la monodétention Arbre de décision appliqué sur une population jeune Þ cadre ou profession libérale consommateur de voyages Þ jeune marié avec un voyage longue distance : cible peu propice Approche neuronale et Arbre de décision appliqués sur les populations « middle-aged » et « âgé »

149
Exemple : 7. Évaluation du résultat
Mesure du taux de classification sur la base test ¹ entre base apprentissage et test doit être minimale Validation avec la connaissance des commerciaux et des spécialistes marketing possibilité d’interagir sur l’arbre de décision en forçant la scission sur une variable supposée pertinente par les experts pour prouver le faible pouvoir discriminant Travail important de communication et de présentation des résultats

150
Exemple : 8. Intégration de la connaissance
politique de communication et production orientée client Forte Faible Flexibilité de communication Flexibilité externe One to Monolithisme augmenter les informations stockées, personnalisa- tion des courriers personnalisation du catalogue et des tarifs Flexibilité de production/logistique rapport

151
Plan Introduction 1.Généralités 2. Le processus de datamining
3. Les modèles du datamining 4. Exemples 5. Critères pour le choix d’un logiciel Conclusion et perspectives

152
Choix d’un logiciel de Data Mining
Selon son prix Selon son intégration possible Selon le problème à résoudre Selon les compétences des utilisateurs

153
Gamme de prix Suites statistiques évolutives (1500-4500 EUR)
SPAD (CISIA) Smart Miner (Grimmer Soft) Knowlbox (Complex Systems) mélange de techniques de gestion de bases de données, d’outils statistiques et de techniques de data mining
 Smart Miner (Grimmer Soft) Knowlbox (Complex Systems) mélange de techniques de gestion de bases de données, d’outils statistiques et de techniques de data mining.")
154
Gamme de prix Outils légers, pour PC de bureau (<2500 EUR)
Scenario (Cognos) Diamond (SPSS) Previa (ElseWare) technique unique de data mining, algorithme unique, facile d’utilisation
 Diamond (SPSS) Previa (ElseWare) technique unique de data mining, algorithme unique, facile d’utilisation.")
155
Gamme de prix Outils intermédiaires (3000-25000 EUR)
Légers étendus : Alice (ISoft) 4Thought (Cognos) Knowledge Seeker (Angoss) Concurrents poids lourds : Clementine (SPSS) PolyAnalyst (Megaputer) majoritaires, accessibles aux néophytes et aux experts
 4Thought (Cognos) Knowledge Seeker (Angoss) Concurrents poids lourds : Clementine (SPSS) PolyAnalyst (Megaputer) majoritaires, accessibles aux néophytes et aux experts.")
156
Gamme de prix Outils poids lourds (30000-150000-… EUR)
Intelligent Miner (IBM) SAS Entreprise Miner (SAS) Decision Series (NeoVista) Mineset (Silicon Graphics) Tera Miner (NCR) ensembles intégrés (techniques et algorithmes variés), puissants
 SAS Entreprise Miner (SAS) Decision Series (NeoVista) Mineset (Silicon Graphics) Tera Miner (NCR) ensembles intégrés (techniques et algorithmes variés), puissants.")
157
Possibilité d’intégration ?
Connexion aux BD ? Format spécifique ? Fonction de nettoyage ? Interface avec des requêteurs et outils OLAP ? En amont, pour orienter l’analyse En aval, pour évaluer les résultats et simuler les décisions

158
Complexité du problème ?
Quantité des données traitées si énorme, éviter un outil utilisant Excel… Origine des données traitées Nombre d’inter-relations entre variables Nature des relations linéaires ou non Techniques souhaitées pour construire un modèle : Unique : connue à l’avance ou choisie par expérimentation Combinées

159
Niveau des utilisateurs ?
Compétences requises spécialistes des données à traiter interfaces utilisateurs assistants formation proposée Novices : interface conviviale, technicité masquée, interprétation guidée Experts : transformation des données, affinage du modèle, …

160
Choix d’un logiciel de Data Mining
Bref,… l’expérimentation est une bonne solution

161
Outils spécialisés Data morphing Arbres de décisions
Amedea (Isoft) Arbres de décisions Scenario, Answer Tree (SPSS), Alice Réseaux de neurones Neuro One (Netral), Saxon (PMSI), Previa (ElseWare), 4Thought Text mining TextAnalyst (Megaputer), NeuroText (Grimmer), Umap (Trivium)
 Arbres de décisions. Scenario, Answer Tree (SPSS), Alice. Réseaux de neurones. Neuro One (Netral), Saxon (PMSI), Previa (ElseWare), 4Thought. Text mining. TextAnalyst (Megaputer), NeuroText (Grimmer), Umap (Trivium)")
162
Outils intégrés Tous les « poids lourds »
+ Strada (Complex Systems) : AD, AG, RN + Knowledge Seeker : AD, RN
 : AD, AG, RN. + Knowledge Seeker : AD, RN.")
163
Pièges à éviter Système d’exploitation Matériel Coût Dépendances
Windows (en général) Unix (poids lourds + produits peu commerciaux) Matériel Minimum 256Mo RAM pour les poids lourds Lenteur d’un réseau Coût Achat ou location ? Dépendances Besoin de « modules » supplémentaires ?
 Unix (poids lourds + produits peu commerciaux) Matériel. Minimum 256Mo RAM pour les poids lourds. Lenteur d’un réseau. Coût. Achat ou location Dépendances. Besoin de « modules » supplémentaires")
164
Expérimentations Indispensables pour choisir un outil A l’UFR :
Alice : version d’évaluation, à installer en local (C:\Temp mot de passe : ducksoup) SAS Entreprise Miner : quelques licences louées très cher, disponible (au moins) en salle 213
 SAS Entreprise Miner : quelques licences louées très cher, disponible (au moins) en salle 213.")
165
Plan Introduction 1.Généralités 2. Le processus de datamining
3. Les modèles du datamining 4. Exemples 5. Critères pour le choix d’un logiciel Conclusion et perspectives

166
Conclusion et Perspectives
Réussite d’un bon projet pilote Constituer un enjeu pour l’entreprise Impliquer plusieurs directions (application transversale) Avoir des effets mesurables rapidement typologie client - pas immédiatement opérationnel + facile optimisation d’une cible de marketing Sujet pour lequel il existe une compétence interne complémentarité avec les experts découverte de phénomène insoupçonnés (+ du DM) Aboutir à des conclusions pouvant être mises en œuvre Rechercher les problèmes répétitifs de l’entreprise
 Avoir des effets mesurables rapidement. typologie client - pas immédiatement opérationnel. + facile optimisation d’une cible de marketing. Sujet pour lequel il existe une compétence interne. complémentarité avec les experts. découverte de phénomène insoupçonnés (+ du DM) Aboutir à des conclusions pouvant être mises en œuvre. Rechercher les problèmes répétitifs de l’entreprise.")
167
Conclusion et Perspectives
L’outillage de base pour un projet de DM Une BD relationnelle Un requêteur (BO, Impromptu, Bio ou GQL) [+ outil de visualisation graphique] agrégation complexe et nettoyage des données Logiciel statistique (si composantes non intégrées) Logiciel d’arbre de décision (3 catégories : poids lourds, haut de gamme, solution légère) Réseau de neurones (prévision temporelle, modèles non linéaires) Matériel dépend des outils et du nbre d’enregistrements
 [+ outil de visualisation graphique] agrégation complexe et nettoyage des données. Logiciel statistique (si composantes non intégrées) Logiciel d’arbre de décision. (3 catégories : poids lourds, haut de gamme, solution légère) Réseau de neurones. (prévision temporelle, modèles non linéaires) Matériel dépend des outils et du nbre d’enregistrements.")
168
Conclusion et Perspectives
Pièges à éviter Attention à la qualité des données ! Eviter une démarche centrée outils Þ définir le pb avant Le DM ne remplace pas les statistiques Þ complémentarité Intégrer les résultats du DM dans le S.I. Ne pas négliger la communication et la mise en application Anticiper la résistance Þ participation des utilisateurs Démystifier le DM

169
Conclusion et Perspectives
Data Mining et SGBD intégration des fonctions de DM Þ transparence de l’analyse et flux continu Data Mining et OLAP intégration des technologies de DM dans les outils d’interrogation et de visualisation ex : partenariat BO et Isoft produit Alice partenaire Cognos / Angoss produit Scenario Þ proposer à l’utilisateur les dimensions à étudier en priorité Þ conseiller l’intégration aux outils de navigation

170
Conclusion et Perspectives
Data Mining et Multimédia text mining, image mining, video mining (ex : interprétation des commentaires libres dans les enquêtes) (ex : similarité entre images médicales Þ aide au diagnostic) (ex : indexation automatique de banques de films) Data Mining et Internet Internet facilite la collecte d’information par son coût faible - BD sur le comportement des clients (profil d’un client sur le site WEB d’un voyagiste) => applications interactives DM apporte des solutions innovantes pour la navigation Interface internet Þ standardisation des interfaces HTML
 (ex : similarité entre images médicales Þ aide au diagnostic) (ex : indexation automatique de banques de films) Data Mining et Internet. Internet facilite la collecte d’information par son coût faible. - BD sur le comportement des clients (profil d’un client sur le site WEB d’un voyagiste) => applications interactives. DM apporte des solutions innovantes pour la navigation. Interface internet Þ standardisation des interfaces HTML.")
171
Conclusion et Perspectives
Vers une « verticalisation » des outils de DM ? Applications du DM sur des domaines particuliers Þ profiter de la puissance du DM sans investir en compétences spécifiques ex : SLP : outil d’analyse de départ de clients dans le domaine des télécommunications VMData : outil prêt à l’emploi pour construire des ciblages Le processus de DM est rarement reproductible Solutions restreintes à des domaines très étroits

172
Conclusion et Perspectives
Droit informatique & liberté et le DM ? Domaine de prédilection du DM : la K du client Exploitation de données pour prédire des comportements individuels Position de la CNIL conformité des méthodes de ciblage à la loi Info & Liberté pas de prise en compte de critères raciaux, politiques, ni aboutir à des qualificatifs péjoratifs ou défavorables Atteinte à la vie privée ? Ex : l’examen des achats par CB ? Droit de regard sur tout traitement automatisé « Big Brother »

173
Conclusion et Perspectives
Évolution plutôt que révolution Ne pas confondre le processus et les outils souvent limité à la phase de recherche du modèle évolution des outils, intégration d’assistants dans le processus Maturité des principales techniques de modélisation Une BD renferme de la connaissance sur l’entreprise règle de gestion : contraintes d’intégrité, triggers modèle des données (ex : modélisation d’une base exprime souvent une classification initiale, le modèle exprime également des liens entre les entités du monde réel)
")
174
Bibliographie Le Data Mining R. Lefébure, G.Venturi Eyrolles 1998
Et de nombreux documents trouvés sur le web !

175
Exemple Plusieurs en quêtes (sources) sur les goûts des gens au cinéma
Base de données relationnelle: cinéma Personne(id-personne,nom,sexe,âge) Enquête(id-personne,id-source,id-film,vote) Source(id-source,nom-source) Film(id-film, titre,année)
 Enquête(id-personne,id-source,id-film,vote) Source(id-source,nom-source) Film(id-film, titre,année)")
176
Algorithme CART algorithme publié en 1984 par L.Briemen
utilisé dans de nombreux outils du marché Processus Trouver la première "bifurcation" Développer l’arbre complet Mesurer le taux d’erreur à chaque nœud Calculer le taux d’erreur de l’arbre entier Elaguer Identifier les sous-arbres Evaluer les sous-arbres Evaluer le meilleur sous-arbre

177
Principe première "bifurcation" : celle qui divise le mieux les enregistrements en groupes pour déterminer le critère qui effectuera le meilleur partage entre les éléments Calcul d'un indice de diversité Max(diversité(avant division) – (diversité fils gauche + diversité fils droit)) différents modes de calcul pour l’indice de diversité : Min (Probabilité(c1), Probabilité(c2)) (Probabilité(c1)logProbabilité(c1))+ (Probabilité(c2)logProbabilité(c2))
 – (diversité fils gauche + diversité fils droit)) différents modes de calcul pour l’indice de diversité : Min (Probabilité(c1), Probabilité(c2)) (Probabilité(c1)logProbabilité(c1))+ (Probabilité(c2)logProbabilité(c2))")
178
Principe Une fois la première bifurcation établie : le nœud racine se sépare en 2 étape suivante : développer l’arbre complet en divisant de la même façon les nouveaux nœuds crées ainsi de suite tant que le résultat de la division a une valeur significative dernier nœud : nœud feuille donnant le classement final d’un enregistrement

179
Principe L’arbre résultant n’est pas obligatoirement le meilleur
prochaine étape : calcul du taux d’erreur pour chaque nœud Si 11 enregistrements sur 15 sont classés correctement d’après l’ensemble d’apprentissage, la probabilité pour ce nœud est de 11/15 soit 0,7333 Le taux d’erreur attribué est de 1 – 0,7333 = 0,2667. possible de calculer le taux d’erreur de l’arbre entier soit : t : taux d’erreur d’un nœud P : probabilité d’aller au nœud Taux d’erreur de l’arbre = (t * P) Soit dans l’exemple, avec un taux d’erreur de (15/17) pour le nœud Masculin ((11/15) * 0,80) + ((15/17) * 0,20) = 0,763
 Soit dans l’exemple, avec un taux d’erreur de (15/17) pour le nœud Masculin. ((11/15) * 0,80) + ((15/17) * 0,20) = 0,763.")
180
Principe à l’issue du premier passage choix des branches à supprimer :
certains nœuds feuilles ne contiennent pas suffisamment d’enregistrements pour être significatifs élaguer le plus complexe étant de trouver la bonne limite à appliquer choix des branches à supprimer : par taux d’erreur ajusté d’un arbre Calculé, sur chaque sous arbre possible : Soit le compte des feuilles Taux d’erreur ajusté = taux d’erreur + compte des feuilles Un premier sous arbre est candidat lorsque son taux d’erreur ajusté devient plus petit ou égal au taux d’erreur ajusté de tout l’arbre Toutes les branches, qui n’en font pas partie, sont élaguées le processus recommence ainsi de suite jusqu’au nœud racine

181
Principe maintenant choisir parmi tous les sous arbres candidats
chaque sous arbre va être exécuté avec un ensemble de test celui qui aura le plus petit taux d’erreur sera le meilleur pour contrôler l’efficacité du sous arbre sélectionné un ensemble d’évaluation va lui être soumis Son taux d’erreur obtenu donnera une estimation des performances de l’arbre

182
Différence avec CART Nombre de sorties d’un nœud variable
CART génère des sorties binaires C4.5 accepte plusieurs valeurs à l’issue d’un nœud Méthode de détermination de l’ordre des bifurcations CART utilise l’indice de diversité comme méthode d’affectation des bifurcations C4.5 utilise le gain informationnel total Elagage C4.5 n’utilise pas d’ensemble de test il élague son arbre à partir des données d’apprentissage en considérant que le taux d’erreur réel sera sensiblement pire parfois, lorsque les nœuds comportent peu d’enregistrements, suppression de sous-arbres complets Ensemble de règles C4.5 déduit de l’arbre de décision un ensemble de règles, facilite son interprétation

183
Exemple : le logiciel Classpad

184
Déduction Orientée Attribut
DBLearn [Han et al. 92] Généraliser une table ou une requête en utilisant la connaissance du domaine Utilisation des tables relationnelles comme structure tuple = formule logique Langage d’apprentissage basé sur SQL Pré-sélection des données par des requêtes Connaissance extraite exprimée sous la forme de règles Connaissance du domaine exprimée : hiérarchie « is-a » de concept hiérarchie de concepts discrets pour les attributs numériques

185
Déduction Orientée Attribut
Principes Pour chaque attribut Ai dans RG (relation obtenue après l’étape de sélection) Tant que nb-valeurs(Ai) > seuil faire substituer Ai avec le concept général fusionner les tuples obtenus (calculer le vote) Tant que nb-tuples(RG) > seuil faire choisir les attributs généralisés fusionner les tuples Fusion de la relation initiale en n relations pour l’apprentissage de règles discriminantes (autant de relations que de classes)
 Tant que nb-valeurs(Ai) > seuil faire. substituer Ai avec le concept général. fusionner les tuples obtenus (calculer le vote) Tant que nb-tuples(RG) > seuil faire. choisir les attributs généralisés. fusionner les tuples. Fusion de la relation initiale en n relations pour l’apprentissage de règles discriminantes (autant de relations que de classes)")
186
Déduction Orientée Attribut
Exemple

187
Déduction Orientée Attribut
Etudiants en relation apprentissage de la règle caractéristique pour Status = « Graduate » en fonction de Name, Major, Birth place, GPA

188
Déduction Orientée Attribut
Règle caractéristique x, graduate(x) (Birth Place(x) Canada GPA(x) excellent) [75%] (Major(x) Science Birth Place(x) Foreign GPA(x) good) [25%]
 (Birth Place(x) Canada GPA(x) excellent) [75%] (Major(x) Science Birth Place(x) Foreign GPA(x) good) [25%]")
189
Déduction Orientée Attribut
Règle discriminante

190
Déduction Orientée Attribut
Règle discriminante (2a) x, graduate(x) (Major(x) Science Birth Place(x) Foreign GPA(x) good) (2b) x, graduate(x) (Major(x) Science Birth Place(x) Foreign GPA(x) good) [100%] (Major(x) Science Birth Place(x) Canada GPA(x) excellent) [44,44%] (Major(x) Art Birth Place(x) Canada GPA(x) excellent) [63,64%]
 x, graduate(x) (Major(x) Science Birth Place(x) Foreign GPA(x) good) (2b) x, graduate(x) (Major(x) Science Birth Place(x) Foreign GPA(x) good) [100%] (Major(x) Science Birth Place(x) Canada GPA(x) excellent) [44,44%] (Major(x) Art Birth Place(x) Canada GPA(x) excellent) [63,64%]")
Présentations similaires










>")




 ROYAUME DU MAROC HAUT COMMISSARIAT AU PLAN DIRECTION DE LA STATISTIQUE.>")




