Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Chapitre 7 Structures covalentes des protéines
Détermination de la structure primaire des protéines A. Coupure des ponts disulfure et séquençage d'Edman B. Réactions d'hydrolyse spécifiques de liaisons peptidiques C. Détermination de la séquence D. Séquençage de protéines par spectrométrie de masse

2
2. Evolution chimique des protéines
A. L'anémie falciforme: influence de la sélection naturelle B. Variations entre espèces de protéines homologues C. Evolution par duplication de gènes 3. Introduction à la bioinformatique A. Bases de données sur les séquences B. Alignements de séquences et construction d'arbres phylogénétiques

3
4. Synthèse chimique de polypeptides
A. Stratégie générale de synthèse B. Couplage des acides aminés

4
Fonctions des protéines
- catalyse (enzymes) - transport (hémoglobine, albumine, transporteurs membranaires) - structure (spectrine) - travail mécanique (actine et myosine) - régulation de la transcription - hormones, récepteurs (insuline, récepteur de l’insuline) - immunoglobulines (IgG, IgM) La fonction d'une protéine ne peut être comprise que par sa structure
 - transport (hémoglobine, albumine, transporteurs membranaires) - structure (spectrine) - travail mécanique (actine et myosine) - régulation de la transcription. - hormones, récepteurs (insuline, récepteur de l’insuline) - immunoglobulines (IgG, IgM) La fonction d une protéine ne peut être comprise que par sa structure.")
5
La description des protéines se fait traditionnellement selon quatre niveaux d'organisation:

6
1 DETERMINATION DE LA STRUCTURE PRIMAIRE DES PROTEINES
Séquençage de la protéine elle-même - clivage d’une protéine en peptides protéases réactifs chimiques - méthode d’Edman cycles de réaction permettant l’enlèvement de l’acide aminé N-terminal - spectrométrie de masse 2. Séquençage de l’ADN (ADNc) codant la protéine
 codant la protéine.")
7
Intérêts de la détermination de la séquence en acides
aminés d'une protéine 1. La séquence d’une protéine est son identité: -indispensable pour comprendre son mécanisme d'action au niveau moléculaire et essentielle pour la détermination de la structure tridimensionnelle 2. Permet d’identifier le gène 3. Comparaisons de séquences: -identification des résidus les plus conservés (les plus importants pour la fonction) -étude de l’évolution -applications cliniques car beaucoup de maladies héréditaires sont dues à des mutations qui modifient la nature d'un acide aminé dans une protéine
 -étude de l’évolution. -applications cliniques car beaucoup de maladies héréditaires sont dues à des mutations qui modifient la nature d un acide aminé dans une protéine.")
8
La première détermination de la séquence complète en acides aminés d'une protéine - l'insuline de boeuf par Fred Sanger en 1953 L'éucidation de la structure primaire a nécessité plus que 10 ans de travail et environ 100g de protéine! Structure primaire de l'insuline bovine. Remarquez les ponts disulfure intra- et intercaténaires

9
A. Coupure des ponts disulfure
Permet la séparation des chaînes polypeptidiques si elles sont liées par ponts disulfure 2. Empêche le conformation native qui pourrait résister l'action des agents protéolytiques

10
Séquençage d’Edman Ne permet pas de d’aller au delà d’une cinquantaine de résidus d'acides aminés Protéine “moyenne” contient 500 acides aminés Nécessité d’au moins deux types de clivages protéolytiques différents, suivis de la purification des fragments

11
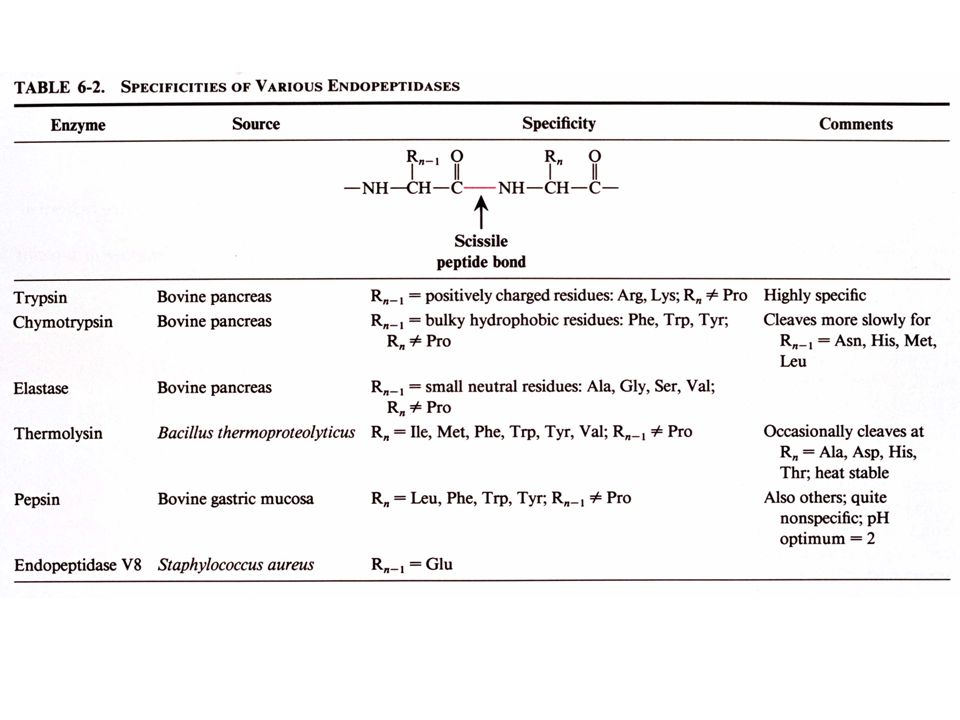
B. Réactions d'hydrolyse spécifiques de liaisons peptidiques
a. La trypsine hydrolyse spécifiquement les liaisons peptidiques après des résidus chargés positivement

13
b. Le bromure de cyanogen (CNBr) hydrolyse spécifiquement les liaisons peptidiques après les résidus méthionine
 hydrolyse spécifiquement les liaisons peptidiques après les résidus méthionine.")
14
C. Détermination de la séquence
L'HPLC en phase inverse permet la séparation des fragments protéolytiques avant leur séquençage par la méthode d'Edman. La séquence du polypeptide original est obtenue en comparant les séquences en acides aminés d'une série de fragments peptidiques avec celles d'une deuxième série dont les sites d'hydrolyse recouvrent ceux de la première série:

15
H3N-_-_-_-_-_-_-_-_-_-_-_-_-_-_-COO
H3N-_-_-_-_-_-_-_-_-_-_-_-_-_-_-COO K F - A - M - K K - F - A - M Q - M - K D - I - K - Q - M G - M - D - I - K Y - R - G - M Y - R Le CNBr hydrolyse spécifiquement après Met i.e M - X La trypsine hydrolyse les liaisons peptidiques après des résidus chargés positivement (K, R)
")
16
D. Séquençage de polypeptides par spectrométrie de masse
La spectrométrie de masse (MS) est devenue une technique importante pour caractériser et séquencer des protéines. Cette technique permet de mesurer de façon précise le rapport masse/charge (m/z) des ions en phase gazeuse: Ion source Mass analyzer Detector Ion generation Ion separation Ion detection F. Lottspeich and H. Zorbas, Bioanalytik 1998, Spektrum Akad. Verlag Méthodes de production d'ions en phase gazeuse:
 est devenue une technique importante pour caractériser et séquencer des protéines. Cette technique permet de mesurer de façon précise le rapport masse/charge (m/z) des ions en phase gazeuse: Ion source. Mass analyzer. Detector. Ion generation. Ion separation. Ion detection. F. Lottspeich and H. Zorbas, Bioanalytik 1998, Spektrum Akad. Verlag. Méthodes de production d ions en phase gazeuse:")
17
1. L'ionisation par electrospray (ESI-MS)
Le peptide en solution dans un solvant organique est pulverisé par un étroit capillaire maintenu à un haut voltage (4000 V), formant de tès fines goutlettes chargées d'où le solvant s'évapore rapidement:
, formant de tès fines goutlettes chargées d où le solvant s évapore rapidement:")
18
2. La désorption/ionisation au laser assistée par une matrice (''Matrix-Assisted Laser Desorption/Ionisation''): MALDI Le peptide est enrobé dans une matrice cristalline et irradié par de courtes (ns) et intenses impulsions d'un rayon laser d'une longueur d'onde telle qu'elle est absorbée par la matrice. L'énergie absorbée par la matrice éjecte de sa surface les peptides intacts chargés:
 et intenses impulsions d un rayon laser d une longueur d onde telle qu elle est absorbée par la matrice. L énergie absorbée par la matrice éjecte de sa surface les peptides intacts chargés:")
19
masse [M + nH+] = (m/z x n) - n
m/z: rapport masse/charge VALEACVQAR Masse = 1059,25 Da H+ Masse = 1060,25 Da m/z = 1060,25/1 = 1060,25 Masse = 1061,25 Da m/z = 1061,25/2 = 530,63 masse [M + nH+] = (m/z x n) - n
![masse [M + nH+] = (m/z x n) - n](http://slideplayer.fr/slide/1592225/5/images/19/masse+%5BM+%2B+nH%2B%5D+%3D+%28m%2Fz+x+n%29+-+n.jpg "m/z: rapport masse/charge. VALEACVQAR. Masse = 1059,25 Da. H+ Masse = 1060,25 Da. m/z = 1060,25/1. = 1060,25. Masse = 1061,25 Da. m/z = 1061,25/2. = 530,63. masse [M + nH+] = (m/z x n) - n.")
20
Spectre ESI-MS du cytochrome c humain
(M+10H)10+ (M+9H)9+ (M+8H)8+ (M+14H)14+ (M+15H)15+ (M+7H)7+ (M+16H)16+ M = Da
10+ (M+9H)9+ (M+8H)8+ (M+14H)14+ (M+15H)15+ (M+7H)7+ (M+16H)16+ M = Da.")
21
a. Séquençage de peptides par spectrométrie de masse
On peut séquencer des petits peptides (<25 résidus) par spectrométrie de masse en tandem (MS/MS)
 par spectrométrie de masse en tandem (MS/MS)")
22
Amino Acid Residue Masses
Monoisotopic Average Glycine Gly G Alanine Ala A Serine Ser S Proline Pro P Valine Val V Threonine Thr T Cysteine Cys C Isoleucine Ile I Leucine Leu L Asparagine Asn N Aspartic Acid Asp D Glutamine Gln Q Lysine Lys K Glutamic Acid Glu E Methionine Met M Histidine His H Phenylalanine Phe F Arginine Arg R Tyrosine Tyr Y Tryptophan Try W Carboxyamidomethyl Cysteine Carboxymethylcysteine

23
T E S T P E P T I D E+ T E S T + P E P T I D E+ b 1 T+ b 2 TE+ b 3 TES+ b 4 TEST+ b 5 TESTP+ b 6 TESTPE+ b 7 TESTPEP+ b 8 TESTPEPT+ b 9 TESTPEPTI+ b10 TESTPEPTID+ b11 TESTPEPTIDE+ - H2O TESTPEPTIDE+ y11 ESTPEPTIDE y10 STPEPTIDE y 9 TPEPTIDE y 8 PEPTIDE y 7 EPTIDE y 6 PTIDE y 5 TIDE y 4 IDE y 3 DE y 2 E y 1 b-ions y-ions La séquence complète du peptide est ainsi elucidée. La fiabilité de la MS a encore été améliorée par la comparaison informatique du spectre de masse mesuré avec des spectres de masses prédits (''in silico'') à partir de séquences génomiques dans des bases de données
 à partir de séquences génomiques dans des bases de données.")
24
400 800 1200 1600 m/z 100 Relative Abundance Y12 1299 Y6 689 Y4 475 Y122+ 650 B10 1102 B6/Y132+ 706 Y7 803 B12 1317 Y8 902 B3 380 B4 493 B9 990 B11 1204 Y13 1412 Y5 588 Y11 1202 Y10 1087 NL 5.29E6 Base peak I/L T V QG D P Spectre de masse en tandem d'un ion peptidique doublement chargé - séquence SYELPDGQVITIGNER

25
Avantages et inconvénients des différentes méthodes
Edman Spectrométrie de masse Séquençage de l’ADN Avantages - Excellent pour 20 acides aminés standards - OK pour longs peptides - Rapidité relative - OK pour certaines modifications post-traductionnelles Rapidité Inconvénients - Lenteur/lourdeur/coût - Beaucoup modifications post- traductionnelles non détectées - Ambiguïté Ile/leu; Gln/Lys - Difficile avec longs peptides - Ignorance des modifications - Erreurs de phase de lecture

26
2 EVOLUTION CHIMIQUE DES PROTEINES
Les changements au cours de l'évolution, dus à des mutations qui se font au hasard, modifient souvent la structure primaire d'une protéine. Une mutation dans une protéine, si elle doit se propager, doit augmenter la probabilité de survie. En de rares occasions, une mutation défavorable améliore l'adaptation de son hôte à son environnement naturel:

27
A. L'anémie falciforme: influence de la sélection naturelle
L'hémoglobine, un tetramère 22, se trouve dans les érythrocytes. Les érythrocytes, qui se présentent normalement sous formes de disques souples biconcaves, doivent se comprimer dans les capillaires Chez les individus atteints de la maladie héréditaire dite anémie falciforme (''en faucille''), les érythrocytes ont une forme en croissant et sont rigides, ce qui gêne leur passage dans les capillaires
, les érythrocytes ont une forme en croissant et sont rigides, ce qui gêne leur passage dans les capillaires.")
28
a. L'anémie falciforme est une maladie moléculaire
En 1945, Linus Pauling a postulé que l'anémie falciforme est due à la présence d'une hémoglobine mutante. Par des études électrophorétiques, il a montré que l'hémoglobine normale (HbA) a une charge anionique plus négative que l'hémoglobine de l'anémie falciforme (HbS): Cette différence vient du remplacement du Glu 6 de HbA par une Val dans HbS (Glu 6 Val)
 a une charge anionique plus négative que l hémoglobine de l anémie falciforme (HbS): Cette différence vient du remplacement du Glu 6 de HbA par une Val dans HbS. (Glu 6 Val)")
29
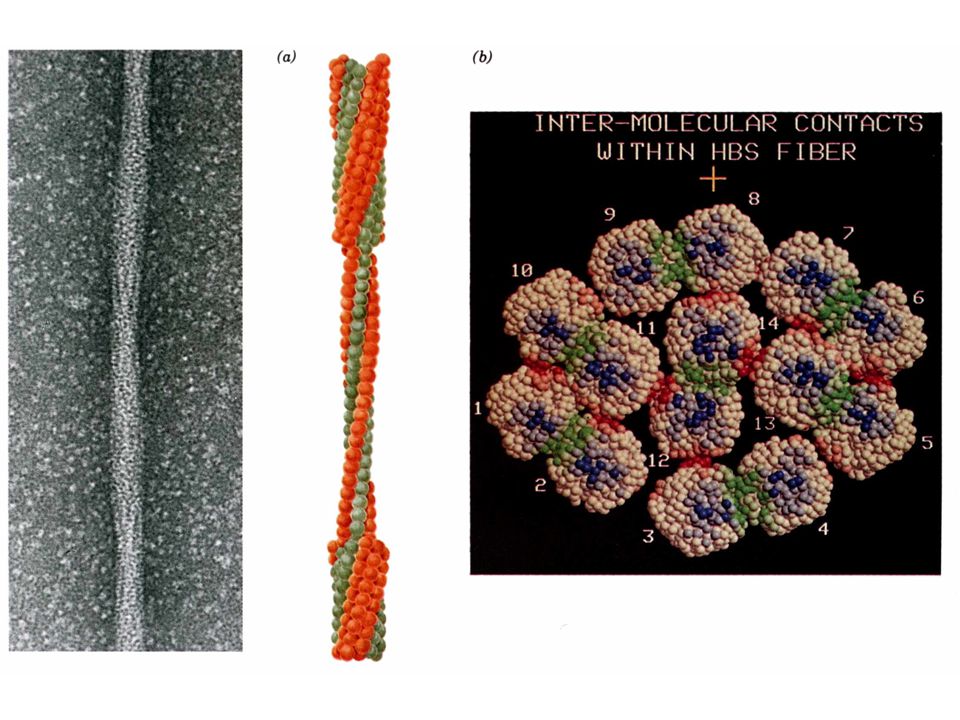
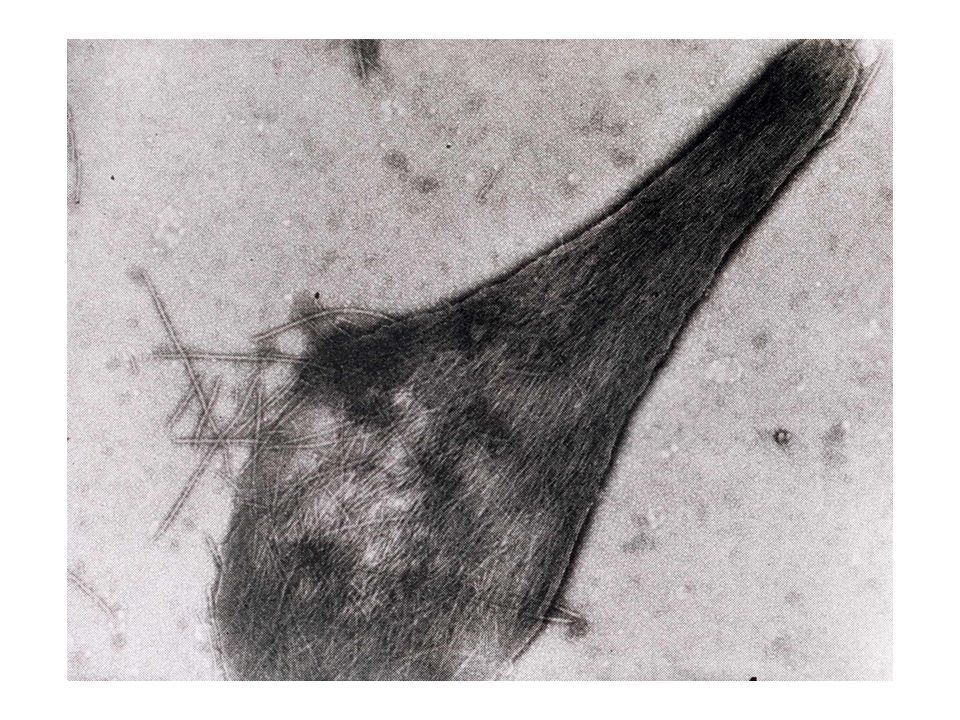
Cette mutation provoque l'agrégation de l'HbS désoxygénée en filaments suffisamment volumineux et rigides pour déformer les érythrocytes:

32
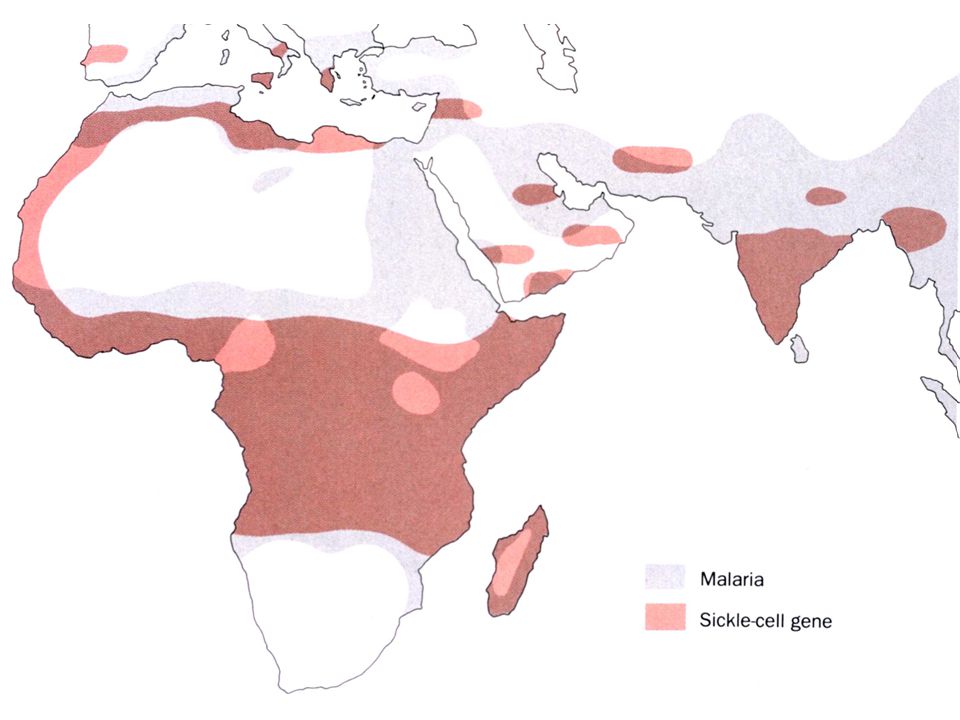
b. Le ''trait'' anémie falciforme confère la résistance à la malaria
Mutations du gène d’une des deux globines entraînant: Modification de l’affinité de Hb pour O2 Anémie falciforme Maladie récessive Mutations des sous-unités ß (Gluß6 en Val) de l'HbS Polymérisation de la désoxy-hémoglobine Déformation des globules rouges et hémolyse Hétérozygotes: non malades, mais porteurs du “trait” Fréquence très élevée dans région d’endémie de malaria Avantage des hétérozygotes (résistance relative à malaria) Au premier stade de l'infection, les érythrocytes infectés sont retires de la circulation par la rate. Aux stades ultérieurs, la forme en faucille désorganise le parasite mécaniquement et/ou métaboliquement
 de l HbS. Polymérisation de la désoxy-hémoglobine. Déformation des globules rouges et hémolyse. Hétérozygotes: non malades, mais porteurs du trait Fréquence très élevée dans région d’endémie de malaria. Avantage des hétérozygotes (résistance relative à malaria) Au premier stade de l infection, les érythrocytes infectés sont retires de la circulation par la rate. Aux stades ultérieurs, la forme en faucille désorganise le parasite mécaniquement et/ou métaboliquement.")
34
B. Variations entre espèces de protéines homologues: effets de la dérive naturelle
Les structures primaires d'une protéine donnée d'espèces voisines sont très semblables Une protéine bien adapté à sa fonction continue néanmoins à évoluer La dérive naturelle - modification d'une protéine par mutation aléatoire avec le temps sans affecter significativement sa fonction La comparaison des structures primaires de protéines homologues indique quels sont des acides aminés qui sont indispensables à sa fonction, ceux qui ont moins d'importance, et ceux qui n'ont pas de rôle spécifique

35
Résidu invariant - acide aminé seul capable d'assurer un rôle essentiel à un endroit particulier de la séquence en acides aminés d'une série de protéines homologues - dû à ses propriétés chimiques/structurelles particulières Substitutions conservatrices - position de la séquence en acides aminés occupée par des résidus qui ont des propriétés physico-chimiques similaires (par exemple ceux à propriétés acides: Asp et Glu) Position hypervariable - beaucoup de résidus d'acides aminés différents peuvent être tolérés en certaines positions
 Position hypervariable - beaucoup de résidus d acides aminés différents peuvent être tolérés en certaines positions.")
36
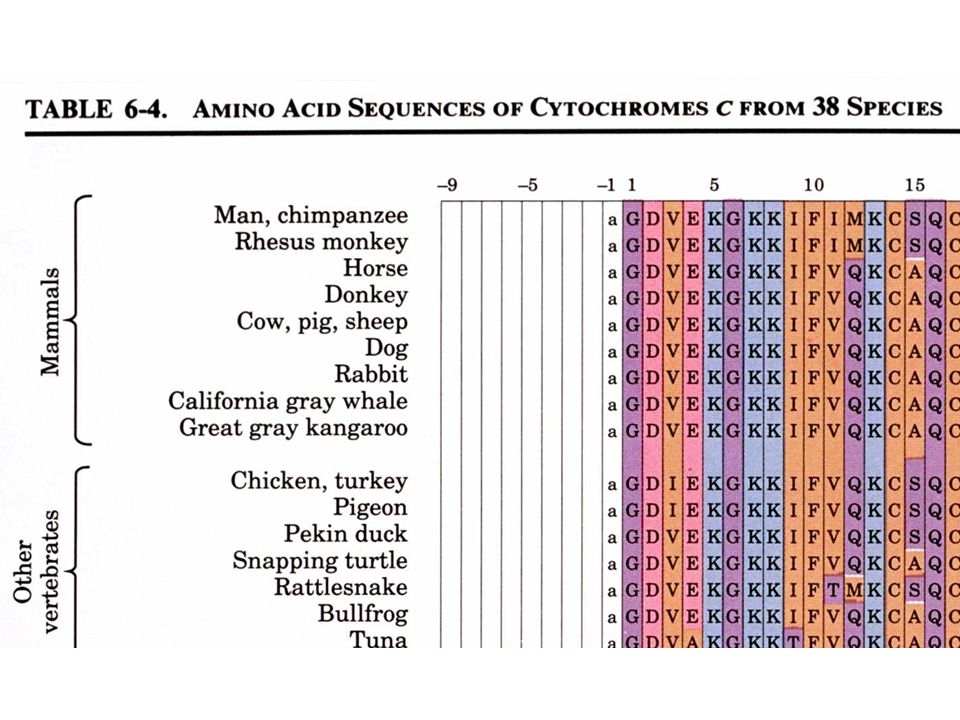
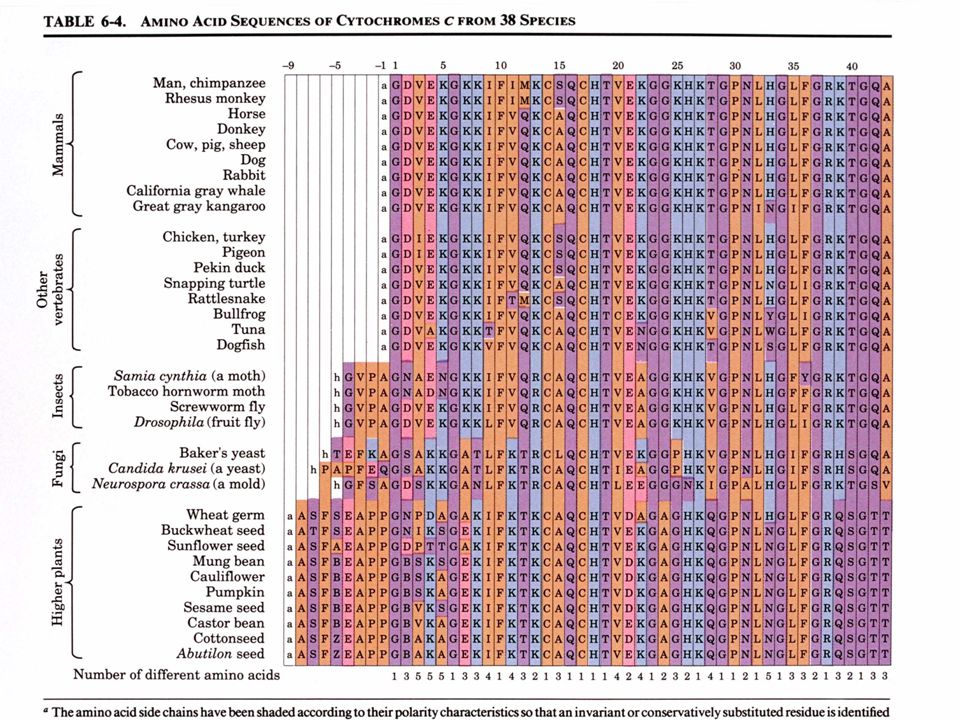
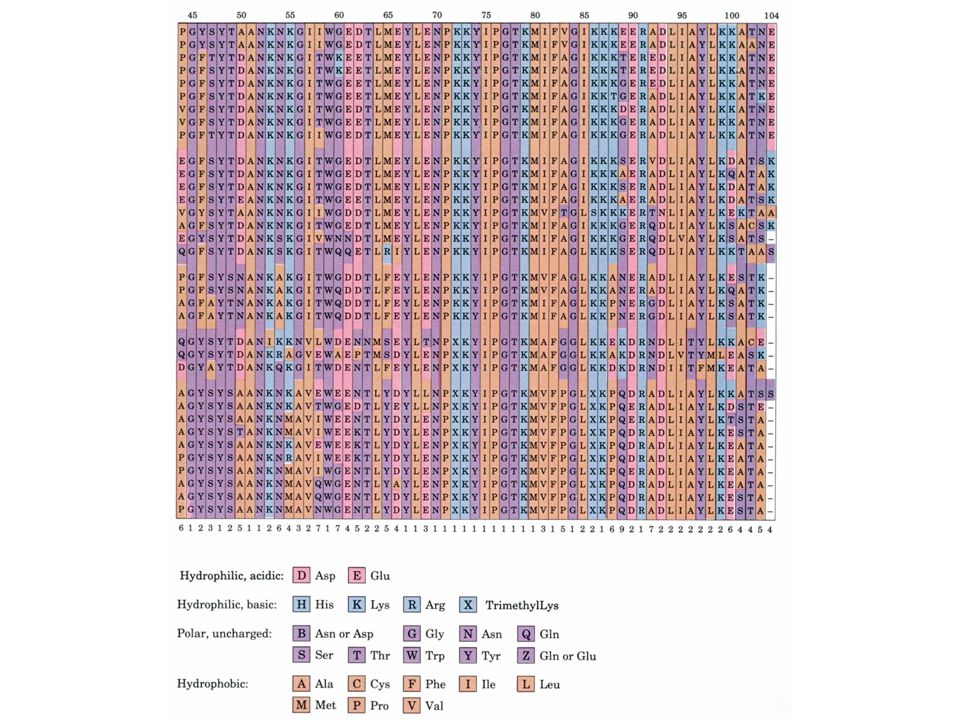
a. Le cytochrome c est une protéine bien adapté
Etudions la structure primaire d'une protéine eucaryote pratiquement universelle, le cytochrome c: Une seule chaîne polypeptidique de résidus Se trouve dans la mitochondrie comme composant de la chaîne de transport des électrons b. La comparaison des séquences protéiques donne des informations taxonomiques Les séquences provenant de 38 eucaryotes sont alignées de sorte à maximaliser les similitudes entre les résidus alignés verticalement Le cytochrome c est une protéine à évolution conservatrice - 38 résidus sur 105 sont invariants et la plupart des autres résidus sont des substitutions conservatrices

40
Le moyen le plus facile de comparer les différences évolutives entre protéines homologues consiste à compter les différences en acides aminés entre ces protéines. L'ordre de ces différences est en accord avec la taxonomie classique Homme Singe rhésus Lapin Poulet Pingouin Serpent à sonnettes Thon Blé Saccharomyces cerevisiae Candida crusei 1 0 8 0 Saccharomyces cerevisiae Serpent à sonnettes Matrice des différences en acides aminés pour 10 séquences de cytochrome c d'espèces différentes

41
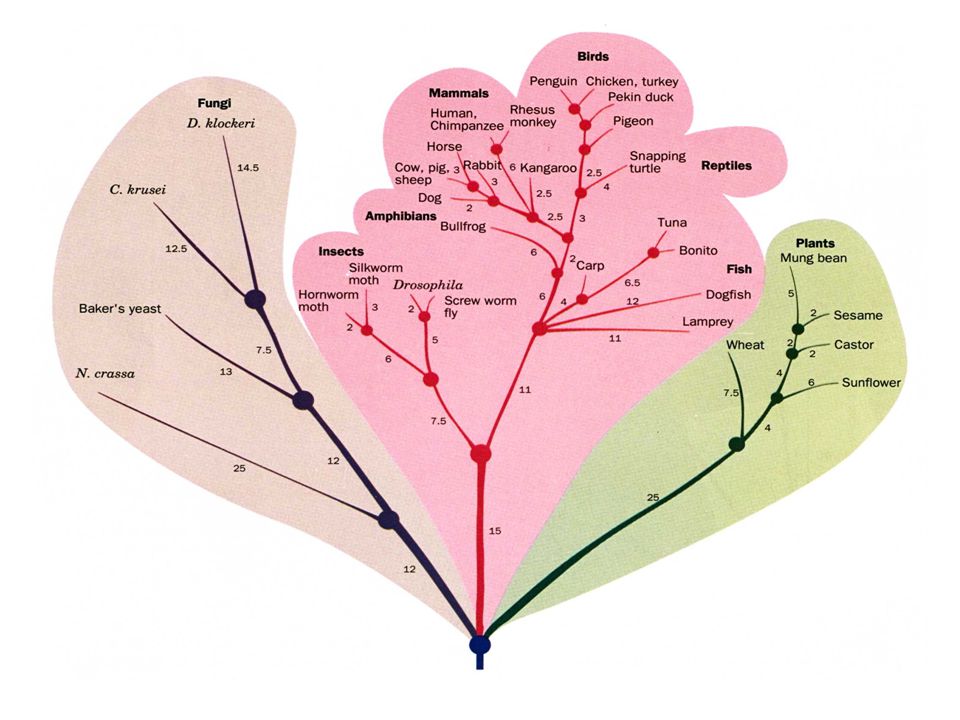
L'analyse par ordinateur des données de la matrice des différences permet de construire un arbre phylogénétique qui indique les relations ancestrales entre les organismes qui produisent ces protéines Chaque point de branchement de l'arbre indique l'existence probable d'un ancêtre commun à tous les organismes qui se trouvent au-dessus Les distances évolutives relatives qui séparent deux points de branchement voisins sont exprimées en nombre de différences en acides aminés pour 100 résidus de la protéine (''Percentage of Accepted pont Mutations'' ou unités PAM). Ceci permet de mesurer quantitativement le degré de relation entre les espèces, ce que la taxonomie classique ne peut pas faire
. Ceci permet de mesurer quantitativement le degré de relation entre les espèces, ce que la taxonomie classique ne peut pas faire.")
43
c. Les protéines évoluent à des vitesses qui leur sont propres
On peut porter en graphique les différences moyennes en unités PAM des séquences en acides aminés des deux côtés d'un point de branchement en fonction du temps, selon des données paléontologiques, depuis que les espèces correspondantes ont divergé de leur ancêtre commun En comparant quatre protéines non apparentées: Fibrinopeptides: peptides libérés lors de la conversion du fibrinogène en fibrine (pas de fonction propre) Hémoglobine: protéine transporteuse d’O2, libre dans le globule rouge Cytochrome c: transporteur d’électrons, qui doit interagir avec complexes III et IV de la chaîne respiratoire Histone H4: protéine servant à “l’emballage” de l’ADN, interagissant avec d’autres histones (octamère) et avec ADN
 Hémoglobine: protéine transporteuse d’O2, libre dans le globule rouge. Cytochrome c: transporteur d’électrons, qui doit interagir avec complexes. III et IV de la chaîne respiratoire. Histone H4: protéine servant à l’emballage de l’ADN, interagissant avec d’autres histones (octamère) et avec ADN.")
44
La vitesse d'évolution de chaque protéine est inversement proportionnelle à la pente de sa droite

45
Cytochrome c: transporteur d’électrons qui doit interagir avec des complexes de grande taille sur une grande partie de sa surface; tout changement par mutation affectera très vraisemblablement ces interactions Histone H4: protéine servant à “l’emballage” de l’ADN, interagissant avec d’autres histones (octamère) et avec ADN. Son rôle essentiel dans le compactage de l'ADN dans la chromatine la rend tout à fait intolérante à tout changement mutationnel
 et avec ADN. Son rôle essentiel dans le compactage de l ADN dans la chromatine la rend tout à fait intolérante à tout changement mutationnel.")
46
C. Evolution par duplication de gènes
La plupart des protéines ont des similitudes de séquences très importantes avec d'autres protéines d'un même organisme. De telles protéines se sont formées par duplication de gène. La duplication de gène est un moyen d'évolution particulièrement efficace - un des gènes dupliqués peut évoluer vers une nouvelle fonction par sélection naturelle tandis que son homologue continue sa fonction ancestrale indispensable Exemple - les protéines de la famille globine: Les séquences des sous unités et de l'hémoglobine tétramérique, 22, et de la chaîne de la myoglobine monomérique sont très semblables La globine ancestrale fonctionnait sans doute simplement comme une protéine de stockage d'oxygène La duplication du gène a permis l'évolution vers une hémoglobine monomérique avec une affinité faible pour l'oxygène pour pouvoir transférer l'oxygène à la myoglobine La duplication de la chaîne a donné naissance à la chaîne et la structure tétramérique qui a fortement améliorée sa capacité à transporter l'oxygène

48
Exemple - les protéines de la famille globine:
5. L'hémoglobine foetale est un tetramère a2, par duplication du gène en, avec une plus grande affinité pour l'oxygène que l'hémoglobine a2 maternelle On trouve encore une hémoglobine monomérique chez la lamproie qui a conservé sa morphologie proche de l'anguille depuis > 400 millions d'années:

49
Les protéines homologues appartenant à un même organisme, et les gènes qui les codent, sont dits ''paralogues''. Les chaînes globines , , et la myoglobine humaine sont donc des paralogues Les protéines et gènes homologues d'organismes différentes et issus de la divergence des espèces (les différents cytochrome c, par exemple) sont dits ''orthologues''
 sont dits orthologues")
50
3 INTRODUCTION A LA BIOINFORMATIQUE
La profusion de séquences protéiques à partir de projets de séquençage génomiques et la disponibilité de données structurales au cours des dernières années a donné naissance à la bioinformatique - analyse de séquences et de structures tridimensionnelles par ordinateur Bases de données sur les séquences On recherche les séquences d'intérêt dans une banque de données via le Web, par exemple SWISS-PROT ( 2. On peut rechercher des séquences homologues en utilisant l'algorithme ''BLAST'' (Basic Local Alignment Search Tool) -
 -")
51
B. Alignements de séquences et construction d'arbres phylogénétiques
On fait un alignement de séquences multiples en utilisant le programme CLUSTALW ( Les séquences sont envoyées en format ''FASTA''. Cet algorithme permet la construction d'un arbre phylogénétique à partir d'une matrice de différences en acides aminés

52
>AAPK2_MOUSE MAEKQKHDGRVKIGHYVLGDTLGVGTFGKVKIGEHQLTGHKVAVKILNRQKIRSLDVVGKIKREIQNLKLFRHPHIIKLYQVISTPTDFFMVMEYVSGGELFDYICKHGRVEEVEARRLFQQILSAVDYCHRHMVVHRDLKPENVLLDAQMNAKIADFGLSNMMSDGEFLRTSCGSPNYAAPEVISGRLYAGPEVDIWSCGVILYALLCGTLPFDDEHVPTLFKKIRGGVFYIPDYLNRSVATLLMHMLQVDPLKRATIKDIREHEWFKQDLPSYLFPEDPSYDANVIVDEAVKEVCEKFECTESEVMNSLYSGDPQDQLAVAYHLIIDNRRIMNQASEFYLASSPPSGSFMDDSAMHIPPGLKPHPERMPPLIADSPKARCPLDALNTTKPKSLAVKKAKWHLGIRSQSKACDIMAEVYRAMKQLGFEWKVVNAYHLRVRRKNPVTGNYVKMSLQLYLVDSRSYLLDFKSIDDEVVEQRSGSSTPQRSCSAAGLHRARSSFDSSTAENHSLSGSLTGSLTGSTLSSASPRLGSHTMDFFEMCASLITALAR >AAPK1_DANIO MATDKQKHEGRVKIGHYILGDTLGVGTFGKVKVGQHELTKHQVAVKILNRQKIRSLDVVGKIRREIQNLKLFRHPHIIKLYQVISTPTDIFMVMEYVSGGELFDYICKNGKLDEKESRRLFQQIISGVDYCHRHMVVHRDLKPENVLLDAHMNAKIADFGLSNMMSDGEFLRTSCGSPNYAAPEVISGRLYAGPEVDIWSSGVILYALLCGTLPFDDDHVPTLFKKICDGIFFTPQYLNPSVISLLKHMLQVDPMKRATIKEIREDEWFKQDLPKYLFPEDAAYSSNMIDEEALKEVCEKCECTEEEVLNCLYSRNHQDPLAVAYHLIIDNRRIMSEAKDFYLASSPPDSFLDDLPAHHSAKVHPERVPFLVAESQPRPRHTLDELNPQKSKHLGVRRAKWHLGIRSQSRPNDIMSEVCRAMKQLDYEWKVVNPYYLRVRRKNPVTGMHTKMSLQLYQVDSRTYLLDFRSIDDDMMEVKSGTATPHRSGSVGNYRTTLKNDKSEKNECEDAAKGEASAPSTPPISASKVAEGSLASSLTSSVDSTGGEILPRPGSHTIEFFEMCANLIKLLAR >AAPK2_CAENORH MPPSGRFDRTIALAGTGHLKIGNFVIKETIGKGAFGAVKRGTHIQTGYDVAIKILNRGRMKGLGTVNKTRNEIDNLQKLTHPHITRLFRVISTPSDIFLVMELVSGGELFSYITRKGALPIRESRRYFQQIISGVSYCHNHMIVHRDLKPENLLLDANKNIKIADFGLSNYMTDGDLLSTACGSPNYAAPELISNKLYVGPEVDPWSCGVILYAMLCGTLPFDDQNVPTLFAKIKSGRYTVPYSMEKQAADLISTMLQVDPVKRADVKRIVNHSWFHIDLPYYLFPECENESSIVDIDVVQSVAEKFDVKEEDVTGALLAEDHHHFLCIAYRLEVNHKRNADESSQKAMEDFWEIGKTMKMGSTSLPVGATTKTNVGRKILEGLKKEQKKLTWNLGIRACLDPVETMKHVFLSLKSVDMEWKVLSMYHIIVRSKPTPINPDPVKVSLQLFALDKKENNKGYLLDFKGLTEDEEAVPPSRCRSRAASVSVTLAKSKSDLNGNSSKVPMSPLSPMSPISPSVNIPKVRVDDADASLKSSLNSSIYMADIENSMESLDEVSTQSSEPEAPIRSQTMEFFATCHIIMQALLAE

53
1 2 FUNGI INSECTS C. elegans AAK1 MAMMALS, BIRDS, AMPHIBIANS, FISH
ALGAE, PLANTS PROTISTS INSECTS SEA ANEMONE C. elegans AAK1 MAMMALS, BIRDS, AMPHIBIANS, FISH 1 2 C. elegans AAK2 ARTEMIA

54
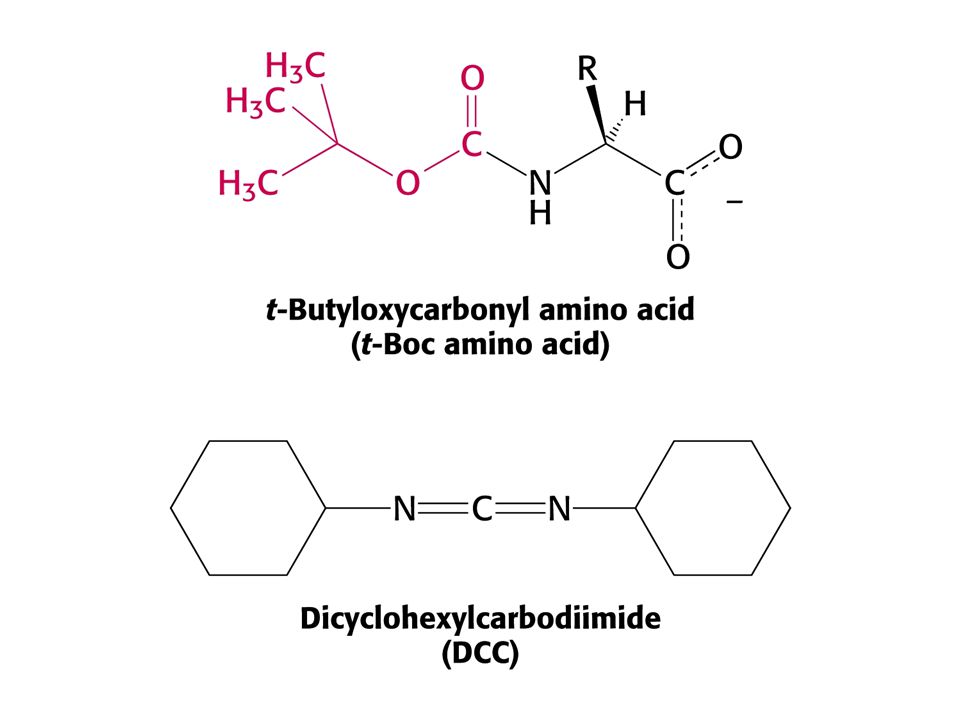
4. Synthèse chimique de polypeptides A. Stratégie générale de synthèse
Suite des réactions pour la synthèse d'un polypeptide en phase solide - le symbole Mn correspond au n ième résidu d'acide aminé qui doit être ajouté. Les polypeptides sont synthétisés par addition d'acides aminés à l'extrémité N-terminale. Sn est le groupement protecteur de sa chaîne latérale. Y symbolise le protecteur du groupe amine. Le couplage utilise une carbodiimide (comme le dicyclohexylcarbodiimide ou DCCD)
")
56
B. Couplage des acides aminés

Présentations similaires



 Obtention de l’ADN recombinant>")
















