Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Filtrage de Kalman Mise en équation Dans le cas de la poursuite + -
Mesure réelle linéarisation Donnée « mesurée » Matrice de transition Matrice de mesure commande + - + Prédiction de la mesure Vecteur d’état Erreur de prédiction

2
Extension au cas d’une transition non linéaire
Commande (entrée) u(t) y(t) sortie (mesure) B + C + x(t) état bruit sur l’entrée w(t) A v(t) bruit sur les mesures z-1 x(t-1) mémoire (retard) x(t)=F(x(t-1))+B.u(t) (transition) F(x(t-1)) y(t)=C.x(t)+D.u(t) (mesure) remplacement de la matrice de transition par une non linéarité comme la matrice A est remplacée par une expression non linéaire il faut reprendre le calcul de l’expression intermédiaire de P qui n’est plus de la forme a p a transpose + r Il faut modifier l’expression de la matrice de covariance ! ce n’est plus (A . P0 .AT + Rw)
 u(t) y(t) sortie. (mesure) B. + C. + x(t) état. bruit sur l’entrée. w(t) A. v(t) bruit sur les mesures. z-1. x(t-1) mémoire. (retard) x(t)=F(x(t-1))+B.u(t) (transition) F(x(t-1)) y(t)=C.x(t)+D.u(t) (mesure) remplacement de. la matrice de transition. par une non linéarité. comme la matrice A est remplacée par une expression non linéaire. il faut reprendre le calcul de l’expression intermédiaire de P qui n’est plus de la forme a p a transpose + r. Il faut modifier l’expression de la matrice de covariance ! ce n’est plus (A . P0 .AT + Rw)")
3
Systèmes non linéaires : transformations non linéaires des
densités de probabilités et des matrices de covariance non linéarité sans détailler la méthode on peut faire la remarque suivante on suppose qu’on connaît la matrice de covariance de x(t) si on suppose que x(t) est un vecteur gaussien caractérisé par cette matrice de covariance on peut déduire l’effet de la non linéarité sur cette densité de probabilité et déduire les moments du deuxième ordre et donc la covariance de la sortie de la non linéarité Effet d’une transformation non linéaire sur la densité de probabilité d’un vecteur aléatoire : On peut déduire la covariance de la sortie en fonction de celle de l’entrée « Unscented Kalman Filter »
 si on suppose que x(t) est un vecteur gaussien caractérisé par cette matrice de covariance. on peut déduire l’effet de la non linéarité sur cette densité de probabilité. et déduire les moments du deuxième ordre et donc la covariance de la sortie de la non linéarité. Effet d’une transformation non linéaire sur la densité de probabilité d’un vecteur aléatoire : On peut déduire la covariance de la sortie en fonction de celle de l’entrée. « Unscented Kalman Filter »")
4
« Unscented Kalman Filter »
Julier, S.J.; Uhlmann, J.K. (1997). "A new extension of the Kalman filter to nonlinear systems" - la densité de probabilité de l’entrée de la fonction non linéaire est connue (par exemple représentée par quelques données spécifiques) on calcule l’effet de la non linéarité sur cette densité on en déduit les caractéristiques statistiques du premier et du deuxième ordre (moyenne, covariance) qui sont utilisées dans la mise à jour du filtre de Kalman au lieu des équations classiques de transition non linéarité
. A new extension of the Kalman filter to nonlinear systems - la densité de probabilité de l’entrée de la fonction non linéaire. est connue (par exemple représentée par quelques données spécifiques) on calcule l’effet de la non linéarité sur cette densité. on en déduit les caractéristiques statistiques du premier et du deuxième. ordre (moyenne, covariance) qui sont utilisées dans la mise à jour du. filtre de Kalman au lieu des équations classiques de transition. non. linéarité.")
5
Méthodes variées d’identification et d’estimation de paramètres
difficultés pour formaliser un modèle analytique simple essayer tout de même de modéliser les données mesurées dans des problèmes complexes (par exemple suivi de plusieurs cibles) moins rigoureuses modèle moins précis ou inexistant nécessitant une grande puissance de calcul permettant d’aborder des problèmes plus complexes filtres particulaires réseaux neuronaux algo. génétiques recuit simulé, etc. ...
 moins rigoureuses. modèle moins précis ou inexistant. nécessitant une grande puissance de calcul. permettant d’aborder des problèmes plus complexes. filtres particulaires. réseaux neuronaux. algo. génétiques. recuit simulé, etc. ...")
6
- on multiplie les particules ainsi sélectionnées
illustration élémentaire des filtres particulaires utiliser pleinement la puissance de calcul des ordinateurs pour contourner les limitation des approches algébriques - on se permet de faire un grand nombre d’essais (particules) traduisant les évolutions possibles du système étudié puis on sélectionne parmi ceux-là ceux qui correspondent assez bien aux mesures effectuées sur le système étudié (on élimine celles qui ne correspondent pas aux mesures) - on multiplie les particules ainsi sélectionnées on réitère le processus jusqu’à ce qu’il converge vers une caractérisation suffisamment précise d’actualité en recherche en robotique
 traduisant les évolutions possibles du système étudié. puis on sélectionne parmi ceux-là ceux qui correspondent assez bien. aux mesures effectuées sur le système étudié. (on élimine celles qui ne correspondent pas aux mesures) - on multiplie les particules ainsi sélectionnées. on réitère le processus jusqu’à ce qu’il converge. vers une caractérisation suffisamment précise. d’actualité en recherche en robotique.")
7
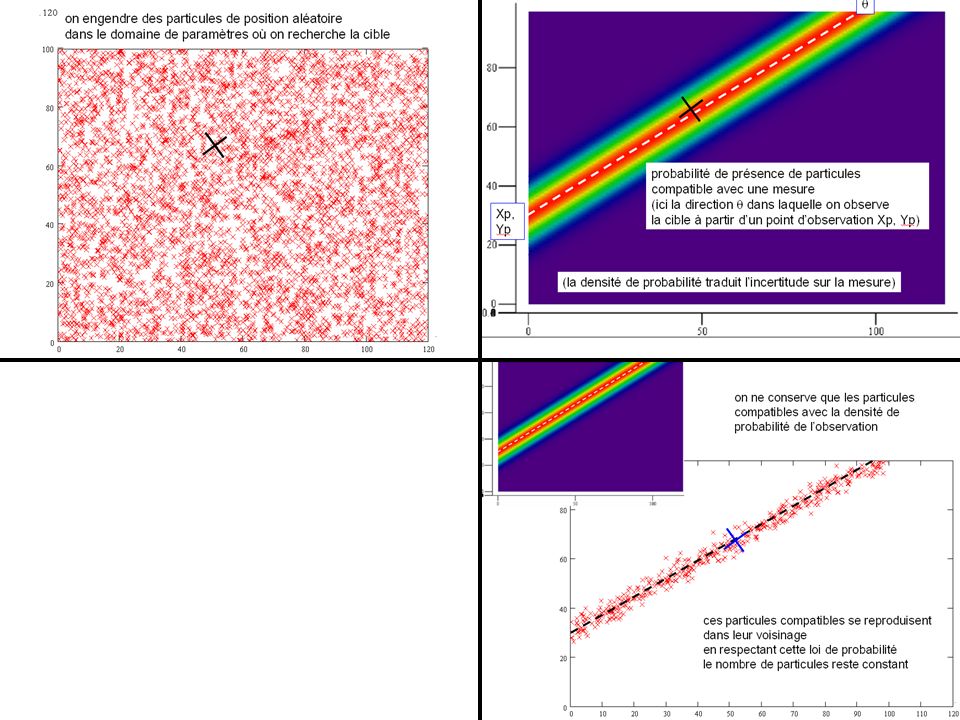
exemple simple : recherche de la position d’une cible fixe par un observateur
qui se déplace et mesure l’angle sous laquelle il voit cette cible observateur XP,YP Nord angle mesuré q cible fixe x0,y0 simuler de nombreux essais concernant la position de la cible , et ne conserver que ceux qui sont suffisamment probables, compte tenu des mesures d’angles réalisées

8
on génère des particules de position aléatoire
dans le domaine de paramètres où on recherche la cible

9
q probabilité de présence de particules compatible avec une mesure (ici la direction q dans laquelle on observe la cible à partir d’un point d’observation Xp, Yp) Xp, Yp (la densité de probabilité traduit l’incertitude sur la mesure)
 Xp, Yp. (la densité de probabilité traduit l’incertitude sur la mesure)")
10
on ne conserve que les particules
compatibles avec la densité de probabilité de l’observation ces particules compatibles se reproduisent dans leur voisinage en respectant cette loi de probabilité le nombre de particules reste constant

11
q on réitère l’opération (on refait une nouvelle mesure d’angle à partir d’un point d’observation différent) les particules acceptables doivent vérifier la loi de probabilité correspondante Xp, Yp
 les particules acceptables doivent vérifier. la loi de probabilité correspondante. Xp, Yp.")
12
la position de la cible doit être compatible avec les deux mesures
(si elles sont indépendantes la densité de probabilité de la position de la cible sera le produit des deux densités précédentes)
")
13
en réitérant l’opération, on sélectionne
les particules compatibles avec la loi de probabilité de la nouvelle mesure elles se multiplient avec une certaine variabilité

14
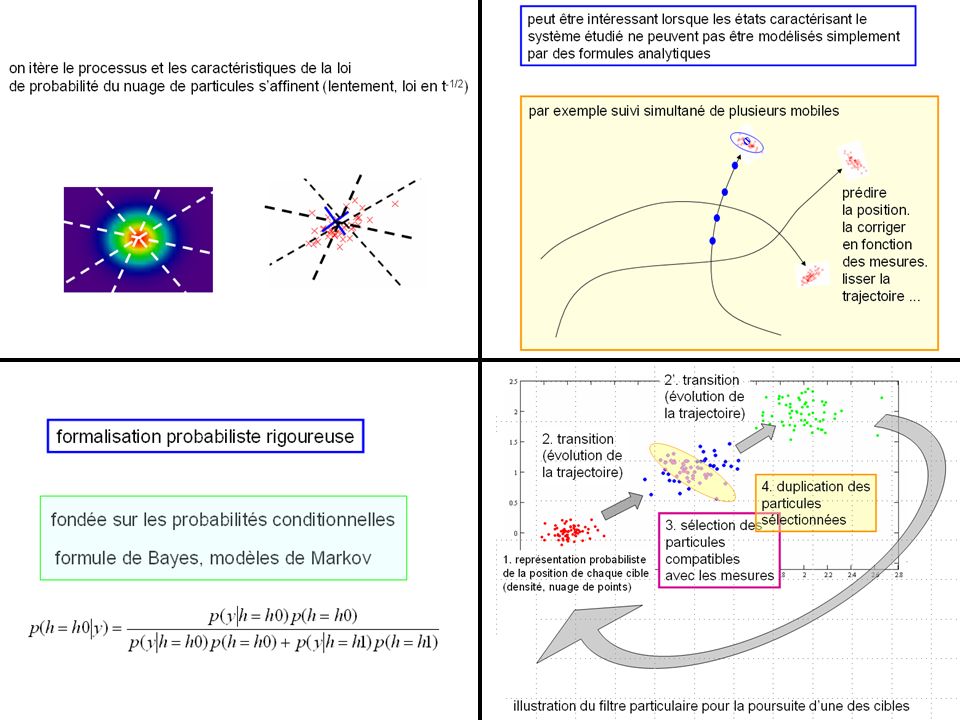
on itère le processus et les caractéristiques de la loi
de probabilité du nuage de particules s’affinent (lentement, convergence en t-1/2)
")
15
formalisation probabiliste rigoureuse
fondée sur les probabilités conditionnelles formule de Bayes, modèles de Markov

16
peut être intéressant lorsque les états caractérisant le système étudié ne peuvent pas être modélisés simplement par des formules analytiques par exemple suivi simultané de plusieurs mobiles prédire la position. la corriger en fonction des mesures. lisser la trajectoire ...

17
illustration du filtre particulaire pour la poursuite d’une des cibles
2’. transition (évolution de la trajectoire) 2. transition (évolution de la trajectoire) 4. duplication des particules sélectionnées 3. sélection des particules compatibles avec les mesures 1. représentation probabiliste de la position de chaque cible (densité, nuage de points) illustration du filtre particulaire pour la poursuite d’une des cibles
 2. transition. (évolution de. la trajectoire) 4. duplication des. particules. sélectionnées. 3. sélection des. particules. compatibles. avec les mesures. 1. représentation probabiliste. de la position de chaque cible. (densité, nuage de points) illustration du filtre particulaire pour la poursuite d’une des cibles.")
18
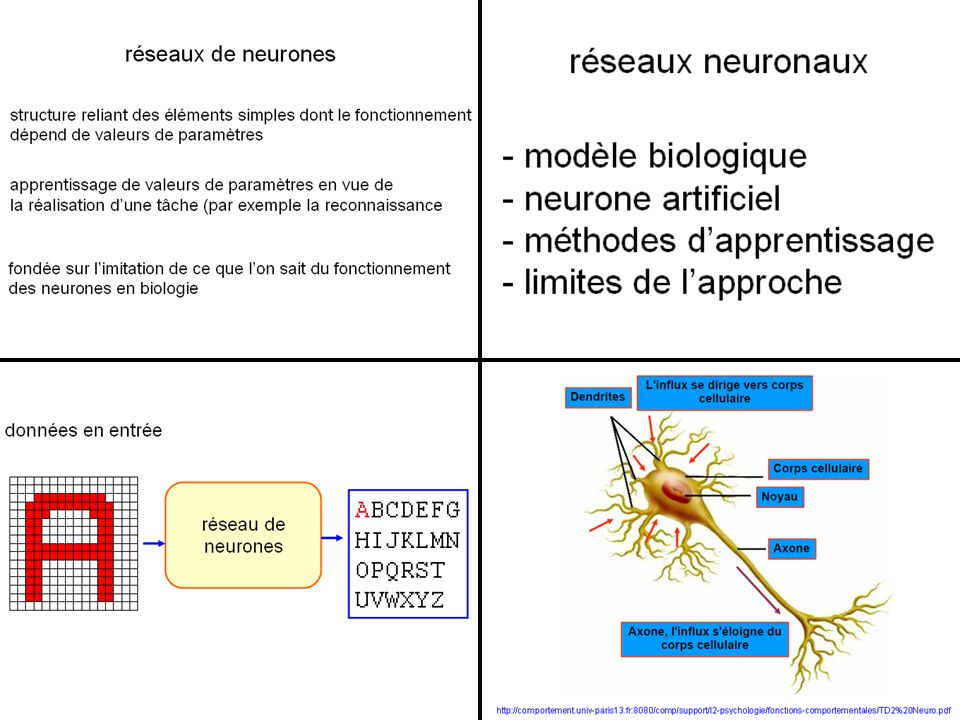
réseaux neuronaux (neural networks)
structure reliant des éléments simples dont le fonctionnement dépend de valeurs de paramètres apprentissage de valeurs de paramètres en vue de la réalisation d’une tâche (par exemple la reconnaissance fondée sur l’imitation de ce que l’on sait du fonctionnement des neurones en biologie

19
ABCDEFG HIJKLMN OPQRST UVWXYZ
illustration : reconnaissance de caractères par un réseau neuronal apprentissage de valeurs de paramètres pour qu’à différentes entrées (différents « A ») ce soit la sortie A qui s’active ; de même pour les autres lettres ABCDEFG HIJKLMN OPQRST UVWXYZ réseau de neurones structure reliant des éléments simples dont le fonctionnement dépend de valeurs de paramètres données en entrée sortie voulue
 ce soit la sortie A qui s’active ; de même pour les autres lettres. ABCDEFG. HIJKLMN. OPQRST. UVWXYZ. réseau de. neurones. structure reliant des éléments simples dont le fonctionnement. dépend de valeurs de paramètres. données en entrée. sortie voulue.")
20
réseaux neuronaux - modèle biologique neurone artificiel méthodes d’apprentissage limites de l’approche

21
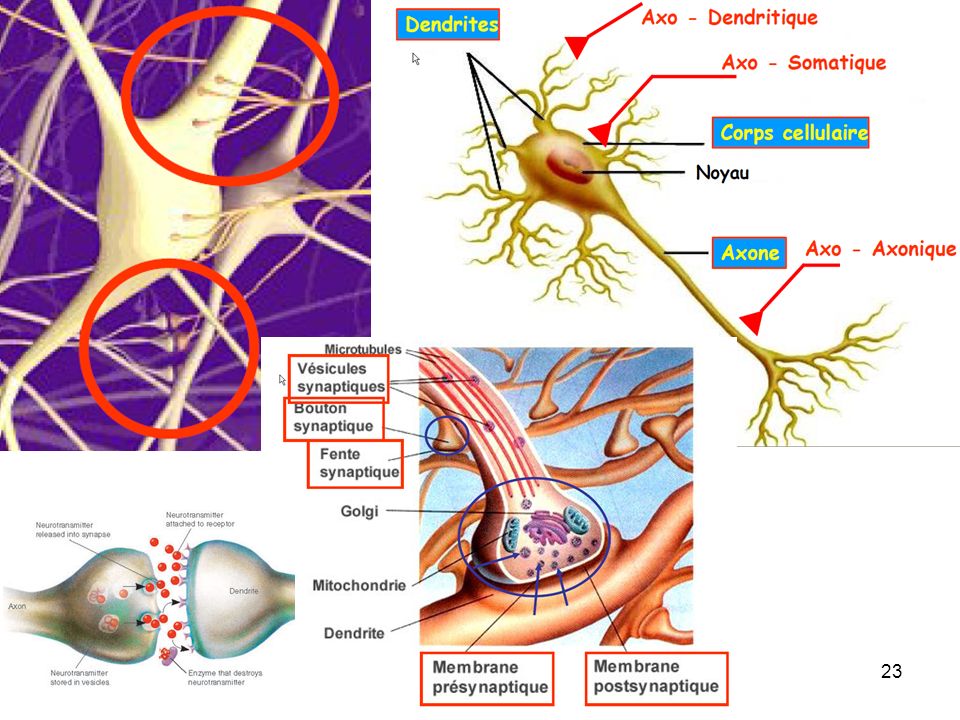
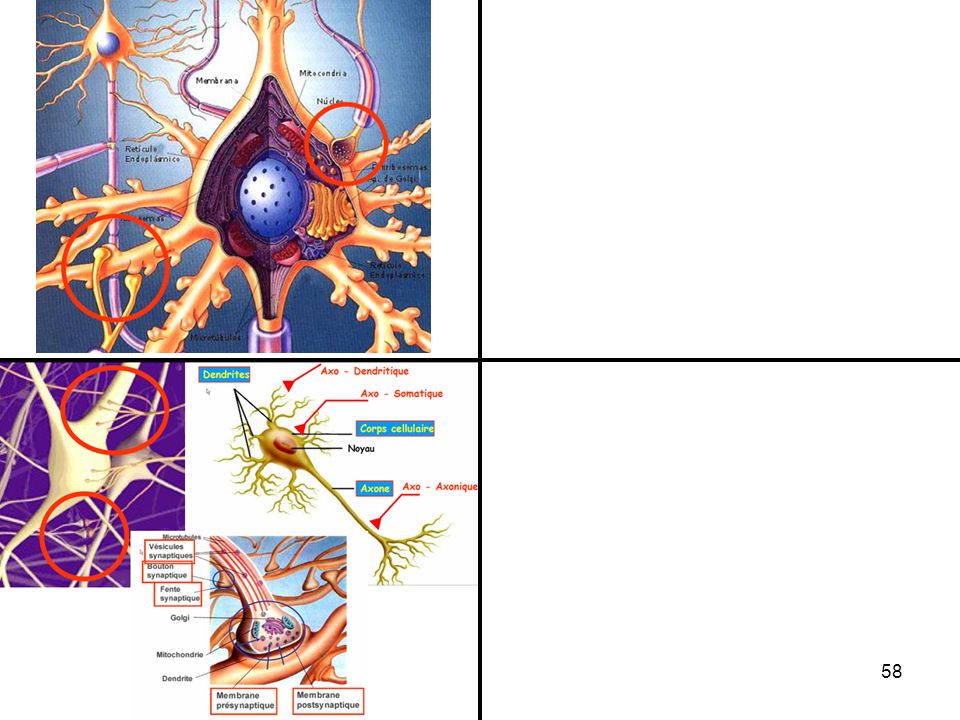
Dessin de la main de Ramón y Cajal de cellules cerebelleuses de poulet, tiré de "Estructura de los centros nerviosos de las aves", Madrid, 1905 Prix Nobel de médecine en 1906

24
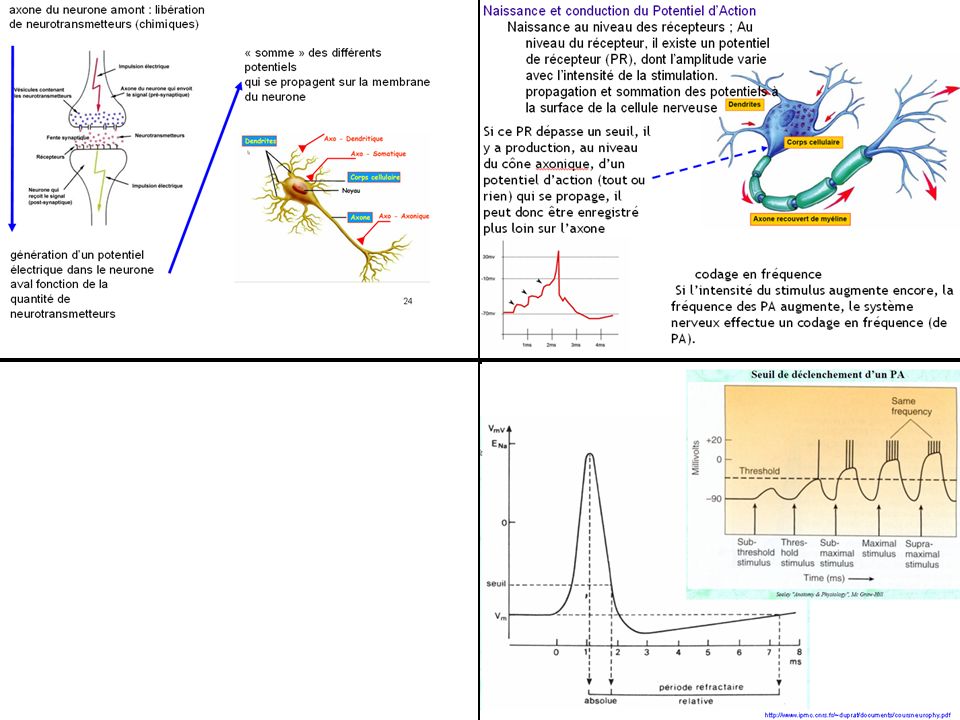
axone du neurone amont : libération de neurotransmetteurs (chimiques)
« somme » des différents potentiels qui se propagent sur la membrane du neurone génération d’un potentiel électrique dans le neurone aval fonction de la quantité de neurotransmetteurs

25
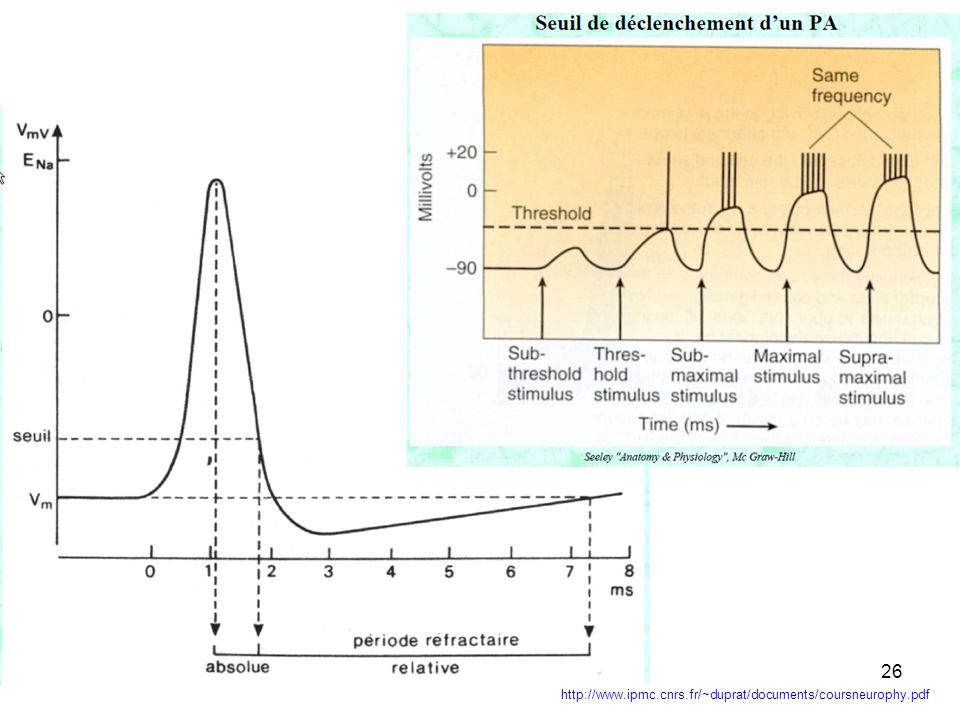
Naissance et conduction du Potentiel d’Action
Naissance au niveau des récepteurs ; Au niveau du récepteur, il existe un potentiel de récepteur (PR), dont l’amplitude varie avec l’intensité de la stimulation. propagation et sommation des potentiels à la surface de la cellule nerveuse Si ce PR dépasse un seuil, il y a production, au niveau du cône axonique, d’un potentiel d’action (tout ou rien) qui se propage, il peut donc être enregistré plus loin sur l’axone codage en fréquence Si l’intensité du stimulus augmente encore, la fréquence des PA augmente, le système nerveux effectue un codage en fréquence (de PA).
, dont l’amplitude varie avec l’intensité de la stimulation. propagation et sommation des potentiels à la surface de la cellule nerveuse. Si ce PR dépasse un seuil, il y a production, au niveau du cône axonique, d’un potentiel d’action (tout ou rien) qui se propage, il peut donc être enregistré plus loin sur l’axone. codage en fréquence. Si l’intensité du stimulus augmente encore, la fréquence des PA augmente, le système nerveux effectue un codage en fréquence (de PA).")
27
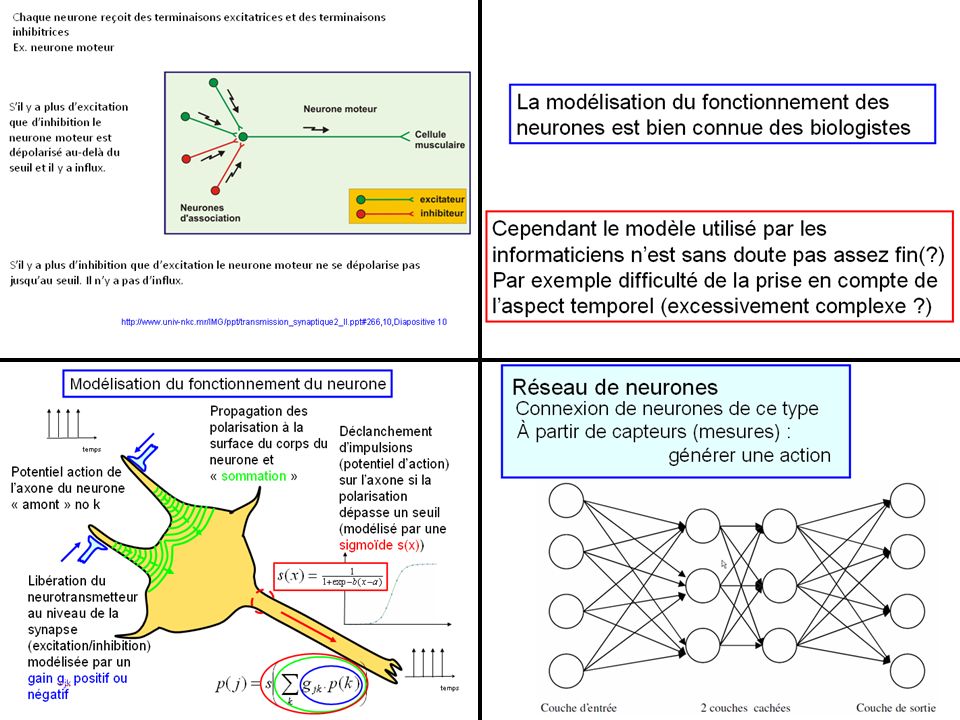
Chaque neurone reçoit des terminaisons excitatrices et des terminaisons inhibitrices
Ex. neurone moteur S’il y a plus d’excitation que d’inhibition le neurone moteur est dépolarisé au-delà du seuil et il y a influx. S’il y a plus d’inhibition que d’excitation le neurone moteur ne se dépolarise pas jusqu’au seuil. Il n’y a pas d’influx. 10 27

28
Modélisation du fonctionnement du neurone
Propagation des polarisation à la surface du corps du neurone et « sommation » Déclanchement d’impulsions (potentiel d’action) sur l’axone si la polarisation dépasse un seuil (modélisé par une sigmoïde s(x)) temps Potentiel action de l’axone du neurone « amont » no k Libération du neurotransmetteur au niveau de la synapse (excitation/inhibition) modélisée par un gain gjk positif ou négatif temps
 sur l’axone si la polarisation dépasse un seuil (modélisé par une sigmoïde s(x)) temps. Potentiel action de l’axone du neurone « amont » no k. Libération du neurotransmetteur au niveau de la synapse (excitation/inhibition) modélisée par un gain gjk positif ou négatif. temps.")
29
La modélisation du fonctionnement des neurones est bien connue des biologistes
Cependant le modèle utilisé par les informaticiens n’est sans doute pas assez fin(?) Par exemple difficulté de la prise en compte de l’aspect temporel (excessivement complexe ?)
 Par exemple difficulté de la prise en compte de l’aspect temporel (excessivement complexe )")
30
Réseau de neurones Connexion de neurones de ce type
À partir de capteurs (mesures) : générer une action
 : générer une action.")
31
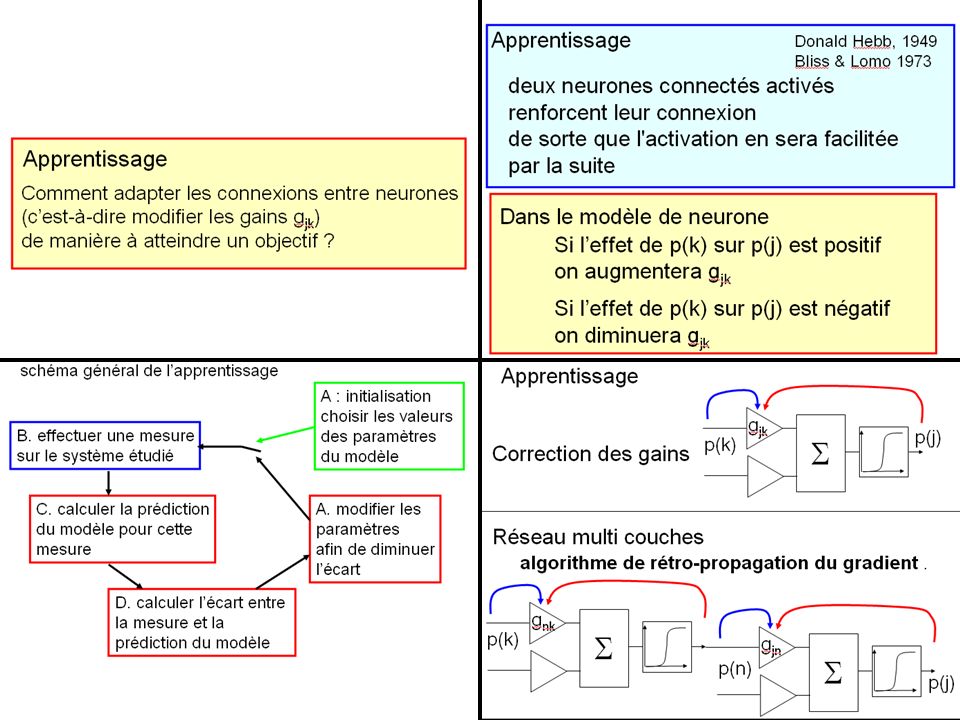
Apprentissage Comment adapter les connexions entre neurones
(c’est-à-dire modifier les gains gjk) de manière à atteindre un objectif ?
 de manière à atteindre un objectif")
32
schéma général de l’apprentissage
A : initialisation choisir les valeurs des paramètres du modèle B. effectuer une mesure sur le système étudié C. calculer la prédiction du modèle pour cette mesure A. modifier les paramètres afin de diminuer l’écart D. calculer l’écart entre la mesure et la prédiction du modèle

33
deux neurones connectés activés renforcent leur connexion
Apprentissage Donald Hebb, 1949 Bliss & Lomo 1973 deux neurones connectés activés renforcent leur connexion de sorte que l'activation du neurone aval sera facilitée par la suite Dans le modèle de neurone Si l’effet de p(k) sur p(j) est positif on augmentera gjk Si l’effet de p(k) sur p(j) est négatif on diminuera gjk
 sur p(j) est positif. on augmentera gjk. Si l’effet de p(k) sur p(j) est négatif. on diminuera gjk.")
34
S S S Apprentissage Correction des gains Réseau multi couches gjk p(j)
p(k) S Correction des gains Réseau multi couches algorithme de rétro-propagation du gradient . gnk p(k) S gjn S p(n) p(j)
 S. Correction des gains. Réseau multi couches. algorithme de rétro-propagation du gradient . gnk. p(k) S. gjn. S. p(n) p(j)")
35
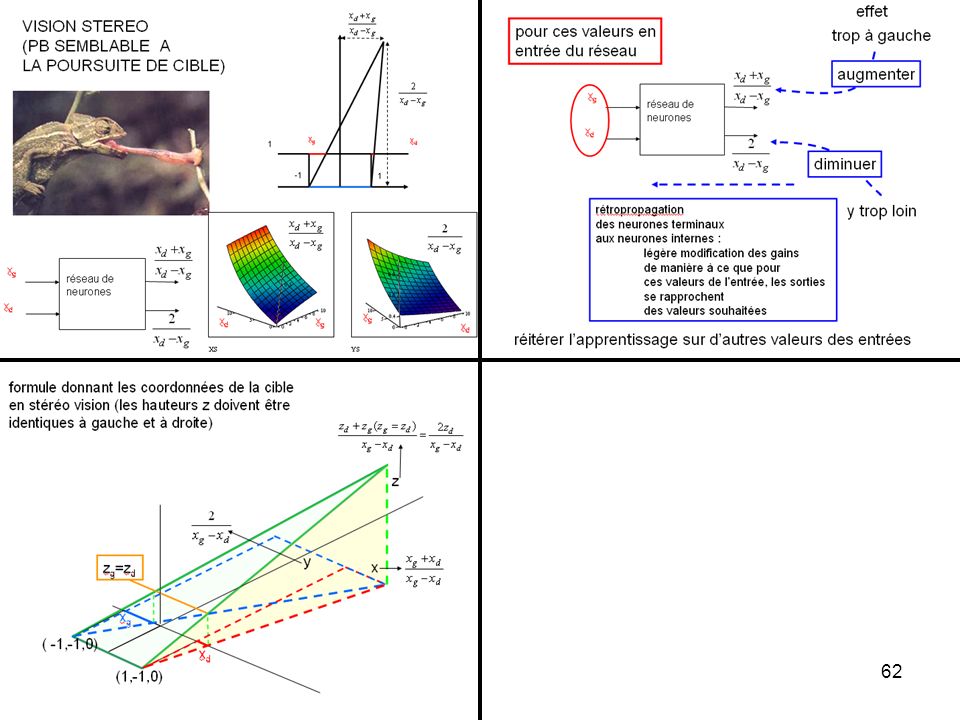
VISION STEREO (PB SEMBLABLE A LA POURSUITE DE CIBLE) xg réseau de
1 xg xd -1 1 xg réseau de neurones xd xg xd xg xd

36
formule donnant les coordonnées de la cible
en stéréo vision (les hauteurs z doivent être identiques à gauche et à droite) z y zg=zd x xg ( -1,-1,0) xd (1,-1,0)
 z. y. zg=zd. x. xg. ( -1,-1,0) xd. (1,-1,0)")
37
réitérer l’apprentissage sur d’autres valeurs des entrées
effet pour ces valeurs en entrée du réseau trop à gauche augmenter xg réseau de neurones xd diminuer rétropropagation des neurones terminaux aux neurones internes : légère modification des gains de manière à ce que pour ces valeurs de l’entrée, les sorties se rapprochent des valeurs souhaitées y trop loin réitérer l’apprentissage sur d’autres valeurs des entrées

38
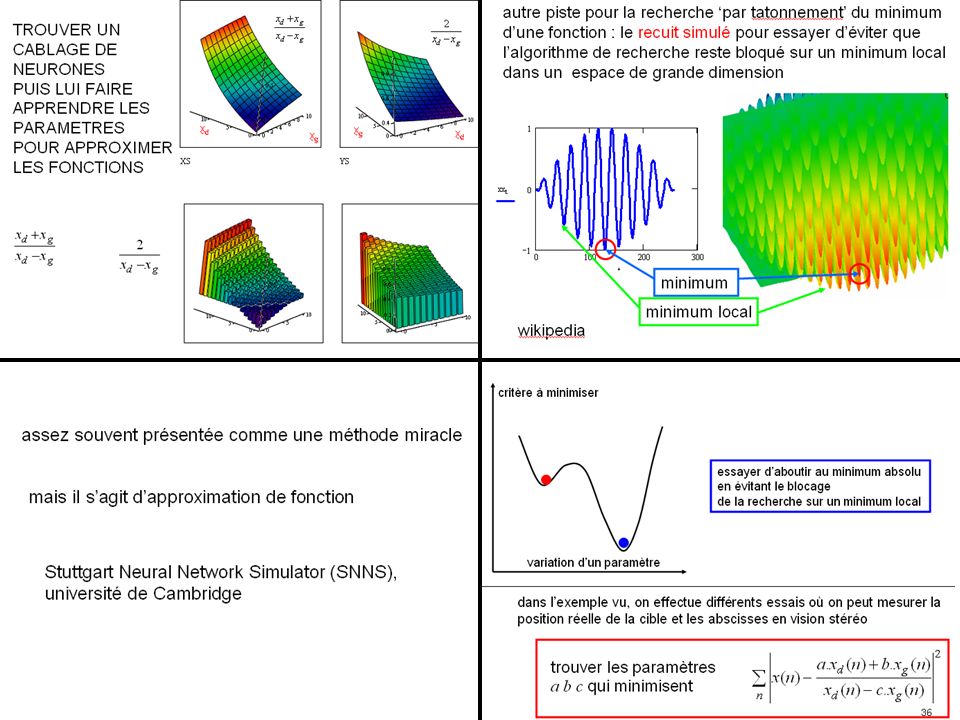
TROUVER UN CABLAGE DE NEURONES
xd xg TROUVER UN CABLAGE DE NEURONES PUIS LUI FAIRE APPRENDRE LES PARAMETRES POUR APPROXIMER LES FONCTIONS xg

39
TROUVER UN CABLAGE DE NEURONES
PUIS LUI FAIRE APPRENDRE LES PARAMETRES POUR APPROXIMER LES FONCTIONS

40
assez souvent présentée comme une méthode miracle
mais il s’agit d’approximation de fonction Stuttgart Neural Network Simulator (SNNS), université de Cambridge
, université de Cambridge.")
41
autre piste pour la recherche ‘par tatonnement’ du minimum
d’une fonction : le recuit simulé pour essayer d’éviter que l’algorithme de recherche reste bloqué sur un minimum local dans un espace de grande dimension minimum minimum local wikipedia

42
trouver les paramètres a b c qui minimisent
critère à minimiser essayer d’aboutir au minimum absolu en évitant le blocage de la recherche sur un minimum local variation d’un paramètre dans l’exemple vu, on effectue différents essais où on peut mesurer la position réelle de la cible et les abscisses en vision stéréo trouver les paramètres a b c qui minimisent

43
Partant d'une solution donnée, en la modifiant, on en obtient une seconde.
Soit celle-ci améliore le critère que l'on cherche à optimiser, on dit qu‘elle a fait baisser l'énergie du système, soit celle-ci le dégrade. En acceptant une solution améliorant le critère, on tend ainsi à chercher l'optimum dans le voisinage de la solution de départ. L'acceptation d'une « mauvaise » solution (dégradant le critère) permet d'explorer une plus grande partie de l'espace de solution et tend à éviter de s'enfermer trop vite dans la recherche d'un optimum local. on effectue un grand nombre d’essais aléatoires à partir de cette solution (voir l’approche mentionnée précédemment des filtres particulaires)
 permet d explorer une plus grande partie de l espace de solution et tend à éviter de s enfermer trop vite dans la recherche d un optimum local. on effectue un grand nombre d’essais aléatoires à partir de cette solution. (voir l’approche mentionnée précédemment des filtres particulaires)")
44
Itérations de l'algorithme
critère à minimiser Itérations de l'algorithme À chaque itération modification élémentaire de la solution. Cette modification entraîne une variation ΔE de l'énergie (critère) Si cette variation est négative (fait baisser l'énergie du système), elle est appliquée. Sinon, elle est acceptée avec une probabilité exp - DE/T . ( règle de Metropolis.) On itère selon ce procédé en gardant la température constante puis en la diminuant légèrement (recuit). valeur d’un paramètre essayer d’aboutir au minimum absolu en évitant le blocage de la recherche sur un minimum local champs de markov en traitement d’images
 Si cette variation est négative (fait baisser l énergie du système), elle est appliquée. Sinon, elle est acceptée avec une probabilité. exp - DE/T . ( règle de Metropolis.) On itère selon ce procédé en gardant la température constante puis en la diminuant légèrement (recuit). valeur d’un paramètre. essayer d’aboutir au minimum absolu en évitant le blocage. de la recherche sur un minimum local. champs de markov en traitement d’images.")
45
recuit simulé Faire baisser la température de façon continue. Ti + 1 = 0.99 λTi si la température a atteint un seuil assez bas le système devient figé, l'algorithme s'arrête. À haute température, le système est libre de se déplacer dans l'espace des solutions (exp - DE/T proche de 1) en choisissant des solutions ne minimisant pas forcément l'énergie du système. À basse température, les modifications baissant l'énergie du système sont choisies, mais d'autres peuvent être acceptées, empêchant ainsi l'algorithme de tomber dans un minimum local.
 en choisissant des solutions ne minimisant pas forcément l énergie du système. À basse température, les modifications baissant l énergie du système sont choisies, mais d autres peuvent être acceptées, empêchant ainsi l algorithme de tomber dans un minimum local.")
46
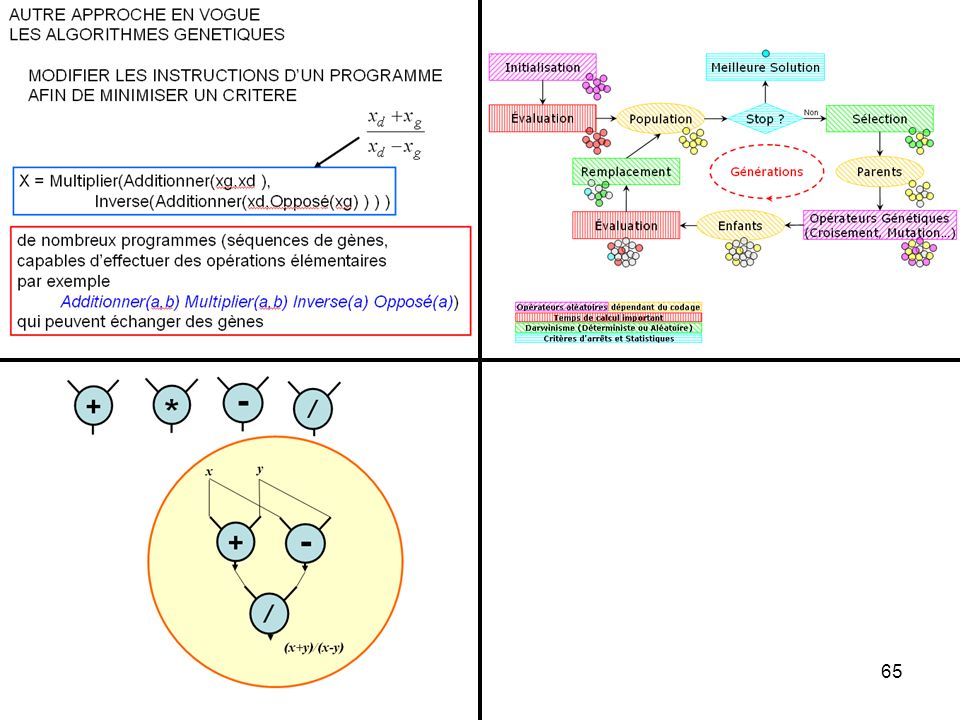
AUTRE APPROCHE EN VOGUE
LES ALGORITHMES GENETIQUES MODIFIER LES INSTRUCTIONS D’UN PROGRAMME AFIN DE MINIMISER UN CRITERE X = Multiplier(Additionner(xg,xd ), Inverse(Additionner(xd,Opposé(xg) ) ) ) de nombreux programmes (séquences de gènes, capables d’effectuer des opérations élémentaires par exemple Additionner(a,b) Multiplier(a,b) Inverse(a) Opposé(a)) qui peuvent échanger des gènes
, Inverse(Additionner(xd,Opposé(xg) ) ) ) de nombreux programmes (séquences de gènes, capables d’effectuer des opérations élémentaires. par exemple. Additionner(a,b) Multiplier(a,b) Inverse(a) Opposé(a)) qui peuvent échanger des gènes.")
47
+ * - / x y + - / (x+y)/(x-y)
/(x-y)")
48
Opérateurs Génétiques (Croisement, Mutation…)
Initialisation Meilleure Solution Évaluation Population Stop ? Non Sélection Générations Remplacement Parents Évaluation Enfants Opérateurs Génétiques (Croisement, Mutation…) Opérateurs aléatoires Darwinisme (Déterministe ou Aléatoire) Temps de calcul important Critères d’arrêts et Statistiques dépendant du codage
 Opérateurs aléatoires. Darwinisme (Déterministe ou Aléatoire) Temps de calcul important. Critères d’arrêts et Statistiques. dépendant du codage.")
49
si le programme modifié est parmi les plus performants des programmes(ici résultats
plus proche de la cible), on le garde et il se multiplie (avec des modifications génétiques) si les performances sont médiocres il est éliminé avec une certaine probabilité
, on le garde et il se multiplie. (avec des modifications génétiques) si les performances sont médiocres il est éliminé avec une. certaine probabilité.")
50
évolution « darwinienne »
Les plus performants (ceux qui se rapprochent de l’objectif, minimisation du critère, se multiplient en modifiant aléatoirement certains gênes ; échange possible de gènes entre individus les moins performants disparaissent et réitération du processus

Présentations similaires