Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Introduction à la bioinformatique
Support de Cours N°1: Introduction à la bioinformatique Catherine Clusel PLU5231

2
La Bioinformatique: définition
Biologie in situ Environnement naturel Biologie in vivo Organisme entier Biologie ex vivo Niveau cellulaire Biologie in vitro Niveau moléculaire Les niveaux d’étude de la biologie. Biologie in silico Bioinformatique PLU5231

3
La bioinformatique : définition
Bioinformatique = biologie théorique Ensemble des concepts et techniques nécessaires pour interpréter: - l’information génétique (manipulation de séquences) - l’information structurale (repliement 3D) C est le décryptage de la bio- information PLU5231
 - l’information structurale (repliement 3D) C est le décryptage de la bio- information. PLU5231.")
4
Le but de la bioinformatique
Bioinformatique = traitement numérique des informations + approche théorique - Effectuer la synthèse des données disponibles - Énoncer des hypothèses généralisatrices - Formuler des prédictions PLU5231

5
Ce que n’est pas la bioinformatique
- Acquisition des données: instrumentation , robotique - Archivage des données: bases de données - Consultation des données: interfaces utilisateurs Biologie théorique implique forcément un pré-requis costaud en biologie. On va donc faire un rappel des principales notions de biologie cellulaire et moléculaire avant d’entrer dans le vif du sujet. Ce document n'est qu'un support de cours, il n'a pas été écrit pour remplacer la présentation orale. Tous les rappels nécessaires en biologie sont inclus dans le cours, ainsi même avec des souvenirs très vagues de classe terminale scientifique, ce cours est abordable. Objectifs: Ce cours est un « starter-kit » ou « kit de démarrage ». Ce qui veux dire qu'avec aucune connaissance a priori dans ce domaine vous devriez à la fin du cours (et du TP) manipuler les concepts de base et même avoir une certaine connaissance pratique vous permettant de faire des analyses informatiques de séquences d'ADN (molécule support de l'hérédité) et des séquences protéiques. Les séquences étant l’objet d’étude principal des bioinformaticiens. Le terme « starter kit » souligne aussi le fait que ce cours n'est pas exhaustif sur le sujet de la bioinformatique, et qu'il est orienté vers un cote pratique, il ne va donc pas entrer dans les détails ou les fondamentaux. Domaines de l’informatique traditionnelle utilisés par la génomique Mais pas impliqués dans la découverte de nouveau concepts en biologie PLU5231
 manipuler les concepts de base et même avoir une certaine connaissance pratique vous permettant de faire des analyses informatiques de séquences d ADN (molécule support de l hérédité) et des séquences protéiques. Les séquences étant l’objet d’étude principal des bioinformaticiens. Le terme « starter kit » souligne aussi le fait que ce cours n est pas exhaustif sur le sujet de la bioinformatique, et qu il est orienté vers un cote pratique, il ne va donc pas entrer dans les détails ou les fondamentaux. Domaines de l’informatique traditionnelle utilisés par la génomique. Mais pas impliqués dans la découverte de nouveau concepts en biologie. PLU5231.")
6
Ce qu’est la bioinformatique
Analyse de l’information biologique L’information est: La séquence (ADN, ARN et Protéine) La structure (primaire, secondaire etc.) La fonction (fonction moléculaire ex: enzyme; composant cellulaire ex: protéine membranaire; processus biologique ex: transport d’oxygène) Les interactions (protéines, voies métaboliques, réseaux de gènes)
 La structure (primaire, secondaire etc.) La fonction (fonction moléculaire ex: enzyme; composant cellulaire ex: protéine membranaire; processus biologique ex: transport d’oxygène) Les interactions (protéines, voies métaboliques, réseaux de gènes)")
7
Les axes privilégiés de la bioinformatique
La formalisation de l'information génétique L'analyse des séquences (biomolécules) et de leur structure (notamment , structure 3D) L'interprétation biologique de l'information génétique L'intégration des données (établissement de cartes et de réseaux d'interactions géniques, d'interactions protéiques ...) La prédiction fonctionnelle
 et de leur structure (notamment , structure 3D) L interprétation biologique de l information génétique. L intégration des données (établissement de cartes et de réseaux d interactions géniques, d interactions protéiques ...) La prédiction fonctionnelle.")
8
Les méthodes de la bioinformatique
Méthode comparative : comparaison des séquences ou structures inconnues avec les bases de données (séquences et structures) de gènes et de protéines connues pour établir des rapprochements (similarités , homologies ou identités). Méthode statistique : Des logiciels appliquent des analyses statistiques aux données (sur la syntaxe des séquences) pour tenter de dégager et de repérer des règles et des contraintes présentant un caractère systématique, régulier ou général. Approche par modélisation Approche probabiliste. Elle consiste à étudier les objets (ex. : séquences, structures, motifs, etc., ...) à travers la construction d'un modèle qui tente d'en extraire les propriétés communes. La relation entre les objets d'étude (et/ou leur reconnaissance) est alors exprimée en référence à ce modèle optimal commun.
 de gènes et de protéines connues pour établir des rapprochements (similarités , homologies ou identités). Méthode statistique : Des logiciels appliquent des analyses statistiques aux données (sur la syntaxe des séquences) pour tenter de dégager et de repérer des règles et des contraintes présentant un caractère systématique, régulier ou général. Approche par modélisation Approche probabiliste. Elle consiste à étudier les objets (ex. : séquences, structures, motifs, etc., ...) à travers la construction d un modèle qui tente d en extraire les propriétés communes. La relation entre les objets d étude (et/ou leur reconnaissance) est alors exprimée en référence à ce modèle optimal commun.")
9
La mission du bioinformaticien
Leur formation première peut être la biologie, les mathématiques ou l'informatique et ils ont suivi une formation complémentaire dans "l'autre domaine". Leur fonction est: mettre en œuvre les méthodes et en automatiser le traitement nourrir la recherche en biologie des résultats de ces analyses réduire les problèmes posés par les biologistes en termes accessibles aux mathématiciens et informaticiens participer à l'élaboration de nouvelles méthodes

10
Biologie: science molle
Biologie = science empirique pas théorique dans le monde du vivant : rien n'est totalement prévisible rien n'est totalement reproductible Ce qui s'est produit à l'instant t ne se produira pas nécessairement à l'instant t+1. rien n'est constant Le temps fait évoluer l'objet vivant dans sa forme et dans ses fonctions de manière irréversible. l'identité totale de deux objets biologiques n'existe pas Deux individus à l'intérieur d'une même espèce ne sont jamais identiques, pas même à l'intérieur d'un couple de jumeaux.

11
Biologie : étude du dynamique
Même si elle intègre la notion d'objet (une cellule, un individu, une population), elle repose fondamentalement sur l'étude des liens, des interactions et des régulations dynamiques qui organisent les objets entre eux dans le temps et dans l'espace, à l'intérieur d'un système d'un niveau de complexité supérieur
, elle repose fondamentalement sur l étude des liens, des interactions et des régulations dynamiques qui organisent les objets entre eux dans le temps et dans l espace, à l intérieur d un système d un niveau de complexité supérieur.")
12
Révolutions dans la biologie
Les lois de Mendel (1866): Mendel est un des pionniers de la bioinformatique : un des premiers à construire une théorie biologique nouvelle à partir d'une analyse statistique. La mise en évidence des chromosomes comme support cellulaire de l' hérédité et de l' information génétique par Morgan (1913). Les découvertes de la structure en double hélice de l' ADN par James Watson et Francis Crick (1953), puis du mécanisme de la régulation génétique impliqué dans le dogme central de la biologie moléculaire, énoncé initialement par Crick et révélé par Jacques Monod, François Jacob et André Wolf (1965).
: Mendel est un des pionniers de la bioinformatique : un des premiers à construire une théorie biologique nouvelle à partir d une analyse statistique. La mise en évidence des chromosomes comme support cellulaire de l hérédité et de l information génétique par Morgan (1913). Les découvertes de la structure en double hélice de l ADN par James Watson et Francis Crick (1953), puis du mécanisme de la régulation génétique impliqué dans le dogme central de la biologie moléculaire, énoncé initialement par Crick et révélé par Jacques Monod, François Jacob et André Wolf (1965).")
13
La séquence : élément fondateur du puzzle du vivant
La séquence , linéaire, chaîne de caractères basée sur un alphabet de quatre caractères (les nucléotides) dont la combinaison donne sa spécificité (espèce, gène..). La séquence est stable dans l'espace et présente des propriétés d' hybridation et de dénaturation à haute température qui en font un objet biologique expérimental de qualité : elle peut être extraite, manipulée et synthétisée in vitro. La séquence est relativement stable dans le temps. Les changements qui l'affectent (mutations , délétions , substitutions) peuvent être utilisés comme une mesure quantitative de l'évolution. Elément fondateur de la biodiversité et de la complexité du vivant : l' ADN est le support biologique commun à presque tous les êtres vivants Le code génétique , avec lequel les protéines seront codées à partir de la séquence nucléique, est (à quelques codons près ...), universel.
 dont la combinaison donne sa spécificité (espèce, gène..). La séquence est stable dans l espace et présente des propriétés d hybridation et de dénaturation à haute température qui en font un objet biologique expérimental de qualité : elle peut être extraite, manipulée et synthétisée in vitro. La séquence est relativement stable dans le temps. Les changements qui l affectent (mutations , délétions , substitutions) peuvent être utilisés comme une mesure quantitative de l évolution. Elément fondateur de la biodiversité et de la complexité du vivant : l ADN est le support biologique commun à presque tous les êtres vivants. Le code génétique , avec lequel les protéines seront codées à partir de la séquence nucléique, est (à quelques codons près ...), universel.")
14
Les biotechnologies Domaine d’application privilégié de la bioinformatique Pour la médecine & santé publique: Diagnostique Pharmacogénomique (pharmacogenetique&toxicogenétique) Thérapie génique Vaccins Empreintes génétiques Pour l’agroalimentaire Résistance aux pesticides, aux pathogènes, aux insectes Tolérance au stress environnementaux Rendements et qualité Pour l’environnement Lutte contre les pollutions chimiques ou biologiques (traitements de l'eau, des sols, des déchets) Nouvelles sources d'énergie Préservation de la biodiversité
 Thérapie génique. Vaccins. Empreintes génétiques. Pour l’agroalimentaire. Résistance aux pesticides, aux pathogènes, aux insectes. Tolérance au stress environnementaux. Rendements et qualité. Pour l’environnement. Lutte contre les pollutions chimiques ou biologiques (traitements de l eau, des sols, des déchets) Nouvelles sources d énergie. Préservation de la biodiversité.")
15
Notions essentielles de biologie
Support de Cours N°1: Les cellules et leurs constituants Catherine Clusel PLU5231

16
Une idée de l échelle entre les cellules vivantes et les atomes.
Chaque image est agrandie d’un facteur 10. La suite et complètement imaginaire mais reflète les niveau d’étude de la vie. Les détails des deux derniers niveau sont au delà de la résolution de la microscopie électronique. PLU5231

17
Trois types cellulaires dessinés de façon réaliste.
Les même composants des cellules sont représentés avec les mêmes couleurs. On distingues trois familles de cellules: -les procaryotes: absence de noyau, l’ADN est libre dans le cytoplasme. Les cellules sont entourées d’une paroi. Ex : bactéries. - les eucaryotes: eu= vrai, karyos= noyau. Les cellules eucaryotes animales et végétales ont un noyau qui contient l’ADN. Les cellules eucaryotes végétales ont des vacuoles, des chloroplastes et une paroi solide. Ex : voir plus loin. PLU5231

18
Schéma d’une cellule eucaryote
Schéma représentatif d’une cellule animale: Notez la présence des nombreuses membranes créant des compartiments fonctionnels très distinct par leur structure et leur fonction. On appelle ça des organites cellulaires. noyau. contient le principal génome, synthèse d’ADN et d’ARN réticulum endoplasmique : synthèse des protéines membranaires et des protéines destinées à être secrétées . Synthèse des lipides. mitochondrie : contient son propre ADN. Générateur d’énergie chimique pour la cellule. Fabricant principal d’ATP. - peroxysomes : espace clos pour réaction chimiques dangereuses. - appareil de Golgi : synthèse, modification, tri et empaquetage des protéines pour l’export. -lysosome : digestion intracellulaire des nutriment depuis les particules alimentaires. Dégradation des indésirables pour recyclage ou excrétion. vésicules : transport de matériaux entre les organites séparés par des membranes, trafic interne. Attention tout est connecté, il s’agît d’un réseau très étroit qu’il faut se représenter mentalement en 3D et dynamique. La cellule communique autant avec l’extérieur que chacun de ces organite entre eux. La cellule eucaryote n’est pas isolée, elle a des voisines dans un organe qui fonctionne en réseau avec l’ensemble du corps. Chaque organite contient des protéines qui lui sont spécifique. PLU5231

19
PLU5231

20
Origines évolutives Procaryote ancestral
Les cellules sont très variées et pourtant proviennent toutes d’une même cellule ancestrale commune. Les principes de changement et de sélection appliqués sur des millions et des millions de génération sont la base de l’évolution. Evolution: processus par lequel les espèces vivantes se modifient et s’adaptent progressivement à leur environnement de manière de plus en plus sophistiquée. L’être vivant le plus simple est la bactérie. Les bactéries qui nous entourent tous les jours (dans l’environnement ou qui nous rendent malades) sont des eubactéries. Les archéobactéries sont retrouvées dans les environnements extrêmes et hostiles à la plupart des autres cellules (mers trop salées, trop chaudes, profondeurs dans airs, milieux acides, etc. Plusieurs de ces milieux ont des conditions qui s’approchent des conditions initiales du début de la vie sur terre ou l’atmosphère étaient pauvre en oxygènes. Les mitochondries sont sembles chez tous les eucaryotes (végétaux, animaux et champignons) Ils ont donc divergé après l’acquisition des mitochondries. Spéciation: fixation d’une espèce au cours de l’évolution. Création d’une espace nouvelle. Les espèces filles ne sont plus capables de se reproduire entre elles. PLU5231
 sont des eubactéries. Les archéobactéries sont retrouvées dans les environnements extrêmes et hostiles à la plupart des autres cellules (mers trop salées, trop chaudes, profondeurs dans airs, milieux acides, etc. Plusieurs de ces milieux ont des conditions qui s’approchent des conditions initiales du début de la vie sur terre ou l’atmosphère étaient pauvre en oxygènes. Les mitochondries sont sembles chez tous les eucaryotes (végétaux, animaux et champignons) Ils ont donc divergé après l’acquisition des mitochondries. Spéciation: fixation d’une espèce au cours de l’évolution. Création d’une espace nouvelle. Les espèces filles ne sont plus capables de se reproduire entre elles. PLU5231.")
21
Les quatre familles de molécules
Les quatre familles de petites molécules organiques: Sucres: Tous les mots en ose (glucose, fructose). Acides Gras: Lipides Acides aminés: 20 au total, entrent dans la composition des protéines. Nucléotides: entrent dans la composition de l’ADN et l’ARN. Des molécules organiques simples contenant du carbone ont été probablement fabriquées spontanément sur la terre durant le premier milliard d’années de son existence (il y a plus de 4 milliards d’années). A l’époque la terre était un endroit violent, avec des éruptions volcaniques, des éclairs et des pluies torrentielles. Il y avait peu d’oxygène et pas de couche d’ozone pour protéger l’atmosphère des rayonnements ultraviolets. La décharge massive d’énergie par les éclairs a probablement été l’une des sources d’énergie pour la synthèse prébiotique des molécules organiques. Si on mélange de la vapeur d’eau, du méthane, de l’ammoniac (gaz) et de l’hydrogène dans un ballon et qu’on envie une décharge électrique sur le ballon, il se forme un grand nombre de molécules organiques : l'adénine (A), la guanine (G), l'uracile (U) et des acides aminés dit aliphatiques : l'alanine, la glycine, l'acide aspartique, l'acide glutamique, etc. Les plus grosses molécules contiennent plus de 100 atomes ( PLU5231
. Acides Gras: Lipides. Acides aminés: 20 au total, entrent dans la composition des protéines. Nucléotides: entrent dans la composition de l’ADN et l’ARN. Des molécules organiques simples contenant du carbone ont été probablement fabriquées spontanément sur la terre durant le premier milliard d’années de son existence (il y a plus de 4 milliards d’années). A l’époque la terre était un endroit violent, avec des éruptions volcaniques, des éclairs et des pluies torrentielles. Il y avait peu d’oxygène et pas de couche d’ozone pour protéger l’atmosphère des rayonnements ultraviolets. La décharge massive d’énergie par les éclairs a probablement été l’une des sources d’énergie pour la synthèse prébiotique des molécules organiques. Si on mélange de la vapeur d’eau, du méthane, de l’ammoniac (gaz) et de l’hydrogène dans un ballon et qu’on envie une décharge électrique sur le ballon, il se forme un grand nombre de molécules organiques : l adénine (A), la guanine (G), l uracile (U) et des acides aminés dit aliphatiques : l alanine, la glycine, l acide aspartique, l acide glutamique, etc. Les plus grosses molécules contiennent plus de 100 atomes ( PLU5231.")
22
Composition d’une cellule bactérienne
Composition approximative d’une cellule bactérienne: Ce cours a traité des protéines, lipides et sucres. Le prochain cours traitera des acides nucléiques. PLU5231

23
Assemblages de molécules
Les liaisons non covalentes permettent aux macromolécules de se lier à d’autres macromolécules. Forces de Van Der Waals: attraction entre les atomes. La rayon de Van der Waals est la distance d’équilibre entre deux atomes (cf exemple de l’hydrogène). Liaisons hydrogènes : présentes sur les protéines , les acides nucléiques ou les assemblage complexes comme le ribosome. Forces hydrophobes: l’eau contraint les groupements hydrophobes a se rapprocher, c’est plus de la répulsion de l’eau que l’attraction des zones hydrophobes. Liaisons ioniques: en solution, dans un cristal ou le site actif d ’un enzyme. Ces forces dirigent les interactions de toutes les molécules de la cellules entre elles. Exemple du ribosome PLU5231
. Liaisons hydrogènes : présentes sur les protéines , les acides nucléiques ou les assemblage complexes comme le ribosome. Forces hydrophobes: l’eau contraint les groupements hydrophobes a se rapprocher, c’est plus de la répulsion de l’eau que l’attraction des zones hydrophobes. Liaisons ioniques: en solution, dans un cristal ou le site actif d ’un enzyme. Ces forces dirigent les interactions de toutes les molécules de la cellules entre elles. Exemple du ribosome. PLU5231.")
24
Quel est le support de l’hérédité?
Démonstration expérimentale que l’ADN est le support de l’hérédité: Deux souches étroitement apparentées de la bactéries Streptococcus pneumoniae diffèrent l’une de l’autre à la fois dans leur apparence au microscope et par leur pathogénicité. Une souche paraît lisse (S), et elle entraîne la mort des souris si elle leur est injectée, une souche paraît rugueuse (R ), et elle n’est pas létale. L’expérience en A prouve qu’une substance présente dans la souche S peut changer (ou transformer) la souche R en souche S, et que ce changement est hérité par les générations ultérieures de bactéries. L’expérience en B identifie la substance comme étant l’ADN. NB: Les bactéries possèdent cette capacité d’accepter et d’exprimer (ou de se servir) un matériel génétique étranger. Cela s’appelle la transformation. C’est une propriété utilisée de façon courante pour le clonage de gènes. PLU5231
, et elle entraîne la mort des souris si elle leur est injectée, une souche paraît rugueuse (R ), et elle n’est pas létale. L’expérience en A prouve qu’une substance présente dans la souche S peut changer (ou transformer) la souche R en souche S, et que ce changement est hérité par les générations ultérieures de bactéries. L’expérience en B identifie la substance comme étant l’ADN. NB: Les bactéries possèdent cette capacité d’accepter et d’exprimer (ou de se servir) un matériel génétique étranger. Cela s’appelle la transformation. C’est une propriété utilisée de façon courante pour le clonage de gènes. PLU5231.")
25
Structure de l’ADN ADN et ses unités de structure:
Les sucres et les phosphates qui alternent constituent le squelette de la chaîne. La manière dont les nucléotides sont liés entre confère à la chaîne d’ADN une polarité chimique. Une extrémité porte un phosphate sur le carbone 5 (5’ P) et l’autre un OH sur le carbone 3 (3’ OH). Une molécule d’ADN est composé de deux chaînes polynucléotidiques, brins d’ADN, maintenues ensemble par des liaisons hydrogènes entre les bases appariées. Les bases sont par conséquent à l’intérieur de la molécule et le squelette à l’extérieur. Les bases ne s’apparient pas au hasard: A toujours avec T : 2 liaisons hydrogènes G toujours avec C: 3 liaisons hydrogènes Dans chaque cas, une base à deux cycles (purine, A et G) est en face d’une base à un cycle (T et C, pyrimidine). Dans cet arrangement, les paires ont une largeur équivalente sur toute la longueur de la molécule d’ADN. ATTENTION: Les deux brins sont colinéaires mais antiparallèles. Le brin « sens » se lit de gauche à droite le brin « antisens » se lit de droite à gauche mais les deux se lisent du phosphate à l’hydroxyle. PLU5231
 et l’autre un OH sur le carbone 3 (3’ OH). Une molécule d’ADN est composé de deux chaînes polynucléotidiques, brins d’ADN, maintenues ensemble par des liaisons hydrogènes entre les bases appariées. Les bases sont par conséquent à l’intérieur de la molécule et le squelette à l’extérieur. Les bases ne s’apparient pas au hasard: A toujours avec T : 2 liaisons hydrogènes. G toujours avec C: 3 liaisons hydrogènes. Dans chaque cas, une base à deux cycles (purine, A et G) est en face d’une base à un cycle (T et C, pyrimidine). Dans cet arrangement, les paires ont une largeur équivalente sur toute la longueur de la molécule d’ADN. ATTENTION: Les deux brins sont colinéaires mais antiparallèles. Le brin « sens » se lit de gauche à droite le brin « antisens » se lit de droite à gauche mais les deux se lisent du phosphate à l’hydroxyle. PLU5231.")
26
Liaisons hydrogènes de l ‘ADN
Paires de bases complémentaires dans l’ADN: La forme et la structure chimique des bases permettent d’aligner les bases sur un plan de façon à créer les deux liaisons entre A et T et les trois liaisons entre G et C. Les bases sont donc empilées comme les marches d’un escalier. La règle d’appariement entre les bases fait que les deux brins d’ADN sont parfaitement complémentaires sur toute leur séquence. Si sur un brin (sens) la séquence est : 5’ GTGCGGGGCATTTGTGCGTCGAACGACGTTT 3’ sur l'autre brin (complémentaire ou antisens) la séquence est : 5’ AAACGTCGTTCGACGCACAAATGCCCCGCAC 3’ L’ADN est un moyen de stockage très efficace : 1 molécule (monomère) -> 2 bits (4 valeurs possibles) 1 cellule humaine contient donc environ 6 Giga-bits ! Si on déroulait l'ADN d'une cellule humaine on obtiendrait un «fil» d'environ 1m de long! PLU5231
 la séquence est : 5’ GTGCGGGGCATTTGTGCGTCGAACGACGTTT 3’ sur l autre brin (complémentaire ou antisens) la séquence est : 5’ AAACGTCGTTCGACGCACAAATGCCCCGCAC 3’ L’ADN est un moyen de stockage très efficace : 1 molécule (monomère) -> 2 bits (4 valeurs possibles) 1 cellule humaine contient donc environ 6 Giga-bits ! Si on déroulait l ADN d une cellule humaine on obtiendrait un «fil» d environ 1m de long! PLU5231.")
27
Liaison hydrogènes de l’ADN

28
Modèle moléculaire d’ADN
Modèle compact d’ADN: A droite les oxygènes sont en rouge et les phosphates sont en jaune. L’enroulement des deux brins crée un grand et un petit sillon. Les bases azotées sont accessibles à la lecture par les protéines dans le grand sillon de l’ADN. PLU5231

29
Gènes?! Génome ?!?!?!

30
Génome humain

31
Constitution du génome
Caractéristiques du génome des Eucaryotes : -Existence d'un noyau dans lequel est isolé le génome des Eucaryotes : génome nucléaire. - En plus du génome nucléaire, les cellules des eucaryotes renferment des organites (mitochondries et chloroplastes) qui ont leurs propres génomes (ADN circulaire). - Le génome est représenté par un nombre de chromosomes constant pour une espèce donnée. Chacun des chromosomes est constitué d'une longue molécule ininterrompue d'ADN, adjointe de diverses protéines. - Les gènes eucaryotes sont morcelés (voir structure d’une gène). Les régions codant pour des protéines ne représentent qu'un faible pourcentage. Les dernières estimations, par exemple, dans le génome humain (voir Science, Vol 291) donnent la répartition suivante : 1,1% pour les exons, 24% pour les introns et 75% pour l'ADN intergénique. Compartimentation fonctionnelle du génome: On distingue dans le génome : Une partie du génome dont la fonction est inconnue (84% du génome humain). - Les fragments d'ADN intergéniques (non génique) : 54 à 71% du génome humain. - Les fragments d'ADN intragéniques : les introns 54 à 71% du génome humain. Les fragments du génome de fonction connue : les gènes - Les gènes protéiques: L'ensemble des exons représentent 2 à 5% du génome humain. Ils sont transcrits en a ARNm par la polymérase II, eux-mêmes traduits en protéines. PLU5231
 qui ont leurs propres génomes (ADN circulaire). - Le génome est représenté par un nombre de chromosomes constant pour une espèce donnée. Chacun des chromosomes est constitué d une longue molécule ininterrompue d ADN, adjointe de diverses protéines. - Les gènes eucaryotes sont morcelés (voir structure d’une gène). Les régions codant pour des protéines ne représentent qu un faible pourcentage. Les dernières estimations, par exemple, dans le génome humain (voir Science, Vol 291) donnent la répartition suivante : 1,1% pour les exons, 24% pour les introns et 75% pour l ADN intergénique. Compartimentation fonctionnelle du génome: On distingue dans le génome : Une partie du génome dont la fonction est inconnue (84% du génome humain). - Les fragments d ADN intergéniques (non génique) : 54 à 71% du génome humain. - Les fragments d ADN intragéniques : les introns 54 à 71% du génome humain. Les fragments du génome de fonction connue : les gènes. - Les gènes protéiques: L ensemble des exons représentent 2 à 5% du génome humain. Ils sont transcrits en a ARNm par la polymérase II, eux-mêmes traduits en protéines. PLU5231.")
32
Organisation du génome

33
Qu’est ce qu’un gène? Gène protéique: code pour une protéine
Gène régulateur: participe aux mécanismes de maintien du génome Géne non traduits: produit un ARN fonctionnel -Les gènes spécifiant des ARN fonctionnels non traduits: (<2% du génome humain). § Les ARNt (ARN de transfert) § Les ARNr (ARN ribosomaux) § Petits ARN nucléaires :Impliqués, par exemple, dans la maturation des ARN. § Petits ARN cytoplasmiques: Impliqués, par exemple, dans le transport des protéines vers la lumière du réticulum endoplasmique. - Les gènes régulateurs : Les gènes réplicateurs: Leur fonction est de spécifier les sites d'initiation et de terminaison de la réplication. Origines de réplication (1 à 3% du génome humain). Les gènes recombinateurs: Leur fonction est de fournir les sites de reconnaissance pour les enzymes de recombinaison. En effet, les crossing-over ne semblent pas initiés aléatoirement mais seulement au niveau de sites spécifiques. -Les gènes ségrégateurs: Leur fonction est de fournir les sites d'attachement nécessaires à la ségrégation des chromosomes. § Les centromères (<10% ? du génome humain). § Les télomères (0,01 à 0,1% du génome humain). § Les SAR (Scaffold Attachment Region, ou MAR, Matrix Attachment Region) : nécessaires à l'attachement de la molécule d'ADN au squelette chromosomal. (autour de 1% du génome humain). PLU5231
. § Les ARNt (ARN de transfert) § Les ARNr (ARN ribosomaux) § Petits ARN nucléaires :Impliqués, par exemple, dans la maturation des ARN. § Petits ARN cytoplasmiques: Impliqués, par exemple, dans le transport des protéines vers la lumière du réticulum endoplasmique. - Les gènes régulateurs : Les gènes réplicateurs: Leur fonction est de spécifier les sites d initiation et de terminaison de la réplication. Origines de réplication (1 à 3% du génome humain). Les gènes recombinateurs: Leur fonction est de fournir les sites de reconnaissance pour les enzymes de recombinaison. En effet, les crossing-over ne semblent pas initiés aléatoirement mais seulement au niveau de sites spécifiques. -Les gènes ségrégateurs: Leur fonction est de fournir les sites d attachement nécessaires à la ségrégation des chromosomes. § Les centromères (<10% du génome humain). § Les télomères (0,01 à 0,1% du génome humain). § Les SAR (Scaffold Attachment Region, ou MAR, Matrix Attachment Region) : nécessaires à l attachement de la molécule d ADN au squelette chromosomal. (autour de 1% du génome humain). PLU5231.")
34
Structure d’un gène protéique eucaryote
Site d’initiation de la transcription Zone Régulatrice = Promoteur Zone transcrite

35
Structure d’un promoteur
PROMOTEUR DISTAL PROMOTEUR BASAL AMPLIFICATEUR pdb pdb 40 pdb TATA Région régulatrice Région Codante 0-20 kb

36
Structure de la partie codante
AMPLIFICATEUR Intron Intron pdb Exon Exon Exon Région codante Région régulatrice

38
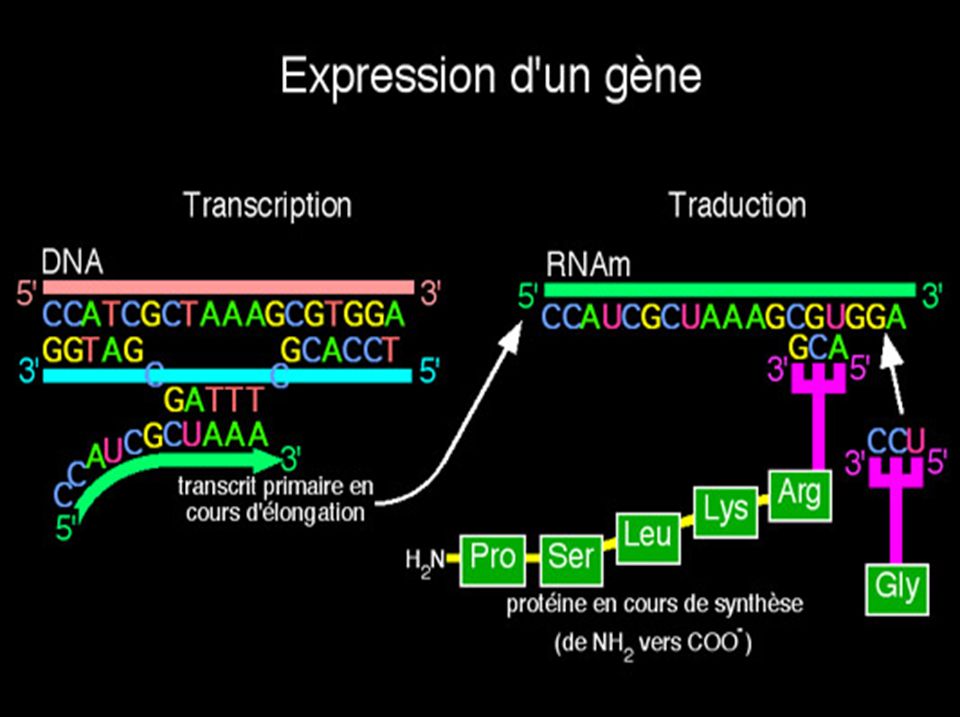
Dogme central de la biologie moléculaire
ADN ARN ARNm protéine Transcription Maturation Traduction Matrice ADN ARN Effecteur ARN pol Très variées Ribosome Produit ARNm Protéine

39
L’expression d’un gène
Procaryotes Définition de la fonction d'un gène La fonction d'un gène est en réalité la fonction biologique que remplit le ou les produits qu'il code, c'est à dire un ARN fonctionnel ou une protéine. Cette fonction se définit à plusieurs niveaux : @ Sa fonction moléculaire : Action biochimique exercée par la protéine Catalyse d'une réaction chimique dans la cellule Interaction avec d'autres molécules, les ligands (protéines, acides nucléiques, petites molécules ou autres). Cette interaction permet de modifier l'activité d'un des partenaires de l'interaction ou de transporter les ligands. @ Sa fonction cellulaire : ne peut être prédite par la fonction biochimique. Processus biologique dans lequel la protéine est impliquée. Ex: la protéine intervient dans la voie de transduction d'un signal donné. Chaque protéine constitue un composant cellulaire faisant partie d'une entité plus large (membrane, cytosol, ribosome, noyau, etc.), ce qui représente un nouveau niveau d'information. @ Sa fonction dans le développement : Contribution du gène à l'embryogenèse .. @ Sa fonction d'adaptation : Contribution du gène à la compétitivité de l'organisme. Eucaryotes PLU5231
. Cette interaction permet de modifier l activité d un des partenaires de l interaction ou de transporter les Sa fonction cellulaire : ne peut être prédite par la fonction biochimique. Processus biologique dans lequel la protéine est impliquée. Ex: la protéine intervient dans la voie de transduction d un signal donné. Chaque protéine constitue un composant cellulaire faisant partie d une entité plus large (membrane, cytosol, ribosome, noyau, etc.), ce qui représente un nouveau niveau d Sa fonction dans le développement : Contribution du gène à l embryogenèse Sa fonction d adaptation : Contribution du gène à la compétitivité de l organisme. Eucaryotes. PLU5231.")
40
Expression d’un gène eucaryote
intron1 intron2 exon1 exon2 exon3 3’UTR 5’UTR intron1 intron2 exon1 exon2 exon3 5’UTR 3’UTR Structure typique d'un gène protéique de vertébré : (5')---Promoteur-exon1-intron1-exon2-intron2-exon3-intron3-Signal de polyadénylation-...-Terminateur de transcription--->(3') Les régions de régulation de l'expression des gènes : - Les promoteurs: Universels chez les êtres vivants. Ils sont situés immédiatement en amont du site de démarrage de la transcription. Les enhancers et silencers: Eléments de modulation spécifiques des eucaryotes. Ils peuvent occuper des localisations très diverses par rapport au gène qu'ils régulent. - le 1er exon contient souvent le codon initiateur (Start codon, code pour Methionine) - le dernier exon contient le codon stop - UTR : Région Non Traduite (Untranslated Region) en 5 ‘ ou en 3’ Structure de l'ARNm mâture (après épissage) : Coiffe—(5'UTR)—CDS—(3'UTR)—PAS—PolyA CDS : Région Codante (Coding Sequence), résulte de la concaténation des exons. Il est précédé du codon Start et suivi du codon Stop. La protéine correspond à la traduction du CDS . ORF: région située entre deux codons stop contenant une portion codante (open reading frame). L’ORF inclue le CDS sur un ARNm. PAS: signal de polyadénylation . PolyA: concaténât d’adénine terminant les ARN messagers matures exon1 exon2 exon3 PLU5231
---Promoteur-exon1-intron1-exon2-intron2-exon3-intron3-Signal de polyadénylation-...-Terminateur de transcription--->(3 ) Les régions de régulation de l expression des gènes : - Les promoteurs: Universels chez les êtres vivants. Ils sont situés immédiatement en amont du site de démarrage de la transcription. Les enhancers et silencers: Eléments de modulation spécifiques des eucaryotes. Ils peuvent occuper des localisations très diverses par rapport au gène qu ils régulent. - le 1er exon contient souvent le codon initiateur (Start codon, code pour Methionine) - le dernier exon contient le codon stop. - UTR : Région Non Traduite (Untranslated Region) en 5 ‘ ou en 3’ Structure de l ARNm mâture (après épissage) : Coiffe—(5 UTR)—CDS—(3 UTR)—PAS—PolyA. CDS : Région Codante (Coding Sequence), résulte de la concaténation des exons. Il est précédé du codon Start et suivi du codon Stop. La protéine correspond à la traduction du CDS . ORF: région située entre deux codons stop contenant une portion codante (open reading frame). L’ORF inclue le CDS sur un ARNm. PAS: signal de polyadénylation . PolyA: concaténât d’adénine terminant les ARN messagers matures. exon1. exon2. exon3. PLU5231.")
41
Initiation de la transcription
Les promoteurs des gènes eucaryotes: Deux régions proximale et distale en fonction de la distance au site d’initiation de la transcription: La région proximale contient les éléments de reconnaissance et d’interaction avec la machinerie basale de transcription. La région distale contient les éléments de régulation spécifiques du gène. Ils contiennent les éléments de réponse aux facteurs hormonaux, métaboliques, immunologiques, de stress etc… Les éléments de réponse sont de courtes séquence (4 à 15 nucléotides) reconnus de façon très spécifique par des protéines particulières appelées facteurs de transcription. Initiation de la transcription sur le promoteur proximal : Les facteurs de transcription ubiquitaires basaux (TFII A, B … , H) se fixent sur la boîte TATA et recrutent l’ ARN polymérase II (ARN polII). La transcription démarre et produit un ARN dit hétérogène nucléaire hnARN. Il contient une copie entière du gène incluant les introns. ATTENTION: L’ARN polII fabrique l’ARN en synthétisant une chaîne complémentaire au brin antisens qui est donc une copie conforme du brin codant. Elle remplace les T par des U. PLU5231
 reconnus de façon très spécifique par des protéines particulières appelées facteurs de transcription. Initiation de la transcription sur le promoteur proximal : Les facteurs de transcription ubiquitaires basaux (TFII A, B … , H) se fixent sur la boîte TATA et recrutent l’ ARN polymérase II (ARN polII). La transcription démarre et produit un ARN dit hétérogène nucléaire hnARN. Il contient une copie entière du gène incluant les introns. ATTENTION: L’ARN polII fabrique l’ARN en synthétisant une chaîne complémentaire au brin antisens qui est donc une copie conforme du brin codant. Elle remplace les T par des U. PLU5231.")
42
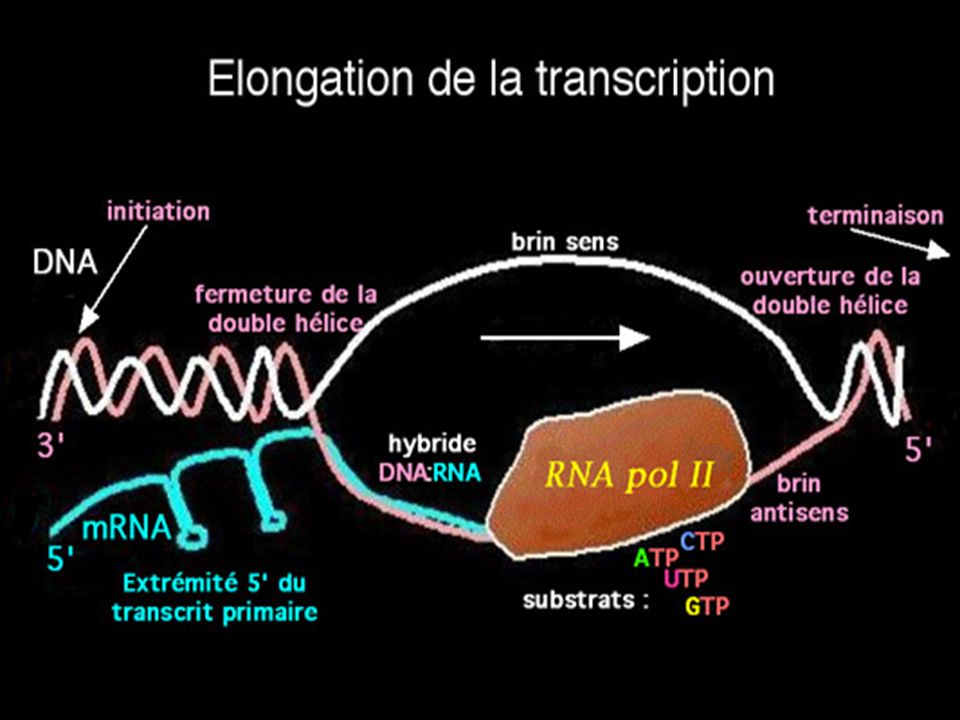
Elongation de la transcription

44
Maturation du transcrit primaire

45
Polyadénylation

46
Structure de l’ARN intermédiaire

47
Epissage du messager

48
Traduction

49
Code génétique

50
Code génétique bis

51
L’ARN de transfert

52
Initiation de la traduction

53
Incorporation d’un acide aminé

54
Translocation du ribosome

55
Elongation de la traduction

56
Terminaison de la traduction

57
Polyribosome

58
Structure de l’ARNm

59
Stabilité du messager

60
Code dégénéré

61
Contrôle de l’expression d’un gène
Enveloppe nucléaire Pore nucléaire ARN primaire Protéine inactive ADN ARNm ARNm Protéine Contrôle de la transcription Contrôle de la maturation Contrôle de la traduction Contrôle de l’activité Cytoplasme Noyau

62
Comment fonctionne le génome
Quelle est l’organisation du génome? Comment est lue l’information contenue dans le génome? Mise en place du programme génétique

63
Organisation des gènes dans les organismes
Le génome est l’ensemble des gènes portés par l’ensemble de nos chromosomes. Comment se mettent en place les programmes génétiques? Quelles sont les cascades d’évènements qui permettent la mise en place et le contrôle du programme génétique? Un organisme se forme à partir d’une seule cellule, l’oeuf , qui contient une gamète mâle et une gamète femelle. Au final on obtient un organisme contenant plus de 200 types cellulaires différents organisés en tissus. Le processus s’appelle la différenciation des cellules. Pendant cette différenciation les cellules perdent la possibilité de donner naissance à de nouvelles lignées cellulaires mais acquièrent des fonctionnalités nouvelles et uniques. L’Adn est il modifié irréversiblement pendant le processus? PLU5231

64
Paradoxe !!!!

65
Complexité du génome Humain
Taille Mb pour gènes Nature répétitive Séquences répétées localement ADN satellite Séquences répétées dispersées SINES (Short Interspersed Repeated Sequences) Ex: ALU, 300 pb tous les 6000 nucleotides LINES (Long Interspersed Repeated Sequenes) Ex: L1, 5 kb, copies dans génome Rôle de l’ADN non génique ??? Régulation globale de l’expression des gènes Nucléosquelette
 Ex: ALU, 300 pb tous les 6000 nucleotides. LINES (Long Interspersed Repeated Sequenes) Ex: L1, 5 kb, copies dans génome. Rôle de l’ADN non génique Régulation globale de l’expression des gènes. Nucléosquelette.")
66
Epissages alternatifs

67
L’ADN conserve toutes les informations pour faire un organisme entier.
PLU5231

68
Le contrôle combinatoire de gènes pour générer différents types cellulaires:
Le schéma hypothétique illustre comment les combinaisons de quelques protéines régulatrices de gènes peuvent générer de nombreux types cellulaires différents durant le développement. Dans ce schéma simple la « décision » de synthétiser une nouvelle protéine régulatrice de gène (désignée par un cercle numéroté) est prise à chaque division cellulaire. La répétition de cette règle simple permet de fabriquer huit types cellulaires (de A à H) en utilisant seulement 3 protéines régulatrices différentes. Chacun de ces types cellulaires hypothétiques exprimerait alors un panel de gènes très spécifique, selon la combinaison des protéines régulatrices de gènes présentes en lui. PLU5231
 est prise à chaque division cellulaire. La répétition de cette règle simple permet de fabriquer huit types cellulaires (de A à H) en utilisant seulement 3 protéines régulatrices différentes. Chacun de ces types cellulaires hypothétiques exprimerait alors un panel de gènes très spécifique, selon la combinaison des protéines régulatrices de gènes présentes en lui. PLU5231.")
69
Initiation de la transcription
Activateurs Répresseur FT FT FT Séquences régulatrices d’un gène eucaryote typique: L'action des protéines régulatrices fixées à l'ADN sur le contrôle de la transcription pouvant avoir lieu à distance du promoteur, les séquences de régulation peuvent être réparties sur de longues distances d'ADN. Nous emploierons ici le terme de régions modulaires ou région de contrôle génique pour désigner l'ensemble des séquences d'ADN nécessaires à l'initiation de la transcription et au contrôle du niveau de cette transcription. Ainsi, ces régions modulaires sont constituées du promoteur sur lequel s'assemblent les facteurs de transcription généraux et la polymérase, et de séquences régulatrices, sur lesquelles se fixent les protéines régulatrices qui déterminent à quelle vitesse doit se faire le processus d'assemblage au niveau du promoteur. Chez les eucaryotes supérieurs, il n'est pas rare de trouver des séquences régulatrices réparties sur des distances allant jusqu'à paires de nucléotides, bien qu'une grande partie de cet ADN serve davantage de séquences d'espacement (spacer) et ne soit pas reconnue par des protéines régulatrices. Bien que la plupart des protéines régulatrices se lient aux éléments amplificateurs et activent la transcription des gènes, certaines fonctionnent comme des régulateurs négatifs RNA Pol II Région codante Promoteur basal Coactivateurs Facteurs d’initiation PLU5231
 et ne soit pas reconnue par des protéines régulatrices. Bien que la plupart des protéines régulatrices se lient aux éléments amplificateurs et activent la transcription des gènes, certaines fonctionnent comme des régulateurs négatifs. RNA Pol II. Région. codante. Promoteur basal. Coactivateurs. Facteurs d’initiation. PLU5231.")
70
Régulation du niveau d’expression des gènes
La reconnaissance moléculaire repose généralement sur une correspondance exacte entre les surfaces des deux molécules, et l'étude des protéines régulatrices a fourni quelques-uns des plus clairs exemples de ce principe. Une protéine régulatrice reconnaît une séquence d'ADN spécifique, car sa surface est fortement complémentaire des éléments de surface caractéristiques de la double hélice. La protéine établit à ce niveau de multiples points de contact avec l'ADN, à l'aide de liaisons hydrogène et ioniques, et d'interactions hydrophobes. Bien que chacun de ces contacts soit faible, la totalité des 20 points, ou plus, qui sont établis spécifiquement à l'interface ADN-protéine, permet d'assurer une interaction à la fois extrêmement spécifique et particulièrement forte. En fait, les interactions ADN-protéine sont parmi les plus étroites et les plus spécifiques des interactions moléculaires connues en biologie. Bien que chaque exemple de reconnaissance ADN-protéine soit unique, des études ont permis de montrer que beaucoup de ces protéines contenaient un des motifs communs de fixation à l'ADN. Chacun de ces motifs utilise soit des hélices alpha, soit des feuillets ß pour se fixer au grand sillon de l'ADN; ce sillon, contient suffisamment d'informations pour qu'une séquence d'ADN puisse être distinguée d'une autre. PLU5231

71
Interaction protéine -ADN
Interaction des protéines régulatrices avec l’ADN Il existe des milliers de protéines régulatrices différentes. Celles-ci varient en fonction des gènes, et sont généralement présentes en très petite quantité dans la cellule. La plupart reconnaissent une séquence d'ADN qui leur est spécifique, contenant un des motifs de fixation. Ces protéines assurent aux gènes donnés d'un organisme une transcription spécifique. Chez les eucaryotes supérieurs, différents éventails de protéines régulatrices sont présents dans chaque type cellulaire. La plupart des protéines régulatrices activant la transcription, ou protéines activatrices de l'expression des gènes, possèdent au moins deux domaines ayant des fonctions différentes. Habituellement, un domaine est responsable de la reconnaissance d'une séquence d'ADN spécifique, l’élément de réponse, et contient un des motifs de fixation à l'ADN décrits plus loin. Dans les cas les plus simples, l'autre domaine contacte la machinerie de transcription et accélère le taux d'initiation de la transcription. Ce type de structure modulaire fut mis en évidence par l'utilisation de techniques de génie génétique, permettant de générer des protéines hybrides contenant le domaine d'activation d'une protéine, fusionné au domaine de fixation à l'ADN d'une autre protéine. PLU5231

72
Interaction protéine - ADN
La fixation à l’ADN des facteurs de transcription: Il existe 4 grandes familles de domaines de fixation à l’ADN : Protéines Hélice-tour-hélice Protéines à doigts de zinc Protéines à répétitions de leucine Protéines Hélice-boucle-hélice Ne sont pas détaillés dans ce cours cela prendrait trop de temps. PLU5231

73
Localisation des éléments régulateurs
Les régions régulatrices des gènes: exemple de la globine Les protéines CP1 sont présentes dans de très nombreux types cellulaires alors que les protéines GATA1 ne sont présentes que dans un très petit nombre de cellules dont les cellules précurseurs des globules rouges. Ces protéines contribuent à la spécificité cellulaire de l’expression de la globine. Notez que les régions régulatrices peuvent se situer en amont du gène comme en aval. PLU5231

Présentations similaires











 Phosphatases: retirent un phosphate.>")







