Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

3
Les enzymes : outils de biologie moléculaire
Enzymes de restriction: endonucléases Kinases: ajoutent un phosphate (P*) Phosphatases: retirent un phosphate Ligases: joignent un OH et un phosphate ADN Polymérase: ADN => ADN Reverse transcriptase : ARN => ADNc
 Phosphatases: retirent un phosphate. Ligases: joignent un OH et un phosphate. ADN Polymérase: ADN => ADN. Reverse transcriptase : ARN => ADNc.")
4
Nomenclature des enzymes de restriction

6
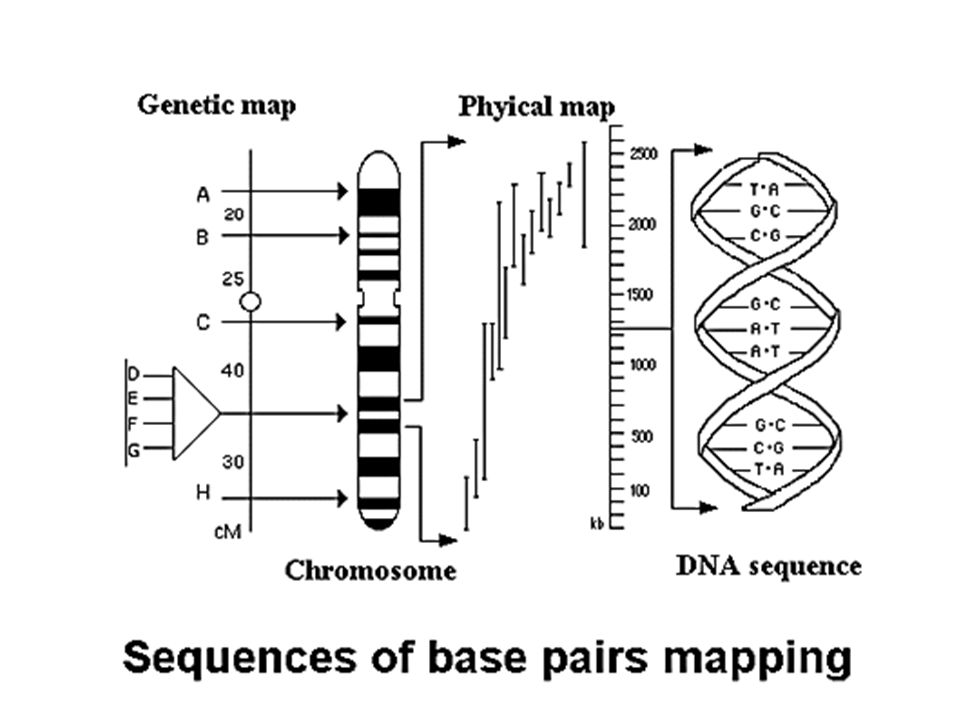
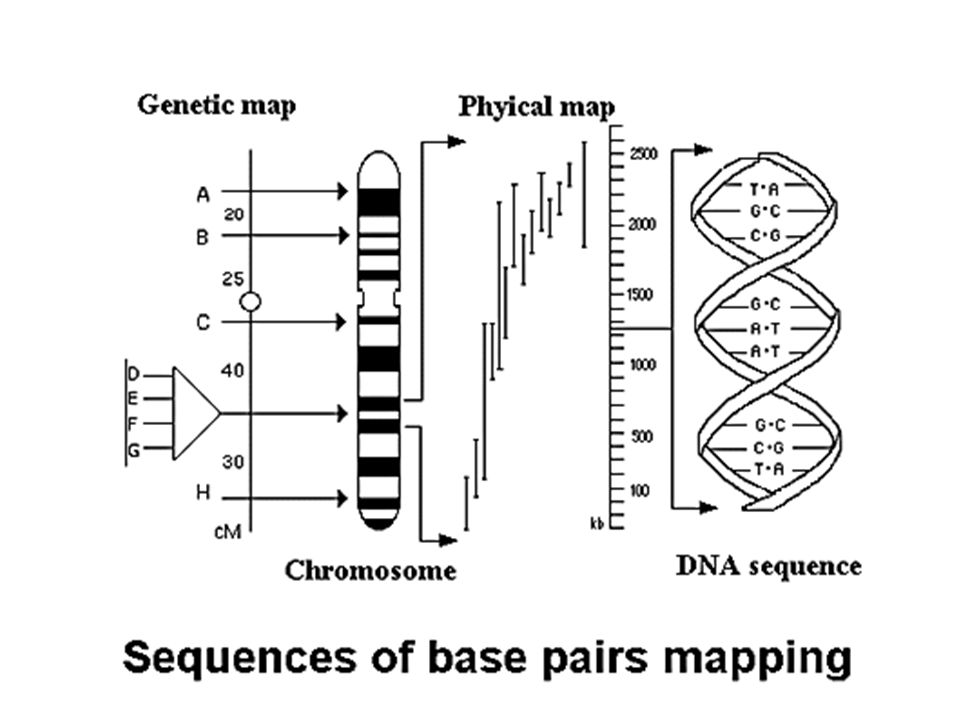
Tailles des séquences incluses
Vecteurs de clonage Tailles des séquences incluses Plasmide bactérien ( 3-4 kb ) Phage λ ( 9-22 kb ) Cosmide ( ≈ 45 kb ) PAC : P1-derived Artificial Chromosome ( kb ) BAC : Bacterial Artificial Chromosome ( kb ) YAC : Yeast Artificial Chromosome ( kb )
 Phage λ ( 9-22 kb ) Cosmide ( ≈ 45 kb ) PAC : P1-derived Artificial Chromosome ( kb ) BAC : Bacterial Artificial Chromosome ( kb ) YAC : Yeast Artificial Chromosome ( kb )")
9
NOMBRE DE CLONES A OBTENIR

12
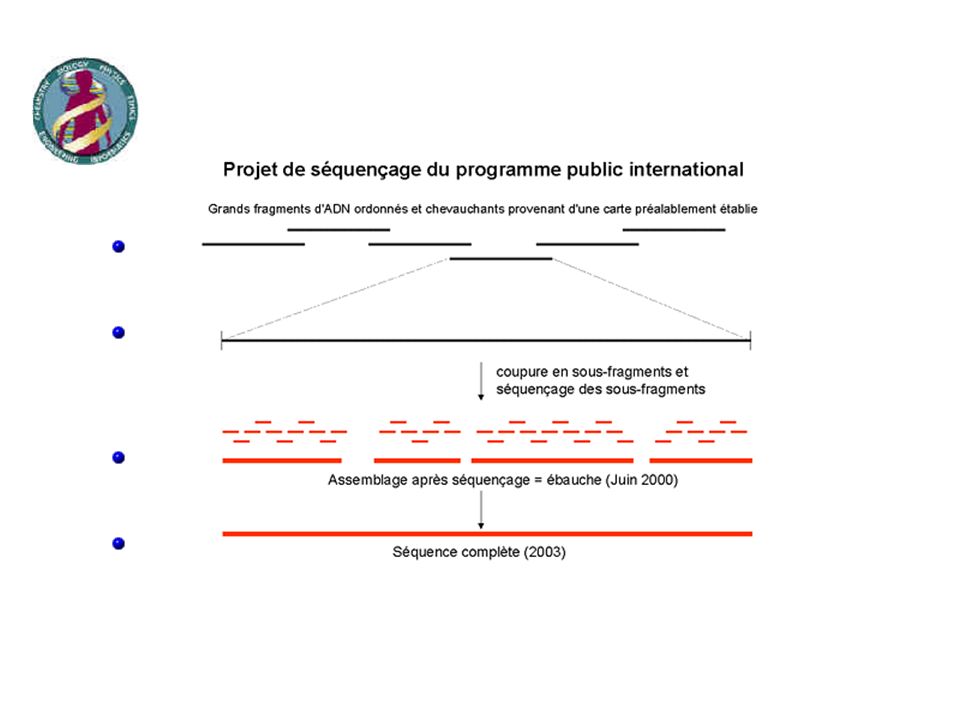
PROJET PUBLIC: ETAPE 1

13
PROJET PUBLIC: ETAPE 2

14
PROJET PRIVE : CELERA

15
PCR : Polymerase Chain Reaction
Amplification d’ADN. Base pour différentes techniques de biologie moléculaire : Séquençage Amplification de l’ADN pour le clonage mutation ponctuelle « differential display » préparation d’ADNc « RT-PCR » détermination de polymorphisme entre génomes (RFLP…) ….
 ….")
18
Séquençage nucléotide : méthode de Sanger
ddNTP : analogues structuraux des dNTP. ddNTP : incapables de réaliser une liaison phosphodiester. ADN polymérase incorpore dNTP ou ddNTP.

19
Séquençage nucléotide : méthode de Sanger

20
Séquençage : Méthode de Sanger Électrophorèse

21
Séquençage nucléotide : méthode de Sanger
Liaison de l’amorce avec l’ADN à séquencer. La fixation des ddNTP aux brins d’ADN va créer des brins de différentes tailles. Les brins vont migrer sur un gel d’électrophorèse selon leur taille : le plus petit migre le plus vite.

22
Séquençage nucléotide : méthode de Sanger

23
Séquençage nucléotide : méthode de Sanger
Automatisation de la méthode : Ajout sur les ddNTP de fluorochrome de différentes couleurs. 1 seul tube regroupant les ddNTP. Lecture par un laser des fragments qui migrent sur le gel. Stockage des données dans la mémoire de l’ordinateur.

24
Séquençage nucléotide : méthode de Sanger

25
Les ddNTPs fluos

27
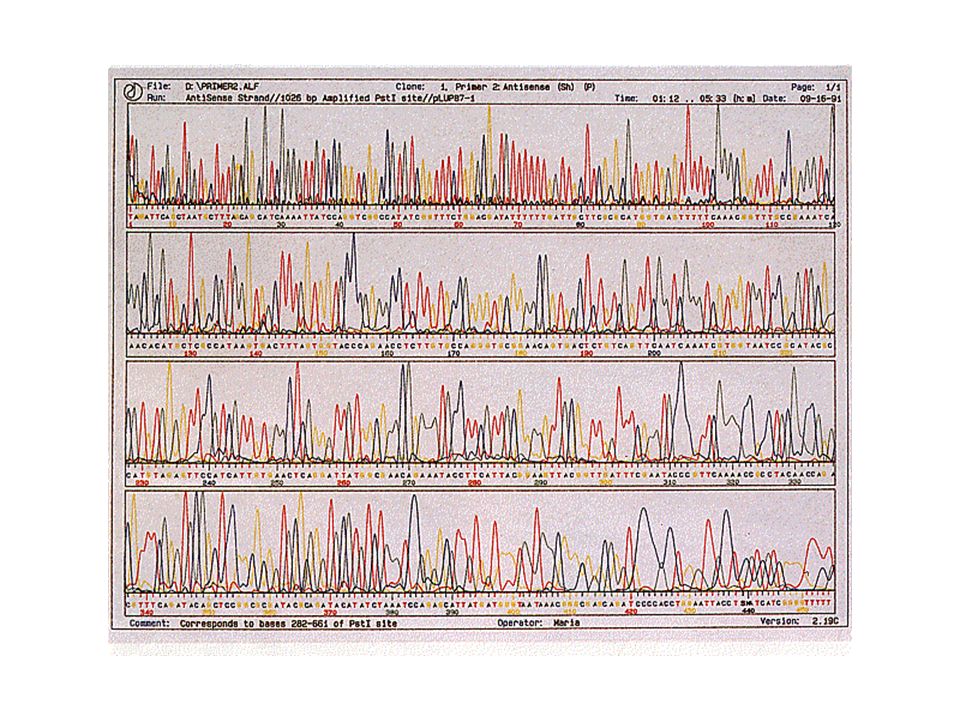
Séquençage nucléotide : méthode de Sanger

29
Automatisation Séquençage sur capillaires :megabace
Permet de séquencer 96 ou 386 échantillons en parallèle

35
RESTE A LIRE LA SEQUENCE ET COMPRENDRE
TOUTES LES INFORMATIONS CONTENUES DANS LE GENOME ANNOTATION DU GENOME

36
Comment fonctionne le génome
Quelle est l’organisation du génome? Comment est lue l’information contenue dans le génome? Mise en place du programme génétique

37
Paradoxe !!!!

38
Complexité du génome Humain
Taille Mb pour gènes Nature répétitive Séquences répétées localement ADN satellite Séquences répétées dispersées SINES (Short Interspersed Repeated Sequences) Ex: ALU, 300 pb tous les 6000 nucleotides LINES (Long Interspersed Repeated Sequenes) Ex: L1, 5 kb, copies dans génome Rôle de l’ADN non génique ??? Régulation globale de l’expression des gènes Nucléosquelette
 Ex: ALU, 300 pb tous les 6000 nucleotides. LINES (Long Interspersed Repeated Sequenes) Ex: L1, 5 kb, copies dans génome. Rôle de l’ADN non génique Régulation globale de l’expression des gènes. Nucléosquelette.")
39
Complexité du génome humain
Pourquoi les gènes sont dispersés? Pourquoi autant de répétitions? Pourquoi les gènes sont morcelés? Toutes les parties du génome sont elles utilisées dans toutes les cellules? Le génome évolue t-il avec la spécialisation des cellules?

40
Epissages alternatifs

41
Que permet l’existence des introns: l’épissage alternatif et l’exon shuffling
L'épissage alternatif est l'un des mécanismes clés utilisés par les vertébrés pour augmenter la diversité protéique. Ce mécanisme permet, à partir d'un gène unique, la synthèse de plusieurs protéines dont les propriétés biologiques diffèrent suivant les tissus, le stade de développement ou encore les différents stimuli que reçoit la cellule. Suite au séquençage du génome humain, il est apparu que plus de 60% des gènes verraient leur expression régulée par épissage alternatif. Ex : Les gènes tropomyosine (TM) constituent une famille multigénique dont les composants sont des marqueurs des principaux lignages musculaires (squelettique, cardiaque et lisse). Décrypter les mécanismes de contrôle qui s'exercent sur l'épissage est donc indispensable non seulement pour mieux comprendre le fonctionnement d'une cellule mais aussi certaines pathologies dont l'origine réside dans un défaut d'épissage. Au cours de l'évolution, certains gènes ont pu être construits à partir d'exons empruntés à d'autres gènes ; les introns auraient facilités la mobilité des exons dans le génome ("shuffling " : action de battre les cartes = redistribution par brassage d'exons).
 constituent une famille multigénique dont les composants sont des marqueurs des principaux lignages musculaires (squelettique, cardiaque et lisse). Décrypter les mécanismes de contrôle qui s exercent sur l épissage est donc indispensable non seulement pour mieux comprendre le fonctionnement d une cellule mais aussi certaines pathologies dont l origine réside dans un défaut d épissage. Au cours de l évolution, certains gènes ont pu être construits à partir d exons empruntés à d autres gènes ; les introns auraient facilités la mobilité des exons dans le génome ( shuffling : action de battre les cartes = redistribution par brassage d exons).")
42
Complexité du génome humain
Pourquoi les gènes sont dispersés? Pourquoi autant de répétitions? Pourquoi les gènes sont morcelés? Toutes les parties du génome sont elles utilisées dans toutes les cellules? Le génome évolue t-il avec la spécialisation des cellules?

43
L’ADN conserve toutes les informations pour faire un organisme entier.

44
Le contrôle combinatoire de gènes pour générer différents types cellulaires:
Le schéma hypothétique illustre comment les combinaisons de quelques protéines régulatrices de gènes peuvent générer de nombreux types cellulaires différents durant le développement. Dans ce schéma simple la « décision » de synthétiser une nouvelle protéine régulatrice de gène (désignée par un cercle numéroté) est prise à chaque division cellulaire. La répétition de cette règle simple permet de fabriquer huit types cellulaires (de A à H) en utilisant seulement 3 protéines régulatrices différentes. Chacun de ces types cellulaires hypothétiques exprimerait alors un panel de gènes très spécifique, selon la combinaison des protéines régulatrices de gènes présentes en lui.
 est prise à chaque division cellulaire. La répétition de cette règle simple permet de fabriquer huit types cellulaires (de A à H) en utilisant seulement 3 protéines régulatrices différentes. Chacun de ces types cellulaires hypothétiques exprimerait alors un panel de gènes très spécifique, selon la combinaison des protéines régulatrices de gènes présentes en lui.")
45
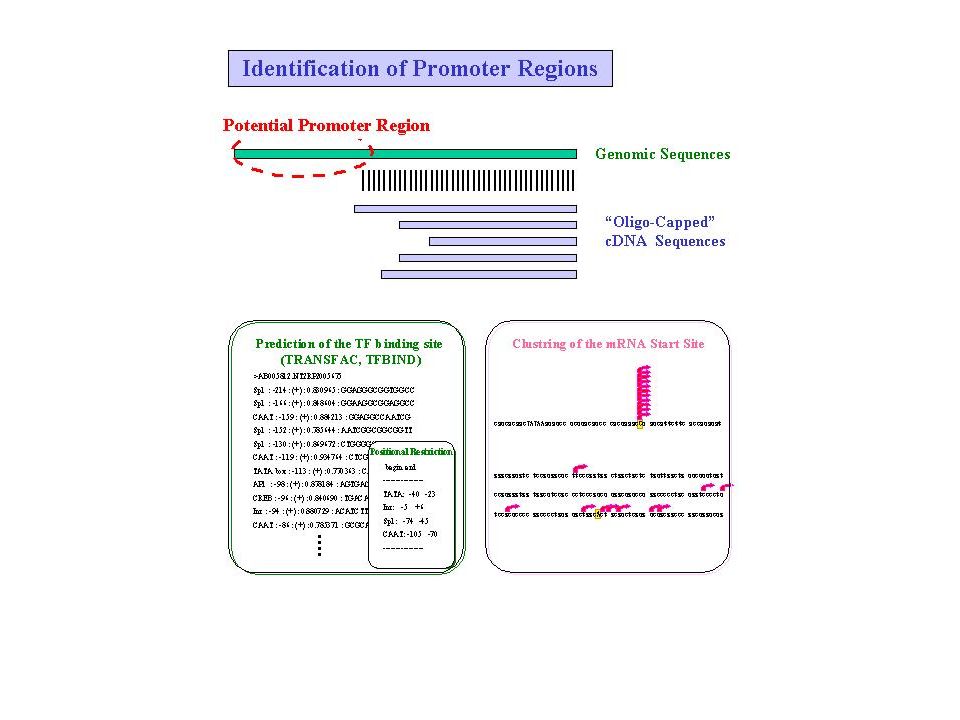
Initiation de la transcription
Activateurs Répresseur FT FT FT Séquences régulatrices d’un gène eucaryote typique: L'action des protéines régulatrices fixées à l'ADN sur le contrôle de la transcription pouvant avoir lieu à distance du promoteur, les séquences de régulation peuvent être réparties sur de longues distances d'ADN. Nous emploierons ici le terme de régions modulaires ou région de contrôle génique pour désigner l'ensemble des séquences d'ADN nécessaires à l'initiation de la transcription et au contrôle du niveau de cette transcription. Ainsi, ces régions modulaires sont constituées du promoteur sur lequel s'assemblent les facteurs de transcription généraux et la polymérase, et de séquences régulatrices, sur lesquelles se fixent les protéines régulatrices qui déterminent à quelle vitesse doit se faire le processus d'assemblage au niveau du promoteur. Chez les eucaryotes supérieurs, il n'est pas rare de trouver des séquences régulatrices réparties sur des distances allant jusqu'à paires de nucléotides, bien qu'une grande partie de cet ADN serve davantage de séquences d'espacement (spacer) et ne soit pas reconnue par des protéines régulatrices. Bien que la plupart des protéines régulatrices se lient aux éléments amplificateurs et activent la transcription des gènes, certaines fonctionnent comme des régulateurs négatifs RNA Pol II Région codante Promoteur basal Coactivateurs Facteurs d’initiation
 et ne soit pas reconnue par des protéines régulatrices. Bien que la plupart des protéines régulatrices se lient aux éléments amplificateurs et activent la transcription des gènes, certaines fonctionnent comme des régulateurs négatifs. RNA Pol II. Région. codante. Promoteur basal. Coactivateurs. Facteurs d’initiation.")
46
Régulation du niveau d’expression des gènes
La reconnaissance moléculaire repose généralement sur une correspondance exacte entre les surfaces des deux molécules, et l'étude des protéines régulatrices a fourni quelques-uns des plus clairs exemples de ce principe. Une protéine régulatrice reconnaît une séquence d'ADN spécifique, car sa surface est fortement complémentaire des éléments de surface caractéristiques de la double hélice. La protéine établit à ce niveau de multiples points de contact avec l'ADN, à l'aide de liaisons hydrogène et ioniques, et d'interactions hydrophobes. Bien que chacun de ces contacts soit faible, la totalité des 20 points, ou plus, qui sont établis spécifiquement à l'interface ADN-protéine, permet d'assurer une interaction à la fois extrêmement spécifique et particulièrement forte. En fait, les interactions ADN-protéine sont parmi les plus étroites et les plus spécifiques des interactions moléculaires connues en biologie. Bien que chaque exemple de reconnaissance ADN-protéine soit unique, des études ont permis de montrer que beaucoup de ces protéines contenaient un des motifs communs de fixation à l'ADN. Chacun de ces motifs utilise soit des hélices alpha, soit des feuillets ß pour se fixer au grand sillon de l'ADN; ce sillon, contient suffisamment d'informations pour qu'une séquence d'ADN puisse être distinguée d'une autre.

47
Interaction protéine -ADN
Interaction des protéines régulatrices avec l’ADN Il existe des milliers de protéines régulatrices différentes. Celles-ci varient en fonction des gènes, et sont généralement présentes en très petite quantité dans la cellule. La plupart reconnaissent une séquence d'ADN qui leur est spécifique, contenant un des motifs de fixation. Ces protéines assurent aux gènes donnés d'un organisme une transcription spécifique. Chez les eucaryotes supérieurs, différents éventails de protéines régulatrices sont présents dans chaque type cellulaire. La plupart des protéines régulatrices activant la transcription, ou protéines activatrices de l'expression des gènes, possèdent au moins deux domaines ayant des fonctions différentes. Habituellement, un domaine est responsable de la reconnaissance d'une séquence d'ADN spécifique, l’élément de réponse, et contient un des motifs de fixation à l'ADN décrits plus loin. Dans les cas les plus simples, l'autre domaine contacte la machinerie de transcription et accélère le taux d'initiation de la transcription. Ce type de structure modulaire fut mis en évidence par l'utilisation de techniques de génie génétique, permettant de générer des protéines hybrides contenant le domaine d'activation d'une protéine, fusionné au domaine de fixation à l'ADN d'une autre protéine.

48
Interaction protéine – ADN
La fixation à l’ADN des facteurs de transcription: Il existe 4 grandes familles de domaines de fixation à l’ADN : Protéines Hélice-tour-hélice Protéines à doigts de zinc Protéines à répétitions de leucine Protéines Hélice-boucle-hélice Ne sont pas détaillés dans ce cours cela prendrait trop de temps.

49
Quelques chiffres sur le génome
Exons 1.1 % du génome Introns 70 % du génome Partie avec fonction inconnue 80% Gènes protéiques 5% Gènes d’ARN spécifiques (ARNt,r) <2% Gènes régulateurs (réplicateurs, recombinateurs, ségrégateurs) # 10%
 <2% Gènes régulateurs (réplicateurs, recombinateurs, ségrégateurs) # 10%")
50
Identifier les gènes spécifiques d’un tissu
Tous les gènes possibles ADN Tous les gènes nécessaires

51
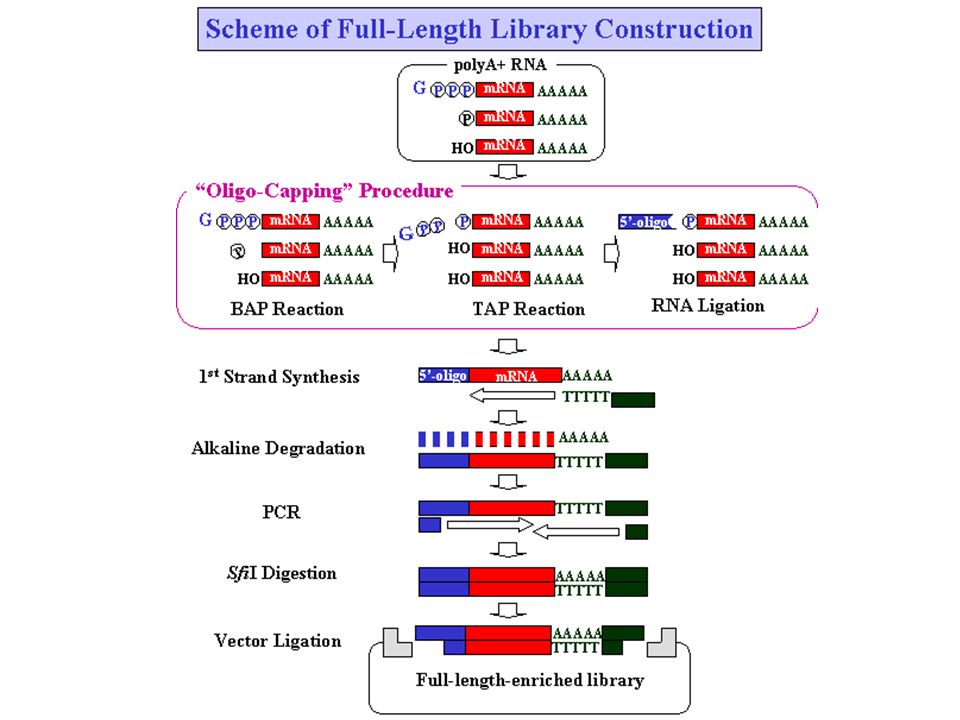
EST Libraries construction
Collection d’ESTs

58
Suivre l’expression des gènes

59
La Bioinformatique Les domaines explorés sont Génomes Transriptomes
Protéomes Physiome Génomes : matériel héréditaire, son organisation et son maintien Transriptomes : le monde l’ARN . Donne une copie ou photo instantanée a un temps T dans une condition donéee de l’ensemble des ARN d’une cellule Protéomes : même chose pour les protéines Physiome: Etude au niveau d’un organisme Metabolome: état d’une voie métabolique a un moment donné dans une condition physiologique donnée

60
Les séquences Définition: suite de constituants unitaires des chaînes moléculaires représentées par un code lettre dans un chaîne de caractères. Ex: ADN suite de ATCG Ex : protéine suite des 20 AA Sont les objets manipulés le plus par les bioinformaticiens. Les grandes banques de séquences généralistes telles que Genbank ou l'EMBL sont des projets internationaux et constituent des leaders dans le domaine. Elles sont maintenant devenues indispensables à la communauté scientifique car elles regroupent des données et des résultats essentiels dont certains ne sont plus reproduits dans la littérature scientifique. Leur principale mission est de rendre publiques les séquences qui ont été déterminées, ainsi un des premiers intérêts de ces banques est la masse de séquences qu'elles contiennent. On y trouve également une bibliographie et une expertise biologique directement liées aux séquences traitées. Pour que l'utilisateur puisse s'y repérer, toutes ces informations sont mises à la disposition de la collectivité scientifique selon une organisation en rubriques

61
Exemple de séquence >mutant 1
MVSKLSQLQTEHLAALLESGLSKEALIQALGEPGPYLLAGEGPLDKGESCGGGRGELAEL PNGLGETRGSEDETDDDGEDFTPPILKELENLSPEEAAHQKAVVETLLQEDPWRVAKMVK SYLQQHNIPQREVVDTTGLNQSHLSQHLNKGTPMKTQKRAALYTWYVRKQREVAQQFTHA GQGGLIEEPTGDELPTKKGRRNRFKWGPASQQILFQAYERQKNPSKEERETLVEECNRAE CIQRGVSPSQAQGLGSNLVTEVRVYNWFANRRKEEAFRHKLAMDTYSGPPPGPGPGPALP AHSSPGLPPPALSPSKVHGVRXGQPATSETAEVPSSSGGPLVTVSTPLHQVSPTGLEPSH SLLSTEAKLVSAAGGPLPPVSTLTALHSLEQTSPGLNQQPQNLIMASLPGVMTIGPGEPA SLGPTFTNTGASTLVIGLASTQAQSVPVINSMGSSLTTLQPVQFSQPLHPSYQQPLMPPV QSHVTQSPFMATMAQLQSPHALYSHKPEVAQYTHTGLLPQTMLITDTTNLSALASLTPTK QVFTSDTEASSESGLHTPASQATTLHVPSQDPAGIQHLQPAHRLSASPTVSSSSLVLYQS SDSSNGQSHLLPSNHSVIETFISTQMASSSQ Séquence de protéine au format fasta

62
Comparaison de séquences
Il existe plusieurs termes permettant de nommer la ressemblance entre deux séquences biologiques. La similarité est une quantité qui se mesure en % d’identité, identité elle même définie comme une ressemblance parfaite entre deux séquences. L’homologie quand à elle est une propriété de séquences qui a une connotation évolutive. Deux séquences sont dites homologues si elles possèdent un ancêtre commun. L’homologie présente la particularité d’être transitive. Si A est homologue à B et B homologue à C alors A est homologue à C même si A et C se ressemblent très peu. L’homologie se mesure par la similarité. On considère qu’une similarité significative est signe d’homologie sauf si les séquences présentent une faible complexité. L’inverse n’est par contre pas vrai. Une absence totale de similarité ne veut pas dire non-homologie.

63
Les outils d’alignement
Un alignement global considère l'ensemble des éléments de chacune des séquences. Si les longueurs des séquences sont différentes, alors des insertions devront être faites dans la séquence la plus petite pour arriver à aligner les deux séquences d'une extrémité à l'autre. Dans le cas où les longueurs sont très différentes, il est possible d'appliquer ce principe d'alignement global seulement en considérant chaque position d'une séquence longue comme étant un point de départ d'alignement avec une séquence courte. Cependant dans un alignement global, si uniquement de courts segments sont très similaires entre deux séquences, les autres parties des séquences risquent de diminuer le poids de ces régions. C'est pourquoi d'autres algorithmes d'alignements, dits locaux, basés sur la localisation des similarités sont nés. Le but de ces alignements locaux est de trouver sans prédétermination de longueur les zones les plus similaires entre deux séquences. L'alignement local comporte donc une partie de chacune des séquences et non la totalité des séquences comme dans la plupart des alignement globaux.

64
Exemple d’alignement Score = 1213 bits (612), Expect = 0.0
Identities = 621/624 (99%) Strand = Plus / Plus Query: 374 aagcccttcagcggccagtagcatctgactttgagcctcagggtctgagtgaagccgctc 433 |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| Sbjct: 134 aagcccttcagcggccagtagcatctgactttgagcctcagggtctgagtgaagccgctc 193 Query: 434 gttggaactccaaggaaaaccttctcgctggacccagtgaaaatgaccccaaccttttcg 493 Sbjct: 194 gttggaactccaaggaaaaccttctcgctggacccagtgaaaatgaccccaaccttttcg 253 Query: 494 ttgcactgtatgattttgtggccagtggagataacactctaagcataactaaaggtgaaa 553 Sbjct: 254 ttgcactgtatgattttgtggccagtggagataacactctaagcataactaaaggtgaaa 313 Query: 554 agctccgggtcttaggctataatcacaatggggaatggtgtgaagcccaaaccaaaaatg 613 Sbjct: 314 agctccgggtcttaggctataatcacaatggggaatggtgtgaagcccaaaccaaaaatg 373
 Strand = Plus / Plus. Query: 374 aagcccttcagcggccagtagcatctgactttgagcctcagggtctgagtgaagccgctc 433. |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||| Sbjct: 134 aagcccttcagcggccagtagcatctgactttgagcctcagggtctgagtgaagccgctc 193. Query: 434 gttggaactccaaggaaaaccttctcgctggacccagtgaaaatgaccccaaccttttcg 493. Sbjct: 194 gttggaactccaaggaaaaccttctcgctggacccagtgaaaatgaccccaaccttttcg 253. Query: 494 ttgcactgtatgattttgtggccagtggagataacactctaagcataactaaaggtgaaa 553. Sbjct: 254 ttgcactgtatgattttgtggccagtggagataacactctaagcataactaaaggtgaaa 313. Query: 554 agctccgggtcttaggctataatcacaatggggaatggtgtgaagcccaaaccaaaaatg 613. Sbjct: 314 agctccgggtcttaggctataatcacaatggggaatggtgtgaagcccaaaccaaaaatg 373.")
65
Les médicaments Beaucoup d'informations dans les cellules se propagent grâce à des molécules via un système de complémentarité de forme. On appelle cela le modèle « clé/serrure », on voit le récepteur du signal comme une serrure et le signal comme une clé. La molécule signal est capable de s'arrimer à la molécule récepteur, Ce contact va déclencher la réaction adéquate. Un même passe partout peut entrer dans différentes serrures d'où les effets secondaires possibles de ce genre de médicaments. Quand le signal fait défaut, on peut le remplacer par un médicament. La plupart des médicaments actuels sont en fait des “passe-partout” capables de remplacer certaines clefs.Si on trouve le gène correspondant à la molécule signal, on a un médicament qui n'aura pas les problèmes d'effet secondaire. On peut voir les effets secondaires de certains médicaments comme une erreur d'adressage, ne définissant pas une « clef assez précise.». Il y a un parallèle informatique avec l'erreur de pointeur (en langage C par exemple), qui peut amener à des comportements erratiques. De même l'effet secondaire peut éventuellement être sans aucun rapport avec la cible originelle. Exemple: Effets secondaire de l'aspirine sur l'estomac.
, qui peut amener à des comportements erratiques. De même l effet secondaire peut éventuellement être sans aucun rapport avec la cible originelle. Exemple: Effets secondaire de l aspirine sur l estomac.")
Présentations similaires


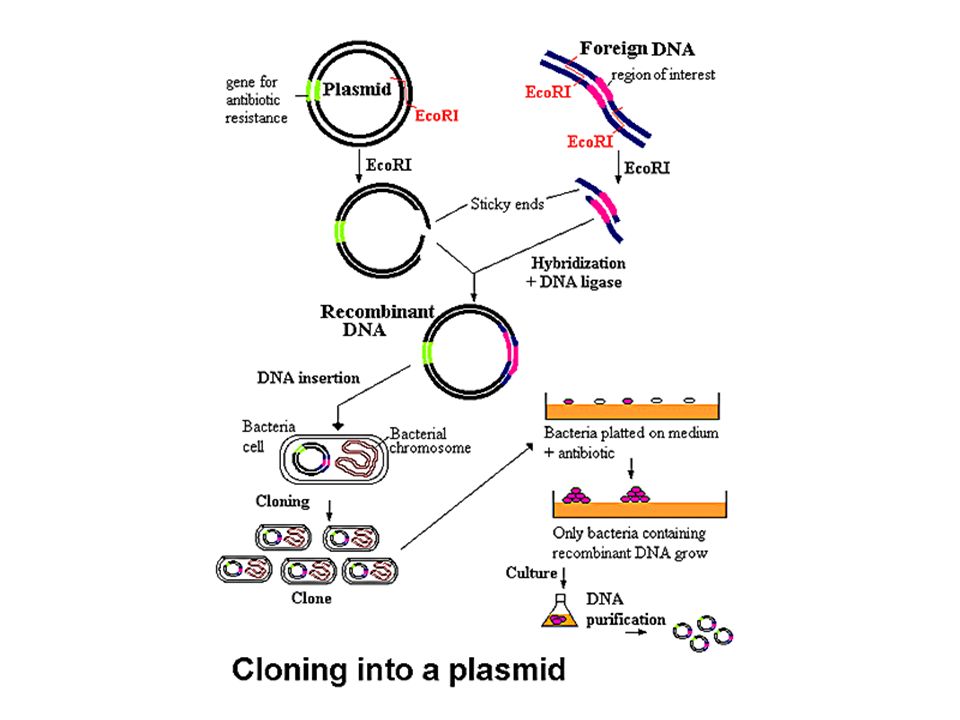













 Obtention de l’ADN recombinant>")
 Obtention de l’ADN recombinant>")
 polymorphes (entre individus, espèces, …) permettant - l’établissement de cartes.>")









>")




