Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Chap. III Statistiques inférentielles
L3 TRC Khaled Fezzani

2
I- Introduction Nous avons examiné le rôle descriptif des statistiques
Nous examinons le rôle inférentiel ou décisionnel des statistiques Nous sommes amenés à étudier l’effet de certains facteurs (déterminants ou variables indépendantes) sur les mesures recueillies ( variables dépendantes). Etudier = comparer ! Comparer deux groupes sur un paramètre donné ou bien comparer le même groupe dans des conditions différentes.
 sur les mesures recueillies ( variables dépendantes). Etudier = comparer ! Comparer deux groupes sur un paramètre donné ou bien comparer le même groupe dans des conditions différentes.")
3
I- Introduction Exemple : Nous avons mesuré le poids de 30 joueurs de football et 30 joueurs de Rugby et nous voulons savoir si les deux groupes sont Significativement différents. La réponse à cette question parait évidente. Elle ne l’est pas. Pourquoi? Variation du poids des joueur de Rugby (de 80 à 130) Variation du poids des joueurs de foot (70 à 90) Certains joueurs de Foot pèsent plus que certains joueurs de rugby. Si on compare deux équipes de Foot on trouvera aussi des différence Idem lorsqu’on compare deux équipes de Rugby. La question est donc de savoir, pourquoi considère-t-on la différence entre cette équipe de foot et cette équipe de Rugby comme significative. Démarche de vérification des hypothèses statistiques
 Variation du poids des joueurs de foot (70 à 90) Certains joueurs de Foot pèsent plus que certains joueurs de rugby. Si on compare deux équipes de Foot on trouvera aussi des différence. Idem lorsqu’on compare deux équipes de Rugby. La question est donc de savoir, pourquoi considère-t-on la différence entre cette équipe de foot et cette équipe de Rugby comme significative. Démarche de vérification des hypothèses statistiques.")
4
II- démarche de vérification des d’hypothèses
1) Formulation des hypothèses Un aspect important de l’inférence statistique. Une hypothèse statistique est un énoncé (une affirmation) concernant les caractéristiques (valeurs des paramètres, forme de la distribution des observations) d’une population.
 Formulation des hypothèses. Un aspect important de l’inférence statistique. Une hypothèse statistique est un énoncé (une affirmation) concernant les caractéristiques (valeurs des paramètres, forme de la distribution des observations) d’une population.")
5
II- démarche de tests d’hypothèses
1) Formulation des hypothèses Deux hypothèses à formuler : L’hypothèse H0 (hypothèse nulle) : Reprenons l’exemple de l’équipe de Rugby et de foot : L’hypothèse nulle ou H0 considère que : M (Rugby) = M (Foot) Les différences qui peuvent être constatées sont assimilables à 0 : erreur d’échantillonage aléatoire.
 Formulation des hypothèses. Deux hypothèses à formuler : L’hypothèse H0 (hypothèse nulle) : Reprenons l’exemple de l’équipe de Rugby et de foot : L’hypothèse nulle ou H0 considère que : M (Rugby) = M (Foot) Les différences qui peuvent être constatées sont assimilables à 0 : erreur d’échantillonage aléatoire.")
6
II- démarche de tests d’hypothèses
2) Formulation des hypothèses Deux hypothèses à formuler L’hypothèse H0 (hypothèse nulle) : L’hypothèse H1 (hypothèse alternative) : on suppose une différence (plus grand ou plus petit) M (Rugby) ≠ M (Foot) : on la désigne de bilatérale. Ou bien on suppose une différence orientée M (Ruby) > M (Foot) ou bien M (Ruby) < M (Foot) : on parle dans ce cas d’hypothèse unilatérale
 Formulation des hypothèses. Deux hypothèses à formuler. L’hypothèse H0 (hypothèse nulle) : L’hypothèse H1 (hypothèse alternative) : on suppose une différence (plus grand ou plus petit) M (Rugby) ≠ M (Foot) : on la désigne de bilatérale. Ou bien on suppose une différence orientée. M (Ruby) > M (Foot) ou bien M (Ruby) < M (Foot) : on parle dans ce cas d’hypothèse unilatérale.")
7
II- démarche de tests d’hypothèses
1) Seuil de signification D’une manière générale, nous testons l’hypothèse nulle Tous les tests comportent des zones d’acceptation de l’hypothèse H0 et des zones de rejet de l’hypothèse H0 = Donc d’acceptation de l’hypothèse H1 ces zones sont déterminées par des valeurs critiques spécifiques à chaque test
 Seuil de signification. D’une manière générale, nous testons l’hypothèse nulle. Tous les tests comportent des zones d’acceptation de l’hypothèse H0 et des zones de rejet de l’hypothèse H0 = Donc d’acceptation de l’hypothèse H1. ces zones sont déterminées par des valeurs critiques spécifiques à chaque test.")
8
II- démarche de tests d’hypothèses
2) Seuil de signification La zone d’acceptation correspond à 95 (0.95) de la surface La zone de rejet à 05% ou (2 X 0.025)
 Seuil de signification. La zone d’acceptation correspond à 95 (0.95) de la surface. La zone de rejet à 05% ou 0.05 (2 X 0.025)")
9
II- démarche de tests d’hypothèses
3) Choix du test approprié C’est un moment important de la démarche : comment éviter les erreurs ! Plusieurs critères peuvent êtres retenus pour choisir le bon outil = le test statistique approprié : Le nombre de groupes ou conditions : 1 groupe, 2 groupe et plus de 2 groupes. La taille de l’échantillon et sa normalité : faible échantillon / distribution ≠ distribution normale versus grand échantillon et distribution normale ou supposée comme telle Le type de conditions comparées : comparaison de deux groupes indépendants (jeune vs. Agés, femmes vs. Homme, riches vs. Pauvres) vs. Comparaison du même groupe dans des conditions différentes. Exemple Avant/Après, avec charge/sans charge etc. Le type de données collectées : le choix dépend du fait que les données sont numériques ou assimilés (intervalles) Données ordinales Données nominales ou catégorielles (fréquence) Toutes ses données doivent êtres prises en compte pour la choix de l’outil statistique approprié.
 Choix du test approprié. C’est un moment important de la démarche : comment éviter les erreurs ! Plusieurs critères peuvent êtres retenus pour choisir le bon outil = le test statistique approprié : Le nombre de groupes ou conditions : 1 groupe, 2 groupe et plus de 2 groupes. La taille de l’échantillon et sa normalité : faible échantillon / distribution ≠ distribution normale versus grand échantillon et distribution normale ou supposée comme telle. Le type de conditions comparées : comparaison de deux groupes indépendants (jeune vs. Agés, femmes vs. Homme, riches vs. Pauvres) vs. Comparaison du même groupe dans des conditions différentes. Exemple Avant/Après, avec charge/sans charge etc. Le type de données collectées : le choix dépend du fait que les. données sont numériques ou assimilés (intervalles) Données ordinales. Données nominales ou catégorielles (fréquence) Toutes ses données doivent êtres prises en compte pour la choix de l’outil statistique approprié.")
10
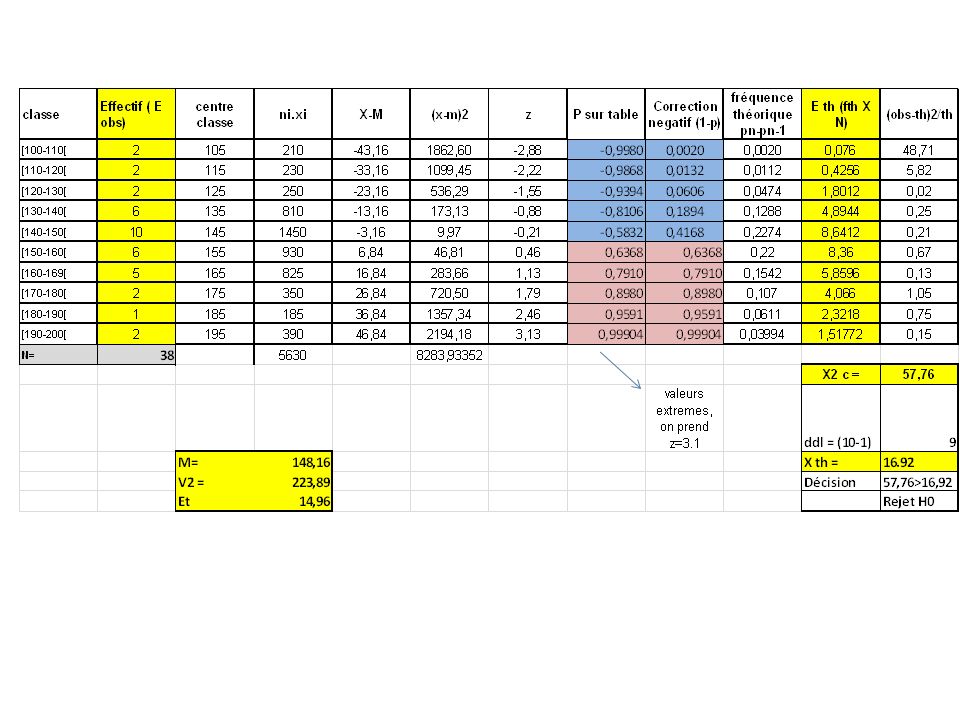
III – les tests 1 ) Test de normalité d’une distribution : Test pour une condition Etudier = comparer Dans le cas présent : comparer la distribution de l’échantillon observé à la distribution théorique ou normale. Exemple : Est la distribution des tailles au sein de l’amphi est normale (donc tout venant ou aléatoire) ou anormale ou exceptionnelle (beaucoup de géants ou beaucoup de nains). Pour répondre à cette question nous faisons référence au test du 𝑋 2
 ou anormale ou exceptionnelle (beaucoup de géants ou beaucoup de nains). Pour répondre à cette question nous faisons référence au test du 𝑋 2.")
11
III – les tests 1 ) Test de normalité d’une distribution : Test pour une condition A) Formulation des hypothèses : Reprenons l’exemple de la détente verticale H0 : la distribution des tailles au sein de l’amphi est assimilable à une distribution normale. H1 : la distribution des tailles au sein de l’amphi est différente d’une distribution normale. Pour tester cette hypothèse nous calculons le X2 selon la formule suivante :

12
1 ) Test de normalité d’une distribution : Test pour une condition
B) procédure de calcul B-2) Etapes description de l’échantillon : calcul des fréquences théoriques trier les données, déterminer les intervalles, calculer le centre de l’intervalle, recenser les effectif, et calculer l’écart centré réduit pour chaque centre de classe : 𝒛 𝒙 = ( 𝒙 𝒊− 𝑴 𝒙 ) 𝑬𝒄 𝒙 Trouver sur la table de la loi normale réduite la probabilité associée avec chaque z calculé : Attention aux valeurs négatives: dans ce cas : Probabilité corrigée : 1- valeur probabilité sur table Cette probabilité = fréquence théorique (fth) Transformez cette fréquence cette fréquence théorique en Effectif théorique : P(z(x)) X N
 procédure de calcul. B-2) Etapes description de l’échantillon : calcul des fréquences théoriques. trier les données, déterminer les intervalles, calculer le centre de l’intervalle, recenser les effectif, et calculer l’écart centré réduit pour chaque centre de classe : 𝒛 𝒙 = ( 𝒙 𝒊− 𝑴 𝒙 ) 𝑬𝒄 𝒙. Trouver sur la table de la loi normale réduite la probabilité associée avec chaque z calculé : Attention aux valeurs négatives: dans ce cas : Probabilité corrigée : 1- valeur probabilité sur table. Cette probabilité = fréquence théorique (fth) Transformez cette fréquence cette fréquence théorique en Effectif théorique : P(z(x)) X N.")
13
1 ) Test de normalité d’une distribution : Test pour une condition
B) procédure de calcul B-2) Etape calcul du X2 ( : Calculez le rapport effectif observé / effectif théorique : comme dans la formule Faire la somme de ces rapports calculés Le X2 = la somme des ces rapports calculés
 procédure de calcul. B-2) Etape calcul du X2 ( : Calculez le rapport effectif observé / effectif théorique : comme dans la formule. Faire la somme de ces rapports calculés. Le X2 = la somme des ces rapports calculés.")
14
1 ) Test de normalité d’une distribution : Test pour une condition
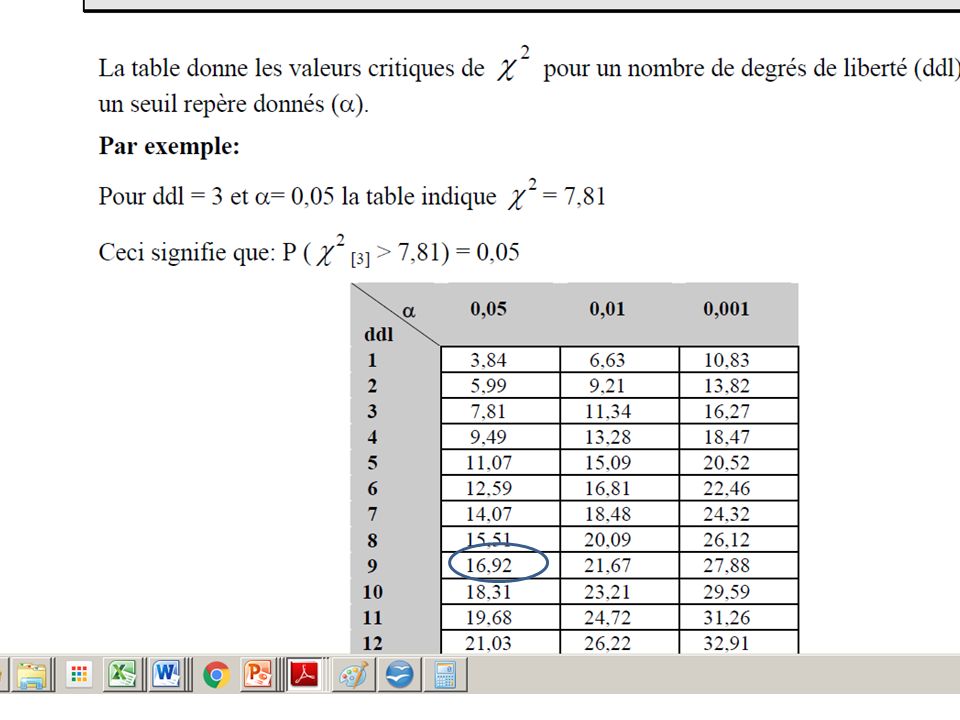
B) procédure de calcul B-3) Etape de vérification de la signification 1) nous fixons conventionnellement le seuil de signification à 0,05 ou 5% 2) fixer le ddl. ddl = K-1 3) sur la table des X2 on cherche le X2 théorique associé au ddl et au seuil de 0.05 4) Décision Si ²Calculé > ²Théorique : Rejet H0 les deux distributions sont différentes Si ²Calculé < ²Théorique : acceptation H0 les deux distributions sont équivalentes
 procédure de calcul. B-3) Etape de vérification de la signification. 1) nous fixons conventionnellement le seuil de signification à 0,05 ou 5% 2) fixer le ddl. ddl = K-1. 3) sur la table des X2 on cherche le X2 théorique associé au ddl et au seuil de ) Décision. Si ²Calculé > ²Théorique : Rejet H0 les deux distributions sont différentes. Si ²Calculé < ²Théorique : acceptation H0 les deux distributions sont équivalentes.")
17
III – les tests 2) Tests de student Il existe deux variantes
- Test de student pour groupes indépendants - test de Student pour mesures répétées ou groupes appariés

18
Les test de Student Test de student pour groupes indépendants
Conditions d’utilisation : Le t-de-student est test paramétrique et donc très exigeant. 1) Lorsque nous avons des données numériques ou assimilées (temps, poids, pression, température etc.) 2) Lorsque nous avons deux groupes indépendants (jeunes vs. âgés, garçons vs. filles, urbains vs. ruraux etc.) 3) lorsqu’on supposes/démontre que les données obtenues dans chaque groupe obéissent à la loi normale. 4) lorsqu’on veut démontrer que les moyennes des deux groupes sont significativement différentes Exemple : quelle est l’effet du régime alimentaire sur le poids des personnes? On choisi un groupe régime méditerranéen et un groupe régime fastfood. On mesure l’IMC pour chaque individu au sein de chaque groupe
 Lorsque nous avons des données numériques ou assimilées (temps, poids, pression, température etc.) 2) Lorsque nous avons deux groupes indépendants (jeunes vs. âgés, garçons vs. filles, urbains vs. ruraux etc.) 3) lorsqu’on supposes/démontre que les données obtenues dans chaque groupe obéissent à la loi normale. 4) lorsqu’on veut démontrer que les moyennes des deux groupes sont significativement différentes. Exemple : quelle est l’effet du régime alimentaire sur le poids des personnes On choisi un groupe régime méditerranéen et un groupe régime fastfood. On mesure l’IMC pour chaque individu au sein de chaque groupe.")
19
Les test de Student Test de student pour groupes indépendants
* Logique d’utilisation Un premier groupe A est caractérisé par un effectif nA et par une moyenne MA. Un second groupe B est caractérisé par un effectif nB et par une moyenne MB. H0 : MA = MB MA-MB = 0 H0 : MA ≠ MB Seuil de signification α= 0.05 ou 5%

20
Les test de Student Test de student pour groupes indépendants
* Procédure Formules : t= 𝑑 𝐸𝑑 t = 𝑀𝑎−𝑀𝑏 𝑉2𝑑 𝑉 2 𝑉 2 𝑑= 𝑉 𝑐 2 ∗ 1 𝑛 𝑎 𝑛 𝑏 𝑉 𝑐 2 = 𝑉 𝑎 2 ∗ 𝑛 𝑎 −1 + 𝑉 𝑏 2 ∗( 𝑛 𝑏 −1) ( 𝑛 𝑎 + 𝑛 𝑏 −2)
 ( 𝑛 𝑎 + 𝑛 𝑏 −2)")
21
Le test de student Test de student pour groupes indépendants
* étapes de calcul A) calculer la V2a et la V2b B) calculer la variance combinée C) calculer la variance de la V2 combinée D) calculer la V2d (variance différence) E) calculer Ed (écart type de la différence F) calculer le t = on l’appelle désormais le tc G) comparer le tc et le t limite (tl) E) le tl est à chercher sur la table des t avec le seuil = 0.05 et un ddl = (na +nb)-2 F) décision : si tc > tl alors rejet H0, autrement acceptation H0
 calculer la V2a et la V2b. B) calculer la variance combinée. C) calculer la variance de la V2 combinée. D) calculer la V2d (variance différence) E) calculer Ed (écart type de la différence. F) calculer le t = on l’appelle désormais le tc. G) comparer le tc et le t limite (tl) E) le tl est à chercher sur la table des t avec le seuil = 0.05 et un ddl = (na +nb)-2. F) décision : si tc > tl alors rejet H0, autrement acceptation H0.")
22
Distribution des valeurs de t-student
Acceptation H0 Rejet H0 Rejet H0

23
Table de t de student

24
VOIR SUR LE SITE DU F2SMH EXERCICES ET CORRIGES
Les test de Student Test de student pour mesures répétées ou appariés. Conditions d’utilisation : Le t-de-student est un test paramétrique et donc très exigeant. 1) Lorsque nous avons des données numériques ou assimilées (temps, poids, pression, température etc.) 2) Lorsqu’un groupe a subi deux évaluation différentes 3) lorsqu’on supposes/démontre que les données obtenues dans chaque évaluation obéissent à la loi normale. 4) lorsqu’on veut démontrer que les moyennes obtenues dans les deux conditions sont significativement différentes Exemple : Quelle est l’effet de l’altitude sur les performances motrice. On évalue le nombre de m parcourus pendant 10 min soit au niveau de la mer (altitude 0) soit en haute altitude (3000 m) VOIR SUR LE SITE DU F2SMH EXERCICES ET CORRIGES
 Lorsque nous avons des données numériques ou assimilées (temps, poids, pression, température etc.) 2) Lorsqu’un groupe a subi deux évaluation différentes. 3) lorsqu’on supposes/démontre que les données obtenues dans chaque évaluation obéissent à la loi normale. 4) lorsqu’on veut démontrer que les moyennes obtenues dans les deux conditions sont significativement différentes. Exemple : Quelle est l’effet de l’altitude sur les performances motrice. On évalue le nombre de m parcourus pendant 10 min soit au niveau de la mer (altitude 0) soit en haute altitude (3000 m) VOIR SUR LE SITE DU F2SMH EXERCICES ET CORRIGES.")
25
Le test de student Test de student pour mesures répétées ou appariés.
* Logique d’utilisation Un groupe A, caractérisé par un effectif nA , a subit deux évaluations successives. et par une moyenne MA. Un second groupe B est caractérisé par un effectif nB et par une moyenne MB. H0 : MA = MB H0 : MA ≠ MB Seuil de signification α= 0.05 ou 5%

26
Les tests de student T= 𝑀𝑑 𝐸 𝑑 𝑛
Test de student pour mesures répétées ou appariés. * Démarche Formules T= 𝑀𝑑 𝐸 𝑑 𝑛 Md = moyenne de la différence = 𝑖=1 𝑛 𝑥 𝑖1 − 𝑥𝑖 2 /n Ed = 𝑉 𝑑 2 𝑉 𝑑 2 = 𝒊=𝟏 𝒏 𝒅 𝟐 − ( 𝒊=𝟏 𝒏 𝒅 ) 𝟐 𝒏 𝒏−𝟏
 𝟐 𝒏 𝒏−𝟏.")
27
Les tests de student Test de student pour mesures répétées ou appariés. * étapes de calcul A) calculer pour chaque individu la différence (di) entre Xi1 et Xi2 B) Calculer la moyenne des différence Md C) la variance de la différence et puis l’écart-type D) calculer le t on l’appelle donc le tc E) comparer le tc et le t limite (tl) E) le tl est à chercher sur la table des t avec le seuil = 0.05 et un ddl = (na +nb)-2 F) décision : si tc > tl alors rejet H0, autrement acceptation H0 VOIR SUR LE SITE DU F2SMH EXERCICES ET CORRIGES
 calculer pour chaque individu la différence (di) entre Xi1 et Xi2. B) Calculer la moyenne des différence Md. C) la variance de la différence et puis l’écart-type. D) calculer le t on l’appelle donc le tc. E) comparer le tc et le t limite (tl) E) le tl est à chercher sur la table des t avec le seuil = 0.05 et un ddl = (na +nb)-2. F) décision : si tc > tl alors rejet H0, autrement acceptation H0. VOIR SUR LE SITE DU F2SMH EXERCICES ET CORRIGES.")
28
Les tests pour valeurs ordinales
Les tests non paramétriques - Ils nécessitent pas des données numériques. Ils utilisent les données ordinales Ne nécessitent pas une distribution supposée normale des données Donc, ils sont utilisables lorsque nous avons des données ordinales ou lorsque nous n’avons pas des données normalisées, dans ce cas les données numériques peuvent être transformées en ordinales; Nous aborderons le U- de Mann-Whitney et Le Wilcoxon

29
Les tests pour valeurs ordinales
Le test de Wilcoxon --- Condition d’utilisation : - Groupes appariés (jumeaux) ou mesures répétées (pratiquement) Mesures non numériques (scores de satisfaction, résultats scolaires, échelle de douleur, de fatigue etc.) mais ayant la propriété ordinale Distribution de l’échantillon différente de celle de la loi normale (exemple cas petit échantillon)
 ou mesures répétées (pratiquement) Mesures non numériques (scores de satisfaction, résultats scolaires, échelle de douleur, de fatigue etc.) mais ayant la propriété ordinale. Distribution de l’échantillon différente de celle de la loi normale (exemple cas petit échantillon)")
30
Les tests pour valeurs ordinales
Le test de Wilcoxon --- Procédure : Deux variantes : Petit versus grand échantillon, Petit échantillon (> 25) : T = la somme des rangs du signe (- ou +) le moins fréquent. Le T calculé (Tc) sera comparé au Tl sur la table avec un ddl = N Si Tc ≥ Tl = rejet H0 Si Tc < TL = acceptation H0 Exemple :
 : T = la somme des rangs du signe (- ou +) le moins fréquent. Le T calculé (Tc) sera comparé au Tl sur la table avec un ddl = N. Si Tc ≥ Tl = rejet H0. Si Tc < TL = acceptation H0. Exemple :")
31
---- Le test de Wilcoxon ---

32
---- Le test de Wilcoxon ---
Tc = 4 Tl avec ddl = 8 et au seuil 0.05 = 4 Tc = Tl = donc rejet H0

33
Les tests pour valeurs ordinales
Le test de Wilcoxon --- Grand échantillon (> 25) : Lorsque N est supérieur à 25, la distribution de T est pratiquement normale. On utilise alors la formule suivante :
 : Lorsque N est supérieur à 25, la distribution de T est pratiquement normale. On utilise alors la formule suivante :")
34
Les tests pour valeurs ordinales
Le test de Wilcoxon --- Grand échantillon (> 25) : z= 𝑇− 𝑈 𝐸𝑇 Où U = N(N+1)/4 Où Et = 𝑁 𝑁+1 (2𝑁+1) 24
 : z= 𝑇− 𝑈 𝐸𝑇. Où U = N(N+1)/4. Où Et = 𝑁 𝑁+1 (2𝑁+1) 24.")
35
Les tests pour valeurs ordinales
Le test de Wilcoxon --- Grand échantillon (> 25) : Appliquons sur l’exemple déjà vu (simplification du calcul z= 4− 𝑈 𝐸𝑇 Où U = N(N+1)/4 = 8(8+1)/4 = 18 Où Et = 𝑁 𝑁+1 (2𝑁+1) 24 = 𝑁 = 72∗ = 7,14 z= 4−18 7,14 = - 1,96 on prend la valeur absolue .. Donc , 1, 96 et on examine la probabilité associée avec cette valeur de Z
 : Appliquons sur l’exemple déjà vu (simplification du calcul. z= 4− 𝑈 𝐸𝑇. Où U = N(N+1)/4 = 8(8+1)/4 = 18. Où Et = 𝑁 𝑁+1 (2𝑁+1) 24 = 𝑁+1 24 = 72∗17 24 = 7,14. z= 4−18 7,14 = - 1,96. on prend la valeur absolue .. Donc , 1, 96 et on examine la probabilité associée avec cette valeur de Z.")
36
Les tests pour valeurs ordinales
Le test de Wilcoxon --- Grand échantillon (> 25) : z= 4−18 7,14 = - 1,96 p= 0,05, H0 est rejetée ! Donc pratiquement : Si IzI est ≥ 1,96 , alors rejet H0
 : z= 4−18 7,14 = - 1,96. p= 0,05, H0 est rejetée ! Donc pratiquement : Si IzI est ≥ 1,96 , alors rejet H0.")
37
Les tests pour valeurs ordinales
Le test de Mann Whitnney--- Condition d’utilisation : - Groupes indépendants. Mesures non numériques (scores de satisfaction, résultats scolaires, échelle de douleur, de fatigue etc.) mais ayant la propriété ordinale Utilisation comme variante t-indépendant dans le cas où la distribution de l’échantillon différente de celle de la loi normale (exemple cas petit échantillon)
 mais ayant la propriété ordinale. Utilisation comme variante t-indépendant dans le cas où la distribution de l’échantillon différente de celle de la loi normale (exemple cas petit échantillon)")
38
---- Le test de Mann Whitnney---
Logique du test : Nous avons deux échantillons indépendants Echantillon 1 ayant un effectif n1 caractérisé par des valeurs (X1…Xn) l’échantillon 2 ayant un effectif de n2 caractérisé par des valeurs (X1…Xn) Nous regroupons ensembles les données des deux échantillons. Toutes les valeurs seront alors triées. Pour chaque échantillon, nous aurons une somme des rangs Soit R1 la somme des rang pour l’échantillon 1 Soit R2 la somme des rang pour l’échantillon 2 Formulation des hypothèses : H0 : R1 = R2, H1 : R1 ≠ R2
 l’échantillon 2 ayant un effectif de n2 caractérisé par des valeurs (X1…Xn) Nous regroupons ensembles les données des deux échantillons. Toutes les valeurs seront alors triées. Pour chaque échantillon, nous aurons une somme des rangs. Soit R1 la somme des rang pour l’échantillon 1. Soit R2 la somme des rang pour l’échantillon 2. Formulation des hypothèses : H0 : R1 = R2, H1 : R1 ≠ R2.")
39
---- Le test de Mann Whitnney---
Logique du test : Cas Echantillon ≤ 20 On calcule U1= n1.n2 + 𝑛1 𝑛 – R1 U2= n1.n2+ 𝑛2 𝑛 –R2 Le U à retenir est le plus faible des deux. Cette valeur sera donc comparée à Ul sur la table de MW

40
---- Le test de Mann Whitnney---
Logique du test : Cas Echantillon ≤ 20 Comparer le U (1 ou 2) calculé au Ul correspondant au seuil 0.05 sur la table
 calculé au Ul correspondant au seuil 0.05 sur la table.")
41
---- Le test de Mann Whitnney---
exemple

42
---- Le test de Mann Whitnney---
exemple On applique U1= n1.n2 + 𝑛1 𝑛 – R1 U2= 𝑛2 𝑛 –R2 N1 = 9 et n2=10, n1.n2 = 90 U1= – 91,5 = ,5 = 43,5 U2= – 98,5 = ,5 = 46,5 Nous prenons alors le U le plus faible = 43,5 Sur la table de U de MW pour n1 =9 et n2 = 10, la Valeur de Ul est 20, Donc Uc ≥ U l = on rejette Ho au seuil de 0.05, L’analyse révèle donc une différence significative entre les deux groupes

43
---- Le test de Mann Whitnney---
exemple On applique U1= 𝑛1 𝑛 – R1 U2= 𝑛2 𝑛 –R2 U1= – 38 = = 7 U2= – 38 = = 2 Nous prenons alors 7(U le plus faible) et Sur la table de U de MW pour n1 =9 et n2 = 9, la Valeur de Ul est 9,
 et. Sur la table de U de MW pour n1 =9 et n2 = 9, la Valeur de Ul est 9,")
44
---- Le test de Mann Whitnney---
Pour les grands échantillons Les valeurs de U se distribuent selon la loi normale centrée réduite Z MU = n1.n2/2 V2U= n1.n2 (n1+n2+1)/12, et donc Ec U = 𝑉 2 U On peut calculer ainsi l’écart réduit z= 𝑈1−𝑀𝑈 𝐸𝐶 = 𝑈2−𝑀𝑈 𝐸𝐶 Si z ≥ 1,96, on rejette l’hypothèse H0 avec le risque (seuil) = 0.05 ou 5% Si z < 1, 96, on accepte H0
/12, et donc Ec U = 𝑉 2 U. On peut calculer ainsi l’écart réduit. z= 𝑈1−𝑀𝑈 𝐸𝐶 = 𝑈2−𝑀𝑈 𝐸𝐶. Si z ≥ 1,96, on rejette l’hypothèse H0 avec le risque (seuil) = 0.05 ou 5% Si z < 1, 96, on accepte H0.")
45
---- Le test de Mann Whitnney---
Pour les grands échantillons Procédure: Calcul de U (même procédure que pour le cas de >20 individus) Calcul de MU (Mu= n1.n2/2) Calcul de de V2U= n1.n2 (n1+n2+1)/12, et Ec U = 𝑉 2 U Calcul du z (z = 𝑈1−𝑀𝑈 𝐸𝐶 ) Tester les hypothèse avec le a limite = 1.96
 Calcul de MU (Mu= n1.n2/2) Calcul de de V2U= n1.n2 (n1+n2+1)/12, et Ec U = 𝑉 2 U. Calcul du z (z = 𝑈1−𝑀𝑈 𝐸𝐶 ) Tester les hypothèse avec le a limite =")
46
---- Le test de Mann Whitnney---
Pour les grands échantillons appliquons: Nous reprenons l’exemple que nous avons abordés. Les n des échantillons sont <20. Mais nous le retenons pour une valeur pédagogique.

47
---- Le test de Mann Whitnney---
Pour les grands échantillons appliquons: Nous avions U1 = 43,5 MU = Mu= n1.n2/2 = 9X10/2 = 45 V2U= n1.n2 (n1+n2+1)/12 = 9x10(9+10+1)/12 = 90 X 20/12 = 150 U = 𝑉 2 U = 𝑉 = 12.24 a = 𝑈1−𝑀𝑈 𝐸𝐶 = 43,5- 45 /12.24 = 0.12 0.12 est inférieur à 1,96…. Acceptation H0
/12. = 9x10(9+10+1)/12. = 90 X 20/12 = 150. U = 𝑉 2 U = 𝑉150 = a = 𝑈1−𝑀𝑈 𝐸𝐶 = 43,5- 45 /12.24 = est inférieur à 1,96…. Acceptation H0.")
48
Le Khi² (²) non paramétrique
Conditions d’utilisation du ² Il est essentiellement utilisé en présence de données nominales. Lorsqu’il s’agit de comparer au moins deux conditions Le test compare la distribution des effectifs observés selon les catégories nominales par rapport à la distribution dite théorique ou aléatoire. H0 : la distribution observée est équivalente à la distribution théorique H1 : la distribution observée est différente à la distribution théorique

49
Le Khi² (²) non paramétrique
Procédure L’indice de est calculé comme suit Nous comparons par la suite le ² calculé au ² théorique qui se trouve sur la table. Le ddl = (nombre de lignes-1) * (nombre de colonnes-1)
 * (nombre de colonnes-1)")
50
Le Khi² (²) non paramétrique
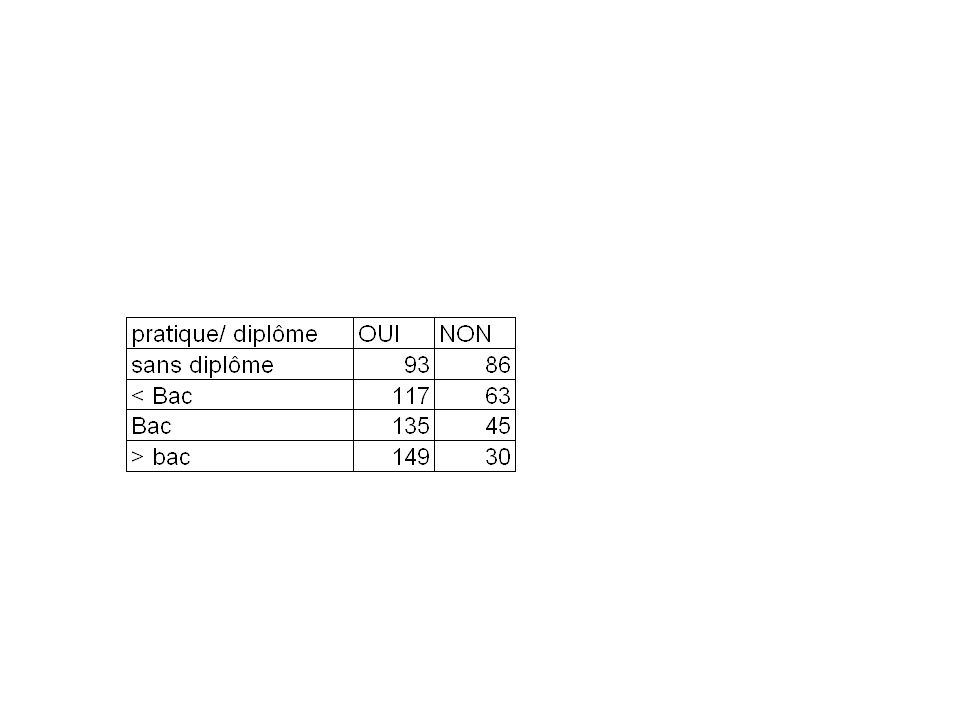
exemple Nous voulons savoir s’il y a une relation entre le niveau d’étude et le fait de pratiquer ou non une activité physique. Un questionnaire a été ainsi posé à des personnes n’ayant aucun diplôme, ayant un diplôme inférieur au bac, ayant le niveau bac, et ayant un diplôme supérieurs au bac. Les résultats sont consignés dans le tableau suivant :

52
exemple Théorique= total C * Total L Total
Tableau ( obser- theo )2/théo ²= 45,49 Le ddl = (nombre de lignes-1) * (nombre de colonnes-1)
2/théo. ²= 45,49. Le ddl = (nombre de lignes-1) * (nombre de colonnes-1)")
53
²= 45,49 Xc>xl Rejet H0

Présentations similaires


 r =>")
>")

>")
>")












