Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

2
Programmes de maîtrise et de doctorat en démographie Modèles de risque et de durée Cours 6 Séance du 21 février 2014 Benoît Laplante, professeur

3
Plan Les modèles de risque dans la recherche démographique
Un exemple: le départ du foyer parental Temps continu, temps discret, temps regroupé Un modèle de risque en temps discret : le modèle logistique Un modèle de risque semi-paramétrique en temps continu : le modèle de Cox

4
Les modèles de risque dans la recherche démographique
L’analyse statistique des biographies ou analyse démographique des biographies ou analyse des transitions ou event history analysis est la principale manière d’utiliser la notion de parcours de vie avec des modèles statistiques pour étudier les phénomènes démographiques natalité, mortalité, migration et leurs corrélats proches ou lointains nuptialité, divortialité, morbidité contraception, avortement, usage des soins de santé étapes de la vie passage à la vie adulte, vieillissement lorsqu’on utilise des données individuelles (ou microdonnées) plutôt que des données agrégées.
 plutôt que des données agrégées.")
5
Les modèles de risque dans la recherche démographique
Les modèles de risque sont les modèles linéaires qui conviennent le mieux au cas où le phénomène étudié est un changement d’état et l’on s’intéresse aux effets d’une ou plusieurs variables indépendantes sur le rythme auquel ce changement d’état se produit ou le moment auquel se produit ce changement.

6
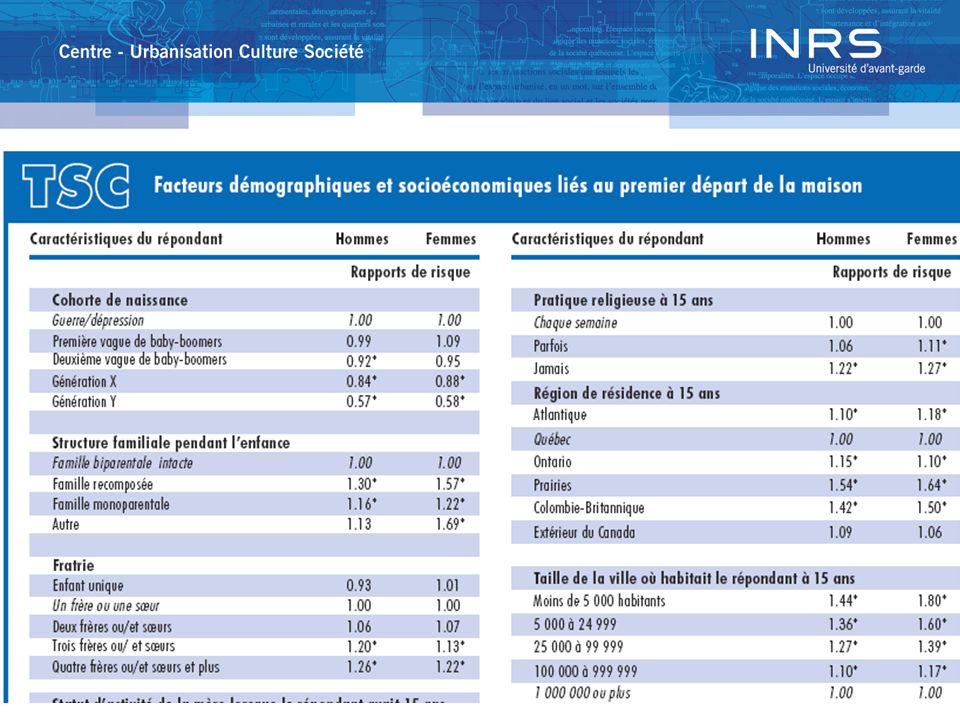
Un exemple: le départ du foyer parental
Pascale Beaupré, Pierre Turcotte et Anne Milan (2006) « Quand fiston quittera-t-il la maison? Transition du domicile parental à l’indépendance » Tendances sociales canadiennes, 82: 8-15.
 « Quand fiston quittera-t-il la maison Transition du domicile parental à l’indépendance » Tendances sociales canadiennes, 82:")
7
Un exemple: le départ du foyer parental
Le phénomène étudié est un changement d’état ou le passage d’un état à un autre d’habiter chez ses parents à ne pas habiter chez ses parents un événement cesser d’habiter chez ses parents.

8
Un exemple: le départ du foyer parental
On cherche à vérifier certaines hypothèses en estimant l’effet de certaines variables indépendantes dont la cohorte de naissance la structure familiale pendant l’enfance la fratrie l’activité de la mère et du père le lieu de naissance de la mère etc.

9
Un exemple: le départ du foyer parental
On utilise un modèle à risques proportionnels (le modèle de Cox même si la chose n’est pas précisée) pour estimer les effets des variables indépendantes sur le risque (et non pas la probabilité) qui régit le processus de changement d’état.
 pour estimer les effets des variables indépendantes sur le risque (et non pas la probabilité) qui régit le processus de changement d’état.")
10
Un exemple: le départ du foyer parental
L’ effet de la variable indépendante s’exprime en rapport de risque (hazard ratio) également nommé risque relatif (relative risk): une variable qui augmente le risque (et donc accélère le processus) a un effet supérieur à 1 et une variable qui diminue le risque (et donc ralentit le processus) a un effet compris entre 0 et 1 (c.-à-d. [0,1[).
 également nommé risque relatif (relative risk): une variable qui augmente le risque (et donc accélère le processus) a un effet supérieur à 1 et. une variable qui diminue le risque (et donc ralentit le processus) a un effet compris entre 0 et 1 (c.-à-d. [0,1[).")
12
Temps continu, temps discret, temps regroupé
En statistique, on connaît deux types de caractère : le caractère qualitatif (p. ex. le sexe ou la langue) et le caractère quantitatif (p. ex. l’âge, le revenu ou le nombre des enfants mis au monde par une femme). On distingue de plus deux types de caractères quantitatifs : le caractère quantitatif continu (p. ex. l’âge ou le revenu) et le caractère quantitatif discret (p. ex. le nombre des enfants mis au monde par une femme). À strictement parler, on réserve le mot « variable » au caractère quantitatif. L’expression « variable discrète » désigne donc un caractère quantitatif discret alors que l’expression « variable continue » désigne un caractère quantitatif continu.
 et. le caractère quantitatif (p. ex. l’âge, le revenu ou le nombre des enfants mis au monde par une femme). On distingue de plus deux types de caractères quantitatifs : le caractère quantitatif continu (p. ex. l’âge ou le revenu) et. le caractère quantitatif discret (p. ex. le nombre des enfants mis au monde par une femme). À strictement parler, on réserve le mot « variable » au caractère quantitatif. L’expression « variable discrète » désigne donc un caractère quantitatif discret alors que. l’expression « variable continue » désigne un caractère quantitatif continu.")
13
Temps continu, temps discret, temps regroupé
La variable discrète ne prend que des valeurs entières et positives (ses valeurs sont éléments de ℕ) : on n’a pas 2,5 enfants ou -3 enfants. Une statistique d’une variable discrète peut être un nombre négatif ou décimal : la moyenne du nombre d’enfants par femme est un réel positif (élément de ℝ+); le coefficient de symétrie de sa distribution statistique est un réel (élément de ℝ).
 : on n’a pas 2,5 enfants ou -3 enfants. Une statistique d’une variable discrète peut être un nombre négatif ou décimal : la moyenne du nombre d’enfants par femme est un réel positif (élément de ℝ+); le coefficient de symétrie de sa distribution statistique est un réel (élément de ℝ).")
14
Temps continu, temps discret, temps regroupé
Il faut absolument éviter de confondre la variable discrète et la distribution qui résulte du regroupement des valeurs d’une variable discrète ou continue en classes. Fort malheureusement, la démographie classique utilise l’expression « temps discret » pour désigner le regroupement en classes des valeurs de la variable continue « temps » (qu’il s’agisse de l’âge, du temps écoulé depuis la dernière naissance ou depuis la formation d’une union) et les opérations mathématiques ou statistiques propres au traitement d’une variable continue dont les valeurs sont regroupées en classes.
 et. les opérations mathématiques ou statistiques propres au traitement d’une variable continue dont les valeurs sont regroupées en classes.")
15
Temps continu, temps discret, temps regroupé
Pour éviter la confusion, on conservera aux mots « discret » et « continu » le sens qu’ils ont en statistique et on nommera « regroupé » ce qui se rapporte au traitement des variables dont les valeurs sont regroupées en classes.

16
Temps continu, temps discret, temps regroupé
La table « classique » traite le cas « regroupé » au moyen d’un artifice : on estime le taux au centre de l’intervalle de classe et on présume que le flux des événements est constant tout au long de l’intervalle, ce qui implique que le taux augmente du début à la fin de l’intervalle. La table construite à partir de taux dont les dénominateurs sont le temps à risque exact et le modèle de Poisson par parties traitent le cas « regroupé » au moyen d’une simplification moins irréaliste : le taux est présumé constant du début à la fin de l’intervalle, ce qui implique que le flux diminue, chose réaliste dans le cas d’un événement non renouvelable puisque la proportion des « survivants » diminue nécessairement au fil du temps.

17
Temps continu, temps discret, temps regroupé
En sciences sociales, le « cas discret » au sens de la statistique est rare. Il exige que l’événement ne puisse se produire qu’à des moments qui puissent être représentés par des entiers naturels. Le « meilleur » exemple la promotion des professeurs d’université, qui ne se fait qu’une fois par année (Paul D. Allison) Autre exemple, moins bon en pratique : la réussite d’un programme d’études régulier, qui ne peut survenir qu’une fois par trimestre. À strictement parler, les modèles statistiques développés pour l’étude des phénomènes qui se déroulent « en temps discret » ne valent que pour ces cas rares.
 Autre exemple, moins bon en pratique : la réussite d’un programme d’études régulier, qui ne peut survenir qu’une fois par trimestre. À strictement parler, les modèles statistiques développés pour l’étude des phénomènes qui se déroulent « en temps discret » ne valent que pour ces cas rares.")
18
Temps continu, temps discret, temps regroupé
Lorsqu’on traite un phénomène « en continu » l’intervalle devient infinitésimal, la distinction entre le moment (la valeur de t sur l’échelle du temps) et la quantité de temps à risque disparaît, la probabilité (donc le quotient de la démographie et le risque de l’épidémiologie) et le taux se confondent. « En continu », quotient instantané, risque instantané et taux instantané sont synonymes.
 et la quantité de temps à risque disparaît, la probabilité (donc le quotient de la démographie et le risque de l’épidémiologie) et le taux se confondent. « En continu », quotient instantané, risque instantané et. taux instantané. sont synonymes.")
19
Temps continu, temps discret, temps regroupé
Le risque instantané comme limite Le risque instantané (ou quotient instantané ou taux instantané) est la probabilité de changer d’état au cours d’un intervalle de largeur infinitésimale (quantité de temps d’exposition infiniment petite) si on n’a pas déjà changé d’état avant cet intervalle (position de cet intervalle sur l’axe du temps).
 est la probabilité de changer d’état au cours d’un intervalle de largeur infinitésimale (quantité de temps d’exposition infiniment petite) si on n’a pas déjà changé d’état avant cet intervalle (position de cet intervalle sur l’axe du temps).")
20
Un modèle de risque en temps discret : le modèle logistique
Rappel de la régression logistique L’usage de la régression logistique dans l’étude du changement d’état plutôt que dans l’étude de l’appartenance statique à une modalité d’un caractère qualitatif.

21
Un modèle de risque en temps discret : le modèle logistique
La régression logistique est un modèle linéaire qui permet d’estimer les effets d’une ou plusieurs variables indépendantes sur une variable dépendante Comme tout modèle linéaire, il est composé de trois éléments: un élément déterministe un élément aléatoire et une fonction de liaison. Son élément le plus intéressant est sa fonction de liaison.

22
Un modèle de risque en temps discret : le modèle logistique
La variable dépendante d’un modèle linéaire doit pouvoir varier entre moins l’infini et plus l’infini. On ne peut pas construire directement un modèle linéaire dont la variable dépendante serait 0 ou 1. On ne peut pas non plus construire directement un modèle linéaire dont la variable dépendante varierait entre 0 et 1.

23
Un modèle de risque en temps discret : le modèle logistique
Construire un modèle linéaire dont on sait que la variable dépendante varie entre 0 et 1 (comme c’est le cas d’une probabilité) en utilisant simplement la probabilité comme variable dépendante d’une régression conventionnelle conduit à une absurdité: les valeurs prédites peuvent être inférieures à 0 ou supérieures à 1.
 en utilisant simplement la probabilité comme variable dépendante d’une régression conventionnelle conduit à une absurdité: les valeurs prédites peuvent être inférieures à 0 ou supérieures à 1.")
24
Un modèle de risque en temps discret : le modèle logistique
La chose a cependant été courante pendant quelques décennies du XXe siècle. Ce mauvais modèle permet cependant de voir comment on passe (naïvement) d’une variable dépendante observée binaire à une variable dépendante estimée qui est continue (même si elle n’est pas bornée correctement). On pose que la valeur observée (0 ou 1) qui est la réalisation d’un tirage aléatoire correspond à la probabilité (comprise en principe entre 0 et 1) qui a régi ce tirage et que l’on estime au moyen du modèle.
 d’une variable dépendante observée binaire à une variable dépendante estimée qui est continue (même si elle n’est pas bornée correctement). On pose que la valeur observée (0 ou 1) qui est la réalisation d’un tirage aléatoire correspond à la probabilité (comprise en principe entre 0 et 1) qui a régi ce tirage et que l’on estime au moyen du modèle.")
25
Un modèle de risque en temps discret : le modèle logistique
L’élément le plus intéressant de la régression logistique est sa fonction de liaison qui propose une autre manière de passer d’une variable observée binaire à une probabilité. Plutôt que d’estimer la probabilité d’appartenir à la modalité représentée par la valeur 1, on estime le rapport entre la probabilité d’appartenir à cette modalité et la probabilité d’appartenir à l’autre modalité:

26
Un modèle de risque en temps discret : le modèle logistique
Dans la régression logistique (également nommée « modèle logit »), on utilise la courbe logistique comme fonction de liaison.
, on utilise la courbe logistique comme fonction de liaison.")
27
Un modèle de risque en temps discret : le modèle logistique
Le modèle peut être représenté sous sa forme multiplicative ou additive. Nous l’utiliserons surtout sous sa forme multiplicative.

28
Un modèle de risque en temps discret : le modèle logistique
Le modèle comprend bien sûr un élément aléatoire. Il s’agit de la loi binomiale dont nous montrons ici la fonction de densité sous trois formes différentes mais reliées.

29
Un modèle de risque en temps discret : le modèle logistique
L’espérance mathématique du modèle est la probabilité que la probabilité vaille π. La variance est égale au produit de π et 1-π.

30
Un modèle de risque en temps discret : le modèle logistique
Un exemple simple de régression logistique, sous forme additive: Le même exemple simple, sous forme multiplicative:

31
Un modèle de risque en temps discret : le modèle logistique
Il est plus simple d’interpréter les coefficients de la régression logistique sous sa forme multiplicative que sous sa forme additive:

32
Un modèle de risque en temps discret : le modèle logistique
Dans la forme multiplicative de la régression logistique: la variable dépendante est le quotient de deux probabilités; pour cette raison, l’effet d’une variable indépendante est d’augmenter ou de réduire le rapport entre ces deux probabilités; les effets des variables indépendantes ne s’additionnent pas à l’ordonnée à l’origine et ne s’additionnent pas les uns aux autres, ils multiplient l’ordonnée à l’origine et se multiplient les uns les autres.

33
Un modèle de risque en temps discret : le modèle logistique
Interprétation des coefficients On a réalisé une enquête qui permet de relier le fait d’avoir obtenu ou non le diplôme de premier cycle dans les délais prévus au nombre d’heures consacré aux études par semaine. On a interrogé les étudiants au moment où ils devaient compléter leur programme et on estimé l’effet du nombre d’heures d’études par semaine sur la probabilité d’avoir obtenu le diplôme au moyen d’un régression logistique. On a les coefficients suivants: α = -1,3863 et β = 0,0953.

34
Un modèle de risque en temps discret : le modèle logistique
La modalité de référence: ne pas avoir étudié du tout Rapport de cotes ou rapport de probabilités ou rapport de « chances » Probabilité

35
Un modèle de risque en temps discret : le modèle logistique
Un autre cas: avoir étudié 20 heures par semaine Rapport de cotes ou rapport de probabilités ou rapport de « chances » Probabilité

36
Un modèle de risque en temps discret : le modèle logistique
La régression logistique comme modèle de risque et non plus de probabilité. On reprend l’enquête sur l’obtention du diplôme, mais on la réalise à tous les ans, on vérifie si le diplôme est obtenu à la fin de chaque année et on mesure le nombre d’heures consacrées à l’étude à chaque année et on suit les étudiants pendant huit ans.

37
Un modèle de risque en temps discret : le modèle logistique
On construit un fichier biographique où on a, pour chaque étudiant, une ligne par année de présence dans le groupe à risque. On sort du groupe à risque en obtenant le diplôme (en changeant d’état), en abandonnant les études (sans changer d’état) ou après huit ans d’études sans avoir obtenu le diplôme (également sans changer d’état).
, en abandonnant les études (sans changer d’état) ou. après huit ans d’études sans avoir obtenu le diplôme (également sans changer d’état).")
38
Un modèle de risque en temps discret : le modèle logistique
La variable dépendante vaut 1 lorsque l’année se termine par l’obtention du diplôme et vaut 0 lorsque l’année se termine sans l’obtention du diplôme. n’est donc plus la probabilité d’avoir obtenu le diplôme, mais bien la probabilité de l’obtenir si l’on est toujours à risque de l’obtenir, ou encore le nombre de changements d’état divisé par le nombre des individus à risque au cours de l’année. La variable dépendante n’est donc plus une probabilité, mais bien un risque.

39
Un modèle de risque en temps discret : le modèle logistique
On estime une régression logistique où chaque ligne du fichier biographique ajoute une contribution à la fonction de vraisemblance. On permet généralement à l’ordonnée à l’origine de prendre une valeur différente pour chaque unité de temps, puisque l’on sait qu’il est plus « probable » d’obtenir le diplôme au cours de certaines années et moins au cours d’autres années. L’équation a donc la forme suivante:

40
Un modèle de risque en temps discret : le modèle logistique
Les effets des variables indépendantes se manipulent et s’interprètent de manière analogue à ceux de la régression logistique « ordinaire », sauf qu’ils ne font plus augmenter ou décroître un rapport de probabilités, mais bien un taux.

41
Un modèle de risque semi-paramétrique en temps continu : le modèle de Cox
On représente généralement comme suit le modèle semi-paramétrique à risques proportionnels (ou relatifs) de Cox où h(t|x1, x2, …, xn) est le risque au temps t pour une combinaison donnée de valeurs des variables indépendantes x1, x2, …, xn, h0(t) est le risque de base, x est le vecteur des variables indépendantes et β est le vecteur des coefficients du modèle.
 de Cox. où h(t|x1, x2, …, xn) est le risque au temps t pour une combinaison donnée de valeurs des variables indépendantes x1, x2, …, xn, h0(t) est le risque de base, x est le vecteur des variables indépendantes et β est le vecteur des coefficients du modèle.")
42
Un modèle de risque semi-paramétrique en temps continu : le modèle de Cox
Le modèle de Cox a une forme semblable à celle de la régression logistique utilisée comme modèle de risque. La principale différence est que dans le modèle de Cox, on estime le risque de base avec la logique de l’estimateur de Kaplan-Meier (c.-à-d. un nouvel intervalle à chaque changement d’état dans l’échantillon) plutôt qu’en « échantillonnant » le temps à intervalles égaux prédéfinis (comme on échantillonne la musique pour en faire un enregistrement numérique).
 plutôt qu’en « échantillonnant » le temps à intervalles égaux prédéfinis (comme on échantillonne la musique pour en faire un enregistrement numérique).")
43
Un modèle de risque semi-paramétrique en temps continu : le modèle de Cox
La fonction de vraisemblance partielle du modèle de Cox et son rapport avec le fichier biographique.

44
Sur le modèle logistique et le modèle de Cox
Ces modèles utilisent l’effectif du groupe à risque plutôt que le temps passé à risque au dénominateur des taux. Les unités qui sortent du groupe à risque sans changer d’état sortent du groupe à risque après chaque instant discret dans le modèle logistique et après l’instant qui marque la fin de chaque intervalle dans le modèle de Cox. Ceci ne crée pas de biais si le modèle logistique s’il est utilisé pour étudier un phénomène véritablement discret, mais sous-estime systématiquement le risque si le modèle logistique est utilisé pour étudier un phénomène intrinsèquement continu. Ceci sous-estime systématiquement le risque dans le modèle de Cox. Les unités qui sortent du groupe à risque en changeant d’état ne sont pas comptées au dénominateur et le taux est donc systématiquement surestimé.

46
La régression logistique en économétrie
Annexe La régression logistique en économétrie Les économètres ont développé une interprétation particulière de la régression logistique. Pour les statisticiens, la régression logistique a une composante aléatoire — la loi binomiale — et une fonction de liaison — la courbe logistique centrée réduite (sic) — qui sert à faire correspondre l’étendue des valeurs prédites ([-∞,+∞]) à l’étendue d’une probabilité ([0,1]). Pour les économètres, la régression logistique a deux composantes aléatoires: la loi binomiale et la loi logistique centrée réduite.
 — qui sert à faire correspondre l’étendue des valeurs prédites ([-∞,+∞]) à l’étendue d’une probabilité ([0,1]). Pour les économètres, la régression logistique a deux composantes aléatoires: la loi binomiale et la loi logistique centrée réduite.")
47
La régression logistique en économétrie
Annexe La régression logistique en économétrie Les économètres interprètent de manière analogue le modèle probit. Pour les statisticiens, le modèle probit a une composante aléatoire — la loi binomiale — et une fonction de liaison — l’intégrale de la courbe normale centrée réduite (sic) — qui, comme la courbe logistique dans la régression logistique, sert à faire correspondre l’étendue des valeurs prédites ([-∞,+∞]) à l’étendue d’une probabilité ([0,1]). Pour les économètres, la régression logistique a deux composantes aléatoires: la loi binomiale et la loi normale centrée réduite.
 — qui, comme la courbe logistique dans la régression logistique, sert à faire correspondre l’étendue des valeurs prédites ([-∞,+∞]) à l’étendue d’une probabilité ([0,1]). Pour les économètres, la régression logistique a deux composantes aléatoires: la loi binomiale et la loi normale centrée réduite.")
Présentations similaires