Télécharger la présentation
La présentation est en train de télécharger. S'il vous plaît, attendez

1
Université Paris Sud - Soudani K.
Modèles statistiques et modélisation de processus stochastiques 1- Modèles statistiques 1.1- Statistiques corrélationnelles - Modèles de régressions linéaire simple et multiple - Modèles non linéaires - Quelques infos sur les distributions théoriques de probabilités 1.2- Modélisation Black-Box : modélisation par réseaux neuronaux 2- Modélisation des processus stochastiques 2.1- Automates cellulaires 2.2- Chaînes de Markov 29 - Octobre 2004 Université Paris Sud - Soudani K.

2
Introduction aux modèles empiriques
Objectif: établir des relations statistiques entre une variable qu’on souhaite prédire et des variables potentiellement capables d’expliquer cette variable. Souvent, le problème revient à étudier l’effet de la variabilité des variables explicatives sur la variabilité de la variable à expliquer (Analyse de variance). On peut diviser les problèmes de prédiction en deux catégories: Régression : prédire la valeur d’une variable à partir d’une ou plusieurs variables quantitatives continues (ou supposées l’être). Classification : déterminer à quelle classe une ou plusieurs variables quantitatives peuvent appartenir. Les variables d’entée sont quantitatives et la variable de sortie est nominale (classe).
. On peut diviser les problèmes de prédiction en deux catégories: Régression : prédire la valeur d’une variable à partir d’une ou plusieurs variables quantitatives continues (ou supposées l’être). Classification : déterminer à quelle classe une ou plusieurs variables quantitatives peuvent appartenir. Les variables d’entée sont quantitatives et la variable de sortie est nominale (classe).")
3
Y = + x + Analyse de régression
Modèle linéaire simple : régression linéaire donnant une équation fonctionnelle de prévision entre deux variables : Y = + x + Où x est la variable indépendante (explicative ou prédictive) et Y est la variable dépendante (réponse ou prédite). est l’erreur de prédiction de Yi en Xi Principe d’estimation des constantes (paramètres de l’équation de prédiction) par la méthode des moindres carrés: Si n est le nombre d’observations et xi et yi sont les quantités mesurées et si f est le modèle à établir (modèle de prédiction) : y = f(x) Alors la méthode de moindres carrés s’applique à toutes les fonctions f(x) et cherche à déterminer les paramètres de la fonction f en minimisant la somme des carrés des écarts (i) entre la variable prédite par le modèle et la valeur mesurée:
 et Y est la variable dépendante (réponse ou prédite). est l’erreur de prédiction de Yi en Xi. Principe d’estimation des constantes (paramètres de l’équation de prédiction) par la méthode des moindres carrés: Si n est le nombre d’observations et xi et yi sont les quantités mesurées et si f est le modèle à établir (modèle de prédiction) : y = f(x) Alors la méthode de moindres carrés s’applique à toutes les fonctions f(x) et cherche à déterminer les paramètres de la fonction f en minimisant la somme des carrés des écarts (i) entre la variable prédite par le modèle et la valeur mesurée:")
4
Pour deux variables Pour p variables >2
Modèle linéaire multiple : régression linéaire donnant une équation fonctionnelle de prévision entre une variable à expliquer et plusieurs variables explicatives : Y = + 1x1 + 2x2+…+ pxp+ Où xi sont les variables indépendantes (explicatives ou prédictives) et Y est la variable dépendante (réponse ou prédite). Exemple : la croissance végétale peut être potentiellement expliquée par la quantité de pluie et le rayonnement. Pour deux variables Pour p variables >2 1. Y = + 1x1 + 2x2 + 2. Y = + 1x1 + 2x2+…+ pxp+ Y définit un plan Y définit un hyperplan 1 : est la pente du plan en x1 i: est la pente selon la dim. xi 2 : est la pente du plan en x2
 et Y est la variable dépendante (réponse ou prédite). Exemple : la croissance végétale peut être potentiellement expliquée par la quantité de pluie et le rayonnement. Pour deux variables Pour p variables >2. 1. Y = + 1x1 + 2x2 + 2. Y = + 1x1 + 2x2+…+ pxp+ Y définit un plan Y définit un hyperplan. 1 : est la pente du plan en x1 i: est la pente selon la dim. xi. 2 : est la pente du plan en x2.")
5
Modèle multilinéaire Y = X * A +
Le modèle comporte deux composantes : - Une composante déterministe (explicable) : A*X - Une composante stochastique (aléatoire): Hyp. 1: E(Y) = A*E(X) en supposant que les erreurs s’annulent mutuellement. Hyp. 2: E() = 0 Dans l’ensemble le système est stable mais individuellement, le même xi n’implique pas obligatoirement le même yi. Hyp. 3: Les erreurs suivent la même loi statistique (loi normale). Hyp. 4: Les erreurs ne sont pas autocorrelées. Hyp. 5: Les variables X (1 à p) sont indépendantes.
 : A*X. - Une composante stochastique (aléatoire): Hyp. 1: E(Y) = A*E(X) en supposant que les erreurs s’annulent mutuellement. Hyp. 2: E() = 0. Dans l’ensemble le système est stable mais individuellement, le même xi n’implique pas obligatoirement le même yi. Hyp. 3: Les erreurs suivent la même loi statistique (loi normale). Hyp. 4: Les erreurs ne sont pas autocorrelées. Hyp. 5: Les variables X (1 à p) sont indépendantes.")
6
Modélisation de distributions de données expérimentales:
Quelques infos sur les fonctions de densité de probabilités Si X est une variable quantitative aléatoire et si n est la taille de l’échantillon d’observations xi, la distribution des fréquences donne : Pour X=xi : f(xi) est la fréquence relative. Est la fréquence cumulée X≥xi Si la variable X est continue, alors la distribution des fréquences correspond à une distribution de probabilités. Pr(X>xi) =F(xi)= f(x) est la fonction de densité de probabilité. F(x) est la fonction de répartition
 est la fréquence relative. Est la fréquence cumulée. X≥xi. Si la variable X est continue, alors la distribution des fréquences correspond à une distribution de probabilités. Pr(X>xi) =F(xi)= f(x) est la fonction de densité de probabilité. F(x) est la fonction de répartition.")
7
Quelques fonctions théoriques de densité de probabilités
La loi normale (loi de Gauss-Laplace) Signification: Une variable X suit une loi normale lorsque plusieurs causes sont à l’origine de sa variation, ayant des effets additifs et qu’aucune n’est prépondérante. μ et σ sont respectivement la moyenne et l’écart-type.
 Signification: Une variable X suit une loi normale lorsque plusieurs causes sont à l’origine de sa variation, ayant des effets additifs et qu’aucune n’est prépondérante. μ et σ sont respectivement la moyenne et l’écart-type.")
8
Particularité : la moyenne est égale à la variance
La loi de Poisson Particularité : la moyenne est égale à la variance Application en Ecologie : (Ex.) - Mesure de la répartition spatiale d’une variable aléatoire. Si : Variance/Moyenne =1 La variable est géographiquement répartie d’une manière aléatoire. Variance/Moyenne >>1 La répartition est agrégative Variance/Moyenne <<1 La répartition est regulière La loi de Poisson simulée (lamda = 50, k=1:100
 - Mesure de la répartition spatiale d’une variable aléatoire. Si : Variance/Moyenne =1. La variable est géographiquement répartie d’une manière aléatoire. Variance/Moyenne >>1. La répartition est agrégative. Variance/Moyenne <<1. La répartition est regulière. La loi de Poisson simulée (lamda = 50, k=1:100.")
9
Simulation de distributions foliaires dans un volume végétal pour un modèle de lancée de rayons
Extrait :Walter J-MN, Fournier R., Soudani K. and Meyer E. (2003) : Integrating clumping effects in forest canopy structure : an assessment through hemispherical photographs. Canadian Journal of Remote Sensing (CJRS)- 29,3,
 : Integrating clumping effects in forest canopy structure : an assessment through hemispherical photographs. Canadian Journal of Remote Sensing (CJRS)- 29,3,")
10
Loi Gamma k > 0 est le paramètre de forme et θ > 0 est le paramètre d échelle . Signification : La durée de vie d'un appareil ou d'un organisme suit sous l’effet d’un vieillissement une loi Gamma avec k>1.

11
Loi de Weibull Exemples : La distribution des diamètres de tronc dans une parcelle forestière gérée suit une loi de Weibull. La distribution des indices foliaires locaux dans une parcelle forestière suit également une loi de Weibull.

12
Relations entre les variabilités spatiales LAI et NDVI dans des couverts forestiers
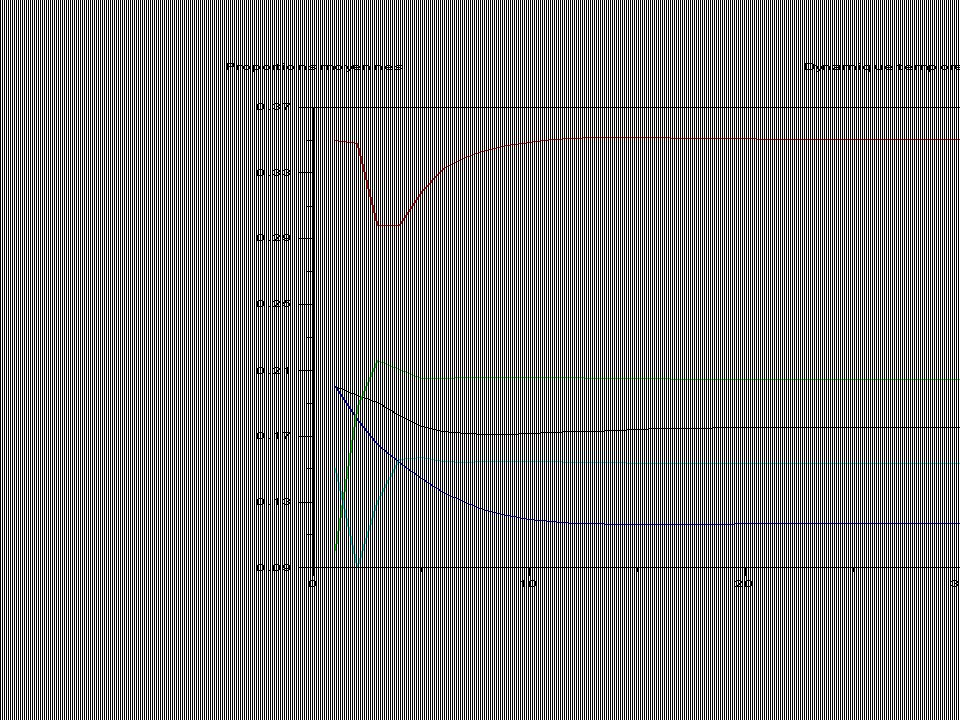
LAI in situ-NDVI LAI-NDVI simulés Conclusions : Pour un indice foliaire moyen de la parcelle correspond une distribution particulière des LAIs locaux. Pour un indice foliaire moyen de la parcelle correspond une distribution particulière des NDVI locaux. Plus l’indice foliaire moyen est élevé plus la variance du NDVI intaparcelle diminue. Davi et al.2004

13
Modélisation Boîte noire par réseaux de neurones
Variables d’entrée Variable (s) de sortie Modélisation "boîte noire". On ne s'intéresse pas aux mécanismes et aux processus expliquant le lien entre les entrées et les sorties mais seulement à leurs relations au sens statistique.
 de sortie. Modélisation boîte noire . On ne s intéresse pas aux mécanismes et aux processus expliquant le lien entre les entrées et les sorties mais seulement à leurs relations au sens statistique.")
14
Principe de la modélisation par réseaux de neurones
Chez l’homme : 10 milliards de neurones. Chaque neurone est connecté à environ autres. Principe : chaque neurone reçoit des signaux (impulsions électriques) des autres neurones par l’intermédiaire des dendrites. Si le signal dépasse un seuil, le neurone transmet un signal aux autres par l’intermédiaire de son axone. Finalement, la tâche d’un neurone est simple mais c’est l’ensemble qui fait qu’on est pas bête Analogie mathématique : un neurone correspond à une entité fonctionnelle recevant des informations, faisant leur somme et émet un signal si la somme dépasse un seuil Analogie aux neurones biologiques Extraits:Frédéric Perez
 des autres neurones par l’intermédiaire des dendrites. Si le signal dépasse un seuil, le neurone transmet un signal aux autres par l’intermédiaire de son axone. Finalement, la tâche d’un neurone est simple mais c’est l’ensemble qui fait qu’on est pas bête. Analogie mathématique : un neurone correspond à une entité fonctionnelle recevant des informations, faisant leur somme et émet un signal si la somme dépasse un seuil. Analogie aux neurones biologiques. Extraits:Frédéric Perez")
15
Principe de fonctionnement d’un réseau d’un seul neurone
Output 1 1 Fonction d’activation Seuil s -1 Somme pondérée 2 12 p2 p1 0.6 0.5 Poids attribués aux inputs 10 15 inputs X1 X2

16
Différentes fonctions d’activation Seuil s -1 2 12
0.9999 1 12 Pas unitaire Sigmoïde Linéaire à seuil Gaussienne Identité Différentes fonctions d’activation Seuil s -1 2 12 Si xi sont les entrées, alors La sortie y est donnée par : p2 p1 0.6 0.5 10 15 f étant la fonction d’activation X1 X2

17
Principe de fonctionnement d’un réseau de plusieurs neurones
1 - Des entrées : Quantitatives ou non 2 - >> Une couche de neurone : Chaque neurone calcule une somme pondérée des entrées. De cette somme, on soustrait souvent un biais (constante). 3- A la sortie du neurone, le résultat est traité par une fonction d’activation (une sorte de filtre). 4- Le résultat de l’application de la fonction d’activation est la participation du neurone considéré dans la sortie y. L’étape primordiale est la détermination des poids : nécessité d’un apprentissage.
. 3- A la sortie du neurone, le résultat est traité par une fonction d’activation (une sorte de filtre). 4- Le résultat de l’application de la fonction d’activation est la participation du neurone considéré dans la sortie y. L’étape primordiale est la détermination des poids : nécessité d’un apprentissage.")
18
Automates cellulaires
Historique Les automates cellulaires ont été inventés par Stanislaw Ulam ( aussi inventeur de la méthode Monte Carlo) et John von Neumann ( ) à la fin des années 40 Jeu de la vie (Game of life) Les règles sont : Dans un espace de n cellules : 1. Les cellules peuvent se trouver dans deux états : vivant / mort. 2. Au départ, l’espace cellulaire est composé de cellules dans l’état mort, sauf pour quelques unes. 3. L’évolution de chaque cellule est déterminée en fonction du nombre de cellules (Nv pour vivantes) vivantes se trouvant autour d’elle. Les règles sont : Une cellule vivante meurt (devient vide) pour Nv ≤ 1 : état d’isolement de cellule. Une cellule vivante meurt pour Nv ≥ 4 : un état de surpeuplement autour de la cellule. Une cellule morte peut devenir vivante pour Nv = 3 : cela correspond à une reproduction « trisexuée ».
 et John von Neumann ( ) à la fin des années 40. Jeu de la vie (Game of life) Les règles sont : Dans un espace de n cellules : 1. Les cellules peuvent se trouver dans deux états : vivant / mort. 2. Au départ, l’espace cellulaire est composé de cellules dans l’état mort, sauf pour quelques unes. 3. L’évolution de chaque cellule est déterminée en fonction du nombre de cellules (Nv pour vivantes) vivantes se trouvant autour d’elle. Les règles sont : Une cellule vivante meurt (devient vide) pour Nv ≤ 1 : état d’isolement de cellule. Une cellule vivante meurt pour Nv ≥ 4 : un état de surpeuplement autour de la cellule. Une cellule morte peut devenir vivante pour Nv = 3 : cela correspond à une reproduction « trisexuée ».")
19
Propriétés des automates cellulaires
Voisinage : l’état d’une cellule dépend des états de ses voisines Parallélisme : les modifications des états de toutes les cellules sont synchrones. Déterminisme et stochasticité Automates déterministes L’état d’une cellule est déterminé avec certitude par les états de ses voisines. Automates stochastiques L’état d’une cellule est stochastiquement déterminé par les états de ses voisines selon des probabilités de transition. Autrement dit, une même configuration peut donner des situations différentes. Homogénéité: les mêmes règles s’appliquent à toutes les cellules Discrétisation:l’évolution de l’ensemble du système se fait selon un pas de temps discret.

20
Quelques domaines d’application des automates cellulaires :
Simulation de la propagation des feux de forêts; Modélisation et simulation de la dynamique des écosystèmes forestiers; 3. Application en Urbanisation; 4. Application en physique (Turbulence dans un fluide); 5. Informatique (Cryptographie),Electronique, etc.
; 5. Informatique (Cryptographie),Electronique, etc.")
21
Exemple d’application : diffusion d’un feu de forêt
Paysage initial (50 * 50 cellules): 1 - Occupation en surface Eau = 5% Feuillues = 25% Pin = 50% Sols nus= 10% Cultures =10% 2- Inflammabilité (Probabilité) Eau : 0 Sol nu : 0 Feuillues : 0.80 Pin : 0.95 Cultures :0.5 Etat possibles: - Occupation - Feu - Cendre
: 1 - Occupation en surface. Eau = 5% Feuillues = 25% Pin = 50% Sols nus= 10% Cultures =10% 2- Inflammabilité (Probabilité) Eau : 0. Sol nu : 0. Feuillues : Pin : Cultures :0.5. Etat possibles: - Occupation. - Feu. - Cendre.")
22
Modélisation des processus stochastiques par les chaînes de Markov
Un processus est appelé chaîne de Markov lorsque l’état d’un phénomène aléatoire ou le résultat d’une expérience aléatoire peut influencer l’état suivant ou le résultat de l’expérience suivante. Soit un système quelconque composés de trois états A, B et C tels que les probabilités de passage d’un état à un autre sont les suivantes: Etat A Etat B Etat C PAB PAC PBB PBC PAA PBA PCC PCB Etat A Etat B Etat C Etat A Etat B Etat C Etat C Etat B PAA Etat A PAC PAB PCC PBB PBA PCB Etat C Etat B PBC

23
Etat B Etat A Etat C PAA PAB PAC PBB PBA PBC PCB PCC Les probabilités (P) correspondent à des probabilités de transition entre états: On a PAA+PAB+PAC = 1, PBB+PBA+PBC =1, PCC+PCB=1 Entre les temps t et t+1, on a: (Etat A)t+1 = PAA*(Etat A)t + PBA*(Etat B)t (Etat B)t+1 = PAB*(Etat A)t + PBB*(Etat B)t + PCB*(Etat C)t (Etat C)t+1 = PAc*(Etat A)t + PBc*(Etat B)t PCC*(Etat C)t Autrement :
 correspondent à des probabilités de transition entre états: On a PAA+PAB+PAC = 1, PBB+PBA+PBC =1, PCC+PCB=1. Entre les temps t et t+1, on a: (Etat A)t+1 = PAA*(Etat A)t + PBA*(Etat B)t. (Etat B)t+1 = PAB*(Etat A)t + PBB*(Etat B)t + PCB*(Etat C)t. (Etat C)t+1 = PAc*(Etat A)t + PBc*(Etat B)t PCC*(Etat C)t. Autrement :")
24
Etat B Etat A Etat C PAA PAB PAC PBB PBA PBC PCB PCC Etats finaux (temps t+1) A B C PAA PAB PAC PBC PBB PCA PCB PCC ∑P = 1 Etats initiaux (temps t) Les matrices ETAT s’écrivent : (ETAT)t+1 = (ETAT)t [T] La matrice [T] est la matrice de transition dont les éléments sont donnés dans le tableau ci-dessus.
 Les matrices ETAT s’écrivent : (ETAT)t+1 = (ETAT)t [T] La matrice [T] est la matrice de transition dont les éléments sont donnés dans le tableau ci-dessus.")
25
L’état à un instant t quelconque est donné par:
Etat Initial (t=0) :V0 Chênes = 20% Vignes = 20% Pelouse = 10% Garrigue = 15% Pinède = 35% Exemple tiré de : Coquillard et Hill- Modélisation et simulation d’écosystème L’état à un instant t quelconque est donné par:
 :V0. Chênes = 20% Vignes = 20% Pelouse = 10% Garrigue = 15% Pinède = 35% Exemple tiré de : Coquillard et Hill- Modélisation et simulation d’écosystème. L’état à un instant t quelconque est donné par:")
27
MERCI

Présentations similaires
 r =>")


















